

























GPT-2 (XL) has 1.5 billion parameters, and its parameters consume ~3GB of memory in 16-bit precision.
However, one can hardly train it on a single GPU with 30GB of memory.


That’s 10x the model’s memory, and you might wonder how that could be even possible.
While the focus of this article is not LLM memory consumption (
In fact, in the above example, we considered a pretty small model — GPT-2 (XL), with just 1.5 Billion parameters.
Here’s a size comparison of GPT-2 (XL) with GPT-3 so you can imagine what would happen there:


One of the things that make LLM training widely different from regular model training is the sheer scale these models exhibit, requiring substantial computational resources and techniques to develop, train, and deploy efficiently.
That is why typical LLM building is much more about “Engineering” than “Training.”
Thankfully, today, we have various specialized libraries and tools designed to handle various stages of LLM projects, from initial development and training to testing, evaluation, deployment, and logging.


This article presents some of the best libraries available for LLM development, categorized by their specific roles in the project lifecycle, as shown in the figure above.
While there are plenty of libraries and tools for LLM development, we decided to keep our list relatively concise and shortlisted 9 libraries based on factors such as adoption, community support, reliability, practical usefulness, and more. Feel free to use the table of contents to jump to the libraries you want to learn more about.
Training and Scaling
A reality check
#1) Megatron-LM
#2) DeepSpeed
#3) YaFSDP
Testing and Evaluation
#1) Giskard
#2) lm-evaluation-harness
Deployment and Inference
#1) vLLM
#2) CTranslate2
Logging
#1) Truera
#2) Deepchecks
Training and Scaling

A reality check
Given the scale, distributed learning (a training procedure that involves multiple GPUs) is at the forefront of training LLMs.
One obvious way to utilize distributed learning is by distributing the data across multiple GPUs, run the forward pass on each device, and compute the gradients:

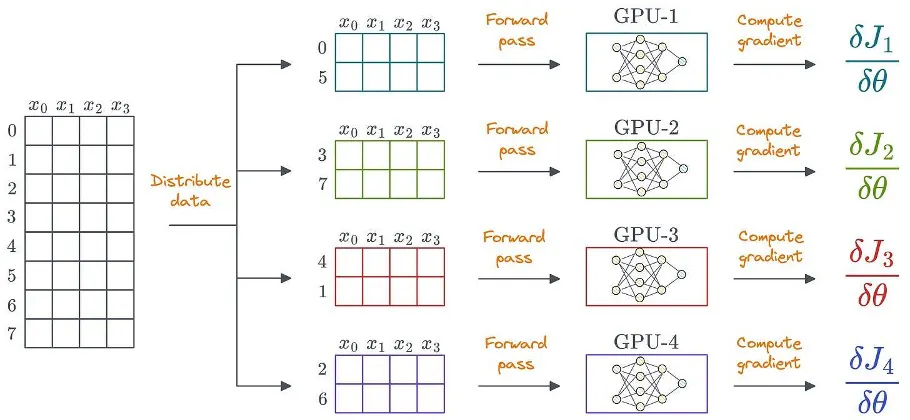
Data can be unstructured as well. Structured data is only shown for simplicity.
To achieve this, each GPU stores its own copy of model weights and optimizer states:


However, the biggest issue is that these models are HUGE. Replicating the entire model across each GPU device is practically infeasible.
Also, what about the memory consumed by optimizer states? We haven’t even considered that yet.
For more context, the memory consumed by the Adam optimizer (one of the most widely used optimizers) is equivalent to two times the model’s weights (in 32-bit precision).


Assuming we have somehow managed to compute the gradients, the next bottleneck is transferring them to other GPUs for synchronizing models.
The naive way (shown below) involves transferring gradients from one GPU to all other GPUs, and every transfer is equivalent to the model size.


Of course, there are ways to optimize this, but they are also practically infeasible at this scale.
Here are a few libraries that address this problem.
#1) Megatron-LM
Megatron is an optimization library developed by NVIDIA to train large-scale transformer models while addressing the limitations of traditional distributed learning.
The library claims that one can train multi-billion parameter LLMs using model parallelism. The core idea is to distribute the model’s parameters across multiple GPUs.


Model parallelism can be combined with data parallelism (discussed in the section above).
The corresponding paper released by NVIDIA mentioned that they efficiently trained transformer-based models up to 8.3 billion parameters on 512 NVIDIA GPUs.
Frankly speaking, this is not reasonably large, considering the scale of today’s models.
But it was considered a big feat because Megatron was first released in 2019 (pre-GPT-3 era) and building models of such a scale was inherently difficult back then.
In fact, since 2019, a few more iterations of Megatron have been proposed.
Get started here:
#2) DeepSpeed
DeepSpeed is an optimization library developed by Microsoft that addresses the pain points of distributed learning.


The
Recall that in the above discussion, the distributed learning setup involved plenty of redundancy:
-
Every GPU held the same model weights.
-
Every GPU maintained a copy of the optimizer.
-
Every GPU stored the same dimensional copy of optimizer states.
The ZeRO (Zero Redundancy Optimizer) algorithm, as the name suggests, entirely eliminates this redundancy by completely splitting the weights, gradients, and states of the optimizer between all GPUs.
This is depicted below:


While we won’t get into the technical details, this smart idea made it possible to speed up the learning process with a significantly reduced memory load.
Moreover, it speeds up the optimizer step by a factor of N (number of GPUs).
The paper claims that ZeRO can scale beyond 1 Trillion parameters.
In their own experiments, however, the researchers built a 17B-parameter model — Turing-NLG, the largest model in the world as of May 12th, 2020.
Get started here:
In 2022 (after GPT-3), NVIDIA (the creator of Megatron) and Microsoft (the creator of DeepSpeed) worked together to propose
They used it to build Megatron-Turing NLG, which had 530B parameters — three times bigger than GPT-3.


#3) YaFSDP
While DeepSpeed is quite powerful, it also possesses various practical limitations.
For instance:
-
The DeepSpeed implementation can become inefficient on large clusters due to communication overheads and reliance on the
NCCL library for collective communications. -
Additionally, DeepSpeed significantly transforms the training pipeline, which can introduce bugs and require significant testing.
YaFSDP is a new data parallelism library that is an enhanced version of
In a nutshell, compared to FSDP and DeepSpeed, YaFSDP:
- Dynamically allocates memory for layers more efficiently, ensuring that only the necessary amount of memory is used at any given time.
- Gets rid of the "give-way effect", thereby greatly reducing the downtime in computations.
- Leverages techniques like
FlattenParameter, which combines multiple layer parameters into single large parameters before sharding, which further enhances communication efficiency and scalability. - Maintains a more user-friendly interface by only affecting the model, but not the training pipeline.
- And more.
The following table compares the results of YaFSDP with current techniques:


- YaFSDP is ALWAYS more performant than current techniques.
- With a large number of GPUs, YaFSDP achieves much better speedups, which depicts its scope for better scalability.
Get started here:
Testing and Evaluation
With that, we are done with training and scaling. The next step is testing and evaluation:
An inherent challenge with evaluating LLMs is that they can’t be assessed based on a few metrics like Accuracy, F1 score, Recall, etc.
Instead, they must be assessed across multiple dimensions such as fluency, coherence, factual accuracy, and robustness to adversarial attacks, and this evaluation is often subjective.
Various tools help us do this:
#1) Giskard


Giskard is an open-source library that helps us detect the following issues with LLMs:
- Hallucinations
- Misinformation
- Harmfulness
- Stereotypes
- Private information disclosures
- Prompt injections
It works with all popular frameworks, such as PyTorch, TensorFlow, HuggingFace, Scikit-Learn, XGBoost, and LangChain. Moreover, one can also integrate it with HuggingFace, Weights & Biases, and MLFlow.
Get started here:
#2) lm-evaluation-harness
Evaluation Harness is another open-source tool that puts LLMs through a robust evaluation process.
Essentially, one can choose what benchmarks they would like to test their model against, run these in the system, and then receive results.
As of May 2024, it has over 60 standard academic benchmarks for LLMs and easy support for custom prompts and evaluation metrics, which is difficult with Giskard.
Some common benchmarks include:
- Questions and answers
- Multiple choice questions
- Tasks that test against gender bias, similar to what humans would be able to do.
- And more.
Get started here:
There are a few more tools, like Truera and DeepChecks, but they are much more comprehensive because they provide end-to-end evaluation and observability solutions. We shall cover them in the last section.
If you want to get into more details about LLM evaluation, I recommend this article:
Deployment and Inference
With that, we have evaluated our model, and we have confidently moved it to deployment:

Note that when we say “deployment,” we don’t mean pushing the model to the cloud. Anyone can do that.
Instead, it’s more about achieving efficiency during inference stages to reduce costs.
#1) vLLM
vLLM is possibly one of the best open-source tools to boost LLM inference efficiency.


In a nutshell, vLLM uses a novel attention algorithm to speed up inference without compromising the model’s performance.
Results suggest it can deliver ~24x higher throughput than HuggingFace Transformers without requiring any model changes.


As a result, it makes LLM serving much more affordable for everyone.
Get started here:
#2) CTranslate2
CTranslate2 is another popular fast inference engine for Transformer models.
Long story short, the library implements many performance optimization techniques for LLMs, such as:
- Weights quantization: Quantization reduces the precision of the weights from floating-point to lower-bit representations, such as int8 or int16. This significantly decreases the model size and memory footprint, allowing faster computation and lower power consumption. Moreover, matrix multiplications also run faster under lower-precision representations:


- Layer fusion: As the name suggests, layer fusion combines multiple operations into a single operation during the inference phase. While the exact technicalities are beyond this article, the number of computational steps is reduced by merging layers, which reduces the overhead associated with each layer.
- Batch reordering: Batch reordering involves organizing the input batches to optimize the use of hardware resources. This technique ensures that similar lengths of sequences are processed together, minimizing padding and maximizing parallel processing efficiency.
Using techniques drastically accelerates and reduces the memory usage of Transformer models, both on CPU and GPU.
Get started here:
Logging
The model has been scaled, tested, productionized, and deployed and is now handling user requests.
However, it’s essential to have robust logging mechanisms to monitor the model’s performance, track its behavior, and ensure it operates as expected in the production environment.
This applies not just to LLMs but all real-world ML models.

Here are some essential tools and techniques for logging in the context of LLMs.
#1) Truera
Truera is not just a logging solution.


Instead, it also provides additional capabilities for testing and evaluating LLMs.
This makes it a much more comprehensive observability solution — one that provides tools to track production performance, minimize issues like hallucinations, and ensure responsible AI practices.
Here are some key features:
-
LLM Observability: TruEra provides detailed observability for LLM applications. Users can evaluate their LLM apps using feedback functions and app tracking, which helps optimize performance and minimize risks like hallucinations.
-
Scalable Monitoring and Reporting: The platform offers comprehensive monitoring, reporting, and alerting in terms of model performance, inputs, and outputs. This feature ensures that any issues like model drift, overfitting, or bias are quickly identified and addressed through unique AI root cause analysis.
-
[IMPORTANT] TruLens: TruEra’s TruLens is an open-source library that allows users to test and track their LLM apps.
-
And more.
One of the great things about TruEra is that it can integrate seamlessly with existing AI stacks, including predictive model development solutions like AWS SageMaker, Microsoft Azure, Vertex.ai, and more.
It also supports deployment in various environments, including private cloud, AWS, Google, or Azure, and scales to meet high model volumes.
Get started here:
#2) Deepchecks


Deepchecks is another comprehensive solution like TruEra, which provides LLM evaluation, testing, and monitoring solutions.
However, the library is not just limited to LLMs. Instead, many data scientists and machine learning engineers leverage DeepChecks for various machine learning models across various domains.
That said, their evaluation framework is not as comprehensive and thorough as that of Giskard, the tool we discussed earlier.
Get started here:
Since we wanted this article to be concise and quick, we didn’t cover every single tool out there, but we did showcase the tools that will be sufficient for 90% of use cases.
Here are a few examples of the tools we decided to omit.
- Training and scaling: Fairscale.
- Testing and evaluation: TextAttack.
- Serving: Flowise.
- Logging: Weights & Biases, MLFlow, and more.
If you want to dive deeper into many more tool stacks, check out this
Thanks for reading!












