









































































Jan 01, 1970
460 lecturas
Las bibliotecas de código abierto que debe consultar para la construcción de LLM
Demasiado Largo; Para Leer
Este artículo presenta algunas de las mejores bibliotecas disponibles para el desarrollo de LLM, categorizadas por sus funciones específicas en el ciclo de vida del proyecto.GPT-2 (XL) tiene 1.500 millones de parámetros y sus parámetros consumen ~3 GB de memoria con una precisión de 16 bits.
Sin embargo, difícilmente se puede entrenar en una sola GPU con 30 GB de memoria.
Eso es 10 veces la memoria del modelo, y quizás te preguntes cómo podría ser posible.
Si bien el enfoque de este artículo no es el consumo de memoria LLM (
De hecho, en el ejemplo anterior, consideramos un modelo bastante pequeño: GPT-2 (XL), con sólo 1,5 mil millones de parámetros.
Aquí hay una comparación de tamaños de GPT-2 (XL) con GPT-3 para que puedas imaginar lo que sucedería allí:
Una de las cosas que hace que la capacitación LLM sea muy diferente de la capacitación con modelos regular es la gran escala que exhiben estos modelos, que requieren recursos y técnicas computacionales sustanciales para desarrollarlos, entrenarlos e implementarlos de manera eficiente.
Es por eso que la construcción típica de un LLM tiene mucho más que ver con “Ingeniería” que con “Capacitación”.
Afortunadamente, hoy contamos con varias bibliotecas y herramientas especializadas diseñadas para manejar varias etapas de proyectos LLM, desde el desarrollo inicial y la capacitación hasta las pruebas, la evaluación, la implementación y el registro.
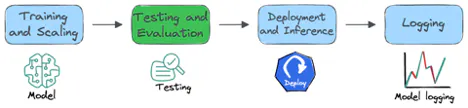
Este artículo presenta algunas de las mejores bibliotecas disponibles para el desarrollo de LLM, categorizadas por sus funciones específicas en el ciclo de vida del proyecto, como se muestra en la figura anterior.
Si bien hay muchas bibliotecas y herramientas para el desarrollo de LLM, decidimos mantener nuestra lista relativamente concisa y seleccionamos 9 bibliotecas en función de factores como la adopción, el apoyo de la comunidad, la confiabilidad, la utilidad práctica y más. Siéntase libre de utilizar la tabla de contenido para ir a las bibliotecas sobre las que desea obtener más información.
Entrenamiento y escalamiento
Una revisión de la realidad
#1) Megatrón-LM
# 2) Velocidad profunda
#3) YaFSDP
Pruebas y evaluación
#1) Giskard
# 2) arnés de evaluación de película
Despliegue e inferencia
#1) vLLM
#2) CTranslate2
Inicio sesión
#1) Truera
# 2) Verificaciones profundas
Entrenamiento y escalamiento
Una revisión de la realidad
Dada la escala, el aprendizaje distribuido (un procedimiento de capacitación que involucra múltiples GPU) está a la vanguardia de la capacitación de LLM.
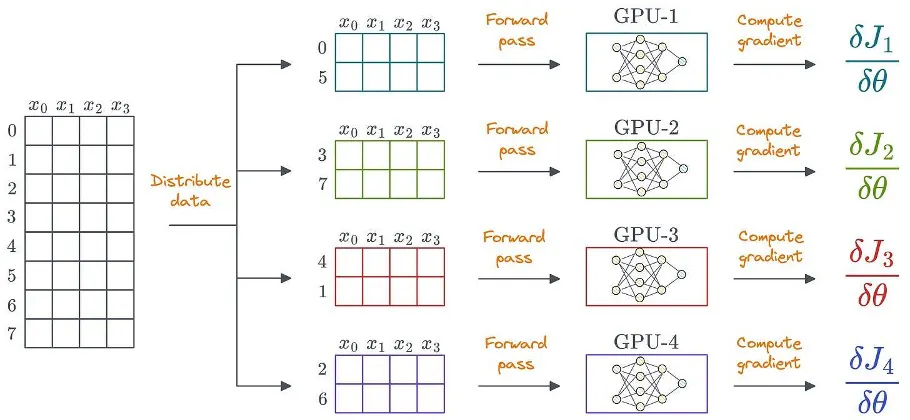
Una forma obvia de utilizar el aprendizaje distribuido es distribuir los datos entre varias GPU, ejecutar el paso directo en cada dispositivo y calcular los gradientes:
Los datos también pueden estar desestructurados. Los datos estructurados solo se muestran por simplicidad.
Para lograr esto, cada GPU almacena su propia copia de los pesos del modelo y los estados del optimizador:
Sin embargo, el mayor problema es que estos modelos son ENORMES. Replicar el modelo completo en cada dispositivo GPU es prácticamente inviable.
Además, ¿qué pasa con la memoria consumida por los estados del optimizador? Ni siquiera lo hemos considerado todavía.
Para mayor contexto, la memoria consumida por el optimizador Adam (uno de los optimizadores más utilizados) equivale a dos veces los pesos del modelo (con precisión de 32 bits).
Suponiendo que de alguna manera hayamos logrado calcular los gradientes, el siguiente cuello de botella es transferirlos a otras GPU para sincronizar los modelos.
La forma ingenua (que se muestra a continuación) implica transferir gradientes de una GPU a todas las demás GPU, y cada transferencia es equivalente al tamaño del modelo.
Por supuesto, hay formas de optimizar esto, pero también son prácticamente inviables a esta escala.
Aquí hay algunas bibliotecas que abordan este problema.
#1) Megatrón-LM
Megatron es una biblioteca de optimización desarrollada por NVIDIA para entrenar modelos de transformadores a gran escala y al mismo tiempo abordar las limitaciones del aprendizaje distribuido tradicional.
La biblioteca afirma que se pueden entrenar LLM con parámetros multimillonarios utilizando el paralelismo de modelos . La idea central es distribuir los parámetros del modelo entre múltiples GPU.
El paralelismo de modelos se puede combinar con el paralelismo de datos (que se analiza en la sección anterior).
El documento correspondiente publicado por NVIDIA mencionó que entrenaron de manera eficiente modelos basados en transformadores con hasta 8,3 mil millones de parámetros en 512 GPU NVIDIA.
Francamente, esto no es razonablemente grande, considerando la escala de los modelos actuales.
Pero se consideró una gran hazaña porque Megatron se lanzó por primera vez en 2019 (era anterior a GPT-3) y construir modelos de tal escala era intrínsecamente difícil en ese entonces.
De hecho, desde 2019 se han propuesto algunas iteraciones más de Megatron.
Comience aquí:
# 2) Velocidad profunda
DeepSpeed es una biblioteca de optimización desarrollada por Microsoft que aborda los puntos débiles del aprendizaje distribuido.
El
Recuerde que en la discusión anterior, la configuración de aprendizaje distribuido implicó mucha redundancia:
Cada GPU tenía los mismos pesos de modelo.
Cada GPU mantuvo una copia del optimizador.
Cada GPU almacenó la misma copia dimensional de los estados del optimizador.
El algoritmo ZeRO (Zero Redundancy Optimizer), como su nombre indica, elimina por completo esta redundancia al dividir completamente los pesos, gradientes y estados del optimizador entre todas las GPU.
Esto se muestra a continuación:
Aunque no entraremos en detalles técnicos, esta inteligente idea hizo posible acelerar el proceso de aprendizaje con una carga de memoria significativamente reducida.
Además, acelera el paso del optimizador en un factor de N (número de GPU).
El documento afirma que ZeRO puede escalar más allá de 1 billón de parámetros .
Sin embargo, en sus propios experimentos, los investigadores construyeron un modelo de parámetros 17B: Turing-NLG , el modelo más grande del mundo al 12 de mayo de 2020.
Comience aquí:
En 2022 (después de GPT-3), NVIDIA (el creador de Megatron) y Microsoft (el creador de DeepSpeed) trabajaron juntos para proponer
Lo usaron para construir Megatron-Turing NLG, que tenía parámetros 530B, tres veces más grande que GPT-3.
#3) YaFSDP
Si bien DeepSpeed es bastante potente, también posee varias limitaciones prácticas.
Por ejemplo:
La implementación de DeepSpeed puede volverse ineficiente en clústeres grandes debido a los gastos generales de comunicación y la dependencia de la
NCCL Biblioteca para comunicaciones colectivas.Además, DeepSpeed transforma significativamente el proceso de capacitación, lo que puede introducir errores y requerir pruebas importantes.
YaFSDP es una nueva biblioteca de paralelismo de datos que es una versión mejorada de
En pocas palabras, en comparación con FSDP y DeepSpeed, YaFSDP:
- Asigna dinámicamente memoria para capas de manera más eficiente, asegurando que solo se use la cantidad necesaria de memoria en un momento dado.
- Elimina el "efecto ceder", reduciendo así en gran medida el tiempo de inactividad en los cálculos.
- Aprovecha técnicas como
FlattenParameter, que combina múltiples parámetros de capa en parámetros únicos grandes antes de la fragmentación, lo que mejora aún más la eficiencia y la escalabilidad de la comunicación. - Mantiene una interfaz más fácil de usar al afectar solo al modelo, pero no al proceso de capacitación.
- Y más.
La siguiente tabla compara los resultados de YaFSDP con las técnicas actuales:
- YaFSDP SIEMPRE tiene más rendimiento que las técnicas actuales.
- Con una gran cantidad de GPU, YaFSDP logra aceleraciones mucho mejores, lo que muestra su alcance para una mejor escalabilidad.
Comience aquí:
Pruebas y evaluación
Con eso, hemos terminado con la capacitación y el escalamiento. El siguiente paso es la prueba y la evaluación:
Un desafío inherente a la evaluación de LLM es que no se pueden evaluar en función de algunas métricas como precisión, puntuación F1, recuperación, etc.
En cambio, deben evaluarse en múltiples dimensiones, como fluidez, coherencia, precisión fáctica y solidez ante ataques adversarios, y esta evaluación suele ser subjetiva.
Varias herramientas nos ayudan a hacer esto:
#1) Giskard
Giskard es una biblioteca de código abierto que nos ayuda a detectar los siguientes problemas con los LLM:
- Alucinaciones
- Desinformación
- Nocividad
- Estereotipos
- Divulgaciones de información privada
- inyecciones inmediatas
Funciona con todos los marcos populares, como PyTorch, TensorFlow, HuggingFace, Scikit-Learn, XGBoost y LangChain. Además, también se puede integrar con HuggingFace, Weights & Biases y MLFlow.
Comience aquí:
# 2) arnés de evaluación de película
Evaluación Arnés es otra herramienta de código abierto que somete a los LLM a un sólido proceso de evaluación.
Básicamente, uno puede elegir con qué puntos de referencia le gustaría probar su modelo, ejecutarlos en el sistema y luego recibir los resultados.
En mayo de 2024, tiene más de 60 puntos de referencia académicos estándar para LLM y soporte sencillo para indicaciones personalizadas y métricas de evaluación, lo cual es difícil con Giskard.
Algunos puntos de referencia comunes incluyen:
- Preguntas y respuestas
- Preguntas de respuestas múltiples
- Tareas que ponen a prueba los prejuicios de género, similares a las que los humanos podrían hacer.
- Y más.
Comience aquí:
Hay algunas herramientas más, como Truera y DeepChecks, pero son mucho más completas porque brindan soluciones de observación y evaluación de un extremo a otro. Los cubriremos en la última sección.
Si desea profundizar en más detalles sobre la evaluación LLM, le recomiendo este artículo:
Despliegue e inferencia
Con eso, hemos evaluado nuestro modelo y lo hemos movido con confianza a su implementación:
Tenga en cuenta que cuando decimos "implementación" no nos referimos a llevar el modelo a la nube. Cualquiera puede hacer eso.
En cambio, se trata más de lograr eficiencia durante las etapas de inferencia para reducir costos.
#1) vLLM
vLLM es posiblemente una de las mejores herramientas de código abierto para aumentar la eficiencia de la inferencia de LLM.
En pocas palabras, vLLM utiliza un algoritmo de atención novedoso para acelerar la inferencia sin comprometer el rendimiento del modelo.
Los resultados sugieren que puede ofrecer un rendimiento ~24 veces mayor que los HuggingFace Transformers sin requerir ningún cambio de modelo.
Como resultado, hace que el LLM sea mucho más asequible para todos.
Comience aquí:
#2) CTranslate2
CTranslate2 es otro motor de inferencia rápida popular para modelos Transformer.
En pocas palabras, la biblioteca implementa muchas técnicas de optimización del rendimiento para LLM, como:
- Cuantización de pesos : la cuantización reduce la precisión de los pesos desde representaciones de punto flotante a representaciones de bits inferiores, como int8 o int16. Esto reduce significativamente el tamaño del modelo y el uso de memoria, lo que permite un cálculo más rápido y un menor consumo de energía. Además, las multiplicaciones de matrices también se ejecutan más rápido en representaciones de menor precisión:
- Fusión de capas : como sugiere el nombre, la fusión de capas combina múltiples operaciones en una sola operación durante la fase de inferencia. Si bien los detalles técnicos exactos están más allá de este artículo, la cantidad de pasos computacionales se reduce al fusionar capas, lo que reduce la sobrecarga asociada con cada capa.
- Reordenamiento por lotes : el reordenamiento por lotes implica organizar los lotes de entrada para optimizar el uso de los recursos de hardware. Esta técnica garantiza que se procesen juntas longitudes similares de secuencias, minimizando el relleno y maximizando la eficiencia del procesamiento paralelo.
El uso de técnicas acelera y reduce drásticamente el uso de memoria de los modelos Transformer, tanto en CPU como en GPU.
Comience aquí:
Inicio sesión
El modelo ha sido ampliado, probado, producido e implementado y ahora está manejando las solicitudes de los usuarios.
Sin embargo, es esencial contar con mecanismos de registro sólidos para monitorear el desempeño del modelo, rastrear su comportamiento y garantizar que funcione como se espera en el entorno de producción.
Esto se aplica no solo a los LLM sino a todos los modelos de ML del mundo real.
A continuación se presentan algunas herramientas y técnicas esenciales para iniciar sesión en el contexto de los LLM.
#1) Truera
Truera no es sólo una solución de registro.
En cambio, también proporciona capacidades adicionales para probar y evaluar LLM.
Esto la convierte en una solución de observabilidad mucho más completa, que proporciona herramientas para rastrear el rendimiento de la producción, minimizar problemas como las alucinaciones y garantizar prácticas responsables de IA.
Estas son algunas características clave:
Observabilidad de LLM : TruEra proporciona observabilidad detallada para aplicaciones de LLM. Los usuarios pueden evaluar sus aplicaciones LLM utilizando funciones de retroalimentación y seguimiento de aplicaciones, lo que ayuda a optimizar el rendimiento y minimizar riesgos como las alucinaciones.
Monitoreo e informes escalables : la plataforma ofrece monitoreo, informes y alertas integrales en términos de rendimiento, entradas y salidas del modelo. Esta característica garantiza que cualquier problema como la desviación del modelo, el sobreajuste o el sesgo se identifique y solucione rápidamente mediante un análisis de causa raíz único de IA.
[IMPORTANTE] TruLens : TruLens de TruEra es una biblioteca de código abierto que permite a los usuarios probar y realizar un seguimiento de sus aplicaciones LLM.
Y más.
Una de las mejores cosas de TruEra es que puede integrarse perfectamente con las pilas de IA existentes, incluidas soluciones de desarrollo de modelos predictivos como AWS SageMaker, Microsoft Azure, Vertex.ai y más.
También admite la implementación en varios entornos, incluida la nube privada, AWS, Google o Azure, y se escala para satisfacer grandes volúmenes de modelos.
Comience aquí:
# 2) Verificaciones profundas
Deepchecks es otra solución integral como TruEra, que proporciona soluciones de evaluación, prueba y monitoreo de LLM.
Sin embargo, la biblioteca no se limita solo a los LLM. En cambio, muchos científicos de datos e ingenieros de aprendizaje automático aprovechan DeepChecks para varios modelos de aprendizaje automático en diversos dominios.
Dicho esto, su marco de evaluación no es tan completo y exhaustivo como el de Giskard, la herramienta que analizamos anteriormente.
Comience aquí:
Como queríamos que este artículo fuera conciso y rápido, no cubrimos todas las herramientas disponibles, pero sí mostramos las herramientas que serán suficientes para el 90% de los casos de uso.
A continuación se muestran algunos ejemplos de las herramientas que decidimos omitir.
- Capacitación y escalamiento: Fairscale.
- Pruebas y evaluación: TextAttack.
- Servicio: Flowise.
- Registro: ponderaciones y sesgos, MLFlow y más.
Si desea profundizar en muchas más pilas de herramientas, consulte esto
¡Gracias por leer!
L O A D I N G
. . . comments & more!
. . . comments & more!



