
























GPT-2 (XL) には 15 億のパラメータがあり、そのパラメータは 16 ビット精度で約 3 GB のメモリを消費します。
しかし、 30GBのメモリを搭載した単一の GPU でトレーニングすることはほとんど不可能です。


これはモデルのメモリの 10 倍であり、それがどのように可能なのか疑問に思うかもしれません。
この記事の焦点はLLMのメモリ消費量ではないが(
実際、上記の例では、わずか 15 億個のパラメータを持つ非常に小さなモデル、GPT-2 (XL) を検討しました。
GPT-2 (XL) と GPT-3 のサイズ比較を以下に示します。何が起こるか想像できます。


LLM トレーニングが通常のモデル トレーニングと大きく異なる点の 1 つは、これらのモデルが示す規模の大きさです。効率的に開発、トレーニング、展開するには、かなりの計算リソースとテクニックが必要です。
そのため、典型的な LLM の構築では、「トレーニング」よりも「エンジニアリング」に重点が置かれます。
幸いなことに、現在では、初期開発とトレーニングからテスト、評価、展開、ログ記録まで、LLM プロジェクトのさまざまな段階を処理するために設計されたさまざまな専門ライブラリとツールがあります。


この記事では、上の図に示すように、プロジェクト ライフサイクルにおける特定の役割別に分類された、LLM 開発に使用できる最適なライブラリをいくつか紹介します。
LLM 開発用のライブラリやツールは数多くありますが、私たちはリストを比較的簡潔にすることにし、採用、コミュニティ サポート、信頼性、実用性などの要素に基づいて 9 つのライブラリを絞り込みました。目次を使用して、詳細を知りたいライブラリに自由にジャンプしてください。
トレーニングとスケーリング
現実を直視する
#1) メガトロン-LM
#2) ディープスピード
#3) ヤFSDP
テストと評価
#1) ギスカード
#2) lm評価ハーネス
展開と推論
#1) vLLM
#2) CTranslate2
ログ記録
#1) トゥルーラ
#2) ディープチェック
トレーニングとスケーリング

現実を直視する
規模を考えると、分散学習 (複数の GPU を使用するトレーニング手順) が LLM のトレーニングの最前線にあります。
分散学習を活用する明らかな方法の 1 つは、データを複数の GPU に分散し、各デバイスでフォワード パスを実行し、勾配を計算することです。

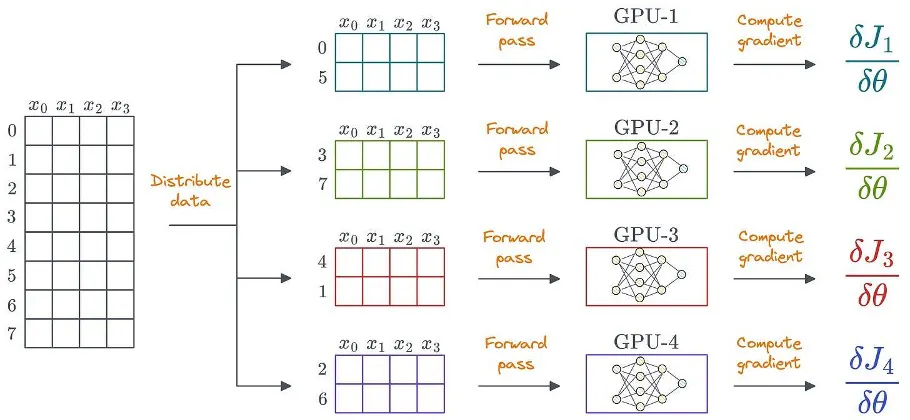
データは非構造化である場合もあります。構造化データは、簡潔にするためにのみ示されています。
これを実現するために、各 GPU はモデルの重みとオプティマイザーの状態の独自のコピーを保存します。


しかし、最大の問題は、これらのモデルが非常に大きいことです。各 GPU デバイス間でモデル全体を複製することは、事実上不可能です。
また、オプティマイザーの状態によって消費されるメモリについてはどうでしょうか? まだそれについて考慮していません。
さらに詳しく説明すると、Adam オプティマイザー (最も広く使用されているオプティマイザーの 1 つ) によって消費されるメモリは、モデルの重みの 2 倍 (32 ビット精度) に相当します。


何らかの方法で勾配を計算できたと仮定すると、次のボトルネックはモデルを同期するために勾配を他の GPU に転送することです。
単純な方法 (以下に示す) では、1 つの GPU から他のすべての GPU に勾配を転送し、すべての転送はモデル サイズに相当します。


もちろん、これを最適化する方法はありますが、この規模では実質的に実行不可能です。
この問題に対処するライブラリをいくつか紹介します。
#1) メガトロン-LM
Megatron は、従来の分散学習の限界に対処しながら大規模なトランスフォーマー モデルをトレーニングするために NVIDIA が開発した最適化ライブラリです。
このライブラリは、モデル並列処理を使用して数十億のパラメータを持つ LLM をトレーニングできると主張しています。中心となるアイデアは、モデルのパラメータを複数の GPU に分散することです。


モデルの並列処理は、データの並列処理 (上記のセクションで説明) と組み合わせることができます。
NVIDIA が発表した関連論文では、512 個の NVIDIA GPU で最大83 億のパラメータを持つトランスフォーマーベースのモデルを効率的にトレーニングしたことが述べられています。
率直に言って、今日のモデルの規模を考えると、これはそれほど大きいとは言えません。
しかし、メガトロンが最初にリリースされたのは2019年(GPT-3以前)であり、当時はこのような規模のモデルを構築することは本質的に困難だったため、これは大きな偉業と見なされました。
実際、2019年以降、メガトロンのさらにいくつかのバージョンが提案されてきました。
ここから始めましょう:
#2) ディープスピード
DeepSpeed は、分散学習の問題点を解決するために Microsoft が開発した最適化ライブラリです。


の
上記の説明では、分散学習の設定に多くの冗長性が含まれていたことを思い出してください。
すべての GPU は同じモデルの重みを保持していました。
各 GPU はオプティマイザーのコピーを保持していました。
各 GPU は、オプティマイザー状態の同じ次元のコピーを保存しました。
ZeRO (Zero Redundancy Optimizer) アルゴリズムは、その名前が示すように、オプティマイザーの重み、勾配、状態をすべての GPU 間で完全に分割することにより、この冗長性を完全に排除します。
これを以下に示します。


技術的な詳細には立ち入りませんが、この賢いアイデアにより、メモリ負荷を大幅に削減しながら学習プロセスを高速化することが可能になりました。
さらに、最適化ステップが N 倍 (GPU の数) に高速化されます。
この論文では、ZeRO は1 兆パラメータを超えて拡張できると主張しています。
しかし、研究者たちは独自の実験で、170億パラメータのモデル、つまりTuring-NLGを構築しました。これは2020年5月12日時点で世界最大のモデルです。
ここから始めましょう:
2022年(GPT-3の後)、NVIDIA(Megatronの開発者)とMicrosoft(DeepSpeedの開発者)が協力して提案した。
彼らはこれを活用して、GPT-3 の 3 倍の 530B パラメータを持つ Megatron-Turing NLG を構築しました。


#3)ヤFSDP
DeepSpeed は非常に強力ですが、さまざまな実用的な制限もあります。
例えば:
DeepSpeedの実装は、通信オーバーヘッドと
国立公文書館 集団コミュニケーションのためのライブラリ。さらに、DeepSpeed はトレーニング パイプラインを大幅に変更するため、バグが発生し、大規模なテストが必要になる可能性があります。
YaFSDPは、次の拡張版である新しいデータ並列処理ライブラリです。
一言で言えば、FSDP および DeepSpeed と比較すると、YaFSDP は次のようになります。
- レイヤーのメモリをより効率的に動的に割り当て、必要な量のメモリのみが常に使用されるようにします。
- 「ギブウェイ効果」を排除し、計算のダウンタイムを大幅に短縮します。
-
FlattenParameterなどのテクニックを活用します。このテクニックは、シャーディングの前に複数のレイヤー パラメータを 1 つの大きなパラメータに結合し、通信効率とスケーラビリティをさらに向上させます。 - トレーニング パイプラインではなくモデルにのみ影響を与えることで、よりユーザーフレンドリーなインターフェースを維持します。
- もっと。
次の表は、YaFSDP の結果と現在の技術の結果を比較したものです。


- YaFSDP は常に現在の技術よりもパフォーマンスが優れています。
- 多数の GPU を使用すると、YaFSDP ははるかに優れた速度向上を実現し、より優れたスケーラビリティの可能性を示します。
ここから始めましょう:
テストと評価
これで、トレーニングとスケーリングは完了です。次のステップはテストと評価です。
LLM を評価する際の固有の課題は、精度、F1 スコア、再現率などのいくつかの指標に基づいて評価できないことです。
代わりに、流暢さ、一貫性、事実の正確性、敵対的攻撃に対する堅牢性など、複数の側面から評価する必要があり、この評価は主観的になることが多いです。
これを実現するために、さまざまなツールが役立ちます。
#1) ギスカード


Giskard は、LLM に関する次の問題を検出するのに役立つオープンソース ライブラリです。
- 幻覚
- 誤報
- 有害
- ステレオタイプ
- 個人情報の開示
- 迅速な注射
PyTorch、TensorFlow、HuggingFace、Scikit-Learn、XGBoost、LangChain などのすべての一般的なフレームワークで動作します。さらに、HuggingFace、Weights & Biases、MLFlow と統合することもできます。
ここから始めましょう:
#2) lm評価ハーネス
Evaluation Harness は、LLM を堅牢な評価プロセスにかけるもう 1 つのオープンソース ツールです。
基本的に、モデルをテストするベンチマークを選択し、それをシステムで実行して結果を受け取ることができます。
2024 年 5 月現在、LLM 向けの 60 を超える標準的な学術ベンチマークを備えており、Giskard では難しいカスタム プロンプトや評価指標も簡単にサポートされています。
一般的なベンチマークには次のようなものがあります。
- 質問と回答
- 複数の選択肢の質問
- 人間が実行できるものと同様の、性別による偏見をテストするタスク。
- もっと。
ここから始めましょう:
Truera や DeepChecks などのツールは他にもいくつかありますが、これらはエンドツーエンドの評価と可観測性ソリューションを提供するため、はるかに包括的です。これらについては最後のセクションで説明します。
LLM 評価についてさらに詳しく知りたい場合は、この記事をお勧めします。
展開と推論
これで、私たちはモデルを評価し、自信を持って展開に移行しました。

ここで言う「デプロイメント」とは、モデルをクラウドにプッシュすることを意味するのではないことに注意してください。これは誰でも実行できます。
むしろ、推論段階で効率化を実現してコストを削減することが重要です。
#1) vLLM
vLLM は、LLM 推論の効率を高めるための最良のオープンソース ツールの 1 つです。


簡単に言えば、vLLM は新しいアテンション アルゴリズムを使用して、モデルのパフォーマンスを損なうことなく推論を高速化します。
結果は、モデルの変更を必要とせずに、HuggingFace Transformers よりも約 24 倍高いスループットを実現できることを示唆しています。


その結果、LLM サービスは誰にとってもはるかに手頃なものになります。
ここから始めましょう:
#2) CTranslate2
CTranslate2 は、Transformer モデル用のもう 1 つの人気のある高速推論エンジンです。
簡単に言うと、このライブラリは、次のような LLM 向けの多くのパフォーマンス最適化手法を実装しています。
- 重みの量子化: 量子化により、重みの精度が浮動小数点から int8 や int16 などの低ビット表現に削減されます。これにより、モデルのサイズとメモリ フットプリントが大幅に削減され、計算速度が向上し、消費電力が削減されます。さらに、行列の乗算も低精度表現でより高速に実行されます。


- レイヤー フュージョン: 名前が示すように、レイヤー フュージョンは推論フェーズで複数の操作を 1 つの操作に結合します。正確な技術的詳細はこの記事では説明しませんが、レイヤーをマージすることで計算ステップの数が減り、各レイヤーに関連するオーバーヘッドが削減されます。
- バッチ並べ替え: バッチ並べ替えでは、入力バッチを整理してハードウェア リソースの使用を最適化します。この手法により、同様の長さのシーケンスが一緒に処理され、パディングが最小限に抑えられ、並列処理の効率が最大化されます。
これらのテクニックを使用すると、CPU と GPU の両方で Transformer モデルのメモリ使用量が大幅に高速化され、削減されます。
ここから始めましょう:
ログ記録
モデルは拡張、テスト、実稼働、展開され、現在はユーザーのリクエストを処理しています。
ただし、モデルのパフォーマンスを監視し、その動作を追跡し、実稼働環境で期待どおりに動作することを確認するには、堅牢なログ記録メカニズムが不可欠です。
これは LLM だけでなく、すべての現実世界の ML モデルに当てはまります。

ここでは、LLM のコンテキストでログインするための重要なツールとテクニックをいくつか紹介します。
#1) トゥルーラ
Truera は単なるログ記録ソリューションではありません。


代わりに、LLM をテストおよび評価するための追加機能も提供します。
これにより、本番環境のパフォーマンスを追跡し、幻覚などの問題を最小限に抑え、責任ある AI の実践を保証するツールを提供する、より包括的な可観測性ソリューションが実現します。
主な機能は次のとおりです。
LLM の可観測性: TruEra は、LLM アプリケーションの詳細な可観測性を提供します。ユーザーは、フィードバック機能とアプリ トラッキングを使用して LLM アプリを評価できるため、パフォーマンスを最適化し、幻覚などのリスクを最小限に抑えることができます。
スケーラブルな監視とレポート: このプラットフォームは、モデルのパフォーマンス、入力、出力に関して包括的な監視、レポート、アラートを提供します。この機能により、モデルのドリフト、オーバーフィッティング、バイアスなどの問題が、独自の AI 根本原因分析を通じて迅速に特定され、対処されます。
[重要] TruLens : TruEra の TruLens は、ユーザーが LLM アプリをテストおよび追跡できるオープンソース ライブラリです。
もっと。
TruEra の優れた点の 1 つは、AWS SageMaker、Microsoft Azure、Vertex.ai などの予測モデル開発ソリューションを含む既存の AI スタックとシームレスに統合できることです。
また、プライベート クラウド、AWS、Google、Azure などのさまざまな環境での展開をサポートし、大量のモデルに対応できるように拡張できます。
ここから始めましょう:
#2) ディープチェック


Deepchecks は TruEra のようなもう 1 つの包括的なソリューションであり、LLM 評価、テスト、および監視ソリューションを提供します。
ただし、このライブラリは LLM だけに限定されるものではありません。多くのデータ サイエンティストや機械学習エンジニアが、さまざまなドメインのさまざまな機械学習モデルに DeepChecks を活用しています。
とはいえ、彼らの評価フレームワークは、先ほど説明したツールである Giskard ほど包括的かつ徹底的ではありません。
ここから始めましょう:
この記事は簡潔かつ迅速に書きたかったため、すべてのツールを網羅したわけではありませんが、90% のユースケースに十分なツールを紹介しました。
省略することにしたツールの例をいくつか示します。
- トレーニングとスケーリング: Fairscale。
- テストと評価: TextAttack。
- 提供:Flowwise。
- ログ記録: 重みとバイアス、MLFlow など。
より多くのツールスタックについてさらに詳しく知りたい場合は、こちらをご覧ください。
読んでくれてありがとう!








