
























GPT-2 (XL) এর 1.5 বিলিয়ন প্যারামিটার রয়েছে এবং এর পরামিতিগুলি 16-বিট নির্ভুলতায় ~3GB মেমরি ব্যবহার করে।
যাইহোক, 30GB মেমরি সহ একক GPU-তে কেউ এটিকে খুব কমই প্রশিক্ষণ দিতে পারে।


এটি মডেলের মেমরির 10x, এবং আপনি ভাবতে পারেন যে এটি কীভাবে সম্ভব হতে পারে।
যদিও এই নিবন্ধের ফোকাস এলএলএম মেমরি খরচ নয় (
প্রকৃতপক্ষে, উপরের উদাহরণে, আমরা একটি সুন্দর ছোট মডেল বিবেচনা করেছি — GPT-2 (XL), মাত্র 1.5 বিলিয়ন প্যারামিটার সহ।
এখানে GPT-3 এর সাথে GPT-2 (XL) এর আকারের তুলনা করা হয়েছে যাতে আপনি কল্পনা করতে পারেন সেখানে কী ঘটবে:


যে জিনিসগুলি এলএলএম প্রশিক্ষণকে নিয়মিত মডেল প্রশিক্ষণ থেকে ব্যাপকভাবে আলাদা করে তোলে তা হল এই মডেলগুলি প্রদর্শন করা নিছক স্কেল, যার বিকাশ, প্রশিক্ষণ এবং দক্ষতার সাথে মোতায়েন করার জন্য যথেষ্ট গণনামূলক সংস্থান এবং কৌশল প্রয়োজন।
এই কারণেই সাধারণ এলএলএম বিল্ডিং "প্রশিক্ষণ" এর চেয়ে "ইঞ্জিনিয়ারিং" সম্পর্কে অনেক বেশি।
সৌভাগ্যবশত, আজ, আমাদের কাছে বিভিন্ন বিশেষায়িত লাইব্রেরি এবং সরঞ্জাম রয়েছে যা এলএলএম প্রকল্পের প্রাথমিক উন্নয়ন এবং প্রশিক্ষণ থেকে শুরু করে পরীক্ষা, মূল্যায়ন, স্থাপনা এবং লগিং পর্যন্ত পরিচালনা করার জন্য ডিজাইন করা হয়েছে।


এই নিবন্ধটি LLM বিকাশের জন্য উপলব্ধ সেরা লাইব্রেরিগুলির কিছু উপস্থাপন করে, প্রকল্পের জীবনচক্রে তাদের নির্দিষ্ট ভূমিকা দ্বারা শ্রেণীবদ্ধ করা হয়েছে, যেমনটি উপরের চিত্রে দেখানো হয়েছে।
যদিও এলএলএম ডেভেলপমেন্টের জন্য প্রচুর লাইব্রেরি এবং টুল রয়েছে, আমরা আমাদের তালিকা তুলনামূলকভাবে সংক্ষিপ্ত রাখার সিদ্ধান্ত নিয়েছি এবং গ্রহণ, সম্প্রদায় সমর্থন, নির্ভরযোগ্যতা, ব্যবহারিক উপযোগিতা এবং আরও অনেক কিছুর উপর ভিত্তি করে 9টি লাইব্রেরি সংক্ষিপ্ত রাখার সিদ্ধান্ত নিয়েছি। আপনি যে লাইব্রেরিগুলি সম্পর্কে আরও জানতে চান সেখানে যেতে বিনা দ্বিধায় বিষয়বস্তুর সারণী ব্যবহার করুন৷
প্রশিক্ষণ এবং স্কেলিং
একটি বাস্তবতা পরীক্ষা
#1) মেগাট্রন-এলএম
#2) ডিপস্পীড
#3) ইয়াএফএসডিপি
পরীক্ষা এবং মূল্যায়ন
#1) জিসকার্ড
#2) lm-মূল্যায়ন-জোতা
স্থাপনা এবং অনুমান
#1) ভিএলএলএম
#2) CTranslate2
লগিং
#1) ট্রুয়েরা
#2) গভীর পরীক্ষা
প্রশিক্ষণ এবং স্কেলিং

একটি বাস্তবতা পরীক্ষা
স্কেল দেওয়া হলে, ডিস্ট্রিবিউটেড লার্নিং (একটি প্রশিক্ষণ পদ্ধতি যাতে একাধিক জিপিইউ জড়িত) LLM-এর প্রশিক্ষণের অগ্রভাগে রয়েছে।
ডিস্ট্রিবিউটেড লার্নিং ব্যবহার করার একটি সুস্পষ্ট উপায় হল একাধিক জিপিইউ জুড়ে ডেটা বিতরণ করা, প্রতিটি ডিভাইসে ফরওয়ার্ড পাস চালানো এবং গ্রেডিয়েন্টগুলি গণনা করা:

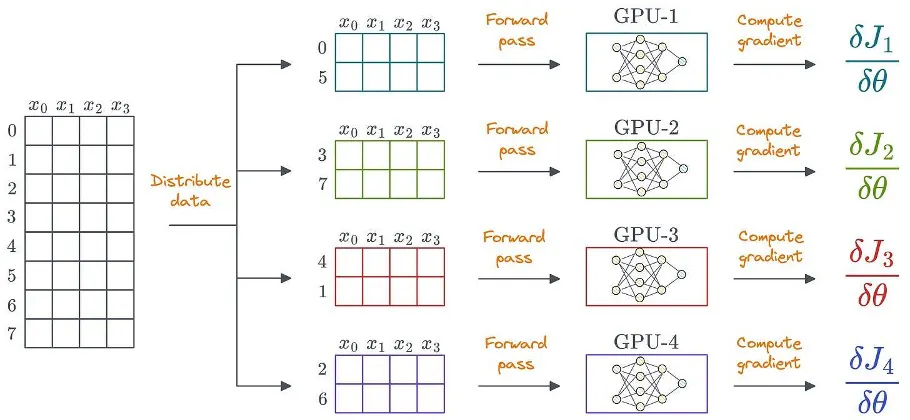
ডাটাও অসংগঠিত হতে পারে। স্ট্রাকচার্ড ডেটা শুধুমাত্র সরলতার জন্য দেখানো হয়েছে।
এটি অর্জন করতে, প্রতিটি জিপিইউ মডেল ওজন এবং অপ্টিমাইজার স্টেটের নিজস্ব অনুলিপি সঞ্চয় করে:


যাইহোক, সবচেয়ে বড় সমস্যা হল এই মডেলগুলি বিশাল। প্রতিটি GPU ডিভাইস জুড়ে সমগ্র মডেলের প্রতিলিপি করা কার্যত অসম্ভাব্য।
এছাড়াও, অপ্টিমাইজার স্টেট দ্বারা গ্রাস করা মেমরি সম্পর্কে কি? আমরা এখনও এটি বিবেচনা করিনি।
আরও প্রেক্ষাপটের জন্য, অ্যাডাম অপ্টিমাইজার (সবচেয়ে বেশি ব্যবহৃত অপ্টিমাইজারগুলির মধ্যে একটি) দ্বারা ব্যবহৃত মেমরি মডেলের ওজনের দ্বিগুণ (32-বিট নির্ভুলতায়) সমতুল্য।


ধরে নিচ্ছি যে আমরা গ্রেডিয়েন্টগুলি গণনা করতে পেরেছি, পরবর্তী বাধাটি মডেলগুলি সিঙ্ক্রোনাইজ করার জন্য সেগুলিকে অন্যান্য GPU-তে স্থানান্তর করছে।
নিষ্পাপ উপায়ে (নীচে দেখানো হয়েছে) একটি GPU থেকে অন্য সমস্ত GPU-তে গ্রেডিয়েন্ট স্থানান্তর করা জড়িত, এবং প্রতিটি স্থানান্তর মডেল আকারের সমতুল্য।


অবশ্যই, এটি অপ্টিমাইজ করার উপায় আছে, কিন্তু তারা এই স্কেলে কার্যত অসম্ভাব্য।
এখানে কয়েকটি লাইব্রেরি রয়েছে যা এই সমস্যার সমাধান করে।
#1) মেগাট্রন-এলএম
মেগাট্রন হল একটি অপ্টিমাইজেশান লাইব্রেরি যা NVIDIA দ্বারা বিকশিত হয়েছে প্রথাগত বিতরণ করা শিক্ষার সীমাবদ্ধতাগুলিকে মোকাবেলা করার সময় বড় আকারের ট্রান্সফরমার মডেলগুলিকে প্রশিক্ষণ দেওয়ার জন্য।
লাইব্রেরি দাবি করে যে মডেল সমান্তরালতা ব্যবহার করে কেউ মাল্টি-বিলিয়ন প্যারামিটার এলএলএম প্রশিক্ষণ দিতে পারে। মূল ধারণাটি হল মডেলের প্যারামিটারগুলিকে একাধিক GPU গুলিতে বিতরণ করা।


মডেল সমান্তরালতা ডেটা সমান্তরালতার সাথে মিলিত হতে পারে (উপরের বিভাগে আলোচনা করা হয়েছে)।
NVIDIA দ্বারা প্রকাশিত সংশ্লিষ্ট কাগজে উল্লেখ করা হয়েছে যে তারা 512 NVIDIA GPU-তে 8.3 বিলিয়ন প্যারামিটার পর্যন্ত ট্রান্সফরমার-ভিত্তিক মডেলগুলিকে দক্ষতার সাথে প্রশিক্ষিত করেছে।
সত্যি কথা বলতে, আজকের মডেলগুলির স্কেল বিবেচনা করে এটি যুক্তিসঙ্গতভাবে বড় নয়।
তবে এটি একটি বড় কৃতিত্ব হিসাবে বিবেচিত হয়েছিল কারণ মেগাট্রন প্রথম 2019 সালে মুক্তি পেয়েছিল (প্রি-GPT-3 যুগ) এবং এই ধরনের স্কেলের মডেল তৈরি করা তখন স্বাভাবিকভাবেই কঠিন ছিল।
আসলে, 2019 সাল থেকে, মেগাট্রনের আরও কয়েকটি পুনরাবৃত্তির প্রস্তাব করা হয়েছে।
এখানে শুরু করুন:
#2) ডিপস্পীড
DeepSpeed একটি অপ্টিমাইজেশান লাইব্রেরি যা মাইক্রোসফ্ট দ্বারা তৈরি করা হয়েছে যা বিতরণ করা শিক্ষার ব্যথার পয়েন্টগুলিকে সম্বোধন করে৷


দ্য
মনে রাখবেন যে উপরের আলোচনায়, বিতরণ করা শেখার সেটআপে প্রচুর অপ্রয়োজনীয়তা জড়িত ছিল:
প্রতিটি জিপিইউ একই মডেলের ওজন ধারণ করে।
প্রতিটি GPU অপ্টিমাইজারের একটি অনুলিপি বজায় রাখে।
প্রতিটি জিপিইউ অপ্টিমাইজার স্টেটের একই মাত্রিক কপি সংরক্ষণ করে।
জিরো (জিরো রিডানডেন্সি অপ্টিমাইজার) অ্যালগরিদম, নাম অনুসারে, সমস্ত জিপিইউগুলির মধ্যে অপ্টিমাইজারের ওজন, গ্রেডিয়েন্ট এবং স্টেটগুলিকে সম্পূর্ণরূপে বিভক্ত করে এই অপ্রয়োজনীয়তা সম্পূর্ণরূপে দূর করে৷
এটি নীচে চিত্রিত করা হয়েছে:


যদিও আমরা প্রযুক্তিগত বিবরণে প্রবেশ করব না, এই স্মার্ট ধারণাটি উল্লেখযোগ্যভাবে হ্রাস মেমরি লোডের সাথে শেখার প্রক্রিয়াটিকে দ্রুত করা সম্ভব করেছে।
অধিকন্তু, এটি এন (জিপিইউ-এর সংখ্যা) একটি ফ্যাক্টর দ্বারা অপ্টিমাইজার পদক্ষেপের গতি বাড়ায়।
কাগজটি দাবি করে যে ZeRO 1 ট্রিলিয়ন প্যারামিটার অতিক্রম করতে পারে।
তবে, তাদের নিজস্ব পরীক্ষায়, গবেষকরা একটি 17B-প্যারামিটার মডেল তৈরি করেছেন — Turing-NLG , যা 12 মে, 2020 পর্যন্ত বিশ্বের বৃহত্তম মডেল।
এখানে শুরু করুন:
2022 সালে (GPT-3-এর পরে), NVIDIA (Megatron-এর স্রষ্টা) এবং Microsoft (DeepSpeed-এর স্রষ্টা) প্রস্তাব দেওয়ার জন্য একসঙ্গে কাজ করেছিল
তারা এটি মেগাট্রন-টুরিং এনএলজি তৈরি করতে ব্যবহার করেছিল, যার 530B প্যারামিটার ছিল — GPT-3 এর চেয়ে তিনগুণ বড়।


#3) ইয়াএফএসডিপি
যদিও DeepSpeed বেশ শক্তিশালী, এটির বিভিন্ন ব্যবহারিক সীমাবদ্ধতাও রয়েছে।
এই ক্ষেত্রে:
ডিপস্পিড বাস্তবায়ন বৃহৎ ক্লাস্টারে অকার্যকর হয়ে উঠতে পারে কমিউনিকেশন ওভারহেড এবং নির্ভরতার কারণে
NCCL যৌথ যোগাযোগের জন্য লাইব্রেরি।অতিরিক্তভাবে, DeepSpeed উল্লেখযোগ্যভাবে প্রশিক্ষণ পাইপলাইনকে রূপান্তরিত করে, যা বাগ প্রবর্তন করতে পারে এবং গুরুত্বপূর্ণ পরীক্ষার প্রয়োজন হয়।
ইয়াএফএসডিপি একটি নতুন ডেটা সমান্তরাল লাইব্রেরি যা এর একটি উন্নত সংস্করণ
সংক্ষেপে, FSDP এবং DeepSpeed এর তুলনায়, YaFSDP:
- গতিশীলভাবে স্তরগুলির জন্য আরও দক্ষতার সাথে মেমরি বরাদ্দ করে, নিশ্চিত করে যে কোনও নির্দিষ্ট সময়ে শুধুমাত্র প্রয়োজনীয় পরিমাণ মেমরি ব্যবহার করা হয়।
- "গিভ-ওয়ে ইফেক্ট" থেকে পরিত্রাণ পায়, যার ফলে গণনার ডাউনটাইম ব্যাপকভাবে হ্রাস পায়।
-
FlattenParameterএর মতো কৌশলগুলি ব্যবহার করে, যা শার্ডিংয়ের আগে একাধিক স্তরের পরামিতিগুলিকে একক বড় প্যারামিটারে একত্রিত করে, যা যোগাযোগের দক্ষতা এবং মাপযোগ্যতাকে আরও উন্নত করে। - শুধুমাত্র মডেলকে প্রভাবিত করে একটি আরো ব্যবহারকারী-বান্ধব ইন্টারফেস বজায় রাখে, কিন্তু প্রশিক্ষণ পাইপলাইন নয়।
- এবং আরো
নিম্নলিখিত সারণী বর্তমান কৌশলগুলির সাথে YaFSDP-এর ফলাফলের তুলনা করে:


- ইয়াএফএসডিপি বর্তমান কৌশলগুলির তুলনায় সর্বদাই বেশি কর্মক্ষম।
- বিপুল সংখ্যক GPU-এর সাথে, YaFSDP অনেক ভালো গতি অর্জন করে, যা আরও ভালো মাপযোগ্যতার সুযোগকে চিত্রিত করে।
এখানে শুরু করুন:
পরীক্ষা এবং মূল্যায়ন
যে সঙ্গে, আমরা প্রশিক্ষণ এবং স্কেলিং সম্পন্ন করা হয়. পরবর্তী ধাপ হল পরীক্ষা এবং মূল্যায়ন:
এলএলএম মূল্যায়নের সাথে একটি অন্তর্নিহিত চ্যালেঞ্জ হল যে সঠিকতা, F1 স্কোর, প্রত্যাহার ইত্যাদির মতো কয়েকটি মেট্রিকের উপর ভিত্তি করে তাদের মূল্যায়ন করা যায় না।
পরিবর্তে, তাদের অবশ্যই একাধিক মাত্রা জুড়ে মূল্যায়ন করা উচিত যেমন সাবলীলতা, সংগতি, বাস্তবিক নির্ভুলতা এবং প্রতিপক্ষের আক্রমণের দৃঢ়তা, এবং এই মূল্যায়ন প্রায়ই বিষয়ভিত্তিক হয়।
বিভিন্ন সরঞ্জাম আমাদের এটি করতে সাহায্য করে:
#1) জিসকার্ড


Giskard হল একটি ওপেন সোর্স লাইব্রেরি যা আমাদের LLM-এর সাথে নিম্নলিখিত সমস্যাগুলি সনাক্ত করতে সাহায্য করে:
- হ্যালুসিনেশন
- ভুল তথ্য
- ক্ষতিকরতা
- স্টেরিওটাইপস
- ব্যক্তিগত তথ্য প্রকাশ
- প্রম্পট ইনজেকশন
এটি PyTorch, TensorFlow, HuggingFace, Scikit-Learn, XGBoost এবং LangChain-এর মতো সমস্ত জনপ্রিয় ফ্রেমওয়ার্কের সাথে কাজ করে। তাছাড়া, কেউ একে HuggingFace, Weights & Biases এবং MLFlow-এর সাথেও একীভূত করতে পারে।
এখানে শুরু করুন:
#2) lm-মূল্যায়ন-জোতা
ইভালুয়েশন হারনেস হল আরেকটি ওপেন-সোর্স টুল যা এলএলএমগুলিকে একটি শক্তিশালী মূল্যায়ন প্রক্রিয়ার মাধ্যমে রাখে।
মূলত, কেউ বেছে নিতে পারে কোন বেঞ্চমার্কের বিরুদ্ধে তারা তাদের মডেল পরীক্ষা করতে চায়, এগুলিকে সিস্টেমে চালান এবং তারপর ফলাফল পান।
2024 সালের মে পর্যন্ত, এটিতে LLM-এর জন্য 60টিরও বেশি স্ট্যান্ডার্ড একাডেমিক বেঞ্চমার্ক রয়েছে এবং কাস্টম প্রম্পট এবং মূল্যায়ন মেট্রিক্সের জন্য সহজ সমর্থন রয়েছে, যা Giskard-এর জন্য কঠিন।
কিছু সাধারণ বেঞ্চমার্ক অন্তর্ভুক্ত:
- প্রশ্ন এবং উত্তর
- বহু নির্বাচনী প্রশ্ন
- যে কাজগুলি লিঙ্গ পক্ষপাতের বিরুদ্ধে পরীক্ষা করে, মানুষ যা করতে সক্ষম হবে তার অনুরূপ।
- এবং আরো
এখানে শুরু করুন:
ট্রুয়েরা এবং ডিপচেকসের মতো আরও কয়েকটি সরঞ্জাম রয়েছে, তবে সেগুলি আরও ব্যাপক কারণ তারা শেষ থেকে শেষ মূল্যায়ন এবং পর্যবেক্ষণের সমাধান প্রদান করে। আমরা শেষ বিভাগে তাদের কভার করব।
আপনি যদি এলএলএম মূল্যায়ন সম্পর্কে আরও বিশদে জানতে চান, আমি এই নিবন্ধটি সুপারিশ করছি:
স্থাপনা এবং অনুমান
এর সাথে, আমরা আমাদের মডেলের মূল্যায়ন করেছি, এবং আমরা আত্মবিশ্বাসের সাথে এটিকে স্থাপনায় স্থানান্তরিত করেছি:

মনে রাখবেন যে যখন আমরা বলি “ডিপ্লয়মেন্ট”, তখন আমরা মডেলটিকে ক্লাউডে ঠেলে দেওয়া বোঝায় না। যে কেউ এটা করতে পারেন.
পরিবর্তে, এটি খরচ কমাতে অনুমান পর্যায়ে দক্ষতা অর্জন সম্পর্কে আরও বেশি।
#1) ভিএলএলএম
এলএলএম ইনফারেন্স দক্ষতা বাড়ানোর জন্য ভিএলএলএম সম্ভবত সেরা ওপেন সোর্স টুলগুলির মধ্যে একটি।


সংক্ষেপে, মডেলের পারফরম্যান্সের সাথে আপস না করেই অনুমানের গতি বাড়ানোর জন্য ভিএলএলএম একটি অভিনব মনোযোগ অ্যালগরিদম ব্যবহার করে।
ফলাফলগুলি পরামর্শ দেয় যে এটি কোনও মডেল পরিবর্তনের প্রয়োজন ছাড়াই HuggingFace ট্রান্সফরমারের তুলনায় ~24x বেশি থ্রুপুট সরবরাহ করতে পারে।


ফলস্বরূপ, এটি এলএলএমকে সবার জন্য অনেক বেশি সাশ্রয়ী মূল্যের পরিবেশন করে।
এখানে শুরু করুন:
#2) CTranslate2
CTranslate2 হল ট্রান্সফরমার মডেলের জন্য আরেকটি জনপ্রিয় ফাস্ট ইনফারেন্স ইঞ্জিন।
সংক্ষেপে, লাইব্রেরি এলএলএম-এর জন্য অনেক কর্মক্ষমতা অপ্টিমাইজেশন কৌশল প্রয়োগ করে, যেমন:
- ওয়েট কোয়ান্টাইজেশন : কোয়ান্টাইজেশন ফ্লোটিং-পয়েন্ট থেকে লো-বিট রিপ্রেজেন্টেশনে ওজনের নির্ভুলতা হ্রাস করে, যেমন int8 বা int16। এটি মডেলের আকার এবং মেমরি পদচিহ্ন উল্লেখযোগ্যভাবে হ্রাস করে, দ্রুত গণনা এবং কম পাওয়ার খরচের অনুমতি দেয়। অধিকন্তু, নিম্ন-নির্ভুল উপস্থাপনাগুলির অধীনে ম্যাট্রিক্স গুণনগুলিও দ্রুত চলে:


- লেয়ার ফিউশন : নাম অনুসারে, লেয়ার ফিউশন অনুমান পর্বের সময় একাধিক অপারেশনকে একক অপারেশনে একত্রিত করে। যদিও সঠিক কারিগরি এই নিবন্ধের বাইরে রয়েছে, স্তরগুলি একত্রিত করার মাধ্যমে গণনামূলক পদক্ষেপের সংখ্যা হ্রাস করা হয়, যা প্রতিটি স্তরের সাথে যুক্ত ওভারহেডকে হ্রাস করে।
- ব্যাচ পুনর্বিন্যাস : ব্যাচ পুনঃক্রমের মধ্যে হার্ডওয়্যার সংস্থানগুলির ব্যবহার অপ্টিমাইজ করার জন্য ইনপুট ব্যাচগুলিকে সংগঠিত করা জড়িত। এই কৌশলটি নিশ্চিত করে যে অনুরূপ দৈর্ঘ্যের অনুক্রমগুলি একসাথে প্রক্রিয়া করা হয়, প্যাডিংকে ন্যূনতম করে এবং সমান্তরাল প্রক্রিয়াকরণের দক্ষতা সর্বাধিক করে।
কৌশল ব্যবহার করা CPU এবং GPU উভয় ক্ষেত্রেই ট্রান্সফরমার মডেলের মেমরি ব্যবহারকে ত্বরান্বিত করে এবং হ্রাস করে।
এখানে শুরু করুন:
লগিং
মডেলটি স্কেল করা হয়েছে, পরীক্ষা করা হয়েছে, উত্পাদন করা হয়েছে এবং স্থাপন করা হয়েছে এবং এখন ব্যবহারকারীর অনুরোধগুলি পরিচালনা করছে।
যাইহোক, মডেলের কর্মক্ষমতা নিরীক্ষণ করতে, এর আচরণ ট্র্যাক করতে এবং উত্পাদন পরিবেশে এটি প্রত্যাশিত হিসাবে কাজ করে তা নিশ্চিত করার জন্য শক্তিশালী লগিং প্রক্রিয়া থাকা অপরিহার্য।
এটি শুধু এলএলএম নয় সব বাস্তব-বিশ্বের এমএল মডেলের ক্ষেত্রে প্রযোজ্য।

এলএলএম-এর প্রেক্ষাপটে লগ ইন করার জন্য এখানে কিছু প্রয়োজনীয় সরঞ্জাম এবং কৌশল রয়েছে।
#1) ট্রুয়েরা
Truera শুধুমাত্র একটি লগিং সমাধান নয়.


পরিবর্তে, এটি এলএলএম পরীক্ষা এবং মূল্যায়নের জন্য অতিরিক্ত ক্ষমতা প্রদান করে।
এটি এটিকে আরও ব্যাপক পর্যবেক্ষণযোগ্যতা সমাধান করে তোলে - যা উত্পাদন কর্মক্ষমতা ট্র্যাক করার জন্য সরঞ্জাম সরবরাহ করে, হ্যালুসিনেশনের মতো সমস্যাগুলি হ্রাস করে এবং দায়িত্বশীল AI অনুশীলনগুলি নিশ্চিত করে৷
এখানে কিছু মূল বৈশিষ্ট্য রয়েছে:
LLM পর্যবেক্ষণযোগ্যতা : TruEra LLM অ্যাপ্লিকেশনের জন্য বিশদ পর্যবেক্ষণযোগ্যতা প্রদান করে। ব্যবহারকারীরা ফিডব্যাক ফাংশন এবং অ্যাপ ট্র্যাকিং ব্যবহার করে তাদের LLM অ্যাপগুলিকে মূল্যায়ন করতে পারে, যা কর্মক্ষমতা অপ্টিমাইজ করতে এবং হ্যালুসিনেশনের মতো ঝুঁকি কমাতে সাহায্য করে।
স্কেলেবল মনিটরিং এবং রিপোর্টিং : প্ল্যাটফর্মটি মডেল পারফরম্যান্স, ইনপুট এবং আউটপুটের পরিপ্রেক্ষিতে ব্যাপক পর্যবেক্ষণ, রিপোর্টিং এবং সতর্কতা প্রদান করে। এই বৈশিষ্ট্যটি নিশ্চিত করে যে মডেল ড্রিফ্ট, ওভারফিটিং বা পক্ষপাতের মতো যেকোন সমস্যা দ্রুত সনাক্ত করা হয়েছে এবং অনন্য এআই মূল কারণ বিশ্লেষণের মাধ্যমে সমাধান করা হয়েছে।
[গুরুত্বপূর্ণ] TruLens : TruEra-এর TruLens হল একটি ওপেন-সোর্স লাইব্রেরি যা ব্যবহারকারীদের তাদের LLM অ্যাপ পরীক্ষা ও ট্র্যাক করতে দেয়।
এবং আরো
TruEra সম্পর্কে একটি দুর্দান্ত জিনিস হল যে এটি AWS SageMaker, Microsoft Azure, Vertex.ai এবং আরও অনেক কিছুর মতো ভবিষ্যদ্বাণীমূলক মডেল ডেভেলপমেন্ট সলিউশন সহ বিদ্যমান AI স্ট্যাকের সাথে নির্বিঘ্নে সংহত করতে পারে।
এটি ব্যক্তিগত ক্লাউড, AWS, Google, বা Azure সহ বিভিন্ন পরিবেশে স্থাপনাকে সমর্থন করে এবং উচ্চ মডেল ভলিউম পূরণের জন্য স্কেল।
এখানে শুরু করুন:
#2) গভীর পরীক্ষা


ডিপচেকস হল TruEra এর মত আরেকটি ব্যাপক সমাধান, যা এলএলএম মূল্যায়ন, পরীক্ষা এবং পর্যবেক্ষণ সমাধান প্রদান করে।
তবে, লাইব্রেরি শুধু এলএলএম-এর মধ্যেই সীমাবদ্ধ নয়। পরিবর্তে, অনেক ডেটা সায়েন্টিস্ট এবং মেশিন লার্নিং ইঞ্জিনিয়াররা বিভিন্ন ডোমেন জুড়ে বিভিন্ন মেশিন লার্নিং মডেলের জন্য DeepChecks ব্যবহার করে।
এটি বলেছিল, তাদের মূল্যায়ন কাঠামোটি জিসকার্ডের মতো ব্যাপক এবং পুঙ্খানুপুঙ্খ নয়, যে টুলটি আমরা আগে আলোচনা করেছি।
এখানে শুরু করুন:
যেহেতু আমরা এই নিবন্ধটি সংক্ষিপ্ত এবং দ্রুত হতে চেয়েছিলাম, আমরা সেখানে প্রতিটি একক টুলকে কভার করিনি, তবে আমরা এমন সরঞ্জামগুলি প্রদর্শন করেছি যা 90% ব্যবহারের ক্ষেত্রে যথেষ্ট হবে।
আমরা বাদ দেওয়ার সিদ্ধান্ত নিয়েছি এমন সরঞ্জামগুলির কয়েকটি উদাহরণ এখানে রয়েছে৷
- প্রশিক্ষণ এবং স্কেলিং: ফেয়ারস্কেল।
- পরীক্ষা এবং মূল্যায়ন: TextAttack।
- পরিবেশন: প্রবাহিত।
- লগিং: ওজন এবং পক্ষপাত, MLFlow, এবং আরও অনেক কিছু।
আপনি যদি আরও অনেক টুল স্ট্যাকের গভীরে যেতে চান তবে এটি দেখুন
পড়ার জন্য ধন্যবাদ!








