
























GPT-2 (XL) 1,5 milyar parametreye sahiptir ve parametreleri 16 bit hassasiyetle ~3 GB bellek tüketir.
Ancak bunu 30 GB belleğe sahip tek bir GPU üzerinde eğitmek pek mümkün değildir.


Bu, modelin belleğinin 10 katıdır ve bunun nasıl mümkün olabileceğini merak edebilirsiniz.
Bu makalenin odak noktası LLM bellek tüketimi olmasa da (
Aslında yukarıdaki örnekte, yalnızca 1,5 Milyar parametreye sahip, oldukça küçük bir model olan GPT-2 (XL)'yi ele aldık.
Burada ne olacağını hayal edebilmeniz için GPT-2 (XL) ile GPT-3'ün boyut karşılaştırması verilmiştir:


LLM eğitimini normal model eğitiminden büyük ölçüde farklı kılan şeylerden biri, bu modellerin sergilediği büyük ölçektir; bu modellerin verimli bir şekilde geliştirilmesi, eğitilmesi ve dağıtılması için önemli hesaplama kaynakları ve teknikleri gerektirir.
Tipik LLM binasının "Eğitim"den çok "Mühendislik" ile ilgili olmasının nedeni budur.
Neyse ki bugün, ilk geliştirme ve eğitimden test etme, değerlendirme, dağıtım ve günlüğe kaydetmeye kadar LLM projelerinin çeşitli aşamalarını yönetmek için tasarlanmış çeşitli özel kütüphanelerimiz ve araçlarımız var.


Bu makale, yukarıdaki şekilde gösterildiği gibi, LLM geliştirme için mevcut en iyi kütüphanelerden bazılarını, proje yaşam döngüsündeki belirli rollerine göre kategorize ederek sunmaktadır.
LLM geliştirme için çok sayıda kütüphane ve araç olmasına rağmen, benimseme, topluluk desteği, güvenilirlik, pratik kullanışlılık ve daha fazlası gibi faktörlere dayanarak listemizi nispeten kısa tutmaya ve 9 kütüphaneyi kısa listeye almaya karar verdik. Hakkında daha fazla bilgi edinmek istediğiniz kütüphanelere gitmek için içindekiler tablosunu kullanmaktan çekinmeyin.
Eğitim ve Ölçeklendirme
Gerçeklik kontrolü
#1) Megatron-LM
#2) Derin Hız
#3) YaFSDP
Test ve Değerlendirme
#1) Giskard
#2) lm-değerlendirme-koşum takımı
Dağıtım ve Çıkarım
#1) vLLM
#2) CÇeviri2
Kerestecilik
#1) Gerçek
#2) Derin kontroller
Eğitim ve Ölçeklendirme

Gerçeklik kontrolü
Ölçek göz önüne alındığında, dağıtılmış öğrenme (birden fazla GPU içeren bir eğitim prosedürü), LLM'lerin eğitiminin ön saflarında yer almaktadır.
Dağıtılmış öğrenmeyi kullanmanın açık bir yolu, verileri birden fazla GPU'ya dağıtmak, her cihazda ileri geçişi çalıştırmak ve gradyanları hesaplamaktır:

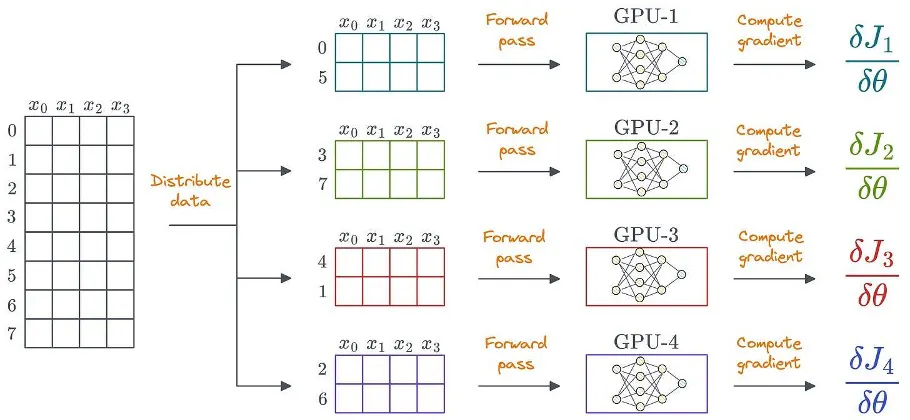
Veriler yapılandırılmamış da olabilir. Yapılandırılmış veriler yalnızca basitlik amacıyla gösterilmiştir.
Bunu başarmak için her GPU, model ağırlıklarının ve optimize edici durumlarının kendi kopyasını saklar:


Ancak en büyük sorun bu modellerin BÜYÜK olmasıdır. Modelin tamamını her GPU cihazına kopyalamak pratikte mümkün değildir.
Ayrıca optimizer durumları tarafından tüketilen bellek ne olacak? Bunu henüz değerlendirmedik bile.
Daha fazla bağlam için, Adam iyileştirici (en yaygın kullanılan iyileştiricilerden biri) tarafından tüketilen bellek, modelin ağırlığının iki katına eşdeğerdir (32 bit hassasiyette).


Gradyanları bir şekilde hesaplamayı başardığımızı varsayarsak, bir sonraki darboğaz bunları modelleri senkronize etmek için diğer GPU'lara aktarmak olacaktır.
Basit yol (aşağıda gösterilmektedir), degradelerin bir GPU'dan diğer tüm GPU'lara aktarılmasını içerir ve her aktarım, model boyutuna eşdeğerdir.


Elbette bunu optimize etmenin yolları var, ancak bunlar da bu ölçekte pratik olarak mümkün değil.
İşte bu sorunu çözen birkaç kütüphane.
#1) Megatron-LM
Megatron, geleneksel dağıtılmış öğrenmenin sınırlamalarını ele alırken büyük ölçekli transformatör modellerini eğitmek için NVIDIA tarafından geliştirilen bir optimizasyon kütüphanesidir.
Kütüphane, model paralelliği kullanılarak milyarlarca parametreli LLM'lerin eğitilebileceğini iddia ediyor. Temel fikir, modelin parametrelerini birden fazla GPU'ya dağıtmaktır.


Model paralelliği veri paralelliğiyle birleştirilebilir (yukarıdaki bölümde tartışılmıştır).
NVIDIA tarafından yayınlanan ilgili belgede, transformatör tabanlı modelleri 512 NVIDIA GPU'larda 8,3 milyar parametreye kadar verimli bir şekilde eğittikleri belirtildi.
Açıkçası günümüz modellerinin ölçeği göz önüne alındığında bu çok da büyük bir rakam değil.
Ancak bu büyük bir başarı olarak kabul edildi çünkü Megatron ilk kez 2019'da piyasaya sürüldü (GPT-3 öncesi dönem) ve o zamanlar bu kadar büyük ölçekte modeller oluşturmak doğası gereği zordu.
Aslında 2019'dan bu yana Megatron'un birkaç yinelemesi daha önerildi.
Buradan başla:
#2) Derin Hız
DeepSpeed, Microsoft tarafından geliştirilen ve dağıtılmış öğrenmenin sıkıntılı noktalarını ele alan bir optimizasyon kitaplığıdır.


Yukarıdaki tartışmada dağıtılmış öğrenme kurulumunun bol miktarda artıklık içerdiğini hatırlayın:
Her GPU aynı model ağırlıklarına sahipti.
Her GPU, optimize edicinin bir kopyasını tutar.
Her GPU, optimize edici durumlarının aynı boyutlu kopyasını depoladı.
Adından da anlaşılacağı gibi ZeRO (Sıfır Artıklık Optimize Edici) algoritması, optimize edicinin ağırlıklarını, gradyanlarını ve durumlarını tüm GPU'lar arasında tamamen bölerek bu fazlalığı tamamen ortadan kaldırır.
Bu, aşağıda gösterilmektedir:


Teknik ayrıntılara girmesek de, bu akıllı fikir, öğrenme sürecini önemli ölçüde azaltılmış bellek yüküyle hızlandırmayı mümkün kıldı.
Ayrıca, optimize edici adımını N (GPU sayısı) faktörü kadar hızlandırır.
Makale, Sıfır'ın 1 Trilyon parametrenin ötesine ölçeklenebileceğini iddia ediyor.
Ancak araştırmacılar kendi deneylerinde 12 Mayıs 2020 itibarıyla dünyanın en büyük modeli olan 17B parametreli bir model olan Turing-NLG'yi oluşturdular.
Buradan başla:
2022'de (GPT-3'ten sonra), NVIDIA (Megatron'un yaratıcısı) ve Microsoft (DeepSpeed'in yaratıcısı) birlikte çalışarak şu öneride bulundu:
Bunu, GPT-3'ten üç kat daha büyük olan 530B parametrelerine sahip Megatron-Turing NLG'yi inşa etmek için kullandılar.


#3) YaFSDP
DeepSpeed oldukça güçlü olmasına rağmen çeşitli pratik sınırlamalara da sahiptir.
Örneğin:
DeepSpeed uygulaması, iletişim ek yükleri ve veri tabanına olan güven nedeniyle büyük kümelerde verimsiz hale gelebilir.
NCCL toplu iletişim için kütüphane.Ek olarak DeepSpeed, hatalara yol açabilecek ve önemli testler gerektirebilecek eğitim hattını önemli ölçüde dönüştürüyor.
YaFSDP, YaFSDP'nin geliştirilmiş bir versiyonu olan yeni bir veri paralellik kitaplığıdır.
Özetle, FSDP ve DeepSpeed ile karşılaştırıldığında YaFSDP:
- Belleği katmanlara daha verimli şekilde dinamik olarak ayırır ve herhangi bir zamanda yalnızca gerekli miktarda belleğin kullanılmasını sağlar.
- "Yol verme etkisinden" kurtulur, böylece hesaplamalardaki aksama süresini büyük ölçüde azaltır.
- Parçalamadan önce birden çok katman parametresini tek büyük parametrelerde birleştiren
FlattenParametergibi tekniklerden yararlanır, bu da iletişim verimliliğini ve ölçeklenebilirliği daha da artırır. - Eğitim hattını etkilemeden yalnızca modeli etkileyerek daha kullanıcı dostu bir arayüz sağlar.
- Ve dahası.
Aşağıdaki tabloda YaFSDP'nin sonuçları mevcut tekniklerle karşılaştırılmaktadır:


- YaFSDP HER ZAMAN mevcut tekniklerden daha performanslıdır.
- Çok sayıda GPU ile YaFSDP, daha iyi ölçeklenebilirlik kapsamını gösteren çok daha iyi hızlanmalar elde ediyor.
Buradan başla:
Test ve Değerlendirme
Bununla eğitim ve ölçeklendirme işimiz bitti. Bir sonraki adım test etme ve değerlendirmedir:
LLM'leri değerlendirmenin doğasında olan bir zorluk, bunların Doğruluk, F1 puanı, Geri Çağırma vb. gibi birkaç ölçüme dayalı olarak değerlendirilememesidir.
Bunun yerine akıcılık, tutarlılık, olgusal doğruluk ve düşman saldırılarına karşı sağlamlık gibi birden fazla boyutta değerlendirilmeleri gerekir ve bu değerlendirme genellikle özneldir.
Çeşitli araçlar bunu yapmamıza yardımcı olur:
#1) Giskard


Giskard, Yüksek Lisans'larla ilgili aşağıdaki sorunları tespit etmemize yardımcı olan açık kaynaklı bir kütüphanedir:
- Halüsinasyonlar
- Yanlış bilgi
- Zararlılık
- Stereotipler
- Özel bilgilerin ifşa edilmesi
- Hızlı enjeksiyonlar
PyTorch, TensorFlow, HuggingFace, Scikit-Learn, XGBoost ve LangChain gibi tüm popüler çerçevelerle çalışır. Üstelik HuggingFace, Weights & Biases ve MLFlow ile de entegre edilebilir.
Buradan başla:
#2) lm-değerlendirme-koşum takımı
Evaluation Harness, LLM'leri sağlam bir değerlendirme sürecine sokan başka bir açık kaynaklı araçtır.
Temel olarak kişi, modelini hangi kriterlere göre test etmek istediğini seçebilir, bunları sistemde çalıştırabilir ve ardından sonuçları alabilir.
Mayıs 2024 itibarıyla, LLM'ler için 60'tan fazla standart akademik kritere ve özel istemler ve değerlendirme ölçümleri için kolay desteğe sahiptir, ancak Giskard'da bu zordur.
Bazı yaygın kriterler şunları içerir:
- Sorular ve cevaplar
- Çoktan seçmeli sorular
- İnsanların yapabileceğine benzer, cinsiyet önyargısını test eden görevler.
- Ve dahası.
Buradan başla:
Truera ve DeepChecks gibi birkaç araç daha var ancak uçtan uca değerlendirme ve gözlemlenebilirlik çözümleri sundukları için çok daha kapsamlılar. Bunları son bölümde ele alacağız.
LLM değerlendirmesi hakkında daha fazla ayrıntıya girmek istiyorsanız şu makaleyi öneririm:
Dağıtım ve Çıkarım
Bununla modelimizi değerlendirdik ve güvenle dağıtıma taşıdık:

"Dağıtım" derken modeli buluta itmeyi kastetmediğimizi unutmayın. Bunu herkes yapabilir.
Bunun yerine, daha çok maliyetleri azaltmak için çıkarım aşamalarında verimliliğe ulaşmakla ilgilidir.
#1) vLLM
vLLM muhtemelen LLM çıkarım verimliliğini artırmak için en iyi açık kaynaklı araçlardan biridir.


Özetle vLLM, modelin performansından ödün vermeden çıkarımı hızlandırmak için yeni bir dikkat algoritması kullanıyor.
Sonuçlar, herhangi bir model değişikliği gerektirmeden HuggingFace Transformers'a göre ~24 kat daha yüksek verim sağlayabileceğini gösteriyor.


Sonuç olarak, LLM'nin herkes için çok daha uygun fiyatlı hizmet vermesini sağlar.
Buradan başla:
#2) CÇeviri2
CTranslate2, Transformer modelleri için bir başka popüler hızlı çıkarım motorudur.
Uzun lafın kısası, kütüphane LLM'ler için aşağıdakiler gibi birçok performans optimizasyon tekniğini uygulamaktadır:
- Ağırlık nicelemesi : Niceleme, ağırlıkların hassasiyetini kayan noktadan int8 veya int16 gibi daha düşük bit temsillerine azaltır. Bu, model boyutunu ve bellek alanını önemli ölçüde azaltarak daha hızlı hesaplamaya ve daha düşük güç tüketimine olanak tanır. Üstelik matris çarpımları daha düşük duyarlıklı gösterimlerde daha hızlı çalışır:


- Katman füzyonu : Adından da anlaşılacağı gibi katman füzyonu, çıkarım aşamasında birden fazla işlemi tek bir işlemde birleştirir. Kesin teknik ayrıntılar bu makalenin ötesinde olsa da, katmanların birleştirilmesiyle hesaplama adımlarının sayısı azaltılır, bu da her katmanla ilişkili ek yükü azaltır.
- Toplu yeniden sıralama : Toplu yeniden sıralama, donanım kaynaklarının kullanımını optimize etmek için girdi gruplarını düzenlemeyi içerir. Bu teknik, benzer uzunluktaki dizilerin birlikte işlenmesini sağlayarak dolgulamayı en aza indirir ve paralel işleme verimliliğini maksimuma çıkarır.
Tekniklerin kullanılması, Transformer modellerinin hem CPU hem de GPU üzerindeki bellek kullanımını büyük ölçüde hızlandırır ve azaltır.
Buradan başla:
Kerestecilik
Model ölçeklendirildi, test edildi, üretime geçirildi ve devreye alındı ve şu anda kullanıcı isteklerini yerine getiriyor.
Ancak modelin performansını izlemek, davranışını takip etmek ve üretim ortamında beklendiği gibi çalışmasını sağlamak için sağlam kayıt mekanizmalarına sahip olmak önemlidir.
Bu sadece Yüksek Lisans'lar için değil, gerçek dünyadaki tüm makine öğrenimi modelleri için geçerlidir.

Yüksek Lisans bağlamında oturum açmak için bazı temel araç ve teknikleri burada bulabilirsiniz.
#1) Truera
Truera yalnızca bir günlük kaydı çözümü değildir.


Bunun yerine, LLM'leri test etmek ve değerlendirmek için ek yetenekler de sağlar.
Bu, onu çok daha kapsamlı bir gözlemlenebilirlik çözümü haline getiriyor; üretim performansını izlemek, halüsinasyonlar gibi sorunları en aza indirmek ve sorumlu yapay zeka uygulamaları sağlamak için araçlar sağlayan bir çözüm.
İşte bazı temel özellikler:
LLM Gözlemlenebilirliği : TruEra, LLM uygulamaları için ayrıntılı gözlemlenebilirlik sağlar. Kullanıcılar, performansın optimize edilmesine ve halüsinasyonlar gibi risklerin en aza indirilmesine yardımcı olan geri bildirim işlevlerini ve uygulama izlemeyi kullanarak Yüksek Lisans uygulamalarını değerlendirebilir.
Ölçeklenebilir İzleme ve Raporlama : Platform, model performansı, girdiler ve çıktılar açısından kapsamlı izleme, raporlama ve uyarı sunar. Bu özellik, model sapması, aşırı uyum veya önyargı gibi sorunların benzersiz yapay zeka temel neden analizi yoluyla hızlı bir şekilde tanımlanmasını ve ele alınmasını sağlar.
[ÖNEMLİ] TruLens : TruEra'nın TruLens'i, kullanıcıların Yüksek Lisans uygulamalarını test etmelerine ve takip etmelerine olanak tanıyan açık kaynaklı bir kitaplıktır.
Ve dahası.
TruEra'nın harika yanlarından biri, AWS SageMaker, Microsoft Azure, Vertex.ai ve daha fazlası gibi tahmine dayalı model geliştirme çözümleri de dahil olmak üzere mevcut AI yığınlarıyla sorunsuz bir şekilde entegre olabilmesidir.
Ayrıca özel bulut, AWS, Google veya Azure dahil olmak üzere çeşitli ortamlarda dağıtımı destekler ve yüksek model hacimlerini karşılayacak şekilde ölçeklenir.
Buradan başla:
#2) Derin kontroller


Deepchecks, LLM değerlendirme, test ve izleme çözümleri sunan TruEra gibi başka bir kapsamlı çözümdür.
Ancak kütüphane sadece Yüksek Lisans (LLM) ile sınırlı değildir. Bunun yerine birçok veri bilimci ve makine öğrenimi mühendisi, çeşitli alanlardaki çeşitli makine öğrenimi modelleri için DeepChecks'ten yararlanıyor.
Bununla birlikte, değerlendirme çerçeveleri daha önce tartıştığımız Giskard'ınki kadar kapsamlı ve kapsamlı değildir.
Buradan başla:
Bu makalenin kısa ve hızlı olmasını istediğimizden, mevcut her aracı kapsamadık ancak kullanım durumlarının %90'ı için yeterli olacak araçları sergiledik.
Burada çıkarmamaya karar verdiğimiz araçlara birkaç örnek verilmiştir.
- Eğitim ve ölçeklendirme: Adil ölçek.
- Test etme ve değerlendirme: TextAttack.
- Servis: Flowise.
- Günlük kaydı: Ağırlıklar ve Önyargılar, MLFlow ve daha fazlası.
Daha fazla araç yığınına daha derinlemesine dalmak istiyorsanız buna göz atın
Okuduğunuz için teşekkürler!








