
























GPT-2 (XL) có 1,5 tỷ tham số và các tham số của nó tiêu thụ ~3GB bộ nhớ ở độ chính xác 16 bit.
Tuy nhiên, người ta khó có thể huấn luyện nó trên một GPU có bộ nhớ 30GB .


Đó là bộ nhớ của mô hình gấp 10 lần và bạn có thể tự hỏi làm thế nào điều đó lại có thể xảy ra.
Mặc dù trọng tâm của bài viết này không phải là mức tiêu thụ bộ nhớ LLM (
Trên thực tế, trong ví dụ trên, chúng tôi đã xem xét một mô hình khá nhỏ — GPT-2 (XL), chỉ với 1,5 tỷ thông số.
Đây là so sánh kích thước của GPT-2 (XL) với GPT-3 để bạn có thể tưởng tượng điều gì sẽ xảy ra ở đó:


Một trong những điều làm cho đào tạo LLM khác biệt nhiều so với đào tạo mô hình thông thường là quy mô tuyệt đối mà các mô hình này thể hiện, đòi hỏi các kỹ thuật và nguồn lực tính toán đáng kể để phát triển, đào tạo và triển khai một cách hiệu quả.
Đó là lý do tại sao tòa nhà LLM điển hình lại thiên về “Kỹ thuật” hơn là “Đào tạo”.
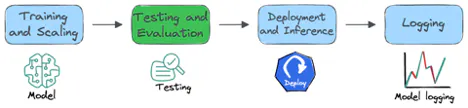
Rất may, ngày nay, chúng tôi có nhiều thư viện và công cụ chuyên dụng khác nhau được thiết kế để xử lý các giai đoạn khác nhau của dự án LLM, từ phát triển và đào tạo ban đầu đến thử nghiệm, đánh giá, triển khai và ghi nhật ký.


Bài viết này trình bày một số thư viện tốt nhất hiện có để phát triển LLM, được phân loại theo vai trò cụ thể của chúng trong vòng đời dự án, như trong hình trên.
Mặc dù có rất nhiều thư viện và công cụ để phát triển LLM, chúng tôi quyết định giữ danh sách 9 thư viện tương đối ngắn gọn và lọt vào danh sách rút gọn dựa trên các yếu tố như khả năng áp dụng, hỗ trợ cộng đồng, độ tin cậy, tính hữu ích thực tế, v.v. Vui lòng sử dụng mục lục để chuyển đến các thư viện mà bạn muốn tìm hiểu thêm.
Đào tạo và mở rộng quy mô
Kiểm tra thực tế
#1) Megatron-LM
#2) Tốc độ sâu
#3) YaFSDP
Kiểm tra và đánh giá
#1) Giskard
#2) lm-đánh giá-khai thác
Triển khai và suy luận
#1) vLLM
#2) CDịch2
Ghi nhật ký
#1) Đúng
#2) Kiểm tra sâu
Đào tạo và mở rộng quy mô

Kiểm tra thực tế
Với quy mô, học tập phân tán (một quy trình đào tạo liên quan đến nhiều GPU) được đặt lên hàng đầu trong việc đào tạo LLM.
Một cách rõ ràng để sử dụng học tập phân tán là phân phối dữ liệu trên nhiều GPU, chạy chuyển tiếp trên từng thiết bị và tính toán độ dốc:

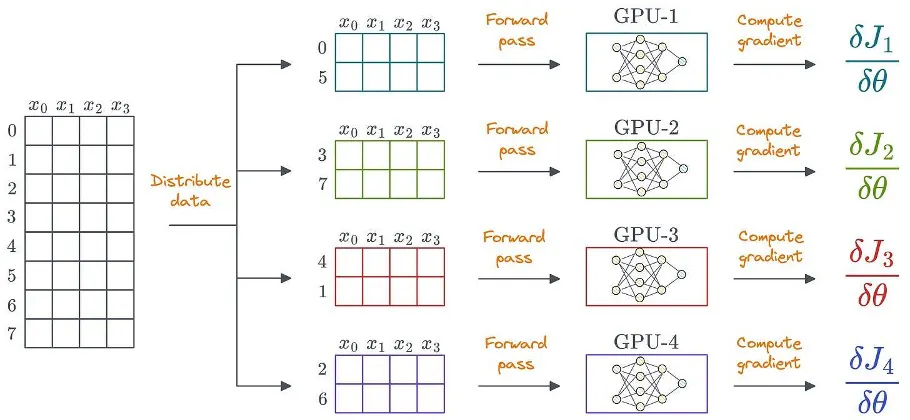
Dữ liệu cũng có thể không có cấu trúc. Dữ liệu có cấu trúc chỉ được hiển thị để đơn giản.
Để đạt được điều này, mỗi GPU lưu trữ bản sao trọng số mô hình và trạng thái tối ưu hóa của riêng mình:


Tuy nhiên, vấn đề lớn nhất là những mô hình này rất LỚN. Việc sao chép toàn bộ mô hình trên mỗi thiết bị GPU trên thực tế là không khả thi.
Ngoài ra, còn bộ nhớ được sử dụng bởi các trạng thái tối ưu hóa thì sao? Chúng tôi thậm chí còn chưa xem xét điều đó.
Để biết thêm ngữ cảnh, bộ nhớ mà trình tối ưu hóa Adam (một trong những trình tối ưu hóa được sử dụng rộng rãi nhất) sử dụng tương đương với hai lần trọng lượng của mô hình (ở độ chính xác 32 bit).


Giả sử bằng cách nào đó chúng ta đã tính toán được gradient, nút thắt tiếp theo là chuyển chúng sang các GPU khác để đồng bộ hóa mô hình.
Cách đơn giản (hiển thị bên dưới) liên quan đến việc chuyển độ dốc từ GPU này sang tất cả các GPU khác và mỗi lần chuyển đều tương đương với kích thước mô hình.


Tất nhiên, có nhiều cách để tối ưu hóa điều này, nhưng chúng thực tế không khả thi ở quy mô này.
Dưới đây là một vài thư viện giải quyết vấn đề này.
#1) Megatron-LM
Megatron là thư viện tối ưu hóa được NVIDIA phát triển để đào tạo các mô hình máy biến áp quy mô lớn đồng thời giải quyết các hạn chế của phương pháp học tập phân tán truyền thống.
Thư viện tuyên bố rằng người ta có thể huấn luyện LLM nhiều tỷ tham số bằng cách sử dụng mô hình song song . Ý tưởng cốt lõi là phân phối các tham số của mô hình trên nhiều GPU.


Song song mô hình có thể được kết hợp với song song dữ liệu (đã thảo luận ở phần trên).
Bài báo tương ứng do NVIDIA phát hành đã đề cập rằng họ đã đào tạo hiệu quả các mô hình dựa trên máy biến áp lên tới 8,3 tỷ thông số trên 512 GPU NVIDIA.
Thành thật mà nói, con số này không lớn một cách hợp lý nếu xét đến quy mô của các mô hình ngày nay.
Nhưng đó được coi là một kỳ tích lớn bởi Megatron được ra mắt lần đầu tiên vào năm 2019 (thời kỳ tiền GPT-3) và việc xây dựng những mô hình có quy mô như vậy vào thời điểm đó vốn đã khó khăn.
Trên thực tế, kể từ năm 2019, một số phiên bản Megatron khác đã được đề xuất.
Hãy bắt đầu từ đây:
#2) Tốc độ sâu
DeepSpeed là một thư viện tối ưu hóa do Microsoft phát triển nhằm giải quyết các điểm yếu của việc học tập phân tán.


Các
Hãy nhớ lại rằng trong cuộc thảo luận ở trên, thiết lập học tập phân tán có rất nhiều điểm dư thừa:
Mọi GPU đều có cùng trọng lượng mô hình.
Mỗi GPU đều duy trì một bản sao của trình tối ưu hóa.
Mọi GPU đều lưu trữ cùng một bản sao chiều của các trạng thái tối ưu hóa.
Thuật toán ZeRO (Zero Redundancy Optimizer), như tên cho thấy, loại bỏ hoàn toàn sự dư thừa này bằng cách phân tách hoàn toàn trọng số, độ dốc và trạng thái của trình tối ưu hóa giữa tất cả các GPU.
Điều này được mô tả dưới đây:


Mặc dù chúng ta sẽ không đi sâu vào chi tiết kỹ thuật nhưng ý tưởng thông minh này đã giúp tăng tốc quá trình học tập với mức tải bộ nhớ giảm đáng kể.
Hơn nữa, nó tăng tốc bước tối ưu hóa theo hệ số N (số lượng GPU).
Bài báo tuyên bố rằng ZeRO có thể mở rộng quy mô vượt quá 1 nghìn tỷ thông số .
Tuy nhiên, trong các thí nghiệm của riêng mình, các nhà nghiên cứu đã xây dựng mô hình tham số 17B - Turing-NLG , mô hình lớn nhất trên thế giới tính đến ngày 12 tháng 5 năm 2020.
Hãy bắt đầu từ đây:
Năm 2022 (sau GPT-3), NVIDIA (tác giả của Megatron) và Microsoft (tác giả của DeepSpeed) đã cùng nhau đề xuất
Họ đã sử dụng nó để xây dựng Megatron-Turing NLG, có thông số 530B - lớn gấp ba lần GPT-3.


#3) YaFSDP
Mặc dù DeepSpeed khá mạnh mẽ nhưng nó cũng có nhiều hạn chế thực tế.
Ví dụ:
Việc triển khai DeepSpeed có thể trở nên kém hiệu quả trên các cụm lớn do chi phí liên lạc và sự phụ thuộc vào
NCCL thư viện dành cho truyền thông tập thể.Ngoài ra, DeepSpeed biến đổi đáng kể quy trình đào tạo, có thể gây ra lỗi và yêu cầu thử nghiệm đáng kể.
YaFSDP là thư viện song song dữ liệu mới, là phiên bản nâng cao của
Tóm lại, so với FSDP và DeepSpeed, YaFSDP:
- Tự động phân bổ bộ nhớ cho các lớp hiệu quả hơn, đảm bảo rằng chỉ sử dụng lượng bộ nhớ cần thiết tại bất kỳ thời điểm nào.
- Loại bỏ "hiệu ứng nhường đường", do đó giảm đáng kể thời gian ngừng hoạt động trong quá trình tính toán.
- Tận dụng các kỹ thuật như
FlattenParameter, kết hợp nhiều tham số lớp thành các tham số lớn duy nhất trước khi phân chia, giúp nâng cao hơn nữa hiệu quả giao tiếp và khả năng mở rộng. - Duy trì giao diện thân thiện hơn với người dùng bằng cách chỉ ảnh hưởng đến mô hình chứ không ảnh hưởng đến quy trình đào tạo.
- Và hơn thế nữa.
Bảng sau so sánh kết quả của YaFSDP với các kỹ thuật hiện tại:


- YaFSDP LUÔN LUÔN có hiệu suất cao hơn các kỹ thuật hiện tại.
- Với số lượng GPU lớn, YaFSDP đạt được tốc độ tốt hơn nhiều, điều này cho thấy khả năng mở rộng tốt hơn của nó.
Hãy bắt đầu từ đây:
Kiểm tra và đánh giá
Như vậy là chúng ta đã hoàn tất việc đào tạo và mở rộng quy mô. Bước tiếp theo là kiểm tra và đánh giá:
Một thách thức cố hữu khi đánh giá LLM là chúng không thể được đánh giá dựa trên một số số liệu như Độ chính xác, điểm F1, Khả năng thu hồi, v.v.
Thay vào đó, chúng phải được đánh giá trên nhiều khía cạnh như tính trôi chảy, mạch lạc, độ chính xác thực tế và khả năng chống lại các cuộc tấn công đối nghịch và việc đánh giá này thường mang tính chủ quan.
Nhiều công cụ khác nhau giúp chúng tôi thực hiện việc này:
#1) Giskard


Giskard là một thư viện mã nguồn mở giúp chúng tôi phát hiện các vấn đề sau với LLM:
- Ảo giác
- Thông tin sai lệch
- Tác hại
- khuôn mẫu
- Tiết lộ thông tin riêng tư
- tiêm nhắc nhở
Nó hoạt động với tất cả các khung phổ biến, chẳng hạn như PyTorch, TensorFlow, HuggingFace, Scikit-Learn, XGBoost và LangChain. Hơn nữa, người ta cũng có thể tích hợp nó với HuggingFace, Weights & Biases và MLFlow.
Hãy bắt đầu từ đây:
#2) lm-đánh giá-khai thác
Khai thác đánh giá là một công cụ nguồn mở khác giúp LLM trải qua quy trình đánh giá mạnh mẽ.
Về cơ bản, người ta có thể chọn điểm chuẩn mà họ muốn kiểm tra mô hình của mình, chạy chúng trong hệ thống và sau đó nhận kết quả.
Tính đến tháng 5 năm 2024, nó có hơn 60 điểm chuẩn học thuật tiêu chuẩn cho LLM và hỗ trợ dễ dàng cho các lời nhắc tùy chỉnh và chỉ số đánh giá, điều này rất khó với Giskard.
Một số điểm chuẩn phổ biến bao gồm:
- Câu hỏi và câu trả lời
- Câu hỏi trắc nghiệm
- Nhiệm vụ kiểm tra sự thiên vị về giới tính, tương tự như những gì con người có thể làm.
- Và hơn thế nữa.
Hãy bắt đầu từ đây:
Có một số công cụ khác như Truera và DeepChecks, nhưng chúng toàn diện hơn nhiều vì chúng cung cấp các giải pháp đánh giá và quan sát toàn diện. Chúng tôi sẽ đề cập đến chúng trong phần cuối cùng.
Nếu bạn muốn biết thêm chi tiết về đánh giá LLM, tôi khuyên bạn nên viết bài này:
Triển khai và suy luận
Cùng với đó, chúng tôi đã đánh giá mô hình của mình và chúng tôi đã tự tin chuyển nó sang triển khai:

Lưu ý rằng khi chúng tôi nói “triển khai”, chúng tôi không có nghĩa là đẩy mô hình lên đám mây. Bất cứ ai cũng có thể làm điều đó.
Thay vào đó, vấn đề quan trọng hơn là đạt được hiệu quả trong các giai đoạn suy luận để giảm chi phí.
#1) vLLM
vLLM có thể là một trong những công cụ nguồn mở tốt nhất để tăng hiệu quả suy luận LLM.


Tóm lại, vLLM sử dụng thuật toán chú ý mới để tăng tốc độ suy luận mà không ảnh hưởng đến hiệu suất của mô hình.
Kết quả cho thấy nó có thể mang lại thông lượng cao hơn ~24 lần so với HuggingFace Transformers mà không yêu cầu bất kỳ thay đổi mô hình nào.


Kết quả là, nó làm cho việc phục vụ LLM trở nên hợp lý hơn nhiều đối với mọi người.
Hãy bắt đầu từ đây:
#2) CDịch2
CTranslate2 là một công cụ suy luận nhanh phổ biến khác dành cho các mô hình Transformer.
Tóm lại, thư viện triển khai nhiều kỹ thuật tối ưu hóa hiệu suất cho LLM, chẳng hạn như:
- Lượng tử hóa trọng số : Lượng tử hóa làm giảm độ chính xác của trọng số từ biểu diễn dấu phẩy động đến biểu diễn bit thấp hơn, chẳng hạn như int8 hoặc int16. Điều này làm giảm đáng kể kích thước mô hình và dung lượng bộ nhớ, cho phép tính toán nhanh hơn và tiêu thụ điện năng thấp hơn. Hơn nữa, phép nhân ma trận cũng chạy nhanh hơn dưới các biểu diễn có độ chính xác thấp hơn:


- Hợp nhất lớp : Như tên cho thấy, hợp nhất lớp kết hợp nhiều thao tác thành một thao tác duy nhất trong giai đoạn suy luận. Mặc dù các thông tin kỹ thuật chính xác nằm ngoài bài viết này nhưng số bước tính toán sẽ giảm đi bằng cách hợp nhất các lớp, giúp giảm chi phí hoạt động liên quan đến mỗi lớp.
- Sắp xếp lại hàng loạt : Sắp xếp lại hàng loạt liên quan đến việc tổ chức các lô đầu vào để tối ưu hóa việc sử dụng tài nguyên phần cứng. Kỹ thuật này đảm bảo rằng các chuỗi có độ dài tương tự nhau được xử lý cùng nhau, giảm thiểu phần đệm và tối đa hóa hiệu quả xử lý song song.
Việc sử dụng các kỹ thuật giúp tăng tốc đáng kể và giảm mức sử dụng bộ nhớ của các mẫu Transformer, cả trên CPU và GPU.
Hãy bắt đầu từ đây:
Ghi nhật ký
Mô hình đã được thu nhỏ, thử nghiệm, sản xuất và triển khai và hiện đang xử lý các yêu cầu của người dùng.
Tuy nhiên, điều cần thiết là phải có cơ chế ghi nhật ký mạnh mẽ để giám sát hiệu suất của mô hình, theo dõi hành vi của mô hình và đảm bảo mô hình hoạt động như mong đợi trong môi trường sản xuất.
Điều này không chỉ áp dụng cho LLM mà còn áp dụng cho tất cả các mô hình ML trong thế giới thực.

Dưới đây là một số công cụ và kỹ thuật cần thiết để đăng nhập trong bối cảnh LLM.
#1) Đúng
Truera không chỉ là một giải pháp ghi nhật ký.


Thay vào đó, nó cũng cung cấp các khả năng bổ sung để kiểm tra và đánh giá LLM.
Điều này làm cho nó trở thành một giải pháp có khả năng quan sát toàn diện hơn nhiều — một giải pháp cung cấp các công cụ để theo dõi hiệu suất sản xuất, giảm thiểu các vấn đề như ảo giác và đảm bảo thực hành AI có trách nhiệm.
Dưới đây là một số tính năng chính:
Khả năng quan sát LLM : TruEra cung cấp khả năng quan sát chi tiết cho các ứng dụng LLM. Người dùng có thể đánh giá ứng dụng LLM của mình bằng chức năng phản hồi và theo dõi ứng dụng, giúp tối ưu hóa hiệu suất và giảm thiểu rủi ro như ảo giác.
Giám sát và báo cáo có thể mở rộng : Nền tảng này cung cấp khả năng giám sát, báo cáo và cảnh báo toàn diện về hiệu suất, đầu vào và đầu ra của mô hình. Tính năng này đảm bảo rằng mọi vấn đề như sai lệch mô hình, trang bị quá mức hoặc sai lệch đều nhanh chóng được xác định và giải quyết thông qua phân tích nguyên nhân gốc rễ duy nhất của AI.
[QUAN TRỌNG] TruLens : TruLens của TruEra là một thư viện mã nguồn mở cho phép người dùng kiểm tra và theo dõi các ứng dụng LLM của họ.
Và hơn thế nữa.
Một trong những điều tuyệt vời về TruEra là nó có thể tích hợp liền mạch với các nhóm AI hiện có, bao gồm các giải pháp phát triển mô hình dự đoán như AWS SageMaker, Microsoft Azure, Vertex.ai, v.v.
Nó cũng hỗ trợ triển khai trong nhiều môi trường khác nhau, bao gồm đám mây riêng, AWS, Google hoặc Azure và mở rộng quy mô để đáp ứng khối lượng mô hình cao.
Hãy bắt đầu từ đây:
#2) Kiểm tra sâu


Deepchecks là một giải pháp toàn diện khác như TruEra, cung cấp các giải pháp đánh giá, thử nghiệm và giám sát LLM.
Tuy nhiên, thư viện không chỉ giới hạn ở LLM. Thay vào đó, nhiều nhà khoa học dữ liệu và kỹ sư máy học tận dụng DeepChecks cho các mô hình máy học khác nhau trên nhiều lĩnh vực khác nhau.
Điều đó nói lên rằng, khung đánh giá của họ không toàn diện và kỹ lưỡng như Giskard, công cụ mà chúng ta đã thảo luận trước đó.
Hãy bắt đầu từ đây:
Vì muốn bài viết này ngắn gọn và nhanh chóng nên chúng tôi không đề cập đến từng công cụ riêng lẻ nhưng chúng tôi đã giới thiệu những công cụ đủ cho 90% trường hợp sử dụng.
Dưới đây là một số ví dụ về các công cụ mà chúng tôi quyết định bỏ qua.
- Đào tạo và nhân rộng: Fairscale.
- Kiểm tra và đánh giá: TextAttack.
- Phục vụ: Flowise.
- Ghi nhật ký: Trọng lượng & Xu hướng, MLFlow, v.v.
Nếu bạn muốn tìm hiểu sâu hơn về nhiều nhóm công cụ khác, hãy xem phần này
Cảm ơn vì đã đọc!








