
























GPT-2 (XL) में 1.5 बिलियन पैरामीटर हैं, और इसके पैरामीटर 16-बिट परिशुद्धता में ~3GB मेमोरी का उपभोग करते हैं।
हालाँकि, इसे 30GB मेमोरी वाले एकल GPU पर प्रशिक्षित करना मुश्किल है।


यह मॉडल की मेमोरी से 10 गुना अधिक है, और आप सोच रहे होंगे कि यह कैसे संभव हो सकता है।
यद्यपि इस लेख का फोकस एलएलएम मेमोरी खपत नहीं है (
वास्तव में, उपरोक्त उदाहरण में, हमने एक बहुत छोटे मॉडल - GPT-2 (XL) पर विचार किया था, जिसमें केवल 1.5 बिलियन पैरामीटर थे।
यहां GPT-2 (XL) और GPT-3 के आकार की तुलना दी गई है, जिससे आप कल्पना कर सकते हैं कि वहां क्या होगा:


एलएलएम प्रशिक्षण को नियमित मॉडल प्रशिक्षण से व्यापक रूप से भिन्न बनाने वाली एक बात यह है कि इन मॉडलों का विशाल पैमाना होता है, जिसके विकास, प्रशिक्षण और कुशलतापूर्वक तैनाती के लिए पर्याप्त कम्प्यूटेशनल संसाधनों और तकनीकों की आवश्यकता होती है।
यही कारण है कि सामान्य एलएलएम का निर्माण "प्रशिक्षण" की तुलना में "इंजीनियरिंग" के बारे में अधिक है।
शुक्र है कि आज हमारे पास विभिन्न विशिष्ट लाइब्रेरी और उपकरण हैं, जो एलएलएम परियोजनाओं के विभिन्न चरणों को संभालने के लिए डिज़ाइन किए गए हैं, प्रारंभिक विकास और प्रशिक्षण से लेकर परीक्षण, मूल्यांकन, परिनियोजन और लॉगिंग तक।


यह आलेख LLM विकास के लिए उपलब्ध कुछ सर्वोत्तम पुस्तकालयों को प्रस्तुत करता है, जिन्हें परियोजना जीवनचक्र में उनकी विशिष्ट भूमिकाओं के आधार पर वर्गीकृत किया गया है, जैसा कि ऊपर दिए गए चित्र में दिखाया गया है।
जबकि एलएलएम विकास के लिए बहुत सारे पुस्तकालय और उपकरण हैं, हमने अपनी सूची को अपेक्षाकृत संक्षिप्त रखने का फैसला किया और गोद लेने, सामुदायिक समर्थन, विश्वसनीयता, व्यावहारिक उपयोगिता और अधिक जैसे कारकों के आधार पर 9 पुस्तकालयों को चुना। आप उन पुस्तकालयों पर जाने के लिए सामग्री की तालिका का उपयोग करने के लिए स्वतंत्र हैं जिनके बारे में आप अधिक जानना चाहते हैं।
प्रशिक्षण और स्केलिंग
वास्तविकता की जाँच
#1) मेगाट्रॉन-एलएम
#2) डीपस्पीड
#3) वाईएफएसडीपी
परीक्षण और मूल्यांकन
#1) गिस्कार्ड
#2) lm-मूल्यांकन-हार्नेस
परिनियोजन और अनुमान
#1) वीएलएलएम
#2) सीट्रांसलेट2
लॉगिंग
#1) ट्रूएरा
#2) डीपचेक्स
प्रशिक्षण और स्केलिंग

वास्तविकता की जाँच
पैमाने को देखते हुए, वितरित शिक्षण (एक प्रशिक्षण प्रक्रिया जिसमें कई GPU शामिल होते हैं) LLM प्रशिक्षण में सबसे आगे है।
वितरित शिक्षण का उपयोग करने का एक स्पष्ट तरीका है डेटा को कई GPU में वितरित करना, प्रत्येक डिवाइस पर फॉरवर्ड पास चलाना, और ग्रेडिएंट की गणना करना:

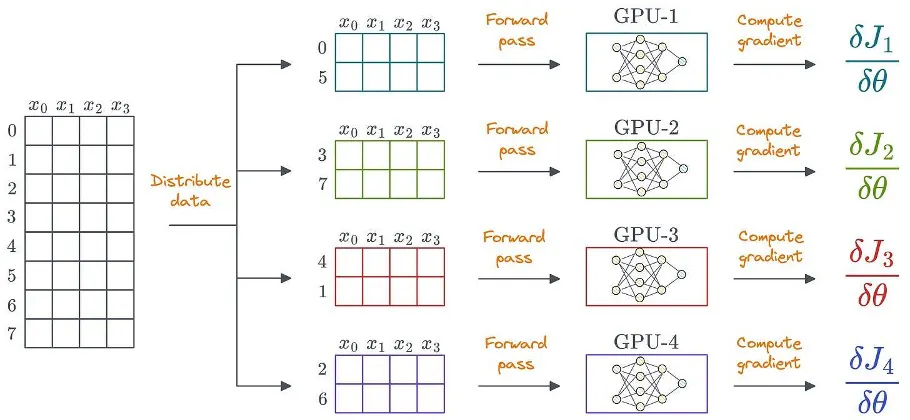
डेटा असंरचित भी हो सकता है। संरचित डेटा केवल सरलता के लिए दिखाया जाता है।
इसे प्राप्त करने के लिए, प्रत्येक GPU मॉडल भार और अनुकूलक स्थिति की अपनी प्रतिलिपि संग्रहीत करता है:


हालाँकि, सबसे बड़ी समस्या यह है कि ये मॉडल बहुत बड़े हैं। प्रत्येक GPU डिवाइस में पूरे मॉडल की नकल करना व्यावहारिक रूप से असंभव है।
इसके अलावा, ऑप्टिमाइज़र स्टेट द्वारा खपत की जाने वाली मेमोरी के बारे में क्या? हमने अभी तक इस पर विचार भी नहीं किया है।
अधिक संदर्भ के लिए, एडम ऑप्टिमाइज़र (सबसे व्यापक रूप से प्रयुक्त ऑप्टिमाइज़र में से एक) द्वारा उपभोग की गई मेमोरी, मॉडल के भार के दो गुना (32-बिट परिशुद्धता में) के बराबर होती है।


यह मानते हुए कि हम किसी तरह ग्रेडिएंट की गणना करने में कामयाब हो गए हैं, अगली बाधा मॉडलों को सिंक्रोनाइज़ करने के लिए उन्हें अन्य GPU में स्थानांतरित करना है।
सरल तरीके (नीचे दर्शाया गया है) में एक GPU से अन्य सभी GPU में ग्रेडिएंट स्थानांतरित करना शामिल है, और प्रत्येक स्थानांतरण मॉडल आकार के बराबर होता है।


बेशक, इसे अनुकूलित करने के तरीके हैं, लेकिन वे इस पैमाने पर व्यावहारिक रूप से अव्यवहारिक भी हैं।
यहां कुछ पुस्तकालय दिए गए हैं जो इस समस्या का समाधान करते हैं।
#1) मेगाट्रॉन-एलएम
मेगाट्रॉन एक अनुकूलन लाइब्रेरी है जिसे NVIDIA द्वारा विकसित किया गया है, जो पारंपरिक वितरित शिक्षण की सीमाओं को संबोधित करते हुए बड़े पैमाने पर ट्रांसफार्मर मॉडलों को प्रशिक्षित करता है।
लाइब्रेरी का दावा है कि मॉडल समानांतरता का उपयोग करके बहु-अरब पैरामीटर एलएलएम को प्रशिक्षित किया जा सकता है। मुख्य विचार मॉडल के मापदंडों को कई GPU में वितरित करना है।


मॉडल समानांतरता को डेटा समानांतरता के साथ जोड़ा जा सकता है (जिसकी चर्चा ऊपर अनुभाग में की गई है)।
NVIDIA द्वारा जारी संबंधित पेपर में उल्लेख किया गया है कि उन्होंने 512 NVIDIA GPU पर 8.3 बिलियन पैरामीटर तक ट्रांसफार्मर-आधारित मॉडलों को कुशलतापूर्वक प्रशिक्षित किया।
स्पष्ट रूप से कहें तो, आज के मॉडलों के पैमाने को देखते हुए, यह कोई बहुत बड़ी राशि नहीं है।
लेकिन इसे एक बड़ी उपलब्धि माना गया क्योंकि मेगेट्रॉन को पहली बार 2019 (प्री-जीपीटी-3 युग) में जारी किया गया था और उस समय इस तरह के पैमाने के मॉडल का निर्माण स्वाभाविक रूप से कठिन था।
वास्तव में, 2019 के बाद से, मेगेट्रॉन के कुछ और संस्करण प्रस्तावित किए गए हैं।
यहाँ से शुरुआत करें:
#2) डीपस्पीड
डीपस्पीड माइक्रोसॉफ्ट द्वारा विकसित एक अनुकूलन लाइब्रेरी है जो वितरित शिक्षण के समस्याओं का समाधान करती है।


स्मरण करें कि उपरोक्त चर्चा में, वितरित शिक्षण व्यवस्था में बहुत अधिक अतिरेक शामिल था:
प्रत्येक GPU का मॉडल भार समान था।
प्रत्येक GPU ने ऑप्टिमाइज़र की एक प्रति बनाए रखी।
प्रत्येक GPU ने अनुकूलक अवस्थाओं की समान आयामी प्रतिलिपि संग्रहित की।
जैसा कि नाम से पता चलता है, ZeRO (जीरो रिडंडेंसी ऑप्टिमाइज़र) एल्गोरिथ्म, सभी GPU के बीच ऑप्टिमाइज़र के भार, ग्रेडिएंट और स्थिति को पूरी तरह से विभाजित करके इस अतिरेक को पूरी तरह से समाप्त कर देता है।
इसे नीचे दर्शाया गया है:


हालांकि हम तकनीकी विवरण में नहीं जाएंगे, लेकिन इस स्मार्ट विचार ने स्मृति भार को काफी कम करके सीखने की प्रक्रिया को तीव्र करना संभव बना दिया।
इसके अलावा, यह ऑप्टिमाइज़र चरण को N (GPU की संख्या) के कारक से तेज़ कर देता है।
पेपर में दावा किया गया है कि ज़ीरो 1 ट्रिलियन पैरामीटर से आगे तक जा सकता है।
हालाँकि, अपने स्वयं के प्रयोगों में, शोधकर्ताओं ने एक 17B-पैरामीटर मॉडल - ट्यूरिंग-एनएलजी बनाया, जो 12 मई, 2020 तक दुनिया का सबसे बड़ा मॉडल है।
यहाँ से शुरुआत करें:
2022 में (GPT-3 के बाद), NVIDIA (मेगाट्रॉन के निर्माता) और Microsoft (डीपस्पीड के निर्माता) ने मिलकर प्रस्ताव रखा
उन्होंने इसका उपयोग मेगेट्रॉन-ट्यूरिंग एनएलजी बनाने के लिए किया, जिसके पैरामीटर 530बी थे - जो जीपीटी-3 से तीन गुना बड़े थे।


#3) वाईएफएसडीपी
हालांकि डीपस्पीड काफी शक्तिशाली है, लेकिन इसमें कई व्यावहारिक सीमाएं भी हैं।
उदाहरण के लिए:
संचार ओवरहेड्स और निर्भरता के कारण डीपस्पीड कार्यान्वयन बड़े क्लस्टरों पर अक्षम हो सकता है
एनसीसीएल सामूहिक संचार के लिए पुस्तकालय.इसके अतिरिक्त, डीपस्पीड प्रशिक्षण पाइपलाइन को महत्वपूर्ण रूप से परिवर्तित करता है, जिसमें बग आ सकते हैं और महत्वपूर्ण परीक्षण की आवश्यकता हो सकती है।
YaFSDP एक नई डेटा समानांतरता लाइब्रेरी है जो का एक उन्नत संस्करण है
संक्षेप में, FSDP और डीपस्पीड की तुलना में, YaFSDP:
- यह परतों के लिए गतिशील रूप से अधिक कुशलता से मेमोरी आवंटित करता है, तथा यह सुनिश्चित करता है कि किसी भी समय केवल आवश्यक मात्रा में ही मेमोरी का उपयोग किया जाए।
- इससे "गिव-वे प्रभाव" से छुटकारा मिलता है, जिससे गणनाओं में डाउनटाइम बहुत कम हो जाता है।
-
FlattenParameterजैसी तकनीकों का लाभ उठाता है, जो शार्डिंग से पहले कई परत मापदंडों को एकल बड़े मापदंडों में जोड़ता है, जो संचार दक्षता और मापनीयता को और बढ़ाता है। - केवल मॉडल को प्रभावित करके, प्रशिक्षण पाइपलाइन को प्रभावित न करके, अधिक उपयोगकर्ता-अनुकूल इंटरफ़ेस बनाए रखता है।
- और अधिक।
निम्नलिखित तालिका वर्तमान तकनीकों के साथ YaFSDP के परिणामों की तुलना करती है:


- YaFSDP वर्तमान तकनीकों की तुलना में सदैव अधिक निष्पादन योग्य है।
- बड़ी संख्या में GPU के साथ, YaFSDP बेहतर गति प्राप्त करता है, जो बेहतर मापनीयता की इसकी संभावना को दर्शाता है।
यहाँ से शुरुआत करें:
परीक्षण और मूल्यांकन
इसके साथ ही, हमने प्रशिक्षण और स्केलिंग का काम पूरा कर लिया है। अगला चरण परीक्षण और मूल्यांकन है:
एलएलएम के मूल्यांकन में एक अंतर्निहित चुनौती यह है कि उनका मूल्यांकन कुछ मापदंडों जैसे सटीकता, एफ1 स्कोर, रिकॉल आदि के आधार पर नहीं किया जा सकता है।
इसके बजाय, उनका मूल्यांकन कई आयामों जैसे प्रवाह, सुसंगति, तथ्यात्मक सटीकता और प्रतिकूल हमलों के प्रति मजबूती के आधार पर किया जाना चाहिए, और यह मूल्यांकन अक्सर व्यक्तिपरक होता है।
विभिन्न उपकरण हमें ऐसा करने में मदद करते हैं:
#1) गिस्कार्ड


गिस्कार्ड एक ओपन-सोर्स लाइब्रेरी है जो हमें LLMs के साथ निम्नलिखित समस्याओं का पता लगाने में मदद करती है:
- दु: स्वप्न
- झूठी खबर
- अनिष्टमयता
- लकीर के फकीर
- निजी जानकारी का खुलासा
- शीघ्र इंजेक्शन
यह PyTorch, TensorFlow, HuggingFace, Scikit-Learn, XGBoost और LangChain जैसे सभी लोकप्रिय फ्रेमवर्क के साथ काम करता है। इसके अलावा, इसे HuggingFace, Weights & Biases और MLFlow के साथ भी एकीकृत किया जा सकता है।
यहाँ से शुरुआत करें:
#2) lm-मूल्यांकन-हार्नेस
इवैल्यूएशन हार्नेस एक अन्य ओपन-सोर्स टूल है जो एलएलएम को एक मजबूत मूल्यांकन प्रक्रिया से गुजरता है।
मूलतः, कोई भी व्यक्ति यह चुन सकता है कि वह अपने मॉडल का परीक्षण किन मानकों के आधार पर करना चाहता है, उन्हें सिस्टम में चला सकता है, और फिर परिणाम प्राप्त कर सकता है।
मई 2024 तक, इसमें एलएलएम के लिए 60 से अधिक मानक शैक्षणिक बेंचमार्क और कस्टम प्रॉम्प्ट और मूल्यांकन मेट्रिक्स के लिए आसान समर्थन है, जो कि गिस्कार्ड के साथ मुश्किल है।
कुछ सामान्य बेंचमार्क में शामिल हैं:
- प्रश्न एवं उत्तर
- बहु विकल्पीय प्रश्न
- ऐसे कार्य जो लैंगिक पूर्वाग्रह के विरुद्ध परीक्षण करते हैं, जो मनुष्य कर सकते हैं।
- और अधिक।
यहाँ से शुरुआत करें:
ट्रूएरा और डीपचेक्स जैसे कुछ और उपकरण हैं, लेकिन वे अधिक व्यापक हैं क्योंकि वे एंड-टू-एंड मूल्यांकन और अवलोकनीयता समाधान प्रदान करते हैं। हम उन्हें अंतिम अनुभाग में कवर करेंगे।
यदि आप एलएलएम मूल्यांकन के बारे में अधिक जानकारी प्राप्त करना चाहते हैं, तो मैं इस लेख की अनुशंसा करता हूं:
परिनियोजन और अनुमान
इसके साथ ही, हमने अपने मॉडल का मूल्यांकन कर लिया है, और हमने विश्वास के साथ इसे क्रियान्वयन हेतु आगे बढ़ा दिया है:

ध्यान दें कि जब हम "तैनाती" कहते हैं, तो हमारा मतलब मॉडल को क्लाउड पर धकेलना नहीं होता। ऐसा कोई भी कर सकता है।
इसके बजाय, इसका उद्देश्य लागत कम करने के लिए अनुमान चरणों के दौरान दक्षता प्राप्त करना है।
#1) वीएलएलएम
वीएलएलएम संभवतः एलएलएम अनुमान दक्षता को बढ़ाने के लिए सबसे अच्छे ओपन-सोर्स टूल में से एक है।


संक्षेप में, vLLM मॉडल के प्रदर्शन से समझौता किए बिना अनुमान को गति देने के लिए एक नवीन ध्यान एल्गोरिथ्म का उपयोग करता है।
परिणाम बताते हैं कि यह बिना किसी मॉडल परिवर्तन की आवश्यकता के हगिंगफेस ट्रांसफॉर्मर्स की तुलना में ~ 24 गुना अधिक थ्रूपुट प्रदान कर सकता है।


परिणामस्वरूप, इससे एलएलएम सेवा सभी के लिए अधिक किफायती हो गई है।
यहाँ से शुरुआत करें:
#2) सीट्रांसलेट2
CTranslate2 ट्रांसफॉर्मर मॉडल के लिए एक और लोकप्रिय तीव्र अनुमान इंजन है।
संक्षेप में, लाइब्रेरी एलएलएम के लिए कई प्रदर्शन अनुकूलन तकनीकों को लागू करती है, जैसे:
- वज़न परिमाणीकरण : परिमाणीकरण फ़्लोटिंग-पॉइंट से लेकर कम-बिट अभ्यावेदन, जैसे int8 या int16 तक वज़न की सटीकता को कम करता है। यह मॉडल के आकार और मेमोरी फ़ुटप्रिंट को महत्वपूर्ण रूप से कम करता है, जिससे तेज़ गणना और कम बिजली की खपत होती है। इसके अलावा, मैट्रिक्स गुणन भी कम-सटीकता वाले अभ्यावेदन के तहत तेज़ी से चलता है:


- लेयर फ़्यूज़न : जैसा कि नाम से पता चलता है, लेयर फ़्यूज़न अनुमान चरण के दौरान कई ऑपरेशनों को एक ही ऑपरेशन में जोड़ता है। जबकि सटीक तकनीकी विवरण इस लेख से परे हैं, परतों को मर्ज करके कम्प्यूटेशनल चरणों की संख्या कम हो जाती है, जिससे प्रत्येक परत से जुड़े ओवरहेड कम हो जाते हैं।
- बैच रीऑर्डरिंग : बैच रीऑर्डरिंग में हार्डवेयर संसाधनों के उपयोग को अनुकूलित करने के लिए इनपुट बैचों को व्यवस्थित करना शामिल है। यह तकनीक सुनिश्चित करती है कि अनुक्रमों की समान लंबाई एक साथ संसाधित की जाती है, जिससे पैडिंग कम से कम होती है और समानांतर प्रसंस्करण दक्षता अधिकतम होती है।
तकनीकों के प्रयोग से सीपीयू और जीपीयू दोनों पर ट्रांसफॉर्मर मॉडल का मेमोरी उपयोग काफी तेजी से बढ़ता है और कम होता है।
यहाँ से शुरुआत करें:
लॉगिंग
मॉडल का मापन, परीक्षण, उत्पादनीकरण और परिनियोजन किया जा चुका है और अब यह उपयोगकर्ता के अनुरोधों को संभाल रहा है।
हालाँकि, मॉडल के प्रदर्शन की निगरानी करने, उसके व्यवहार को ट्रैक करने और यह सुनिश्चित करने के लिए कि वह उत्पादन परिवेश में अपेक्षा के अनुरूप काम करता है, मजबूत लॉगिंग तंत्र का होना आवश्यक है।
यह बात न केवल एलएलएम पर लागू होती है, बल्कि सभी वास्तविक दुनिया के एमएल मॉडलों पर लागू होती है।

एलएलएम के संदर्भ में लॉगिंग के लिए यहां कुछ आवश्यक उपकरण और तकनीकें दी गई हैं।
#1) ट्रूएरा
ट्रूएरा सिर्फ लॉगिंग समाधान नहीं है।


इसके बजाय, यह एलएलएम के परीक्षण और मूल्यांकन के लिए अतिरिक्त क्षमताएं भी प्रदान करता है।
यह इसे और अधिक व्यापक अवलोकनीयता समाधान बनाता है - जो उत्पादन प्रदर्शन को ट्रैक करने, मतिभ्रम जैसे मुद्दों को कम करने और जिम्मेदार एआई प्रथाओं को सुनिश्चित करने के लिए उपकरण प्रदान करता है।
यहां कुछ प्रमुख विशेषताएं दी गई हैं:
एलएलएम अवलोकनीयता : ट्रूएरा एलएलएम अनुप्रयोगों के लिए विस्तृत अवलोकनीयता प्रदान करता है। उपयोगकर्ता फीडबैक फ़ंक्शन और ऐप ट्रैकिंग का उपयोग करके अपने एलएलएम ऐप का मूल्यांकन कर सकते हैं, जो प्रदर्शन को अनुकूलित करने और भ्रम जैसे जोखिमों को कम करने में मदद करता है।
स्केलेबल मॉनिटरिंग और रिपोर्टिंग : यह प्लेटफ़ॉर्म मॉडल के प्रदर्शन, इनपुट और आउटपुट के संदर्भ में व्यापक निगरानी, रिपोर्टिंग और अलर्टिंग प्रदान करता है। यह सुविधा सुनिश्चित करती है कि मॉडल ड्रिफ्ट, ओवरफिटिंग या पूर्वाग्रह जैसी किसी भी समस्या को तुरंत पहचाना जाए और अद्वितीय AI मूल कारण विश्लेषण के माध्यम से संबोधित किया जाए।
[महत्वपूर्ण] ट्रूलेन्स : ट्रूएरा का ट्रूलेन्स एक ओपन-सोर्स लाइब्रेरी है जो उपयोगकर्ताओं को अपने एलएलएम ऐप्स का परीक्षण और ट्रैक करने की अनुमति देता है।
और अधिक।
ट्रूएरा के बारे में एक अच्छी बात यह है कि यह मौजूदा एआई स्टैक के साथ सहजता से एकीकृत हो सकता है, जिसमें AWS SageMaker, Microsoft Azure, Vertex.ai, आदि जैसे पूर्वानुमान मॉडल विकास समाधान शामिल हैं।
यह निजी क्लाउड, AWS, गूगल या Azure सहित विभिन्न वातावरणों में तैनाती का भी समर्थन करता है, तथा उच्च मॉडल वॉल्यूम को पूरा करने के लिए स्केल करता है।
यहाँ से शुरुआत करें:
#2) डीपचेक्स


डीपचेक्स ट्रूएरा की तरह एक और व्यापक समाधान है, जो एलएलएम मूल्यांकन, परीक्षण और निगरानी समाधान प्रदान करता है।
हालाँकि, यह लाइब्रेरी सिर्फ़ LLM तक ही सीमित नहीं है। इसके बजाय, कई डेटा वैज्ञानिक और मशीन लर्निंग इंजीनियर विभिन्न डोमेन में विभिन्न मशीन लर्निंग मॉडल के लिए डीपचेक का लाभ उठाते हैं।
जैसा कि कहा गया है, उनका मूल्यांकन ढांचा गिस्कार्ड (जिस टूल पर हमने पहले चर्चा की थी) जितना व्यापक और गहन नहीं है।
यहाँ से शुरुआत करें:
चूंकि हम चाहते थे कि यह आलेख संक्षिप्त और त्वरित हो, इसलिए हमने हर एक उपकरण को शामिल नहीं किया, लेकिन हमने उन उपकरणों को प्रदर्शित किया जो 90% उपयोग मामलों के लिए पर्याप्त होंगे।
यहां उन उपकरणों के कुछ उदाहरण दिए गए हैं जिन्हें हमने छोड़ने का निर्णय लिया है।
- प्रशिक्षण और स्केलिंग: फेयरस्केल.
- परीक्षण और मूल्यांकन: टेक्स्टअटैक.
- सेवा: फ्लोविज़.
- लॉगिंग: भार और पूर्वाग्रह, एमएलफ्लो, और अधिक।
यदि आप और अधिक टूल स्टैक में गहराई से गोता लगाना चाहते हैं, तो इसे देखें
पढ़ने के लिए धन्यवाद!








