
























giriiş
Önceki blogda size Databricks CLI eXtensions ve GitLab'ı kullanarak nasıl CI ardışık düzeni oluşturulacağını göstermiştim. Bu yazıda size en yeni ve önerilen Databricks dağıtım çerçevesi Databricks Asset Bundles ile aynı hedefe nasıl ulaşacağınızı göstereceğim. DAB, Databricks platformu için karmaşık verilerin, analizlerin ve makine öğrenimi projelerinin geliştirilmesini kolaylaştırmaya yönelik yeni bir araç olarak Databricks ekibi tarafından aktif olarak desteklenmekte ve geliştirilmektedir.
DAB ve özelliklerinin genel tanıtımını atlayıp sizi Databricks belgelerine yönlendireceğim. Burada dbx projemizi önceki blogdan DAB'a nasıl taşıyacağımıza odaklanacağım. Yol boyunca her adımı daha iyi kavramanıza yardımcı olabilecek bazı kavram ve özellikleri açıklayacağım.
Databricks GUI'yi kullanarak geliştirme modeli
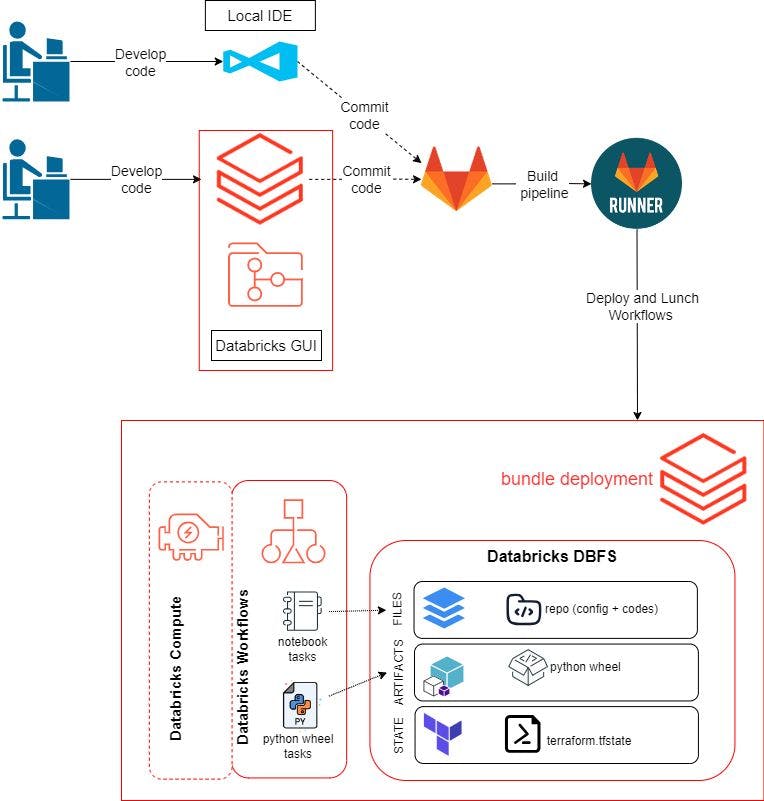
Önceki gönderide kodumuzu ve iş akışlarımızı geliştirmek ve test etmek için Databricks GUI'yi kullandık. Bu blog yazısında kodumuzu geliştirmek için yerel ortamımızı da kullanabilmek istiyoruz. İş akışı şu şekilde olacaktır:
Uzak bir depo oluşturun ve bunu yerel ortamımıza ve Databricks çalışma alanımıza kopyalayın. Burada GitLab'ı kullanıyoruz.
Program mantığını geliştirin ve Databricks GUI'sinde veya yerel IDE'mizde test edin. Bu, bir Python Wheel paketi oluşturmak için Python komut dosyalarını, pytest kullanarak veri kalitesini test etmek için komut dosyalarını ve pytest'i çalıştırmak için bir not defterini içerir.
Kodu GitLab'a aktarın.
git pushDatabricks Asset Bundle'ları kullanarak Databricks üzerinde kaynaklar oluşturmak, dağıtmak ve başlatmak için bir GitLab Runner'ı tetikleyecektir.Geliştirme ortamlarınızı ayarlama
Databricks CLI'si
Öncelikle yerel makinenize Databricks CLI versiyon 0.205 veya üzerini kurmamız gerekiyor. Databricks CLI'nin yüklü sürümünü kontrol etmek için
databricks -vkomutunu çalıştırın. Databricks CLI sürüm 0.205 veya üzerini yüklemek için bkz. Databricks CLI'yi yükleme veya güncelleme .Kimlik doğrulama
Databricks, geliştirme makinemizdeki Databricks CLI ile Databricks çalışma alanınız arasında çeşitli kimlik doğrulama yöntemlerini destekler. Bu eğitim için Databricks kişisel erişim belirteci kimlik doğrulamasını kullanıyoruz. İki adımdan oluşur:
- Databricks çalışma alanımızda kişisel bir erişim belirteci oluşturun.
- Yerel makinemizde bir Databricks konfigürasyon profili oluşturun.
Databricks çalışma alanınızda bir Databricks belirteci oluşturmak için Kullanıcı Ayarları → Geliştirici → Belirteçlere erişim → Yönet → Yeni belirteç oluştur seçeneğine gidin.
Bir konfigürasyon profili oluşturmak için kök klasörünüzde aşağıdaki içeriğe sahip
~/.databrickscfgdosyasını oluşturun:

[asset-bundle-tutorial] host = https://xxxxxxxxxxx.cloud.databricks.com token = xxxxxxx Burada asset-bundle-tutorial profil adımızdır, ana bilgisayar çalışma alanımızın adresidir ve belirteç de az önce oluşturduğumuz kişisel erişim belirtecidir.
Bu dosyayı Databricks CLI'yi kullanarak, terminalinizde databricks configure --profile asset-bundle-tutorial çalıştırarak oluşturabilirsiniz. Komut sizden Databricks Ana Bilgisayarı ve Kişisel Erişim Belirteci'ni isteyecektir. --profile işaretini belirtmezseniz profil adı DEFAULT olarak ayarlanacaktır.
Git entegrasyonu (Databricks)
İlk adım olarak Git kimlik bilgilerini yapılandırıyoruz ve uzak bir repoyu Databricks'e bağlıyoruz . Daha sonra uzak bir depo oluşturup onu Databricks depomuza ve yerel makinemize kopyalıyoruz . Son olarak Gitlab çalıştırıcısındaki Databricks CLI ile Databricks çalışma alanımız arasında kimlik doğrulamayı ayarlamamız gerekiyor. Bunu yapmak için Gitlab CI/CD işlem hattı yapılandırmalarımıza DATABRICKS_HOST ve DATABRICKS_TOKEN olmak üzere iki ortam değişkeni eklemeliyiz. Bunun için deponuzu Gitlab'da açmak için Ayarlar → CI/CD → Değişkenler → Değişken ekle seçeneğine gidin.


Hem dbx hem de DAB, Databricks REST API'leri etrafında oluşturulmuştur, dolayısıyla özünde çok benzerler. Mevcut dbx projemizden manuel olarak paket oluşturma adımlarını inceleyeceğim.
DAB projemiz için ayarlamamız gereken ilk şey dağıtım yapılandırmasıdır. Dbx'te ortamlarımızı ve iş akışlarımızı (işler ve işlem hatları) tanımlamak ve ayarlamak için iki dosya kullanırız . Ortamı ayarlamak için .dbx/project.json , iş akışlarını tanımlamak için ise deployment.yml kullandık.
DAB'de her şey projenizin kök klasöründe bulunan databricks.yml dosyasına gider. İşte nasıl göründüğü:
bundle: name: DAB_tutorial #our bundle name # These are for any custom variables for use throughout the bundle. variables: my_cluster_id: description: The ID of an existing cluster. default: xxxx-xxxxx-xxxxxxxx #The remote workspace URL and workspace authentication credentials are read from the caller's local configuration profile named <asset-bundle-tutorial> workspace: profile: asset-bundle-tutorial # These are the default job and pipeline settings if not otherwise overridden in # the following "targets" top-level mapping. resources: jobs: etl_job: tasks: - task_key: "main" existing_cluster_id: ${var.my_cluster_id} python_wheel_task: package_name: "my_package" entry_point: "etl_job" # take a look at the setup.py entry_points section for details on how to define an entrypoint libraries: - whl: ../dist/*.whl - task_key: "eda" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/explorative_analysis.py source: WORKSPACE depends_on: - task_key: "main" test_job: tasks: - task_key: "main_notebook" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/run_unit_test.py source: WORKSPACE libraries: - pypi: package: pytest # These are the targets to use for deployments and workflow runs. One and only one of these # targets can be set to "default: true". targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: true workspace: profile: asset-bundle-tutorial root_path: /Users/${workspace.current_user.userName}/.bundle/${bundle.name}/my-envs/${bundle.target} host: <path to your databricks dev workspace>
databricks.yml paket yapılandırma dosyası, eşlemeler adı verilen bölümlerden oluşur. Bu eşlemeler, yapılandırma dosyasını ayrı mantıksal bloklar halinde modülerleştirmemize olanak tanır. 8 üst düzey eşleme vardır:
paket
değişkenler
çalışma alanı
eserler
katmak
kaynaklar
senkronizasyon
hedefler
Burada projemizi düzenlemek için bu eşlemelerden beşini kullanıyoruz.
paket :
bundle eşlemesinde paketin adını tanımlıyoruz. Burada, Git URL'si ve şubesi hakkındaki bilgilerin yanı sıra, geliştirme ortamlarımız için kullanılması gereken varsayılan bir küme kimliğini de tanımlayabiliriz.
değişkenler :
Özel değişkenleri tanımlamak ve yapılandırma dosyamızı daha yeniden kullanılabilir hale getirmek için variables eşlemesini kullanabiliriz. Örneğin mevcut bir kümenin ID’si için bir değişken deklare ediyoruz ve bunu farklı iş akışlarında kullanıyoruz. Artık farklı bir küme kullanmak istemeniz durumunda tek yapmanız gereken değişken değerini değiştirmek.
kaynaklar :
resources haritalaması iş akışlarımızı tanımladığımız yerdir. Aşağıdaki eşlemelerin sıfırını veya birini içerir: experiments , jobs , models ve pipelines . Bu temel olarak dbx projesindeki deployment.yml dosyamızdır. Bazı küçük farklılıklar olsa da:
-
python_wheel_taskiçin wheel paketimizin yolunu eklemeliyiz; aksi takdirde Databricks kitaplığı bulamaz. DAB kullanarak tekerlek paketleri oluşturma hakkında daha fazla bilgiyi burada bulabilirsiniz. - Not defteri görevlerini çalıştırmak için tam yollar yerine göreceli yolları kullanabiliriz. Dizüstü bilgisayarın dağıtılacağı yol, bu görevin bildirildiği
databricks.ymldosyasına bağlıdır.
hedefler :
targets eşleme, projelerimizin farklı aşamalarının/ortamlarının yapılandırmalarını ve kaynaklarını tanımladığımız yerdir. Örneğin, tipik bir CI/CD hattı için üç hedefimiz olacaktır: geliştirme, hazırlama ve üretim. Her hedef, alt eşlemeler olarak tüm üst düzey eşlemelerden ( targets hariç) oluşabilir. İşte hedef eşlemenin şeması ( databricks.yml ).
targets: <some-unique-programmatic-identifier-for-this-target>: artifacts: ... bundle: ... compute_id: string default: true | false mode: development resources: ... sync: ... variables: <preceding-unique-variable-name>: <non-default-value> workspace: ...
Alt eşleme, daha önce üst düzey eşlemelerde tanımladığımız varsayılan yapılandırmaları geçersiz kılmamıza olanak tanır. Örneğin, CI/CD işlem hattımızın her aşaması için yalıtılmış bir Databricks çalışma alanına sahip olmak istiyorsak, her hedef için çalışma alanı alt eşlemesini ayarlamamız gerekir.
workspace: profile: my-default-profile targets: dev: default: true test: workspace: host: https://<staging-workspace-url> prod: workspace: host: https://<production-workspace-url>
katmak:
include etme eşlemesi, yapılandırma dosyamızı farklı modüllere bölmemize olanak tanır. Örneğin kaynaklarımızı ve değişkenlerimizi resources/dev_job.yml dosyasına kaydedip databricks.yml dosyamıza aktarabiliriz.
# yaml-language-server: $schema=bundle_config_schema.json bundle: name: DAB_tutorial #our bundle name workspace: profile: asset-bundle-tutorial include: - ./resources/*.yml targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: trueDAB yapılandırmalarının daha ayrıntılı açıklaması için Databricks Asset Bundle yapılandırmalarına göz atın
İş akışları
İş akışları tam olarak önceki blogda anlattığım gibidir. Tek fark, yapıtların ve dosyaların konumudur.


Proje iskeleti
işte final projesinin nasıl göründüğü
ASSET-BUNDLE-TUTORAL/ ├─ my_package/ │ ├─ tasks/ │ │ ├─ __init__.py │ │ ├─ sample_etl_job.py │ ├─ __init__.py │ ├─ common.py ├─ test/ │ ├─ conftest.py │ ├─ test_sample.py ├─ notebooks/ │ ├─ explorative_analysis.py │ ├─ run_unit_test.py ├─ resources/ │ ├─ dev_jobs.yml ├─ .gitignore ├─ .gitlab-ci.yml ├─ databricks.yml ├─ README.md ├─ setup.py
Doğrula, Dağıt ve Çalıştır
Şimdi terminalinizi açın ve kök dizinden aşağıdaki komutları çalıştırın:
validate: Öncelikle konfigürasyon dosyamızın doğru format ve sözdizimine sahip olup olmadığını kontrol etmeliyiz. Doğrulama başarılı olursa paket yapılandırmasının JSON temsilini alırsınız. Bir hata durumunda düzeltin ve JSON dosyasını alana kadar komutu tekrar çalıştırın.
databricks bundle validate
dağıtım: Dağıtım, Python tekerlek paketini oluşturmayı ve bunu Databricks çalışma alanımıza dağıtmayı, not defterlerini ve diğer dosyaları Databricks çalışma alanımıza dağıtmayı ve Databricks iş akışlarımızda işleri oluşturmayı içerir.
databricks bundle deployHiçbir komut seçeneği belirtilmezse Databricks CLI, paket yapılandırma dosyalarında bildirilen varsayılan hedefi kullanır. Burada yalnızca tek bir hedefimiz var, bu yüzden önemli değil, ancak bunu göstermek için
-t devbayrağını kullanarak belirli bir hedefi de konuşlandırabiliriz.
çalıştır: Dağıtılan işleri çalıştırın. Burada hangi işi çalıştırmak istediğimizi belirtebiliriz. Örneğin aşağıdaki komutta dev hedefinde
test_jobişini çalıştırıyoruz.databricks bundle run -t dev test_job
çıktıda, çalışma alanınızda yürütülen işe işaret eden bir URL alırsınız.


işlerinizi Databricks çalışma alanınızın İş Akışı bölümünde de bulabilirsiniz.
CI ardışık düzeni yapılandırması
CI boru hattımızın genel kurulumu önceki projeyle aynı kalıyor. İki ana aşamadan oluşur: test etme ve dağıtma . Test aşamasında, unit-test-job birim testlerini çalıştırır ve test için ayrı bir iş akışı dağıtır. Test aşamasının başarıyla tamamlanmasının ardından etkinleştirilen dağıtım aşaması, ana ETL iş akışınızın dağıtımını yönetir.
Burada Databricks CLI kurulumu ve kimlik doğrulama profilini ayarlamak için her aşamadan önce ek adımlar eklememiz gerekiyor. Bunu CI hattımızın before_script bölümünde yapıyoruz. before_script anahtar sözcüğü, her işin script komutlarından önce çalışması gereken komut dizisini tanımlamak için kullanılır. Bununla ilgili daha fazla bilgiyi burada bulabilirsiniz.
İsteğe bağlı olarak, her işten SONRA çalışması gereken komut dizisini tanımlamak için after_project anahtar sözcüğünü kullanabilirsiniz. Burada, her iş bittikten sonra temizlik yapmak için databricks bundle destroy --auto-approve kullanabiliriz. Genel olarak boru hattımız şu adımlardan geçer:
- Databricks CLI'yi yükleyin ve yapılandırma profili oluşturun.
- Projeyi oluşturun.
- Derleme yapıtlarını Databricks çalışma alanına aktarın.
- Tekerlek paketini kümenize takın.
- İşleri Databricks İş Akışlarında oluşturun.
- İşleri çalıştırın.
.gitlab-ci.yml dosyamız şu şekilde görünüyor:
image: python:3.9 stages: # List of stages for jobs, and their order of execution - test - deploy default: before_script: - echo "install databricks cli" - curl -V - curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh - echo "databricks CLI installation finished" - echo "create the configuration profile for token authentication" - echo "[asset-bundle-tutorial]" > ~/.databrickscfg - echo "token = $DATABRICKS_TOKEN" >> ~/.databrickscfg - echo "host = $DATABRICKS_HOST" >> ~/.databrickscfg - echo "validate the bundle" - databricks bundle validate after_script: - echo "remove all workflows" #- databricks bundle destroy --auto-approve unit-test-job: # This job runs in the test stage. stage: test script: - echo "Running unit tests." - pip3 install --upgrade wheel setuptools - pip install -e ".[local]" - databricks bundle deploy -t dev - databricks bundle run -t dev test_job deploy-job: # This job runs in the deploy stage. stage: deploy # It only runs when *both* jobs in the test stage complete successfully. script: - echo "Deploying application..." - echo "Install dependencies" - pip install -e ".[local]" - echo "Deploying Job" - databricks bundle deploy -t dev - databricks bundle run -t dev etl_job
Notlar
Paket projenizi oluşturmanıza yardımcı olabilecek bazı notlar:
- Bu blogda paketimizi manuel olarak oluşturduk. Deneyimlerime göre bu, altta yatan kavram ve özelliklerin daha iyi anlaşılmasına yardımcı oluyor. Ancak projenize hızlı bir başlangıç yapmak istiyorsanız Databricks veya diğer taraflarca sağlanan varsayılan ve varsayılan olmayan paket şablonlarını kullanabilirsiniz. Varsayılan Python şablonuyla bir projeyi nasıl başlatacağınızı öğrenmek için bu Databricks gönderisine göz atın.
-
databricks bundle deploykullanarak kodunuzu dağıttığınızda, Databricks CLI, setup.py dosyasını kullanarak paketinizi oluşturmak içinpython3 setup.py bdist_wheelkomutunu çalıştırır. Zaten python3 kuruluysa ancak makineniz python3 yerine python takma adını kullanıyorsa sorunlarla karşılaşırsınız. Ancak bunu düzeltmek kolaydır. Örneğin, burada ve burada bazı çözümlere sahip iki Yığın Taşması iş parçacığı bulunmaktadır.
Sıradaki ne
Bir sonraki blog yazımda Databricks üzerinde makine öğrenimi projesinin nasıl başlatılacağına dair ilk blog yazımla başlayacağım. Bu, geliştirmeden üretime kadar her şeyi kapsayan, yaklaşan uçtan uca makine öğrenimi hattımın ilk gönderisi olacak. Bizi izlemeye devam edin!
Kaynaklar
resources/dev_jobs.yml dosyasındaki Cluster_id değerini güncellediğinizden emin olun.
- Dbx'ten paketlere geçiş | AWS'de Databricks
- Databricks Varlık Paketleri geliştirme çalışması görevleri | AWS'de Databricks
- Databricks Asset Bundle dağıtım modları | AWS'de Databricks
- Databricks Asset Bundles'ı kullanarak bir Python tekerleği geliştirin | AWS'de Databricks
- Databricks Varlık Paketleri: Veri Ürünlerini Databricks'te Dağıtmaya Yönelik Standart, Birleşik Bir Yaklaşım (youtube.com)
- repo ve slaytlar https://github.com/databricks/databricks-asset-bundles-dais2023








