
























GPT-2(XL)有 15 亿个参数,其参数在 16 位精度下消耗约 3GB 内存。
然而,很难在具有30GB内存的单个 GPU 上进行训练。


这是模型内存的 10 倍,您可能想知道这是如何可能的。
虽然本文的重点不是 LLM 内存消耗(
事实上,在上面的例子中,我们考虑了一个非常小的模型——GPT-2(XL),只有 15 亿个参数。
以下是 GPT-2(XL)与 GPT-3 的尺寸比较,你可以想象会发生什么:


LLM 训练与常规模型训练的巨大区别之一是这些模型所展现的庞大规模,需要大量的计算资源和技术才能有效地开发、训练和部署。
这就是为什么典型的 LLM 建设更多的是关于“工程”而不是“培训”。
值得庆幸的是,今天,我们有各种专门的库和工具来处理 LLM 项目的各个阶段,从最初的开发和培训到测试、评估、部署和记录。


本文介绍了一些可用于 LLM 开发的最佳库,并按其在项目生命周期中的特定角色进行分类,如上图所示。
虽然有很多用于 LLM 开发的库和工具,但我们决定将列表保持相对简洁,并根据采用率、社区支持、可靠性、实用性等因素入围了 9 个库。您可以随意使用目录跳转到您想要了解更多信息的库。
训练和扩展
现实检验
#1)威震天-LM
2)DeepSpeed
#3)YaFSDP
测试与评估
1)吉斯卡德
#2) 电影评估工具
部署和推理
1)vLLM
#2)CTranslate2
日志记录
1)特鲁拉
#2)深度检查
训练和扩展

现实检验
鉴于规模,分布式学习(涉及多个 GPU 的训练过程)处于 LLM 训练的最前沿。
利用分布式学习的一个明显方法是将数据分布在多个 GPU 上,在每个设备上运行前向传递,并计算梯度:

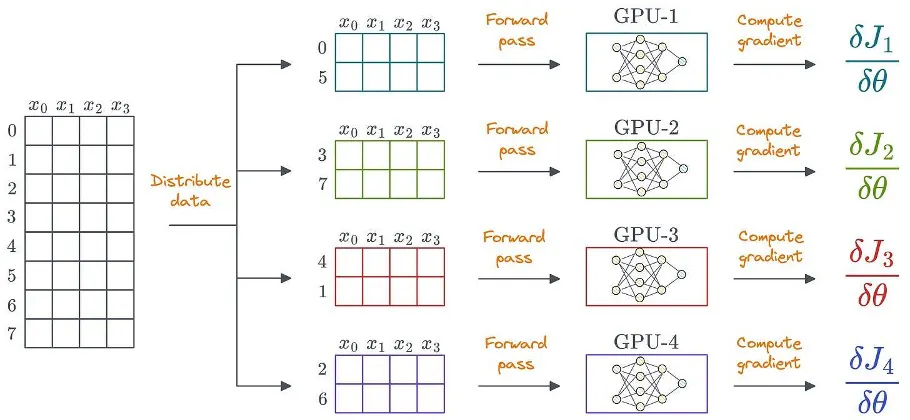
数据也可以是非结构化的。结构化数据只是为了简单起见才显示的。
为了实现这一点,每个 GPU 都存储自己的模型权重和优化器状态的副本:


然而,最大的问题是这些模型非常庞大。在每个 GPU 设备上复制整个模型实际上是不可行的。
另外,优化器状态消耗的内存怎么样?我们甚至还没有考虑过这个问题。
更多背景信息是,Adam 优化器(最广泛使用的优化器之一)消耗的内存相当于模型权重的两倍(32 位精度)。


假设我们已经设法计算出梯度,下一个瓶颈就是将它们传输到其他 GPU 以同步模型。
简单的方法(如下所示)涉及将梯度从一个 GPU 传输到所有其他 GPU,并且每次传输都相当于模型大小。


当然,也有方法可以优化这一点,但在这个规模下实际上也是不可行的。
这里有一些解决这个问题的库。
#1)威震天-LM
Megatron 是 NVIDIA 开发的优化库,用于训练大规模 Transformer 模型,同时解决传统分布式学习的局限性。
该库声称可以使用模型并行性来训练数十亿参数的LLM。其核心思想是将模型的参数分布在多个GPU上。


模型并行可以与数据并行相结合(在上面的部分中讨论)。
NVIDIA发布的相应论文提到,他们在512个NVIDIA GPU上高效训练了多达83亿个参数的基于Transformer的模型。
坦率地说,考虑到当今模型的规模,这个数字并不算大。
但这被认为是一项伟大的壮举,因为 Megatron 于 2019 年(GPT-3 时代之前)首次发布,而当时构建如此规模的模型本质上非常困难。
事实上,自 2019 年以来,已经提出了更多 Megatron 的迭代版本。
从这里开始:
2)DeepSpeed
DeepSpeed是微软针对分布式学习痛点开发的优化库。


这
回想一下,在上面的讨论中,分布式学习设置涉及大量冗余:
每个 GPU 都具有相同的模型权重。
每个 GPU 都保留一份优化器的副本。
每个 GPU 都存储了相同维度的优化器状态副本。
ZeRO(零冗余优化器)算法,顾名思义,通过在所有 GPU 之间完全分割优化器的权重、梯度和状态来完全消除这种冗余。
如下所示:


虽然我们不会深入讨论技术细节,但这个聪明的想法可以加快学习过程,同时显著减少记忆负荷。
此外,它将优化器步骤的速度提高了 N 倍(GPU 数量)。
该论文声称 ZeRO 的扩展范围可以超过1 万亿个参数。
然而,在他们自己的实验中,研究人员构建了一个拥有 17B 个参数的模型——Turing -NLG ,这是截至 2020 年 5 月 12 日世界上最大的模型。
从这里开始:
2022 年(GPT-3 之后),NVIDIA(Megatron 的创造者)和 Microsoft(DeepSpeed 的创造者)合作提出了
他们用它构建了 Megatron-Turing NLG,它有 530B 参数——比 GPT-3 大三倍。


#3)亚弗斯普林斯
虽然 DeepSpeed 功能强大,但它也存在各种实际限制。
例如:
由于通信开销和对
全国临床研究委员会 用于集体通信的图书馆。此外,DeepSpeed 显著改变了训练流程,这可能会引入错误并需要大量测试。
YaFSDP 是一个新的数据并行库,它是
简而言之,与 FSDP 和 DeepSpeed 相比,YaFSDP:
- 更有效地为层动态分配内存,确保在任何给定时间仅使用必要量的内存。
- 摆脱“让路效应”,从而大大减少计算的停机时间。
- 利用
FlattenParameter等技术,在分片之前将多层参数组合成单个大参数,进一步提高通信效率和可扩展性。 - 通过仅影响模型而不影响训练流程来维护更加用户友好的界面。
- 和更多。
下表将 YaFSDP 的结果与当前技术进行了比较:


- YaFSDP 的性能始终比当前技术更高。
- 凭借大量 GPU,YaFSDP 实现了更好的加速,这表明其具有更好的可扩展性。
从这里开始:
测试与评估
这样,我们就完成了训练和扩展。下一步是测试和评估:
评估 LLM 的一个固有挑战是,不能基于准确度、F1 分数、召回率等一些指标进行评估。
相反,必须从流畅性、连贯性、事实准确性和对抗攻击的鲁棒性等多个维度进行评估,而且这种评估通常是主观的。
有各种各样的工具可以帮助我们做到这一点:
1)吉斯卡德


Giskard 是一个开源库,它可以帮助我们检测 LLM 的以下问题:
- 幻觉
- 误传
- 危害性
- 刻板印象
- 私人信息披露
- 及时注射
它适用于所有流行的框架,例如 PyTorch、TensorFlow、HuggingFace、Scikit-Learn、XGBoost 和 LangChain。此外,还可以将其与 HuggingFace、Weights & Biases 和 MLFlow 集成。
从这里开始:
#2) 电影评估工具
Evaluation Harness 是另一个开源工具,可对 LLM 进行严格的评估过程。
本质上,人们可以选择他们想要测试模型的基准,在系统中运行这些基准,然后收到结果。
截至 2024 年 5 月,它拥有超过 60 个 LLM 标准学术基准,并可轻松支持自定义提示和评估指标,而这对于 Giskard 来说很难实现。
一些常见的基准包括:
- 问题与解答
- 多项选择题
- 测试性别偏见的任务与人类能够完成的任务类似。
- 和更多。
从这里开始:
还有一些其他工具,例如 Truera 和 DeepChecks,但它们更加全面,因为它们提供端到端评估和可观察性解决方案。我们将在最后一节中介绍它们。
如果你想了解有关 LLM 评估的更多详细信息,我推荐这篇文章:
部署和推理
通过此,我们评估了我们的模型,并且有信心将其转移到部署:

请注意,当我们说“部署”时,我们并不是指将模型推送到云端。任何人都可以做到这一点。
相反,它更重要的是在推理阶段实现效率以降低成本。
#1)vLLM
vLLM 可能是提高 LLM 推理效率的最佳开源工具之一。


简而言之,vLLM 使用一种新颖的注意力算法来加速推理,同时不影响模型的性能。
结果表明,它可以提供比 HuggingFace Transformers 高约 24 倍的吞吐量,且无需进行任何模型更改。


因此,它使得 LLM 服务对于每个人来说都变得更加实惠。
从这里开始:
#2)CTranslate2
CTranslate2 是另一种流行的 Transformer 模型快速推理引擎。
长话短说,该库为 LLM 实现了许多性能优化技术,例如:
- 权重量化:量化将权重的精度从浮点数降低到较低位表示,例如 int8 或 int16。这显著减少了模型大小和内存占用,从而实现了更快的计算速度和更低的功耗。此外,矩阵乘法在较低精度表示下也运行得更快:


- 层融合:顾名思义,层融合在推理阶段将多个操作合并为一个操作。虽然确切的技术细节超出了本文的范围,但通过合并层可以减少计算步骤的数量,从而减少与每个层相关的开销。
- 批次重新排序:批次重新排序涉及组织输入批次以优化硬件资源的使用。此技术可确保将相似长度的序列一起处理,从而最大限度地减少填充并最大限度地提高并行处理效率。
使用这些技术可以大大加速 Transformer 模型并减少其在 CPU 和 GPU 上的内存使用量。
从这里开始:
日志记录
该模型已经扩展、测试、生产和部署,目前正在处理用户请求。
然而,必须拥有强大的日志记录机制来监控模型的性能、跟踪其行为并确保它在生产环境中按预期运行。
这不仅适用于 LLM,也适用于所有现实世界的 ML 模型。

以下是在 LLM 环境中进行日志记录的一些基本工具和技术。
1)特鲁拉
Truera 不仅仅是一个日志解决方案。


相反,它还提供了测试和评估 LLM 的附加功能。
这使得它成为一个更加全面的可观察性解决方案——它提供工具来跟踪生产性能、最大限度地减少幻觉等问题并确保负责任的人工智能实践。
以下是一些主要特点:
LLM 可观察性:TruEra 为 LLM 应用程序提供详细的可观察性。用户可以使用反馈功能和应用程序跟踪来评估他们的 LLM 应用程序,这有助于优化性能并最大限度地降低幻觉等风险。
可扩展的监控和报告:该平台在模型性能、输入和输出方面提供全面的监控、报告和警报。此功能可确保通过独特的 AI 根本原因分析快速识别和解决模型漂移、过度拟合或偏差等任何问题。
[重要] TruLens :TruEra 的 TruLens 是一个开源库,允许用户测试和跟踪他们的 LLM 应用程序。
和更多。
TruEra 的一大优点是它可以与现有的 AI 堆栈无缝集成,包括 AWS SageMaker、Microsoft Azure、Vertex.ai 等预测模型开发解决方案。
它还支持在各种环境中部署,包括私有云、AWS、Google 或 Azure,并可扩展以满足高模型量。
从这里开始:
#2)深度检查


Deepchecks 是另一个类似 TruEra 的综合解决方案,它提供 LLM 评估、测试和监控解决方案。
然而,该库并不仅限于 LLM。相反,许多数据科学家和机器学习工程师利用 DeepChecks 来研究各个领域的各种机器学习模型。
话虽如此,他们的评估框架并不像我们之前讨论过的 Giskard 工具那样全面和彻底。
从这里开始:
由于我们希望本文简洁明了,因此我们没有介绍所有的工具,但我们展示了足以满足 90% 用例的工具。
以下是我们决定省略的几个工具的示例。
- 训练和扩展:Fairscale。
- 测试和评估:TextAttack。
- 服务:Flowise。
- 日志记录:权重和偏差、MLFlow 等等。
如果你想深入了解更多工具堆栈,请查看此内容
谢谢阅读!








