
























GPT-2 (XL) имеет 1,5 миллиарда параметров, и его параметры занимают около 3 ГБ памяти с точностью до 16 бит.
Однако вряд ли его можно обучить на одном графическом процессоре с 30 ГБ памяти.


Это в 10 раз больше памяти модели, и вы можете задаться вопросом, как это вообще возможно.
Хотя в этой статье основное внимание уделяется не потреблению памяти LLM (
На самом деле в приведенном выше примере мы рассматривали довольно маленькую модель — GPT-2 (XL) всего с 1,5 миллиарда параметров.
Вот сравнение размеров GPT-2 (XL) и GPT-3, чтобы вы могли представить, что там произойдет:


Одна из вещей, которая сильно отличает обучение LLM от обычного обучения моделям, — это огромный масштаб, демонстрируемый этими моделями, требующий значительных вычислительных ресурсов и методов для эффективной разработки, обучения и развертывания.
Вот почему типичное здание LLM больше связано с «инжинирингом», чем с «обучением».
К счастью, сегодня у нас есть различные специализированные библиотеки и инструменты, предназначенные для управления различными этапами проектов LLM: от начальной разработки и обучения до тестирования, оценки, развертывания и регистрации.


В этой статье представлены некоторые из лучших библиотек, доступных для разработки LLM, сгруппированные по их конкретным ролям в жизненном цикле проекта, как показано на рисунке выше.
Несмотря на то, что существует множество библиотек и инструментов для разработки LLM, мы решили сохранить наш список относительно кратким и включили в короткий список 9 библиотек на основе таких факторов, как принятие, поддержка сообщества, надежность, практическая полезность и многое другое. Не стесняйтесь использовать оглавление, чтобы перейти к библиотекам, о которых вы хотите узнать больше.
Обучение и масштабирование
Проверка реальности
№1) Мегатрон-ЛМ
№2) ДипСпид
#3) ЯФСДП
Тестирование и оценка
#1) Жискар
#2) lm-оценка-жгут
Развертывание и вывод
#1) vLLM
#2) CTranslate2
Ведение журнала
#1) Труера
#2) Глубокие проверки
Обучение и масштабирование

Проверка реальности
Учитывая масштабы, распределенное обучение (процедура обучения, в которой задействовано несколько графических процессоров) находится на переднем крае обучения LLM.
Один очевидный способ использовать распределенное обучение — распределить данные по нескольким графическим процессорам, запустить прямой проход на каждом устройстве и вычислить градиенты:

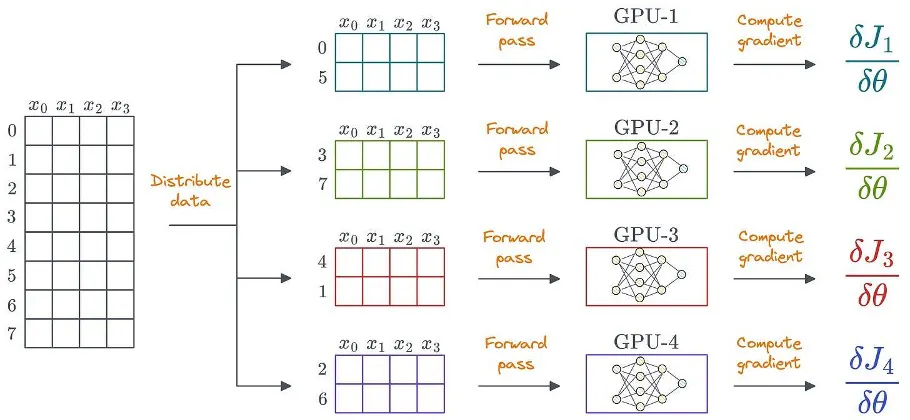
Данные также могут быть неструктурированными. Структурированные данные показаны только для простоты.
Для этого каждый графический процессор хранит собственную копию весов модели и состояний оптимизатора:


Однако самая большая проблема заключается в том, что эти модели ОГРОМНЫ. Репликация всей модели на каждом графическом процессоре практически невозможна.
А как насчет памяти, потребляемой состояниями оптимизатора? Мы это еще даже не рассматривали.
Для более подробного контекста: память, потребляемая оптимизатором Адама (одним из наиболее широко используемых оптимизаторов), эквивалентна удвоенному весу модели (с 32-битной точностью).


Если предположить, что нам каким-то образом удалось вычислить градиенты, следующим узким местом станет передача их на другие графические процессоры для синхронизации моделей.
Наивный способ (показанный ниже) предполагает передачу градиентов с одного графического процессора на все остальные графические процессоры, причем каждая передача эквивалентна размеру модели.


Конечно, есть способы оптимизировать это, но они также практически неосуществимы в таких масштабах.
Вот несколько библиотек, которые решают эту проблему.
№1) Мегатрон-ЛМ
Megatron — это библиотека оптимизации, разработанная NVIDIA для обучения крупномасштабных моделей трансформаторов с учетом ограничений традиционного распределенного обучения.
Библиотека утверждает, что можно обучать LLM с многомиллиардными параметрами, используя параллелизм моделей . Основная идея состоит в том, чтобы распределить параметры модели по нескольким графическим процессорам.


Параллелизм моделей можно комбинировать с параллелизмом данных (обсуждаемым в разделе выше).
В соответствующем документе, опубликованном NVIDIA, упоминается, что они эффективно обучили модели на основе трансформаторов до 8,3 миллиардов параметров на 512 графических процессорах NVIDIA.
Честно говоря, это не слишком большая сумма, учитывая масштабы сегодняшних моделей.
Но это считалось большим подвигом, поскольку Megatron был впервые выпущен в 2019 году (до эпохи GPT-3), и создание моделей такого масштаба в то время было по своей сути сложной задачей.
Фактически, с 2019 года было предложено еще несколько итераций Мегатрона.
Начните здесь:
№2) ДипСпид
DeepSpeed — это библиотека оптимизации, разработанная Microsoft, которая устраняет болевые точки распределенного обучения.


Напомним, что в приведенном выше обсуждении установка распределенного обучения включала в себя большое количество избыточности:
Каждый графический процессор имел одинаковый вес модели.
На каждом графическом процессоре имеется копия оптимизатора.
Каждый графический процессор хранил одну и ту же многомерную копию состояний оптимизатора.
Алгоритм ZeRO (оптимизатор нулевой избыточности), как следует из названия, полностью устраняет эту избыточность, полностью разделяя веса, градиенты и состояния оптимизатора между всеми графическими процессорами.
Это изображено ниже:


Хотя мы не будем вдаваться в технические подробности, эта умная идея позволила ускорить процесс обучения при значительном снижении нагрузки на память.
Более того, это ускоряет шаг оптимизатора в N раз (количество графических процессоров).
В документе утверждается, что ZeRO может масштабироваться за пределы 1 триллиона параметров .
Однако в своих собственных экспериментах исследователи построили модель с 17B параметрами — Turing-NLG , крупнейшую модель в мире по состоянию на 12 мая 2020 года.
Начните здесь:
В 2022 году (после GPT-3) NVIDIA (создатель Megatron) и Microsoft (создатель DeepSpeed) вместе предложили
Они использовали его для создания Мегатрона-Тьюринга NLG, который имел параметры 530B — в три раза больше, чем GPT-3.


№3) ЯФСДП
Хотя DeepSpeed является довольно мощным инструментом, он также обладает различными практическими ограничениями.
Например:
Реализация DeepSpeed может стать неэффективной в больших кластерах из-за накладных расходов на связь и зависимости от
НККЛ библиотека для коллективного общения.Кроме того, DeepSpeed существенно трансформирует процесс обучения, что может привести к появлению ошибок и потребовать значительного тестирования.
YaFSDP — это новая библиотека параллелизма данных, которая представляет собой расширенную версию
В двух словах, по сравнению с FSDP и DeepSpeed, YaFSDP:
- Динамически распределяет память для слоев более эффективно, гарантируя, что в любой момент времени используется только необходимый объем памяти.
- Избавляется от «эффекта уступки», тем самым значительно сокращая время простоя вычислений.
- Использует такие методы, как
FlattenParameter, который объединяет несколько параметров уровня в один большой параметр перед сегментированием, что еще больше повышает эффективность связи и масштабируемость. - Поддерживает более удобный интерфейс, влияя только на модель, но не на конвейер обучения.
- И более.
В следующей таблице сравниваются результаты YaFSDP с текущими методами:


- YaFSDP ВСЕГДА более производительен, чем существующие методы.
- Благодаря большому количеству графических процессоров YaFSDP обеспечивает гораздо лучшее ускорение, что указывает на его возможности для лучшей масштабируемости.
Начните здесь:
Тестирование и оценка
На этом мы закончили обучение и масштабирование. Следующий шаг — тестирование и оценка:
Неотъемлемой проблемой оценки LLM является то, что их нельзя оценить на основе нескольких показателей, таких как точность, показатель F1, отзыв и т. д.
Вместо этого их необходимо оценивать по нескольким параметрам, таким как беглость, связность, фактическая точность и устойчивость к состязательным атакам, и эта оценка часто является субъективной.
В этом нам помогают различные инструменты:
#1) Жискар


Giskard — это библиотека с открытым исходным кодом, которая помогает нам обнаруживать следующие проблемы с LLM:
- Галлюцинации
- Дезинформация
- Вредность
- Стереотипы
- Раскрытие частной информации
- Быстрые инъекции
Он работает со всеми популярными фреймворками, такими как PyTorch, TensorFlow, HuggingFace, Scikit-Learn, XGBoost и LangChain. Более того, его также можно интегрировать с HuggingFace, Weights & Biases и MLFlow.
Начните здесь:
#2) lm-оценка-жгут
Evaluation Harness — это еще один инструмент с открытым исходным кодом, который позволяет LLM пройти надежный процесс оценки.
По сути, можно выбрать, по каким критериям он хотел бы протестировать свою модель, запустить их в системе и затем получить результаты.
По состоянию на май 2024 года он имеет более 60 стандартных академических тестов для программ LLM и простую поддержку пользовательских подсказок и показателей оценки, что сложно сделать с Giskard.
Некоторые общие критерии включают в себя:
- Вопросы и ответы
- Вопросы с несколькими вариантами ответов
- Задачи, проверяющие гендерную предвзятость, аналогичные тем, которые могут выполнять люди.
- И более.
Начните здесь:
Есть еще несколько инструментов, таких как Truera и DeepChecks, но они гораздо более комплексны, поскольку предоставляют комплексные решения для оценки и наблюдения. Мы рассмотрим их в последнем разделе.
Если вы хотите получить более подробную информацию об оценке LLM, я рекомендую эту статью:
Развертывание и вывод
Таким образом, мы оценили нашу модель и уверенно перешли к ее развертыванию:

Обратите внимание: когда мы говорим «развертывание», мы не имеем в виду отправку модели в облако. Это может сделать любой.
Вместо этого речь идет больше о достижении эффективности на этапах вывода для снижения затрат.
#1) vLLM
vLLM, возможно, является одним из лучших инструментов с открытым исходным кодом для повышения эффективности вывода LLM.


Короче говоря, vLLM использует новый алгоритм внимания для ускорения вывода без ущерба для производительности модели.
Результаты показывают, что он может обеспечить примерно в 24 раза более высокую пропускную способность, чем HuggingFace Transformers, без каких-либо изменений модели.


В результате это делает обслуживание LLM гораздо более доступным для всех.
Начните здесь:
#2) CTranslate2
CTranslate2 — еще один популярный механизм быстрого вывода для моделей Transformer.
Короче говоря, библиотека реализует множество методов оптимизации производительности для LLM, таких как:
- Квантование весов . Квантование снижает точность весов от представлений с плавающей запятой до представлений с меньшим битом, таких как int8 или int16. Это значительно уменьшает размер модели и объем памяти, позволяя ускорить вычисления и снизить энергопотребление. Более того, умножение матриц также выполняется быстрее при представлениях с меньшей точностью:


- Слияние слоев . Как следует из названия, объединение слоев объединяет несколько операций в одну операцию на этапе вывода. Хотя точные технические подробности выходят за рамки этой статьи, количество вычислительных шагов сокращается за счет слияния слоев, что снижает накладные расходы, связанные с каждым слоем.
- Пакетное изменение порядка . Пакетное изменение порядка включает в себя организацию входных пакетов для оптимизации использования аппаратных ресурсов. Этот метод гарантирует, что последовательности одинаковой длины обрабатываются вместе, минимизируя заполнение и максимизируя эффективность параллельной обработки.
Использование методов значительно ускоряет и снижает использование памяти моделями Transformer как на процессоре, так и на графическом процессоре.
Начните здесь:
Ведение журнала
Модель была масштабирована, протестирована, запущена в эксплуатацию и развернута, и теперь она обрабатывает запросы пользователей.
Однако важно иметь надежные механизмы журналирования для мониторинга производительности модели, ее поведения и обеспечения ее ожидаемой работы в производственной среде.
Это относится не только к LLM, но и ко всем реальным моделям машинного обучения.

Вот некоторые важные инструменты и методы ведения журналов в контексте LLM.
#1) Труера
Truera — это не просто решение для ведения журналов.


Вместо этого он также предоставляет дополнительные возможности для тестирования и оценки LLM.
Это делает его гораздо более комплексным решением для наблюдения, которое предоставляет инструменты для отслеживания производительности производства, минимизирует такие проблемы, как галлюцинации, и обеспечивает ответственную практику искусственного интеллекта.
Вот некоторые ключевые особенности:
Наблюдение за LLM : TruEra обеспечивает детальное наблюдение для приложений LLM. Пользователи могут оценивать свои приложения LLM, используя функции обратной связи и отслеживание приложений, что помогает оптимизировать производительность и минимизировать риски, такие как галлюцинации.
Масштабируемый мониторинг и отчетность . Платформа предлагает комплексный мониторинг, отчетность и оповещение с точки зрения производительности модели, входных и выходных данных. Эта функция гарантирует, что любые проблемы, такие как дрейф модели, переоснащение или смещение, быстро выявляются и устраняются с помощью уникального анализа первопричин ИИ.
[ВАЖНО] TruLens : TruLens от TruEra — это библиотека с открытым исходным кодом, которая позволяет пользователям тестировать и отслеживать свои приложения LLM.
И более.
Одна из замечательных особенностей TruEra заключается в том, что она может легко интегрироваться с существующими стеками искусственного интеллекта, включая решения для разработки прогнозных моделей, такие как AWS SageMaker, Microsoft Azure, Vertex.ai и другие.
Он также поддерживает развертывание в различных средах, включая частное облако, AWS, Google или Azure, и масштабируется для соответствия большим объемам моделей.
Начните здесь:
#2) Глубокие проверки


Deepchecks — еще одно комплексное решение, такое как TruEra, которое предоставляет решения для оценки, тестирования и мониторинга LLM.
Однако библиотека не ограничивается только LLM. Вместо этого многие специалисты по данным и инженеры по машинному обучению используют DeepChecks для различных моделей машинного обучения в различных областях.
Тем не менее, их система оценки не такая всеобъемлющая и тщательная, как у Жискара, инструмента, который мы обсуждали ранее.
Начните здесь:
Поскольку мы хотели, чтобы эта статья была краткой и быстрой, мы не рассмотрели каждый существующий инструмент, но продемонстрировали инструменты, которых будет достаточно для 90% случаев использования.
Вот несколько примеров инструментов, которые мы решили опустить.
- Обучение и масштабирование: Fairscale.
- Тестирование и оценка: TextAttack.
- Подача: Флоуайз.
- Ведение журнала: веса и смещения, MLFlow и многое другое.
Если вы хотите глубже погрузиться во многие другие наборы инструментов, ознакомьтесь с этим
Спасибо за прочтение!








