
























GPT-2 (XL) hat 1,5 Milliarden Parameter und seine Parameter verbrauchen ca. 3 GB Speicher bei 16-Bit-Präzision.
Allerdings kann man es kaum auf einer einzelnen GPU mit 30 GB Speicher trainieren.


Das ist das Zehnfache des Speichers des Modells, und Sie fragen sich vielleicht, wie das überhaupt möglich ist.
Der Schwerpunkt dieses Artikels liegt nicht auf dem LLM-Speicherverbrauch (
Tatsächlich haben wir im obigen Beispiel ein ziemlich kleines Modell betrachtet – GPT-2 (XL) mit nur 1,5 Milliarden Parametern.
Hier ist ein Größenvergleich von GPT-2 (XL) mit GPT-3, damit Sie sich vorstellen können, was dort passieren würde:


Ein Grund, warum sich das LLM-Training stark vom regulären Modelltraining unterscheidet, ist der enorme Umfang dieser Modelle, der für die effiziente Entwicklung, das Training und den Einsatz erhebliche Rechenressourcen und Techniken erfordert.
Aus diesem Grund geht es beim Aufbau eines typischen LLM-Studiums eher um „Engineering“ als um „Ausbildung“.
Glücklicherweise verfügen wir heute über verschiedene spezialisierte Bibliotheken und Tools, die für die verschiedenen Phasen von LLM-Projekten entwickelt wurden, von der anfänglichen Entwicklung und Schulung bis hin zu Tests, Auswertung, Bereitstellung und Protokollierung.


Dieser Artikel stellt einige der besten verfügbaren Bibliotheken für die LLM-Entwicklung vor, kategorisiert nach ihren spezifischen Rollen im Projektlebenszyklus, wie in der Abbildung oben dargestellt.
Obwohl es viele Bibliotheken und Tools für die LLM-Entwicklung gibt, haben wir uns entschieden, unsere Liste relativ kurz zu halten und 9 Bibliotheken anhand von Faktoren wie Akzeptanz, Community-Unterstützung, Zuverlässigkeit, praktischem Nutzen und mehr in die engere Auswahl zu nehmen. Nutzen Sie das Inhaltsverzeichnis, um zu den Bibliotheken zu springen, über die Sie mehr erfahren möchten.
Training und Skalierung
Ein Realitätscheck
#1) Megatron-LM
#2) DeepSpeed
#3) YaFSDP
Testen und Auswerten
#1) Giskard
#2) lm-evaluation-harness
Bereitstellung und Inferenz
#1) vLLM
#2) CTranslate2
Protokollierung
#1) Truera
#2) Tiefenchecks
Training und Skalierung

Ein Realitätscheck
Angesichts des Umfangs steht das verteilte Lernen (ein Trainingsverfahren, an dem mehrere GPUs beteiligt sind) bei der Ausbildung von LLMs im Vordergrund.
Eine offensichtliche Möglichkeit, verteiltes Lernen zu nutzen, besteht darin, die Daten auf mehrere GPUs zu verteilen, den Vorwärtsdurchlauf auf jedem Gerät auszuführen und die Gradienten zu berechnen:

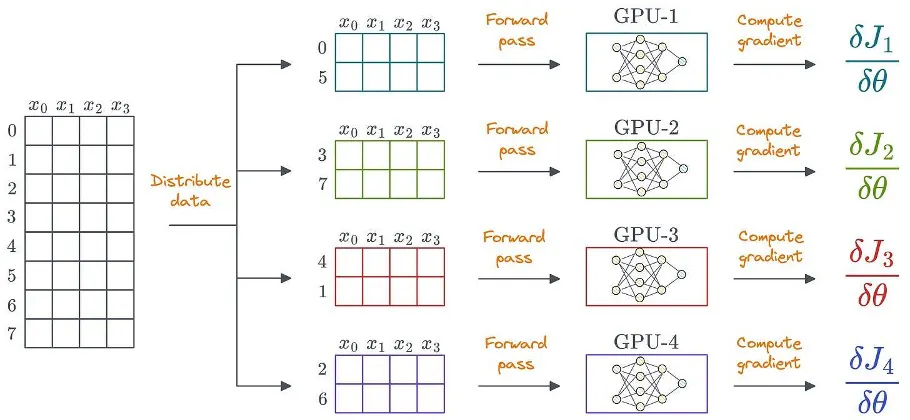
Daten können auch unstrukturiert sein. Strukturierte Daten werden nur der Einfachheit halber angezeigt.
Um dies zu erreichen, speichert jede GPU ihre eigene Kopie der Modellgewichte und Optimiererzustände:


Das größte Problem besteht jedoch darin, dass diese Modelle RIESIG sind. Das Replizieren des gesamten Modells auf jedem GPU-Gerät ist praktisch unmöglich.
Und was ist mit dem Speicher, der von Optimiererzuständen verbraucht wird? Das haben wir noch nicht einmal berücksichtigt.
Zur weiteren Erläuterung: Der vom Adam-Optimierer (einem der am häufigsten verwendeten Optimierer) verbrauchte Speicher entspricht dem Doppelten der Gewichte des Modells (in 32-Bit-Präzision).


Angenommen, wir haben es irgendwie geschafft, die Gradienten zu berechnen, besteht der nächste Engpass darin, sie zur Synchronisierung der Modelle auf andere GPUs zu übertragen.
Bei der naiven Methode (siehe unten) werden Gradienten von einer GPU auf alle anderen GPUs übertragen, und jede Übertragung entspricht der Modellgröße.


Natürlich gibt es Möglichkeiten zur Optimierung, aber auch diese sind in diesem Maßstab praktisch nicht umsetzbar.
Hier sind einige Bibliotheken, die dieses Problem lösen.
#1) Megatron-LM
Megatron ist eine von NVIDIA entwickelte Optimierungsbibliothek zum Trainieren groß angelegter Transformer-Modelle bei gleichzeitiger Überwindung der Einschränkungen des herkömmlichen verteilten Lernens.
Die Bibliothek behauptet, dass man LLMs mit mehreren Milliarden Parametern durch Modellparallelität trainieren kann. Die Kernidee besteht darin, die Parameter des Modells auf mehrere GPUs zu verteilen.


Modellparallelität kann mit Datenparallelität kombiniert werden (siehe Abschnitt oben).
In dem entsprechenden von NVIDIA veröffentlichten Dokument wird erwähnt, dass sie transformerbasierte Modelle mit bis zu 8,3 Milliarden Parametern effizient auf 512 NVIDIA-GPUs trainiert haben.
Ehrlich gesagt ist das angesichts der Größe heutiger Modelle nicht besonders groß.
Dies galt jedoch als große Leistung, da Megatron erstmals im Jahr 2019 (vor der GPT-3-Ära) veröffentlicht wurde und der Bau von Modellen dieser Größenordnung damals von Natur aus schwierig war.
Tatsächlich wurden seit 2019 einige weitere Iterationen von Megatron vorgeschlagen.
Fang hier an:
#2) DeepSpeed
DeepSpeed ist eine von Microsoft entwickelte Optimierungsbibliothek, die die Schwachstellen des verteilten Lernens angeht.


Der
Denken Sie daran, dass das verteilte Lern-Setup in der obigen Diskussion viel Redundanz aufwies:
Jede GPU hatte die gleichen Modellgewichte.
Jede GPU verwaltet eine Kopie des Optimierers.
Jede GPU speicherte die gleiche dimensionale Kopie der Optimiererzustände.
Der ZeRO-Algorithmus (Zero Redundancy Optimizer) eliminiert, wie der Name schon sagt, diese Redundanz vollständig, indem er die Gewichte, Gradienten und Zustände des Optimierers vollständig auf alle GPUs aufteilt.
Dies wird unten dargestellt:


Auf die technischen Details wollen wir hier nicht näher eingehen, aber diese clevere Idee ermöglichte es, den Lernprozess bei deutlich reduzierter Gedächtnisbelastung zu beschleunigen.
Darüber hinaus beschleunigt es den Optimierungsschritt um den Faktor N (Anzahl der GPUs).
In dem Papier wird behauptet, dass ZeRO auf über 1 Billion Parameter skalierbar ist.
In ihren eigenen Experimenten bauten die Forscher jedoch ein 17-B-Parameter-Modell – Turing-NLG , das am 12. Mai 2020 weltweit größte Modell.
Fang hier an:
Im Jahr 2022 (nach GPT-3) arbeiteten NVIDIA (der Entwickler von Megatron) und Microsoft (der Entwickler von DeepSpeed) zusammen, um vorzuschlagen
Sie verwendeten es zum Bau des Megatron-Turing NLG, das über 530 Milliarden Parameter verfügte – dreimal größer als GPT-3.


#3) YaFSDP
Obwohl DeepSpeed recht leistungsstark ist, weist es auch verschiedene praktische Einschränkungen auf.
Zum Beispiel:
Die DeepSpeed-Implementierung kann auf großen Clustern aufgrund von Kommunikations-Overheads und der Abhängigkeit von der
NCCL Bibliothek für kollektive Kommunikation.Darüber hinaus verändert DeepSpeed die Trainingspipeline erheblich, was zu Fehlern führen und umfangreiche Tests erfordern kann.
YaFSDP ist eine neue Datenparallelitätsbibliothek, die eine erweiterte Version von
Kurz gesagt, YaFSDP im Vergleich zu FSDP und DeepSpeed:
- Ordnet den Speicher für Ebenen dynamisch und effizienter zu und stellt sicher, dass zu einem bestimmten Zeitpunkt nur die erforderliche Speichermenge verwendet wird.
- Beseitigt den „Give-Way-Effekt“ und reduziert dadurch die Ausfallzeiten bei Berechnungen erheblich.
- Nutzt Techniken wie
FlattenParameter, das mehrere Layer-Parameter vor dem Sharding zu einzelnen großen Parametern kombiniert, was die Kommunikationseffizienz und Skalierbarkeit weiter verbessert. - Sorgt für eine benutzerfreundlichere Schnittstelle, indem nur das Modell, nicht jedoch die Trainingspipeline beeinflusst wird.
- Und mehr.
Die folgende Tabelle vergleicht die Ergebnisse von YaFSDP mit aktuellen Techniken:


- YaFSDP ist IMMER leistungsfähiger als aktuelle Techniken.
- Mit einer großen Anzahl von GPUs erreicht YaFSDP deutlich bessere Beschleunigungen, was seinen Spielraum für bessere Skalierbarkeit verdeutlicht.
Fang hier an:
Testen und Auswerten
Damit sind wir mit dem Training und der Skalierung fertig. Der nächste Schritt ist das Testen und Auswerten:
Eine inhärente Herausforderung bei der Bewertung von LLMs besteht darin, dass sie nicht anhand einiger weniger Kennzahlen wie Genauigkeit, F1-Score, Rückruf usw. beurteilt werden können.
Stattdessen müssen sie anhand mehrerer Dimensionen wie Flüssigkeit, Kohärenz, sachliche Genauigkeit und Robustheit gegenüber feindlichen Angriffen beurteilt werden, und diese Bewertung ist oft subjektiv.
Verschiedene Tools unterstützen uns hierbei:
#1) Giskard


Giskard ist eine Open-Source-Bibliothek, die uns hilft, die folgenden Probleme mit LLMs zu erkennen:
- Halluzinationen
- Falsche Informationen
- Schädlichkeit
- Stereotypen
- Offenlegung privater Informationen
- Sofortige Injektionen
Es funktioniert mit allen gängigen Frameworks wie PyTorch, TensorFlow, HuggingFace, Scikit-Learn, XGBoost und LangChain. Darüber hinaus kann es auch in HuggingFace, Weights & Biases und MLFlow integriert werden.
Fang hier an:
#2) lm-evaluation-harness
Evaluation Harness ist ein weiteres Open-Source-Tool, das LLMs einem robusten Evaluierungsprozess unterzieht.
Im Wesentlichen kann man auswählen, anhand welcher Benchmarks man sein Modell testen möchte, diese im System ausführen und dann die Ergebnisse erhalten.
Seit Mai 2024 verfügt es über mehr als 60 standardmäßige akademische Benchmarks für LLMs und bietet einfache Unterstützung für benutzerdefinierte Eingabeaufforderungen und Bewertungsmetriken, was bei Giskard schwierig ist.
Zu den gängigen Benchmarks zählen:
- Fragen und Antworten
- Fragen mit mehreren Antworten
- Aufgaben, die auf Geschlechtervorurteile testen, ähnlich wie es Menschen tun könnten.
- Und mehr.
Fang hier an:
Es gibt noch ein paar weitere Tools, wie Truera und DeepChecks, aber sie sind viel umfassender, da sie End-to-End-Evaluierungs- und Beobachtungslösungen bieten. Wir werden sie im letzten Abschnitt behandeln.
Wenn Sie sich näher mit der LLM-Evaluation befassen möchten, empfehle ich diesen Artikel:
Bereitstellung und Inferenz
Damit haben wir unser Modell ausgewertet und es nun zuversichtlich in die Bereitstellung überführt:

Beachten Sie, dass wir mit „Bereitstellung“ nicht das Hochladen des Modells in die Cloud meinen. Das kann jeder.
Vielmehr geht es darum, während der Inferenzphasen Effizienz zu erreichen, um Kosten zu senken.
#1) vLLM
vLLM ist möglicherweise eines der besten Open-Source-Tools zur Steigerung der LLM-Inferenzeffizienz.


Kurz gesagt verwendet vLLM einen neuartigen Aufmerksamkeitsalgorithmus, um die Inferenz zu beschleunigen, ohne die Leistung des Modells zu beeinträchtigen.
Die Ergebnisse lassen darauf schließen, dass es einen etwa 24-mal höheren Durchsatz als HuggingFace Transformers liefern kann, ohne dass Modelländerungen erforderlich sind.


Dadurch wird das LLM-Studium für alle wesentlich erschwinglicher.
Fang hier an:
#2) CTranslate2
CTranslate2 ist eine weitere beliebte schnelle Inferenz-Engine für Transformer-Modelle.
Kurz gesagt, die Bibliothek implementiert viele Techniken zur Leistungsoptimierung für LLMs, wie zum Beispiel:
- Quantisierung von Gewichten : Durch die Quantisierung wird die Genauigkeit der Gewichte von Gleitkomma- auf weniger Bit-Darstellungen wie int8 oder int16 reduziert. Dadurch werden die Modellgröße und der Speicherbedarf erheblich verringert, was eine schnellere Berechnung und einen geringeren Stromverbrauch ermöglicht. Darüber hinaus laufen Matrixmultiplikationen auch bei Darstellungen mit geringerer Genauigkeit schneller:


- Schichtfusion : Wie der Name schon sagt, kombiniert die Schichtfusion während der Inferenzphase mehrere Operationen zu einer einzigen Operation. Die genauen technischen Details gehen über diesen Artikel hinaus, aber durch das Zusammenführen von Schichten wird die Anzahl der Rechenschritte reduziert, was den mit jeder Schicht verbundenen Aufwand verringert.
- Neuanordnung von Stapeln : Bei der Neuanordnung von Stapeln werden die Eingabestapel so organisiert, dass die Nutzung der Hardwareressourcen optimiert wird. Diese Technik stellt sicher, dass Sequenzen ähnlicher Länge zusammen verarbeitet werden, wodurch Auffüllungen minimiert und die Effizienz der parallelen Verarbeitung maximiert werden.
Durch den Einsatz von Techniken wird die Speichernutzung von Transformer-Modellen sowohl auf der CPU als auch auf der GPU drastisch beschleunigt und reduziert.
Fang hier an:
Protokollierung
Das Modell wurde skaliert, getestet, in die Produktion gebracht und bereitgestellt und verarbeitet jetzt Benutzeranforderungen.
Es ist jedoch wichtig, über robuste Protokollierungsmechanismen zu verfügen, um die Leistung des Modells zu überwachen, sein Verhalten zu verfolgen und sicherzustellen, dass es in der Produktionsumgebung wie erwartet funktioniert.
Dies gilt nicht nur für LLMs, sondern für alle realen ML-Modelle.

Hier sind einige wichtige Tools und Techniken zum Protokollieren im Kontext von LLMs.
#1) Truera
Truera ist nicht nur eine Protokollierungslösung.


Stattdessen bietet es auch zusätzliche Möglichkeiten zum Testen und Bewerten von LLMs.
Dadurch handelt es sich um eine viel umfassendere Lösung zur Beobachtung, die Tools zur Verfolgung der Produktionsleistung, zur Minimierung von Problemen wie Halluzinationen und zur Gewährleistung verantwortungsvoller KI-Praktiken bietet.
Hier sind einige Hauptfunktionen:
LLM-Beobachtbarkeit : TruEra bietet detaillierte Beobachtbarkeit für LLM-Anwendungen. Benutzer können ihre LLM-Apps mithilfe von Feedback-Funktionen und App-Tracking bewerten, was zur Leistungsoptimierung und Minimierung von Risiken wie Halluzinationen beiträgt.
Skalierbare Überwachung und Berichterstattung : Die Plattform bietet umfassende Überwachung, Berichterstattung und Warnmeldungen in Bezug auf Modellleistung, Eingaben und Ausgaben. Diese Funktion stellt sicher, dass Probleme wie Modelldrift, Überanpassung oder Verzerrung durch eine einzigartige KI-Ursachenanalyse schnell identifiziert und behoben werden.
[WICHTIG] TruLens : TruLens von TruEra ist eine Open-Source-Bibliothek, mit der Benutzer ihre LLM-Apps testen und verfolgen können.
Und mehr.
Einer der großen Vorteile von TruEra besteht darin, dass es sich nahtlos in vorhandene KI-Stacks integrieren lässt, darunter Lösungen zur Entwicklung prädiktiver Modelle wie AWS SageMaker, Microsoft Azure, Vertex.ai und mehr.
Es unterstützt außerdem die Bereitstellung in verschiedenen Umgebungen, einschließlich privater Cloud, AWS, Google oder Azure, und ist skalierbar, um große Modellvolumina zu bewältigen.
Fang hier an:
#2) Tiefenchecks


Deepchecks ist eine weitere umfassende Lösung wie TruEra, die LLM-Bewertungs-, Test- und Überwachungslösungen bereitstellt.
Die Bibliothek ist jedoch nicht nur auf LLMs beschränkt. Stattdessen nutzen viele Datenwissenschaftler und Machine-Learning-Ingenieure DeepChecks für verschiedene Machine-Learning-Modelle in unterschiedlichen Bereichen.
Allerdings ist ihr Bewertungsrahmen nicht so umfassend und gründlich wie der von Giskard, dem Tool, das wir zuvor besprochen haben.
Fang hier an:
Da dieser Artikel kurz und knapp gehalten sein sollte, haben wir nicht auf jedes einzelne verfügbare Tool eingegangen, aber wir haben die Tools vorgestellt, die für 90 % der Anwendungsfälle ausreichen.
Hier sind einige Beispiele für die Tools, auf die wir verzichtet haben.
- Schulung und Skalierung: Fairscale.
- Testen und Auswerten: TextAttack.
- Servieren: Flowise.
- Protokollierung: Gewichte und Biases, MLFlow und mehr.
Wenn Sie tiefer in viele weitere Tool-Stacks eintauchen möchten, schauen Sie sich dies an
Danke fürs Lesen!








