
























Einführung
Im vorherigen Blog habe ich Ihnen gezeigt, wie Sie mit Databricks CLI eXtensions und GitLab eine CI-Pipeline erstellen. In diesem Beitrag zeige ich Ihnen, wie Sie dasselbe Ziel mit dem neuesten und empfohlenen Databricks-Bereitstellungsframework, Databricks Asset Bundles, erreichen. DAB wird vom Databricks-Team aktiv unterstützt und entwickelt als neues Tool zur Optimierung der Entwicklung komplexer Daten-, Analyse- und ML-Projekte für die Databricks-Plattform.
Ich werde die allgemeine Einführung in DAB und seine Funktionen überspringen und Sie auf die Databricks-Dokumentation verweisen. Hier werde ich mich darauf konzentrieren, wie wir unser dbx-Projekt aus dem vorherigen Blog zu DAB migrieren. Dabei werde ich einige Konzepte und Funktionen erklären, die Ihnen helfen können, jeden Schritt besser zu verstehen.
Entwicklungsmuster mit Databricks GUI
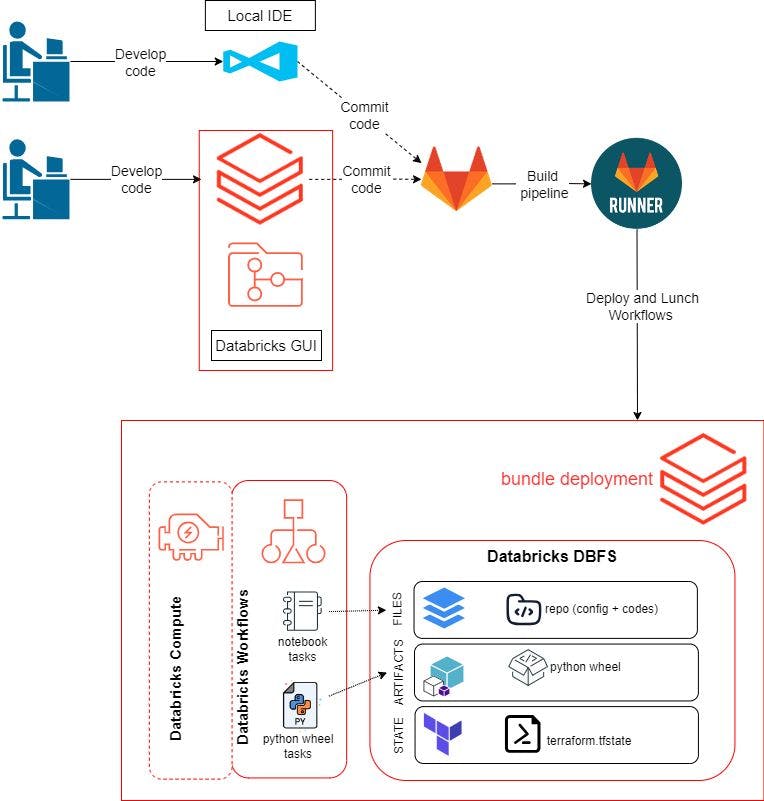
Im vorherigen Beitrag haben wir die Databricks-GUI verwendet, um unseren Code und unsere Workflows zu entwickeln und zu testen. Für diesen Blogbeitrag möchten wir unsere lokale Umgebung auch zum Entwickeln unseres Codes verwenden können. Der Workflow sieht wie folgt aus:
Erstellen Sie ein Remote-Repository und klonen Sie es in unsere lokale Umgebung und den Databricks-Arbeitsbereich. Wir verwenden hier GitLab .
Entwickeln Sie die Programmlogik und testen Sie sie in der Databricks-GUI oder in unserer lokalen IDE. Dazu gehören Python-Skripte zum Erstellen eines Python Wheel-Pakets, Skripte zum Testen der Datenqualität mit pytest und ein Notebook zum Ausführen von pytest.
Pushen Sie den Code zu GitLab. Der
git pushlöst einen GitLab Runner aus, um Ressourcen auf Databricks mithilfe von Databricks Asset Bundles zu erstellen, bereitzustellen und zu starten.Einrichten Ihrer Entwicklungsumgebungen
Databricks-Befehlszeilenschnittstelle
Zunächst müssen wir Databricks CLI Version 0.205 oder höher auf Ihrem lokalen Computer installieren. Um Ihre installierte Version von Databricks CLI zu überprüfen, führen Sie den Befehl
databricks -vaus. Informationen zum Installieren von Databricks CLI Version 0.205 oder höher finden Sie unter Installieren oder Aktualisieren von Databricks CLI .Authentifizierung
Databricks unterstützt verschiedene Authentifizierungsmethoden zwischen der Databricks-CLI auf unserem Entwicklungscomputer und Ihrem Databricks-Arbeitsbereich. Für dieses Tutorial verwenden wir die Databricks-Authentifizierung mit persönlichem Zugriffstoken. Sie besteht aus zwei Schritten:
- Erstellen Sie einen persönlichen Zugriffstoken für unseren Databricks-Arbeitsbereich.
- Erstellen Sie ein Databricks-Konfigurationsprofil auf unserem lokalen Computer.
Um ein Databricks-Token in Ihrem Databricks-Arbeitsbereich zu generieren, gehen Sie zu Benutzereinstellungen → Entwickler → Zugriffstoken → Verwalten → Neues Token generieren.
Um ein Konfigurationsprofil zu erstellen, erstellen Sie die Datei
~/.databrickscfgin Ihrem Stammordner mit folgendem Inhalt:

[asset-bundle-tutorial] host = https://xxxxxxxxxxx.cloud.databricks.com token = xxxxxxx Hier ist das asset-bundle-tutorial unser Profilname, der Host die Adresse unseres Arbeitsbereichs und das Token das persönliche Zugriffstoken, das wir gerade erstellt haben.
Sie können diese Datei mithilfe der Databricks-CLI erstellen, indem databricks configure --profile asset-bundle-tutorial in Ihrem Terminal ausführen. Der Befehl fordert Sie zur Eingabe des Databricks-Hosts und des persönlichen Zugriffstokens auf. Wenn Sie das Flag --profile nicht angeben, wird der Profilname auf DEFAULT gesetzt.
Git-Integration (Databricks)
Als ersten Schritt konfigurieren wir die Git-Anmeldeinformationen und verbinden ein Remote-Repository mit Databricks . Als Nächstes erstellen wir ein Remote-Repository und klonen es in unser Databricks-Repository sowie auf unseren lokalen Computer. Schließlich müssen wir die Authentifizierung zwischen der Databricks-CLI auf dem Gitlab-Runner und unserem Databricks-Arbeitsbereich einrichten. Dazu sollten wir unseren Gitlab CI/CD-Pipeline-Konfigurationen zwei Umgebungsvariablen hinzufügen, DATABRICKS_HOST und DATABRICKS_TOKEN . Öffnen Sie dazu Ihr Repository in Gitlab und gehen Sie zu Einstellungen → CI/CD → Variablen → Variablen hinzufügen


Sowohl dbx als auch DAB basieren auf den Databricks REST APIs und sind sich daher im Kern sehr ähnlich. Ich werde die Schritte durchgehen, um manuell ein Paket aus unserem vorhandenen dbx-Projekt zu erstellen.
Das erste, was wir für unser DAB-Projekt einrichten müssen, ist die Bereitstellungskonfiguration. In dbx verwenden wir zwei Dateien, um unsere Umgebungen und Workflows (Jobs und Pipelines) zu definieren und einzurichten. Zum Einrichten der Umgebung haben wir .dbx/project.json verwendet, und zum Definieren der Workflows haben wir deployment.yml verwendet.
In DAB gelangt alles in databricks.yml , das sich im Stammordner Ihres Projekts befindet. So sieht es aus:
bundle: name: DAB_tutorial #our bundle name # These are for any custom variables for use throughout the bundle. variables: my_cluster_id: description: The ID of an existing cluster. default: xxxx-xxxxx-xxxxxxxx #The remote workspace URL and workspace authentication credentials are read from the caller's local configuration profile named <asset-bundle-tutorial> workspace: profile: asset-bundle-tutorial # These are the default job and pipeline settings if not otherwise overridden in # the following "targets" top-level mapping. resources: jobs: etl_job: tasks: - task_key: "main" existing_cluster_id: ${var.my_cluster_id} python_wheel_task: package_name: "my_package" entry_point: "etl_job" # take a look at the setup.py entry_points section for details on how to define an entrypoint libraries: - whl: ../dist/*.whl - task_key: "eda" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/explorative_analysis.py source: WORKSPACE depends_on: - task_key: "main" test_job: tasks: - task_key: "main_notebook" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/run_unit_test.py source: WORKSPACE libraries: - pypi: package: pytest # These are the targets to use for deployments and workflow runs. One and only one of these # targets can be set to "default: true". targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: true workspace: profile: asset-bundle-tutorial root_path: /Users/${workspace.current_user.userName}/.bundle/${bundle.name}/my-envs/${bundle.target} host: <path to your databricks dev workspace>
Die Bundle-Konfigurationsdatei databricks.yml besteht aus Abschnitten, die als Mappings bezeichnet werden. Diese Mappings ermöglichen es uns, die Konfigurationsdatei in separate logische Blöcke zu modularisieren. Es gibt 8 Mappings auf oberster Ebene:
bündeln
Variablen
Arbeitsplatz
Artefakte
enthalten
Ressourcen
synchronisieren
Ziele
Hier verwenden wir fünf dieser Zuordnungen, um unser Projekt zu organisieren.
Bündel :
Im bundle Mapping legen wir den Namen des Bundles fest. Außerdem können wir hier eine Standard-Cluster-ID festlegen, die für unsere Entwicklungsumgebungen verwendet werden soll, sowie Angaben zur Git-URL und zum Branch.
Variablen :
Wir können die variables verwenden, um benutzerdefinierte Variablen zu definieren und unsere Konfigurationsdatei wiederverwendbarer zu machen. Beispielsweise deklarieren wir eine Variable für die ID eines vorhandenen Clusters und verwenden sie in verschiedenen Workflows. Wenn Sie nun einen anderen Cluster verwenden möchten, müssen Sie nur den Variablenwert ändern.
Ressourcen :
In der resources definieren wir unsere Workflows. Sie enthält null oder jeweils eine der folgenden Zuordnungen: experiments , jobs , models und pipelines . Dies ist im Wesentlichen unsere Datei deployment.yml im dbx-Projekt. Es gibt jedoch einige geringfügige Unterschiede:
- Für die
python_wheel_taskmüssen wir den Pfad zu unserem Wheel-Paket angeben, sonst kann Databricks die Bibliothek nicht finden. Weitere Informationen zum Erstellen von Wheel-Paketen mit DAB finden Sie hier . - Wir können zum Ausführen der Notebook-Aufgaben relative Pfade anstelle von vollständigen Pfaden verwenden. Der Pfad für das bereitzustellende Notebook ist relativ zur Datei
databricks.yml, in der diese Aufgabe deklariert ist.
Ziele :
In der targets definieren wir die Konfigurationen und Ressourcen der verschiedenen Phasen/Umgebungen unserer Projekte. Für eine typische CI/CD-Pipeline hätten wir beispielsweise drei Ziele: Entwicklung, Staging und Produktion. Jedes Ziel kann aus allen Zuordnungen der obersten Ebene (außer targets ) als untergeordnete Zuordnungen bestehen. Hier ist das Schema der Zielzuordnung ( databricks.yml ).
targets: <some-unique-programmatic-identifier-for-this-target>: artifacts: ... bundle: ... compute_id: string default: true | false mode: development resources: ... sync: ... variables: <preceding-unique-variable-name>: <non-default-value> workspace: ...
Mit der untergeordneten Zuordnung können wir die Standardkonfigurationen überschreiben, die wir zuvor in den Zuordnungen der obersten Ebene definiert haben. Wenn wir beispielsweise für jede Phase unserer CI/CD-Pipeline einen isolierten Databricks-Arbeitsbereich haben möchten, sollten wir für jedes Ziel die untergeordnete Arbeitsbereichszuordnung festlegen.
workspace: profile: my-default-profile targets: dev: default: true test: workspace: host: https://<staging-workspace-url> prod: workspace: host: https://<production-workspace-url>
enthalten:
Mit der include Zuordnung können wir unsere Konfigurationsdatei in verschiedene Module aufteilen. Beispielsweise können wir unsere Ressourcen und Variablen in der Datei resources/dev_job.yml speichern und in unsere Datei databricks.yml importieren.
# yaml-language-server: $schema=bundle_config_schema.json bundle: name: DAB_tutorial #our bundle name workspace: profile: asset-bundle-tutorial include: - ./resources/*.yml targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: trueEine detailliertere Erläuterung der DAB-Konfigurationen finden Sie unter Databricks Asset Bundle-Konfigurationen.
Workflows
Die Arbeitsabläufe sind genau die, die ich im vorherigen Blog beschrieben habe. Die einzigen Unterschiede sind der Speicherort der Artefakte und Dateien.


Das Projektskelett
so sieht das fertige Projekt aus
ASSET-BUNDLE-TUTORAL/ ├─ my_package/ │ ├─ tasks/ │ │ ├─ __init__.py │ │ ├─ sample_etl_job.py │ ├─ __init__.py │ ├─ common.py ├─ test/ │ ├─ conftest.py │ ├─ test_sample.py ├─ notebooks/ │ ├─ explorative_analysis.py │ ├─ run_unit_test.py ├─ resources/ │ ├─ dev_jobs.yml ├─ .gitignore ├─ .gitlab-ci.yml ├─ databricks.yml ├─ README.md ├─ setup.py
Validieren, bereitstellen und ausführen
Öffnen Sie nun Ihr Terminal und führen Sie die folgenden Befehle aus dem Stammverzeichnis aus:
validieren: Zuerst sollten wir überprüfen, ob unsere Konfigurationsdatei das richtige Format und die richtige Syntax hat. Wenn die Validierung erfolgreich ist, erhalten Sie eine JSON-Darstellung der Bundle-Konfiguration. Falls ein Fehler auftritt, beheben Sie ihn und führen Sie den Befehl erneut aus, bis Sie die JSON-Datei erhalten.
databricks bundle validate
Bereitstellen: Die Bereitstellung umfasst das Erstellen des Python-Wheel-Pakets und dessen Bereitstellung in unserem Databricks-Arbeitsbereich, die Bereitstellung der Notebooks und anderer Dateien in unserem Databricks-Arbeitsbereich und das Erstellen der Jobs in unseren Databricks-Workflows.
databricks bundle deployWenn keine Befehlsoptionen angegeben sind, verwendet die Databricks-CLI das Standardziel, das in den Bundle-Konfigurationsdateien deklariert ist. Hier haben wir nur ein Ziel, also spielt es keine Rolle, aber um dies zu demonstrieren, können wir auch ein bestimmtes Ziel bereitstellen, indem wir das Flag
-t devverwenden.
ausführen: Die bereitgestellten Jobs ausführen. Hier können wir angeben, welchen Job wir ausführen möchten. Im folgenden Befehl führen wir beispielsweise den Job
test_jobim Entwicklungsziel aus.databricks bundle run -t dev test_job
In der Ausgabe erhalten Sie eine URL, die auf den in Ihrem Arbeitsbereich ausgeführten Job verweist.


Sie können Ihre Jobs auch im Abschnitt „Workflow“ Ihres Databricks-Arbeitsbereichs finden.
CI-Pipeline -Konfiguration
Der allgemeine Aufbau unserer CI-Pipeline bleibt derselbe wie beim vorherigen Projekt. Sie besteht aus zwei Hauptphasen: Testen und Bereitstellen . In der Testphase führt der unit-test-job die Unit-Tests aus und stellt einen separaten Workflow zum Testen bereit. Die Bereitstellungsphase , die nach erfolgreichem Abschluss der Testphase aktiviert wird, übernimmt die Bereitstellung Ihres Haupt-ETL-Workflows.
Hier müssen wir vor jeder Phase zusätzliche Schritte hinzufügen, um Databricks CLI zu installieren und das Authentifizierungsprofil einzurichten. Dies tun wir im Abschnitt before_script unserer CI-Pipeline. Das Schlüsselwort before_script wird verwendet, um ein Array von Befehlen zu definieren, die vor script jedes Jobs ausgeführt werden sollen. Weitere Informationen dazu finden Sie hier .
Optional können Sie das Schlüsselwort after_project verwenden, um ein Array von Befehlen zu definieren, die NACH jedem Job ausgeführt werden sollen. Hier können wir databricks bundle destroy --auto-approve verwenden, um nach Abschluss jedes Jobs aufzuräumen. Im Allgemeinen durchläuft unsere Pipeline diese Schritte:
- Installieren Sie die Databricks-CLI und erstellen Sie ein Konfigurationsprofil.
- Erstellen Sie das Projekt.
- Pushen Sie die Build-Artefakte in den Databricks-Arbeitsbereich.
- Installieren Sie das Wheel-Paket auf Ihrem Cluster.
- Erstellen Sie die Jobs in Databricks-Workflows.
- Führen Sie die Jobs aus.
so sieht unsere .gitlab-ci.yml aus:
image: python:3.9 stages: # List of stages for jobs, and their order of execution - test - deploy default: before_script: - echo "install databricks cli" - curl -V - curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh - echo "databricks CLI installation finished" - echo "create the configuration profile for token authentication" - echo "[asset-bundle-tutorial]" > ~/.databrickscfg - echo "token = $DATABRICKS_TOKEN" >> ~/.databrickscfg - echo "host = $DATABRICKS_HOST" >> ~/.databrickscfg - echo "validate the bundle" - databricks bundle validate after_script: - echo "remove all workflows" #- databricks bundle destroy --auto-approve unit-test-job: # This job runs in the test stage. stage: test script: - echo "Running unit tests." - pip3 install --upgrade wheel setuptools - pip install -e ".[local]" - databricks bundle deploy -t dev - databricks bundle run -t dev test_job deploy-job: # This job runs in the deploy stage. stage: deploy # It only runs when *both* jobs in the test stage complete successfully. script: - echo "Deploying application..." - echo "Install dependencies" - pip install -e ".[local]" - echo "Deploying Job" - databricks bundle deploy -t dev - databricks bundle run -t dev etl_job
Anmerkungen
Hier sind einige Hinweise, die Ihnen beim Einrichten Ihres Bundle-Projekts helfen könnten:
- In diesem Blog haben wir unser Bundle manuell erstellt. Meiner Erfahrung nach hilft dies, die zugrunde liegenden Konzepte und Funktionen besser zu verstehen. Wenn Sie jedoch schnell mit Ihrem Projekt starten möchten, können Sie standardmäßige und nicht standardmäßige Bundle-Vorlagen verwenden, die von Databricks oder anderen Parteien bereitgestellt werden. Lesen Sie diesen Databricks- Beitrag, um zu erfahren, wie Sie ein Projekt mit der standardmäßigen Python-Vorlage starten.
- Wenn Sie Ihren Code mit
databricks bundle deploybereitstellen, führt Databricks CLI den Befehlpython3 setup.py bdist_wheelaus, um Ihr Paket mithilfe der Datei setup.py zu erstellen. Wenn Sie python3 bereits installiert haben, Ihr Computer jedoch den Alias python anstelle von python3 verwendet, treten Probleme auf. Dies lässt sich jedoch leicht beheben. Hier und hier sind beispielsweise zwei Stack Overflow-Threads mit einigen Lösungen.
Was kommt als nächstes
Im nächsten Blogbeitrag werde ich mit meinem ersten Blogbeitrag darüber beginnen, wie man ein Machine-Learning-Projekt auf Databricks startet. Es wird der erste Beitrag in meiner kommenden End-to-End-Pipeline für Machine Learning sein, die alles von der Entwicklung bis zur Produktion abdeckt. Bleiben Sie dran!
Ressourcen
Stellen Sie sicher, dass Sie die Cluster-ID in resources/dev_jobs.yml aktualisieren.
- Von dbx zu Bundles migrieren | Databricks auf AWS
- Entwicklungsaufgaben für Databricks Asset Bundles | Databricks auf AWS
- Bereitstellungsmodi für Databricks Asset Bundle | Databricks auf AWS
- Entwickeln Sie ein Python-Wheel mithilfe von Databricks Asset Bundles | Databricks auf AWS
- Databricks Asset Bundles: Ein standardisierter, einheitlicher Ansatz zur Bereitstellung von Datenprodukten auf Databricks (youtube.com)
- Repo und Folien https://github.com/databricks/databricks-asset-bundles-dais2023








