
























介绍
在上一篇博客中,我向您展示了如何使用Databricks CLI eXtensions和 GitLab 构建 CI 管道。在这篇文章中,我将向您展示如何使用最新和推荐的 Databricks 部署框架Databricks Asset Bundles实现相同的目标。DAB 受到 Databricks 团队的积极支持和开发,作为一种新工具,用于简化 Databricks 平台复杂数据、分析和 ML 项目开发。
我将跳过 DAB 及其功能的一般介绍,并让您参考 Databricks 文档。在这里,我将重点介绍如何将我们上一篇博客中的 dbx 项目迁移到 DAB。在此过程中,我将解释一些概念和功能,以帮助您更好地掌握每个步骤。
使用 Databricks GUI 的开发模式
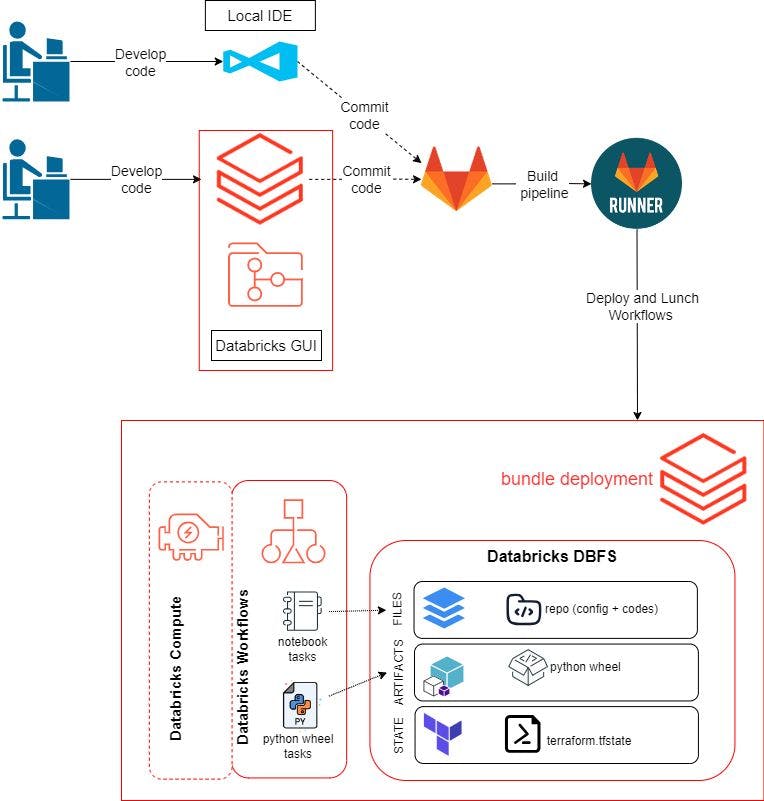
在上一篇文章中,我们使用 Databricks GUI 来开发和测试我们的代码和工作流程。对于这篇博文,我们希望能够使用本地环境来开发我们的代码。工作流程如下:
创建一个远程存储库并将其克隆到我们的本地环境和 Databricks 工作区。我们在这里使用GitLab 。
开发程序逻辑并在 Databricks GUI 或本地 IDE 上进行测试。这包括用于构建 Python Wheel 包的 Python 脚本、用于使用 pytest 测试数据质量的脚本以及用于运行 pytest 的笔记本。
将代码推送到 GitLab。git
git push将触发 GitLab Runner 使用 Databricks Asset Bundles 在 Databricks 上构建、部署和启动资源。设置开发环境
Databricks CLI
首先,我们需要在本地机器上安装 Databricks CLI 0.205 或更高版本。要检查已安装的 Databricks CLI 版本,请运行命令
databricks -v。要安装 Databricks CLI 0.205 或更高版本,请参阅安装或更新 Databricks CLI 。验证
Databricks 支持我们开发计算机上的 Databricks CLI 和您的 Databricks 工作区之间的各种身份验证方法。在本教程中,我们使用 Databricks 个人访问令牌身份验证。它包括两个步骤:
- 在我们的 Databricks 工作区上创建个人访问令牌。
- 在我们的本地机器上创建一个 Databricks 配置文件。
要在 Databricks 工作区中生成 Databricks 令牌,请转到用户设置 → 开发人员 → 访问令牌 → 管理 → 生成新令牌。
要创建配置文件,请在根文件夹中创建文件
~/.databrickscfg,其内容如下:

[asset-bundle-tutorial] host = https://xxxxxxxxxxx.cloud.databricks.com token = xxxxxxx这里, asset-bundle-tutorial是我们的配置文件名称,host 是我们工作区的地址,token 是我们刚刚创建的个人访问令牌。
您可以使用 Databricks CLI 在终端中运行databricks configure --profile asset-bundle-tutorial来创建此文件。该命令将提示您输入Databricks Host和Personal Access Token 。如果您未指定--profile标志,则配置文件名称将设置为DEFAULT 。
Git 集成 (Databricks)
第一步,我们配置 Git 凭证并将远程存储库连接到 Databricks 。接下来,我们创建一个远程存储库并将其克隆到我们的 Databricks 存储库以及本地机器上。最后,我们需要在 Gitlab 运行器上的 Databricks CLI 和我们的 Databricks 工作区之间设置身份验证。为此,我们应该将两个环境变量DATABRICKS_HOST和DATABRICKS_TOKEN添加到我们的 Gitlab CI/CD 管道配置中。为此,在 Gitlab 中打开你的存储库,转到设置→CI/CD→变量→添加变量


dbx 和 DAB 都是围绕Databricks REST API构建的,因此它们的核心非常相似。我将介绍从现有 dbx 项目手动创建包的步骤。
我们需要为 DAB 项目设置的第一件事是部署配置。在dbx 中,我们使用两个文件来定义和设置我们的环境和工作流(作业和管道)。为了设置环境,我们使用.dbx/project.json ,为了定义工作流,我们使用了deployment.yml 。
在 DAB 中,所有内容都放入databricks.yml中,该文件位于项目的根文件夹中。它如下所示:
bundle: name: DAB_tutorial #our bundle name # These are for any custom variables for use throughout the bundle. variables: my_cluster_id: description: The ID of an existing cluster. default: xxxx-xxxxx-xxxxxxxx #The remote workspace URL and workspace authentication credentials are read from the caller's local configuration profile named <asset-bundle-tutorial> workspace: profile: asset-bundle-tutorial # These are the default job and pipeline settings if not otherwise overridden in # the following "targets" top-level mapping. resources: jobs: etl_job: tasks: - task_key: "main" existing_cluster_id: ${var.my_cluster_id} python_wheel_task: package_name: "my_package" entry_point: "etl_job" # take a look at the setup.py entry_points section for details on how to define an entrypoint libraries: - whl: ../dist/*.whl - task_key: "eda" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/explorative_analysis.py source: WORKSPACE depends_on: - task_key: "main" test_job: tasks: - task_key: "main_notebook" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/run_unit_test.py source: WORKSPACE libraries: - pypi: package: pytest # These are the targets to use for deployments and workflow runs. One and only one of these # targets can be set to "default: true". targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: true workspace: profile: asset-bundle-tutorial root_path: /Users/${workspace.current_user.userName}/.bundle/${bundle.name}/my-envs/${bundle.target} host: <path to your databricks dev workspace>
databricks.yml包配置文件由称为映射的部分组成。这些映射使我们能够将配置文件模块化为单独的逻辑块。有 8 个顶级映射:
捆
变量
工作区
文物
包括
资源
同步
目标
在这里,我们使用其中五种映射来组织我们的项目。
捆:
在bundle映射中,我们定义了 bundle 的名称。在这里,我们还可以定义应该用于我们的开发环境的默认集群 ID,以及有关 Git URL 和分支的信息。
变量:
我们可以使用variables映射来定义自定义变量,并使我们的配置文件更具可重用性。例如,我们为现有集群的 ID 声明一个变量,并在不同的工作流中使用它。现在,如果您想使用不同的集群,您只需更改变量值即可。
资源:
resources映射是我们定义工作流程的地方。它包括以下映射中的零个或一个: experiments 、 jobs 、 models和pipelines 。这基本上是 dbx 项目中的deployment.yml文件。尽管存在一些细微的差异:
- 对于
python_wheel_task,我们必须包含 wheel 包的路径;否则,Databricks 找不到该库。您可以在此处找到有关使用 DAB 构建 wheel 包的更多信息。 - 我们可以使用相对路径而不是完整路径来运行笔记本任务。要部署的笔记本的路径相对于声明此任务的
databricks.yml文件。
目标:
targets映射是我们定义项目不同阶段/环境的配置和资源的地方。例如,对于典型的 CI/CD 管道,我们将有三个目标:开发、暂存和生产。每个目标都可以由所有顶级映射( targets除外)作为子映射组成。以下是目标映射 ( databricks.yml ) 的架构。
targets: <some-unique-programmatic-identifier-for-this-target>: artifacts: ... bundle: ... compute_id: string default: true | false mode: development resources: ... sync: ... variables: <preceding-unique-variable-name>: <non-default-value> workspace: ...
子映射允许我们覆盖之前在顶级映射中定义的默认配置。例如,如果我们想为 CI/CD 管道的每个阶段都有一个独立的 Databricks 工作区,我们应该为每个目标设置工作区子映射。
workspace: profile: my-default-profile targets: dev: default: true test: workspace: host: https://<staging-workspace-url> prod: workspace: host: https://<production-workspace-url>
包括:
include映射允许我们将配置文件分成不同的模块。例如,我们可以将资源和变量保存到resources/dev_job.yml文件中,并将其导入到databricks.yml文件中。
# yaml-language-server: $schema=bundle_config_schema.json bundle: name: DAB_tutorial #our bundle name workspace: profile: asset-bundle-tutorial include: - ./resources/*.yml targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: true有关 DAB 配置的更多详细说明,请查看Databricks Asset Bundle 配置
工作流程
工作流程与我在上一篇博客中描述的完全一样。唯一的区别是工件和文件的位置。


项目骨架
最终项目的样子如下
ASSET-BUNDLE-TUTORAL/ ├─ my_package/ │ ├─ tasks/ │ │ ├─ __init__.py │ │ ├─ sample_etl_job.py │ ├─ __init__.py │ ├─ common.py ├─ test/ │ ├─ conftest.py │ ├─ test_sample.py ├─ notebooks/ │ ├─ explorative_analysis.py │ ├─ run_unit_test.py ├─ resources/ │ ├─ dev_jobs.yml ├─ .gitignore ├─ .gitlab-ci.yml ├─ databricks.yml ├─ README.md ├─ setup.py
验证、部署和运行
现在,打开终端并从根目录运行以下命令:
验证:首先,我们应该检查配置文件是否具有正确的格式和语法。如果验证成功,您将获得捆绑配置的 JSON 表示。如果出现错误,请修复它并再次运行命令,直到收到 JSON 文件。
databricks bundle validate
部署:部署包括构建 Python wheel 包并将其部署到我们的 Databricks 工作区、将笔记本和其他文件部署到我们的 Databricks 工作区以及在我们的 Databricks 工作流中创建作业。
databricks bundle deploy如果未指定命令选项,Databricks CLI 将使用捆绑配置文件中声明的默认目标。这里我们只有一个目标,所以这无所谓,但为了演示这一点,我们还可以使用
-t dev标志部署特定目标。
run:运行已部署的作业。在这里,我们可以指定要运行哪个作业。例如,在下面的命令中,我们在 dev 目标中运行
test_job作业。databricks bundle run -t dev test_job
在输出中,您将获得一个指向工作区中运行的作业的 URL。


您还可以在 Databricks 工作区的工作流部分找到您的作业。
CI 管道配置
我们的 CI 管道的一般设置与上一个项目相同。它由两个主要阶段组成:测试和部署。在测试阶段, unit-test-job运行单元测试并部署单独的工作流进行测试。部署阶段在成功完成测试阶段后激活,负责处理主要 ETL 工作流的部署。
在这里,我们必须在每个阶段之前添加额外的步骤来安装 Databricks CLI 并设置身份验证配置文件。我们在 CI 管道的before_script部分执行before_script操作。before_script 关键字用于定义应在每个作业的script命令之前运行的命令数组。有关它的更多信息可以在这里找到。
可选地,您可以使用after_project关键字来定义应在每个作业之后运行的命令数组。在这里,我们可以使用databricks bundle destroy --auto-approve在每个作业结束后进行清理。一般来说,我们的管道要经过以下步骤:
- 安装 Databricks CLI 并创建配置文件。
- 构建项目。
- 将构建工件推送到 Databricks 工作区。
- 在您的集群上安装 wheel 包。
- 在 Databricks Workflows 上创建作业。
- 运行作业。
我们的.gitlab-ci.yml如下所示:
image: python:3.9 stages: # List of stages for jobs, and their order of execution - test - deploy default: before_script: - echo "install databricks cli" - curl -V - curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh - echo "databricks CLI installation finished" - echo "create the configuration profile for token authentication" - echo "[asset-bundle-tutorial]" > ~/.databrickscfg - echo "token = $DATABRICKS_TOKEN" >> ~/.databrickscfg - echo "host = $DATABRICKS_HOST" >> ~/.databrickscfg - echo "validate the bundle" - databricks bundle validate after_script: - echo "remove all workflows" #- databricks bundle destroy --auto-approve unit-test-job: # This job runs in the test stage. stage: test script: - echo "Running unit tests." - pip3 install --upgrade wheel setuptools - pip install -e ".[local]" - databricks bundle deploy -t dev - databricks bundle run -t dev test_job deploy-job: # This job runs in the deploy stage. stage: deploy # It only runs when *both* jobs in the test stage complete successfully. script: - echo "Deploying application..." - echo "Install dependencies" - pip install -e ".[local]" - echo "Deploying Job" - databricks bundle deploy -t dev - databricks bundle run -t dev etl_job
笔记
以下一些注意事项可以帮助您设置捆绑项目:
- 在这篇博客中,我们手动创建了我们的包。根据我的经验,这有助于更好地理解底层概念和功能。但是,如果您想快速启动项目,可以使用 Databricks 或其他方提供的默认和非默认包模板。查看这篇 Databricks文章,了解如何使用默认 Python 模板启动项目。
- 当您使用
databricks bundle deploy部署代码时,Databricks CLI 会运行命令python3 setup.py bdist_wheel来使用setup.py文件构建包。如果您已经安装了python3 ,但您的机器使用的是python别名而不是python3 ,那么您将遇到问题。不过,这很容易解决。例如,这里和这里有两个 Stack Overflow 线程,其中包含一些解决方案。
下一步是什么
在下一篇博文中,我将从我的第一篇博文开始,介绍如何在 Databricks 上启动机器学习项目。这将是我即将推出的端到端机器学习流程的第一篇文章,涵盖从开发到生产的所有内容。敬请期待!
资源
确保更新resources/dev_jobs.yml中的 cluster_id
- 从 dbx 迁移到 bundles | AWS 上的 Databricks
- Databricks Asset Bundles 开发工作任务 | AWS 上的 Databricks
- Databricks Asset Bundle 部署模式 | AWS 上的 Databricks
- 使用 Databricks Asset Bundles 开发 Python wheel | AWS 上的 Databricks
- Databricks Asset Bundles:在 Databricks 上部署数据产品的标准、统一方法(youtube.com)








