
























導入
前回のブログでは、 Databricks CLI eXtensionsと GitLab を使用して CI パイプラインを構築する方法を説明しました。この記事では、最新の推奨される Databricks デプロイメント フレームワークである Databricks Asset Bundlesを使用して同じ目的を達成する方法を説明します。DAB は、Databricks プラットフォームの複雑なデータ、分析、ML プロジェクトの開発を効率化する新しいツールとして、Databricks チームによって積極的にサポートおよび開発されています。
DAB とその機能の一般的な紹介は省略し、Databricks のドキュメントを参照してください。ここでは、前回のブログの dbx プロジェクトを DAB に移行する方法に焦点を当てます。その過程で、各ステップをよりよく理解するのに役立ついくつかの概念と機能について説明します。
Databricks GUIを使用した開発パターン
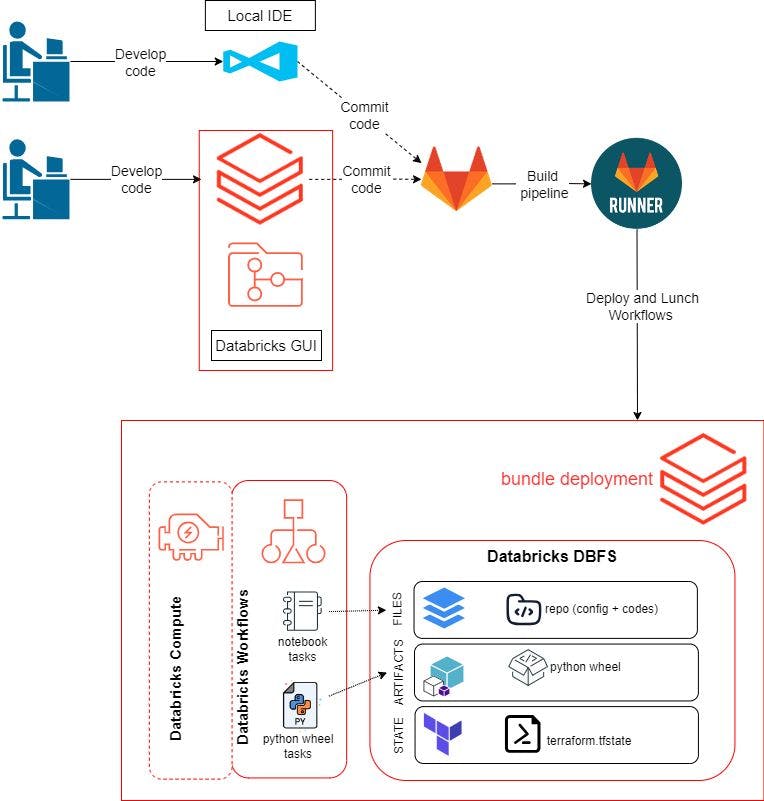
前回の投稿では、Databricks GUI を使用してコードとワークフローを開発およびテストしました。このブログ投稿では、ローカル環境を使用してコードを開発できるようにしたいと考えています。ワークフローは次のようになります。
リモート リポジトリを作成し、それをローカル環境と Databricks ワークスペースにクローンします。ここではGitLabを使用します。
プログラム ロジックを開発し、Databricks GUI 内またはローカル IDE でテストします。これには、Python Wheel パッケージを構築するための Python スクリプト、pytest を使用してデータ品質をテストするためのスクリプト、pytest を実行するためのノートブックが含まれます。
コードを GitLab にプッシュします。git
git pushにより、GitLab Runner がトリガーされ、Databricks Asset Bundles を使用して Databricks 上でリソースをビルド、デプロイ、起動します。開発環境の設定
データブリックスCLI
まず、ローカル マシンに Databricks CLI バージョン 0.205 以上をインストールする必要があります。インストールされている Databricks CLI のバージョンを確認するには、コマンド
databricks -vを実行します。Databricks CLI バージョン 0.205 以上をインストールするには、 「Databricks CLI のインストールまたは更新」を参照してください。認証
Databricks は、開発マシン上の Databricks CLI と Databricks ワークスペース間のさまざまな認証方法をサポートしています。このチュートリアルでは、Databricks 個人アクセス トークン認証を使用します。これは、次の 2 つの手順で構成されます。
- Databricks ワークスペースで個人アクセス トークンを作成します。
- ローカル マシンに Databricks 構成プロファイルを作成します。
Databricks ワークスペースで Databricks トークンを生成するには、「ユーザー設定」→「開発者」→「アクセス トークン」→「管理」→「新しいトークンの生成」に移動します。
構成プロファイルを作成するには、ルート フォルダーに次の内容を含む
~/.databrickscfgファイルを作成します。

[asset-bundle-tutorial] host = https://xxxxxxxxxxx.cloud.databricks.com token = xxxxxxxここで、 asset-bundle-tutorialはプロファイル名、host はワークスペースのアドレス、token は先ほど作成した個人アクセス トークンです。
このファイルは、ターミナルでdatabricks configure --profile asset-bundle-tutorialを実行することで、Databricks CLI を使用して作成できます。このコマンドにより、 Databricks HostとPersonal Access Tokenの入力が求められます。-- --profileフラグを指定しないと、プロファイル名はDEFAULTに設定されます。
Git 統合 (Databricks)
最初のステップとして、 Git の認証情報を設定し、リモート リポジトリを Databricks に接続します。次に、リモート リポジトリを作成し、それを Databricks リポジトリとローカル マシンにクローンします。最後に、Gitlab ランナーの Databricks CLI と Databricks ワークスペース間の認証を設定する必要があります。そのためには、2 つの環境変数DATABRICKS_HOSTとDATABRICKS_TOKENを Gitlab CI/CD パイプライン構成に追加する必要があります。そのためには、Gitlab でリポジトリを開き、 [設定] → [CI/CD] → [変数] → [変数の追加]に移動します。


dbx と DAB はどちらもDatabricks REST APIを中心に構築されているため、本質的には非常に似ています。既存の dbx プロジェクトから手動でバンドルを作成する手順を説明します。
DAB プロジェクトで最初に設定する必要があるのは、デプロイメント構成です。dbx では、環境とワークフロー (ジョブとパイプライン) を定義および設定するために 2 つのファイルを使用します。環境を設定するために.dbx/project.jsonを使用し、ワークフローを定義するために、 deployment.ymlを使用しました。
DAB では、すべてがプロジェクトのルート フォルダーにあるdatabricks.ymlに格納されます。次のようになります。
bundle: name: DAB_tutorial #our bundle name # These are for any custom variables for use throughout the bundle. variables: my_cluster_id: description: The ID of an existing cluster. default: xxxx-xxxxx-xxxxxxxx #The remote workspace URL and workspace authentication credentials are read from the caller's local configuration profile named <asset-bundle-tutorial> workspace: profile: asset-bundle-tutorial # These are the default job and pipeline settings if not otherwise overridden in # the following "targets" top-level mapping. resources: jobs: etl_job: tasks: - task_key: "main" existing_cluster_id: ${var.my_cluster_id} python_wheel_task: package_name: "my_package" entry_point: "etl_job" # take a look at the setup.py entry_points section for details on how to define an entrypoint libraries: - whl: ../dist/*.whl - task_key: "eda" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/explorative_analysis.py source: WORKSPACE depends_on: - task_key: "main" test_job: tasks: - task_key: "main_notebook" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/run_unit_test.py source: WORKSPACE libraries: - pypi: package: pytest # These are the targets to use for deployments and workflow runs. One and only one of these # targets can be set to "default: true". targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: true workspace: profile: asset-bundle-tutorial root_path: /Users/${workspace.current_user.userName}/.bundle/${bundle.name}/my-envs/${bundle.target} host: <path to your databricks dev workspace>
databricks.ymlバンドル構成ファイルは、マッピングと呼ばれるセクションで構成されています。これらのマッピングにより、構成ファイルを個別の論理ブロックにモジュール化できます。トップレベルのマッピングは 8 つあります。
バンドル
変数
ワークスペース
遺物
含む
リソース
同期
ターゲット
ここでは、これらのマッピングを 5 つ使用してプロジェクトを整理します。
バンドル:
bundleマッピングでは、バンドルの名前を定義します。ここでは、開発環境で使用するデフォルトのクラスター ID や、Git URL とブランチに関する情報も定義できます。
変数:
variablesマッピングを使用してカスタム変数を定義し、構成ファイルをより再利用可能にすることができます。たとえば、既存のクラスターの ID の変数を宣言し、それをさまざまなワークフローで使用します。これで、別のクラスターを使用する場合は、変数の値を変更するだけで済みます。
リソース:
resourcesマッピングは、ワークフローを定義する場所です。これには、次のマッピングがそれぞれ 0 個または 1 個含まれます: experiments 、 jobs 、 models 、 pipelines 。これは基本的に、dbx プロジェクトのdeployment.ymlファイルです。ただし、若干の違いがあります。
-
python_wheel_taskの場合、wheel パッケージへのパスを含める必要があります。そうしないと、Databricks はライブラリを見つけることができません。DAB を使用して wheel パッケージを構築する方法の詳細については、こちらを参照してください。 - ノートブック タスクを実行するには、フル パスではなく相対パスを使用できます。デプロイするノートブックのパスは、このタスクが宣言されている
databricks.ymlファイルに相対的です。
ターゲット:
targetsマッピングは、プロジェクトのさまざまなステージ/環境の構成とリソースを定義する場所です。たとえば、一般的な CI/CD パイプラインの場合、開発、ステージング、および運用の 3 つのターゲットがあります。各ターゲットは、子マッピングとしてすべてのトップレベル マッピング ( targetsを除く) で構成できます。ターゲット マッピングのスキーマ ( databricks.yml ) を次に示します。
targets: <some-unique-programmatic-identifier-for-this-target>: artifacts: ... bundle: ... compute_id: string default: true | false mode: development resources: ... sync: ... variables: <preceding-unique-variable-name>: <non-default-value> workspace: ...
子マッピングを使用すると、トップレベル マッピングで以前に定義した既定の構成をオーバーライドできます。たとえば、CI/CD パイプラインの各ステージに分離された Databricks ワークスペースを用意する場合は、ターゲットごとにワークスペースの子マッピングを設定する必要があります。
workspace: profile: my-default-profile targets: dev: default: true test: workspace: host: https://<staging-workspace-url> prod: workspace: host: https://<production-workspace-url>
含む:
includeマッピングを使用すると、構成ファイルをさまざまなモジュールに分割できます。たとえば、リソースと変数をresources/dev_job.ymlファイルに保存し、それをdatabricks.ymlファイルにインポートできます。
# yaml-language-server: $schema=bundle_config_schema.json bundle: name: DAB_tutorial #our bundle name workspace: profile: asset-bundle-tutorial include: - ./resources/*.yml targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: trueDAB構成の詳細な説明については、Databricks Asset Bundle構成をご覧ください。
ワークフロー
ワークフローは、前回のブログで説明したものとまったく同じです。唯一の違いは、成果物とファイルの場所です。


プロジェクトの骨組み
最終的なプロジェクトは次のようになります
ASSET-BUNDLE-TUTORAL/ ├─ my_package/ │ ├─ tasks/ │ │ ├─ __init__.py │ │ ├─ sample_etl_job.py │ ├─ __init__.py │ ├─ common.py ├─ test/ │ ├─ conftest.py │ ├─ test_sample.py ├─ notebooks/ │ ├─ explorative_analysis.py │ ├─ run_unit_test.py ├─ resources/ │ ├─ dev_jobs.yml ├─ .gitignore ├─ .gitlab-ci.yml ├─ databricks.yml ├─ README.md ├─ setup.py
検証、展開、実行
次に、ターミナルを開き、ルート ディレクトリから次のコマンドを実行します。
検証:まず、構成ファイルの形式と構文が正しいかどうかを確認する必要があります。検証が成功すると、バンドル構成の JSON 表現が取得されます。エラーが発生した場合は、それを修正し、JSON ファイルを受け取るまでコマンドを再度実行します。
databricks bundle validate
deploy:デプロイメントには、Python ホイール パッケージの構築と Databricks ワークスペースへのデプロイ、ノートブックとその他のファイルの Databricks ワークスペースへのデプロイ、Databricks ワークフローでのジョブの作成が含まれます。
databricks bundle deployコマンド オプションが指定されていない場合、Databricks CLI はバンドル構成ファイル内で宣言されている既定のターゲットを使用します。ここではターゲットが 1 つしかないため問題はありませんが、これを実証するために、
-t devフラグを使用して特定のターゲットをデプロイすることもできます。
run:デプロイされたジョブを実行します。ここでは、実行するジョブを指定できます。たとえば、次のコマンドでは、dev ターゲットで
test_jobジョブを実行します。databricks bundle run -t dev test_job
出力には、ワークスペースで実行されたジョブを指す URL が表示されます。


Databricks ワークスペースのワークフロー セクションでジョブを見つけることもできます。
CIパイプラインの構成
CI パイプラインの一般的な設定は、以前のプロジェクトと同じです。これは、テストとデプロイという 2 つの主要なステージで構成されます。テストステージでは、 unit-test-jobユニット テストを実行し、テスト用の別のワークフローをデプロイします。テスト ステージが正常に完了するとアクティブになるデプロイステージは、メインの ETL ワークフローのデプロイを処理します。
ここでは、各ステージの前にbefore_script Databricks CLI をインストールして認証プロファイルを設定するための追加手順を追加する必要があります。これは、CI パイプラインのbefore_scriptセクションで行います。before_script キーワードは、各ジョブのscriptコマンドの前に実行するコマンドの配列を定義するために使用されます。詳細については、こちらを参照してください。
オプションで、 after_projectキーワードを使用して、各ジョブの後に実行するコマンドの配列を定義できます。ここでは、各ジョブの終了後にクリーンアップするためにdatabricks bundle destroy --auto-approveを使用できます。一般に、パイプラインは次の手順に従います。
- Databricks CLI をインストールし、構成プロファイルを作成します。
- プロジェクトをビルドします。
- ビルド成果物を Databricks ワークスペースにプッシュします。
- クラスターに wheel パッケージをインストールします。
- Databricks ワークフローでジョブを作成します。
- ジョブを実行します。
.gitlab-ci.yml次のようになります。
image: python:3.9 stages: # List of stages for jobs, and their order of execution - test - deploy default: before_script: - echo "install databricks cli" - curl -V - curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh - echo "databricks CLI installation finished" - echo "create the configuration profile for token authentication" - echo "[asset-bundle-tutorial]" > ~/.databrickscfg - echo "token = $DATABRICKS_TOKEN" >> ~/.databrickscfg - echo "host = $DATABRICKS_HOST" >> ~/.databrickscfg - echo "validate the bundle" - databricks bundle validate after_script: - echo "remove all workflows" #- databricks bundle destroy --auto-approve unit-test-job: # This job runs in the test stage. stage: test script: - echo "Running unit tests." - pip3 install --upgrade wheel setuptools - pip install -e ".[local]" - databricks bundle deploy -t dev - databricks bundle run -t dev test_job deploy-job: # This job runs in the deploy stage. stage: deploy # It only runs when *both* jobs in the test stage complete successfully. script: - echo "Deploying application..." - echo "Install dependencies" - pip install -e ".[local]" - echo "Deploying Job" - databricks bundle deploy -t dev - databricks bundle run -t dev etl_job
ノート
バンドル プロジェクトの設定に役立つ注意事項をいくつか示します。
- このブログでは、バンドルを手動で作成しました。私の経験では、これにより、基礎となる概念と機能をよりよく理解できます。ただし、プロジェクトを迅速に開始したい場合は、Databricks または他の関係者が提供するデフォルトおよび非デフォルトのバンドル テンプレートを使用できます。デフォルトの Python テンプレートを使用してプロジェクトを開始する方法については、この Databricks の投稿をご覧ください。
-
databricks bundle deployを使用してコードをデプロイすると、Databricks CLI はコマンドpython3 setup.py bdist_wheelを実行し、 setup.pyファイルを使用してパッケージをビルドします。 python3が既にインストールされているが、マシンがpython3ではなくpythonエイリアスを使用している場合は、問題が発生します。 ただし、これは簡単に修正できます。 たとえば、こことここには、いくつかの解決策が記載された 2 つの Stack Overflow スレッドがあります。
次は何ですか
次のブログ投稿では、Databricks で機械学習プロジェクトを開始する方法についての最初のブログ投稿から始めます。これは、開発から本番までのすべてを網羅した、今後のエンドツーエンドの機械学習パイプラインの最初の投稿になります。お楽しみに!
リソース
resources/dev_jobs.ymlのcluster_idを更新してください。
- dbx からバンドルへの移行 | AWS 上の Databricks
- Databricks アセットバンドルの開発作業タスク | AWS 上の Databricks
- Databricks アセットバンドルのデプロイメントモード | AWS 上の Databricks
- Databricks アセットバンドルを使用して Python ホイールを開発する | AWS 上の Databricks
- Databricks アセット バンドル: Databricks にデータ製品を展開するための標準的で統一されたアプローチ (youtube.com)








