
























GPT-2 (XL) tem 1,5 bilhão de parâmetros e seus parâmetros consomem aproximadamente 3 GB de memória com precisão de 16 bits.
No entanto, dificilmente é possível treiná-lo em uma única GPU com 30 GB de memória.


Isso é 10x a memória do modelo, e você pode se perguntar como isso poderia ser possível.
Embora o foco deste artigo não seja o consumo de memória do LLM (
Na verdade, no exemplo acima, consideramos um modelo bem pequeno – GPT-2 (XL), com apenas 1,5 bilhão de parâmetros.
Aqui está uma comparação de tamanho do GPT-2 (XL) com o GPT-3 para que você possa imaginar o que aconteceria lá:


Uma das coisas que tornam o treinamento LLM muito diferente do treinamento regular em modelos é a grande escala que esses modelos exibem, exigindo recursos e técnicas computacionais substanciais para desenvolver, treinar e implantar com eficiência.
É por isso que a construção típica de LLM é muito mais sobre “Engenharia” do que “Treinamento”.
Felizmente, hoje temos várias bibliotecas e ferramentas especializadas projetadas para lidar com vários estágios de projetos de LLM, desde o desenvolvimento inicial e treinamento até teste, avaliação, implantação e registro.


Este artigo apresenta algumas das melhores bibliotecas disponíveis para desenvolvimento de LLM, categorizadas por suas funções específicas no ciclo de vida do projeto, conforme mostrado na figura acima.
Embora existam muitas bibliotecas e ferramentas para o desenvolvimento de LLM, decidimos manter nossa lista relativamente concisa e selecionamos 9 bibliotecas com base em fatores como adoção, suporte da comunidade, confiabilidade, utilidade prática e muito mais. Sinta-se à vontade para usar o índice para acessar as bibliotecas sobre as quais deseja aprender mais.
Treinamento e escalonamento
Uma verificação da realidade
#1) Megatron-LM
#2) Velocidade Profunda
#3) YaFSDP
Teste e Avaliação
#1) Giskard
# 2) chicote de avaliação lm
Implantação e Inferência
#1) vLLM
#2) CTranslate2
Exploração madeireira
#1) Truera
#2) Verificações profundas
Treinamento e escalonamento

Uma verificação da realidade
Dada a escala, a aprendizagem distribuída (um procedimento de treinamento que envolve múltiplas GPUs) está na vanguarda do treinamento de LLMs.
Uma maneira óbvia de utilizar o aprendizado distribuído é distribuir os dados em várias GPUs, executar o avanço em cada dispositivo e calcular os gradientes:

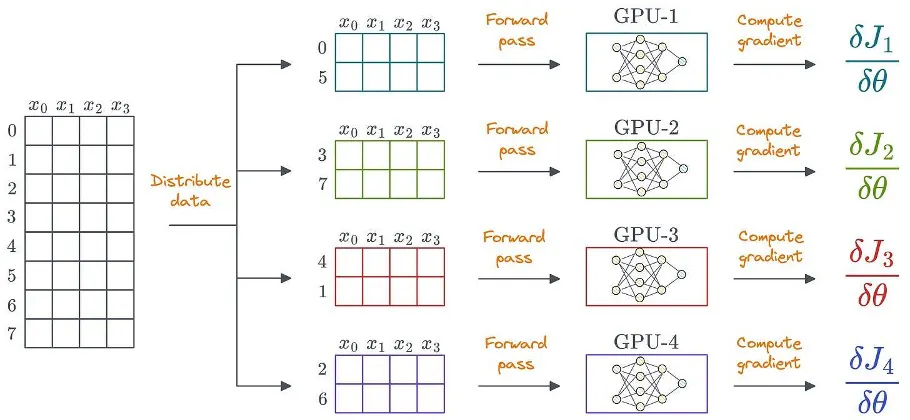
Os dados também podem ser não estruturados. Os dados estruturados são mostrados apenas para simplificar.
Para conseguir isso, cada GPU armazena sua própria cópia dos pesos do modelo e dos estados do otimizador:


No entanto, o maior problema é que esses modelos são ENORMES. Replicar o modelo inteiro em cada dispositivo GPU é praticamente inviável.
Além disso, e quanto à memória consumida pelos estados do otimizador? Nós nem consideramos isso ainda.
Para mais contexto, a memória consumida pelo otimizador Adam (um dos otimizadores mais utilizados) é equivalente a duas vezes os pesos do modelo (com precisão de 32 bits).


Supondo que de alguma forma conseguimos calcular os gradientes, o próximo gargalo é transferi-los para outras GPUs para sincronizar modelos.
A maneira ingênua (mostrada abaixo) envolve a transferência de gradientes de uma GPU para todas as outras GPUs, e cada transferência é equivalente ao tamanho do modelo.


É claro que existem maneiras de otimizar isso, mas também são praticamente inviáveis nesta escala.
Aqui estão algumas bibliotecas que resolvem esse problema.
#1) Megatron-LM
Megatron é uma biblioteca de otimização desenvolvida pela NVIDIA para treinar modelos de transformadores em grande escala e, ao mesmo tempo, abordar as limitações do aprendizado distribuído tradicional.
A biblioteca afirma que é possível treinar LLMs de vários bilhões de parâmetros usando paralelismo de modelo . A ideia central é distribuir os parâmetros do modelo entre múltiplas GPUs.


O paralelismo de modelos pode ser combinado com o paralelismo de dados (discutido na seção acima).
O artigo correspondente divulgado pela NVIDIA mencionou que eles treinaram com eficiência modelos baseados em transformadores com até 8,3 bilhões de parâmetros em 512 GPUs NVIDIA.
Falando francamente, isto não é razoavelmente grande, considerando a escala dos modelos atuais.
Mas foi considerado um grande feito porque o Megatron foi lançado pela primeira vez em 2019 (era pré-GPT-3) e construir modelos nessa escala era inerentemente difícil naquela época.
Na verdade, desde 2019, mais algumas iterações do Megatron foram propostas.
Comece aqui:
#2) Velocidade Profunda
DeepSpeed é uma biblioteca de otimização desenvolvida pela Microsoft que aborda os pontos problemáticos do aprendizado distribuído.


O
Lembre-se de que na discussão acima, a configuração de aprendizagem distribuída envolveu muita redundância:
Cada GPU mantinha os mesmos pesos de modelo.
Cada GPU manteve uma cópia do otimizador.
Cada GPU armazenou a mesma cópia dimensional dos estados do otimizador.
O algoritmo ZeRO (Zero Redundancy Optimizer), como o nome sugere, elimina totalmente essa redundância ao dividir completamente os pesos, gradientes e estados do otimizador entre todas as GPUs.
Isso está representado abaixo:


Embora não entremos em detalhes técnicos, esta ideia inteligente tornou possível acelerar o processo de aprendizagem com uma carga de memória significativamente reduzida.
Além disso, acelera a etapa do otimizador por um fator N (número de GPUs).
O artigo afirma que o ZeRO pode escalar além de 1 trilhão de parâmetros .
Em seus próprios experimentos, no entanto, os pesquisadores construíram um modelo de 17 parâmetros B – Turing-NLG , o maior modelo do mundo em 12 de maio de 2020.
Comece aqui:
Em 2022 (após GPT-3), NVIDIA (criadora do Megatron) e Microsoft (criadora do DeepSpeed) trabalharam juntas para propor
Eles o usaram para construir o Megatron-Turing NLG, que tinha parâmetros 530B – três vezes maiores que o GPT-3.


#3) YaFSDP
Embora o DeepSpeed seja bastante poderoso, ele também possui várias limitações práticas.
Por exemplo:
A implementação do DeepSpeed pode se tornar ineficiente em grandes clusters devido a sobrecargas de comunicação e à dependência do
NCCL biblioteca para comunicações coletivas.Além disso, o DeepSpeed transforma significativamente o pipeline de treinamento, o que pode introduzir bugs e exigir testes significativos.
YaFSDP é uma nova biblioteca de paralelismo de dados que é uma versão aprimorada do
Resumindo, comparado ao FSDP e DeepSpeed, o YaFSDP:
- Aloca memória dinamicamente para camadas com mais eficiência, garantindo que apenas a quantidade necessária de memória seja usada a qualquer momento.
- Elimina o "efeito de cedência", reduzindo significativamente o tempo de inatividade nos cálculos.
- Aproveita técnicas como
FlattenParameter, que combina vários parâmetros de camada em parâmetros grandes e únicos antes da fragmentação, o que aumenta ainda mais a eficiência e a escalabilidade da comunicação. - Mantém uma interface mais amigável, afetando apenas o modelo, mas não o pipeline de treinamento.
- E mais.
A tabela a seguir compara os resultados do YaFSDP com as técnicas atuais:


- O YaFSDP tem SEMPRE mais desempenho do que as técnicas atuais.
- Com um grande número de GPUs, o YaFSDP atinge velocidades muito melhores, o que demonstra seu escopo para melhor escalabilidade.
Comece aqui:
Teste e Avaliação
Com isso, concluímos o treinamento e o dimensionamento. A próxima etapa é teste e avaliação:
Um desafio inerente à avaliação de LLMs é que eles não podem ser avaliados com base em algumas métricas como precisão, pontuação F1, recall, etc.
Em vez disso, devem ser avaliados em múltiplas dimensões, como fluência, coerência, precisão factual e robustez a ataques adversários, e esta avaliação é muitas vezes subjetiva.
Várias ferramentas nos ajudam a fazer isso:
#1) Giskard


Giskard é uma biblioteca de código aberto que nos ajuda a detectar os seguintes problemas com LLMs:
- Alucinações
- Desinformação
- Nocividade
- Estereótipos
- Divulgações de informações privadas
- Injeções imediatas
Funciona com todas as estruturas populares, como PyTorch, TensorFlow, HuggingFace, Scikit-Learn, XGBoost e LangChain. Além disso, também é possível integrá-lo com HuggingFace, Weights & Biases e MLFlow.
Comece aqui:
# 2) chicote de avaliação lm
Evaluation Harness é outra ferramenta de código aberto que coloca os LLMs em um processo de avaliação robusto.
Essencialmente, pode-se escolher em quais benchmarks gostaria de testar seu modelo, executá-los no sistema e então receber os resultados.
Em maio de 2024, ele tinha mais de 60 benchmarks acadêmicos padrão para LLMs e suporte fácil para prompts personalizados e métricas de avaliação, o que é difícil com Giskard.
Alguns benchmarks comuns incluem:
- Perguntas e respostas
- Questões de múltipla escolha
- Tarefas que testam preconceitos de gênero, semelhantes ao que os humanos seriam capazes de fazer.
- E mais.
Comece aqui:
Existem mais algumas ferramentas, como Truera e DeepChecks, mas são muito mais abrangentes porque fornecem soluções completas de avaliação e observabilidade. Iremos abordá-los na última seção.
Se você quiser entrar em mais detalhes sobre a avaliação LLM, recomendo este artigo:
Implantação e Inferência
Com isso, avaliamos nosso modelo e o movemos com segurança para implantação:

Observe que quando dizemos “implantação”, não nos referimos a levar o modelo para a nuvem. Qualquer um pode fazer isso.
Em vez disso, trata-se mais de alcançar eficiência durante os estágios de inferência para reduzir custos.
#1) vLLM
vLLM é possivelmente uma das melhores ferramentas de código aberto para aumentar a eficiência de inferência do LLM.


Resumindo, o vLLM usa um novo algoritmo de atenção para acelerar a inferência sem comprometer o desempenho do modelo.
Os resultados sugerem que ele pode fornecer rendimento cerca de 24x maior do que os HuggingFace Transformers sem exigir nenhuma alteração de modelo.


Como resultado, torna o atendimento do LLM muito mais acessível para todos.
Comece aqui:
#2) CTranslate2
CTranslate2 é outro mecanismo de inferência rápida popular para modelos Transformer.
Resumindo, a biblioteca implementa muitas técnicas de otimização de desempenho para LLMs, como:
- Quantização de pesos : A quantização reduz a precisão dos pesos de representações de ponto flutuante para representações de bits inferiores, como int8 ou int16. Isso diminui significativamente o tamanho do modelo e o consumo de memória, permitindo uma computação mais rápida e menor consumo de energia. Além disso, as multiplicações de matrizes também são executadas mais rapidamente em representações de menor precisão:


- Fusão de camadas : como o nome sugere, a fusão de camadas combina múltiplas operações em uma única operação durante a fase de inferência. Embora os detalhes técnicos exatos estejam além deste artigo, o número de etapas computacionais é reduzido pela fusão de camadas, o que reduz a sobrecarga associada a cada camada.
- Reordenação de lote : A reordenação de lote envolve a organização dos lotes de entrada para otimizar o uso de recursos de hardware. Essa técnica garante que comprimentos semelhantes de sequências sejam processados juntos, minimizando o preenchimento e maximizando a eficiência do processamento paralelo.
O uso de técnicas acelera e reduz drasticamente o uso de memória dos modelos Transformer, tanto na CPU quanto na GPU.
Comece aqui:
Exploração madeireira
O modelo foi dimensionado, testado, produzido e implantado e agora está atendendo às solicitações dos usuários.
No entanto, é essencial ter mecanismos de registo robustos para monitorizar o desempenho do modelo, acompanhar o seu comportamento e garantir que funciona conforme esperado no ambiente de produção.
Isso se aplica não apenas aos LLMs, mas a todos os modelos de ML do mundo real.

Aqui estão algumas ferramentas e técnicas essenciais para registro no contexto de LLMs.
#1) Truera
Truera não é apenas uma solução de registro.


Em vez disso, também fornece recursos adicionais para testar e avaliar LLMs.
Isso o torna uma solução de observabilidade muito mais abrangente – que fornece ferramentas para rastrear o desempenho da produção, minimizar problemas como alucinações e garantir práticas responsáveis de IA.
Aqui estão alguns recursos principais:
Observabilidade LLM : TruEra fornece observabilidade detalhada para aplicações LLM. Os usuários podem avaliar seus aplicativos LLM usando funções de feedback e rastreamento de aplicativos, o que ajuda a otimizar o desempenho e minimizar riscos como alucinações.
Monitoramento e relatórios escalonáveis : a plataforma oferece monitoramento, relatórios e alertas abrangentes em termos de desempenho do modelo, entradas e saídas. Esse recurso garante que quaisquer problemas como desvio de modelo, overfitting ou viés sejam rapidamente identificados e resolvidos por meio de uma análise exclusiva de causa raiz de IA.
[IMPORTANTE] TruLens : TruLens da TruEra é uma biblioteca de código aberto que permite aos usuários testar e rastrear seus aplicativos LLM.
E mais.
Uma das melhores vantagens do TruEra é que ele pode se integrar perfeitamente às pilhas de IA existentes, incluindo soluções de desenvolvimento de modelos preditivos como AWS SageMaker, Microsoft Azure, Vertex.ai e muito mais.
Ele também oferece suporte à implantação em vários ambientes, incluindo nuvem privada, AWS, Google ou Azure, e é dimensionado para atender a grandes volumes de modelos.
Comece aqui:
#2) Verificações profundas


Deepchecks é outra solução abrangente como TruEra, que fornece soluções de avaliação, teste e monitoramento LLM.
No entanto, a biblioteca não se limita apenas aos LLMs. Em vez disso, muitos cientistas de dados e engenheiros de aprendizado de máquina utilizam o DeepChecks para vários modelos de aprendizado de máquina em vários domínios.
Dito isto, o seu quadro de avaliação não é tão abrangente e completo como o do Giskard, a ferramenta que discutimos anteriormente.
Comece aqui:
Como queríamos que este artigo fosse conciso e rápido, não cobrimos todas as ferramentas disponíveis, mas mostramos as ferramentas que serão suficientes para 90% dos casos de uso.
Aqui estão alguns exemplos das ferramentas que decidimos omitir.
- Treinamento e escalonamento: Fairscale.
- Teste e avaliação: TextAttack.
- Servindo: Flowise.
- Registro: pesos e preconceitos, MLFlow e muito mais.
Se você quiser se aprofundar em muitas outras pilhas de ferramentas, confira isto
Obrigado por ler!








