
























Введение
В предыдущем блоге я показал, как построить конвейер CI с помощью расширений Databricks CLI и GitLab. В этом посте я покажу вам, как достичь той же цели с помощью новейшей и рекомендуемой среды развертывания Databricks — Databricks Asset Bundles . Команда Databricks активно поддерживает и разрабатывает DAB как новый инструмент для оптимизации разработки сложных данных, аналитики и проектов машинного обучения для платформы Databricks.
Я пропущу общее представление о DAB и его функциях и отсылаю вас к документации Databricks. Здесь я сосредоточусь на том, как перенести наш проект dbx из предыдущего блога на DAB. Попутно я объясню некоторые концепции и функции, которые помогут вам лучше понять каждый шаг.
Шаблон разработки с использованием графического интерфейса Databricks
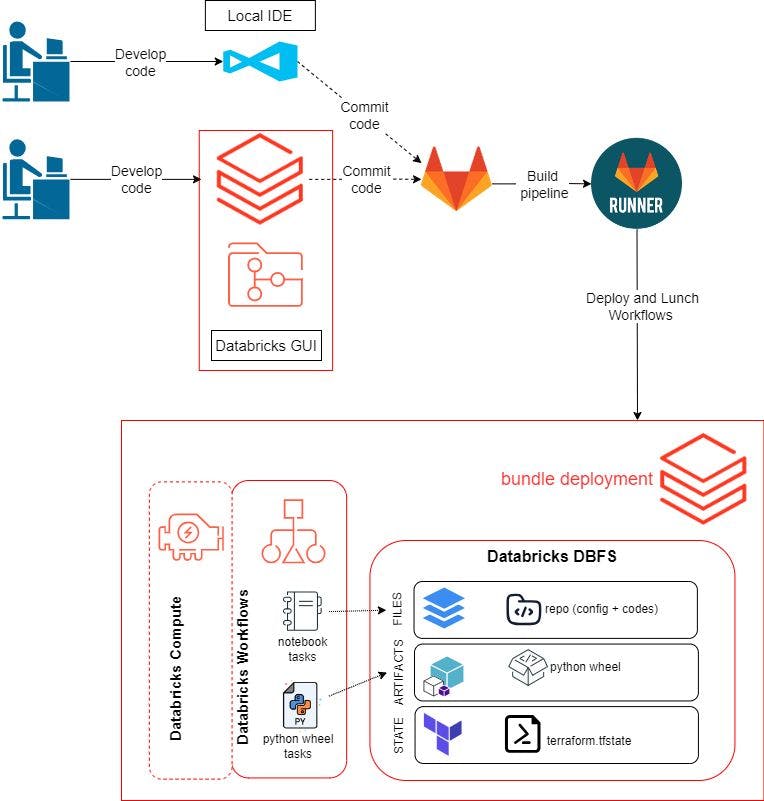
В предыдущем посте мы использовали графический интерфейс Databricks для разработки и тестирования нашего кода и рабочих процессов. В этом сообщении блога мы хотим иметь возможность использовать нашу локальную среду и для разработки нашего кода. Рабочий процесс будет следующим:
Создайте удаленный репозиторий и клонируйте его в нашу локальную среду и рабочую область Databricks. Здесь мы используем GitLab .
Разработайте логику программы и протестируйте ее в графическом интерфейсе Databricks или в нашей локальной IDE. Сюда входят скрипты Python для создания пакета Python Wheel, скрипты для проверки качества данных с помощью pytest и блокнот для запуска pytest.
Отправьте код в GitLab.
git pushзапустит GitLab Runner для создания, развертывания и запуска ресурсов на Databricks с использованием пакетов активов Databricks.Настройка среды разработки
Интерфейс командной строки блоков данных
Прежде всего нам необходимо установить Databricks CLI версии 0.205 или выше на ваш локальный компьютер. Чтобы проверить установленную версию интерфейса командной строки Databricks, выполните команду
databricks -v. Чтобы установить Databricks CLI версии 0,205 или более поздней версии, см. раздел Установка или обновление Databricks CLI .Аутентификация
Databricks поддерживает различные методы аутентификации между интерфейсом командной строки Databricks на нашей машине разработки и вашей рабочей областью Databricks. В этом руководстве мы используем аутентификацию токена личного доступа Databricks. Он состоит из двух шагов:
- Создайте личный токен доступа в нашей рабочей области Databricks.
- Создайте профиль конфигурации Databricks на нашем локальном компьютере.
Чтобы создать токен Databricks в рабочей области Databricks, перейдите в «Настройки пользователя» → «Разработчик» → «Токены доступа» → «Управление» → «Создать новый токен».
Чтобы создать профиль конфигурации, создайте файл
~/.databrickscfgв корневой папке со следующим содержимым:

[asset-bundle-tutorial] host = https://xxxxxxxxxxx.cloud.databricks.com token = xxxxxxx Здесь asset-bundle-tutorial — это имя нашего профиля, хост — это адрес нашей рабочей области, а токен — это токен личного доступа, который мы только что создали.
Вы можете создать этот файл с помощью интерфейса командной строки Databricks, запустив databricks configure --profile asset-bundle-tutorial в своем терминале. Команда запросит у вас хост Databricks и личный токен доступа . Если вы не укажете флаг --profile , имя профиля будет установлено на DEFAULT .
Интеграция с Git (Databricks)
В качестве первого шага мы настраиваем учетные данные Git и подключаем удаленный репозиторий к Databricks . Далее мы создаем удаленный репозиторий и клонируем его в наш репозиторий Databricks , а также на нашу локальную машину. Наконец, нам нужно настроить аутентификацию между интерфейсом командной строки Databricks в бегуне Gitlab и нашей рабочей областью Databricks. Для этого нам нужно добавить две переменные среды, DATABRICKS_HOST и DATABRICKS_TOKEN в наши конфигурации конвейера Gitlab CI/CD. Для этого откройте репозиторий в Gitlab, выберите «Настройки» → CI/CD → «Переменные» → «Добавить переменные».


И dbx, и DAB построены на основе REST API Databricks , поэтому по своей сути они очень похожи. Я расскажу, как вручную создать пакет из существующего проекта dbx.
Первое, что нам нужно настроить для нашего проекта DAB, — это конфигурация развертывания. В dbx мы используем два файла для определения и настройки наших сред и рабочих процессов (заданий и конвейеров). Для настройки среды мы использовали .dbx/project.json , а для определения рабочих процессов — deployment.yml .
В DAB все хранится в databricks.yml , который находится в корневой папке вашего проекта. Вот как это выглядит:
bundle: name: DAB_tutorial #our bundle name # These are for any custom variables for use throughout the bundle. variables: my_cluster_id: description: The ID of an existing cluster. default: xxxx-xxxxx-xxxxxxxx #The remote workspace URL and workspace authentication credentials are read from the caller's local configuration profile named <asset-bundle-tutorial> workspace: profile: asset-bundle-tutorial # These are the default job and pipeline settings if not otherwise overridden in # the following "targets" top-level mapping. resources: jobs: etl_job: tasks: - task_key: "main" existing_cluster_id: ${var.my_cluster_id} python_wheel_task: package_name: "my_package" entry_point: "etl_job" # take a look at the setup.py entry_points section for details on how to define an entrypoint libraries: - whl: ../dist/*.whl - task_key: "eda" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/explorative_analysis.py source: WORKSPACE depends_on: - task_key: "main" test_job: tasks: - task_key: "main_notebook" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/run_unit_test.py source: WORKSPACE libraries: - pypi: package: pytest # These are the targets to use for deployments and workflow runs. One and only one of these # targets can be set to "default: true". targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: true workspace: profile: asset-bundle-tutorial root_path: /Users/${workspace.current_user.userName}/.bundle/${bundle.name}/my-envs/${bundle.target} host: <path to your databricks dev workspace>
Файл конфигурации пакета databricks.yml состоит из разделов, называемых сопоставлениями. Эти сопоставления позволяют нам разбить файл конфигурации на отдельные логические блоки. Существует 8 сопоставлений верхнего уровня:
пучок
переменные
Рабочее пространство
артефакты
включать
Ресурсы
синхронизировать
цели
Здесь мы используем пять из этих сопоставлений для организации нашего проекта.
пучок :
В сопоставлении bundle мы определяем имя пакета. Здесь мы также можем определить идентификатор кластера по умолчанию, который следует использовать для наших сред разработки, а также информацию об URL-адресе и ветке Git.
переменные :
Мы можем использовать сопоставление variables , чтобы определить пользовательские переменные и сделать наш файл конфигурации более пригодным для повторного использования. Например, мы объявляем переменную для идентификатора существующего кластера и используем ее в разных рабочих процессах. Теперь, если вы хотите использовать другой кластер, все, что вам нужно сделать, это изменить значение переменной.
Ресурсы :
Сопоставление resources — это то, где мы определяем наши рабочие процессы. Он включает ноль или одно из следующих сопоставлений: experiments , jobs , models и pipelines . По сути, это наш файл deployment.yml в проекте dbx. Хотя есть небольшие отличия:
- Для
python_wheel_taskмы должны указать путь к нашему пакету колеса; в противном случае Databricks не сможет найти библиотеку. Дополнительную информацию о создании пакетов колес с использованием DAB можно найти здесь . - Мы можем использовать относительные пути вместо полных путей для запуска задач записной книжки. Путь к развертыванию записной книжки определяется относительно файла
databricks.yml, в котором объявлена эта задача.
цели :
Сопоставление targets — это то место, где мы определяем конфигурации и ресурсы различных этапов/сред наших проектов. Например, для типичного конвейера CI/CD у нас будет три цели: разработка, подготовка и производство. Каждая цель может состоять из всех сопоставлений верхнего уровня (кроме targets ) в качестве дочерних сопоставлений. Вот схема целевого сопоставления ( databricks.yml ).
targets: <some-unique-programmatic-identifier-for-this-target>: artifacts: ... bundle: ... compute_id: string default: true | false mode: development resources: ... sync: ... variables: <preceding-unique-variable-name>: <non-default-value> workspace: ...
Дочернее сопоставление позволяет нам переопределить конфигурации по умолчанию, которые мы определили ранее в сопоставлениях верхнего уровня. Например, если мы хотим иметь изолированное рабочее пространство Databricks для каждого этапа нашего конвейера CI/CD, нам следует установить дочернее сопоставление рабочего пространства для каждой цели.
workspace: profile: my-default-profile targets: dev: default: true test: workspace: host: https://<staging-workspace-url> prod: workspace: host: https://<production-workspace-url>
включать:
Сопоставление include позволяет нам разбить наш файл конфигурации на разные модули. Например, мы можем сохранить наши ресурсы и переменные в файле resources/dev_job.yml и импортировать их в наш файл databricks.yml .
# yaml-language-server: $schema=bundle_config_schema.json bundle: name: DAB_tutorial #our bundle name workspace: profile: asset-bundle-tutorial include: - ./resources/*.yml targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: trueДля более подробного объяснения конфигураций DAB ознакомьтесь с конфигурациями Databricks Asset Bundle.
Рабочие процессы
Рабочие процессы именно такие, как я описал в предыдущем блоге. Единственные различия — это расположение артефактов и файлов.


Скелет проекта
вот как выглядит окончательный проект
ASSET-BUNDLE-TUTORAL/ ├─ my_package/ │ ├─ tasks/ │ │ ├─ __init__.py │ │ ├─ sample_etl_job.py │ ├─ __init__.py │ ├─ common.py ├─ test/ │ ├─ conftest.py │ ├─ test_sample.py ├─ notebooks/ │ ├─ explorative_analysis.py │ ├─ run_unit_test.py ├─ resources/ │ ├─ dev_jobs.yml ├─ .gitignore ├─ .gitlab-ci.yml ├─ databricks.yml ├─ README.md ├─ setup.py
Проверка, развертывание и запуск
Теперь откройте терминал и выполните следующие команды из корневого каталога:
проверка: во-первых, мы должны проверить, имеет ли наш файл конфигурации правильный формат и синтаксис. Если проверка пройдет успешно, вы получите JSON-представление конфигурации пакета. В случае ошибки исправьте ее и запускайте команду еще раз, пока не получите файл JSON.
databricks bundle validate
развертывание: развертывание включает в себя создание пакета колеса Python и его развертывание в нашей рабочей области Databricks, развертывание записных книжек и других файлов в нашей рабочей области Databricks, а также создание заданий в наших рабочих процессах Databricks.
databricks bundle deployЕсли параметры команды не указаны, интерфейс командной строки Databricks использует цель по умолчанию, объявленную в файлах конфигурации пакета. Здесь у нас есть только одна цель, поэтому это не имеет значения, но чтобы продемонстрировать это, мы также можем развернуть конкретную цель, используя флаг
-t dev.
run: запустить развернутые задания. Здесь мы можем указать, какое задание мы хотим запустить. Например, в следующей команде мы запускаем задание
test_jobв цели dev.databricks bundle run -t dev test_job
в выходных данных вы получаете URL-адрес, указывающий на задание, выполняемое в вашем рабочем пространстве.


Вы также можете найти свои вакансии в разделе «Рабочий процесс» рабочей области Databricks.
Конфигурация конвейера CI
Общая настройка нашего конвейера CI остается такой же, как и в предыдущем проекте. Он состоит из двух основных этапов: тестирования и развертывания . На этапе тестирования unit-test-job запускает модульные тесты и развертывает отдельный рабочий процесс для тестирования. Этап развертывания , активируемый после успешного завершения этапа тестирования, отвечает за развертывание основного рабочего процесса ETL.
Здесь нам нужно добавить дополнительные шаги перед каждым этапом установки Databricks CLI и настройки профиля аутентификации. Мы делаем это в разделе before_script нашего конвейера CI. Ключевое слово before_script используется для определения массива команд, которые должны выполняться перед командами script каждого задания. Подробнее об этом можно узнать здесь .
При желании вы можете использовать ключевое слово after_project , чтобы определить массив команд, которые должны выполняться ПОСЛЕ каждого задания. Здесь мы можем использовать databricks bundle destroy --auto-approve для очистки после завершения каждого задания. В целом наш конвейер проходит следующие этапы:
- Установите интерфейс командной строки Databricks и создайте профиль конфигурации.
- Постройте проект.
- Отправьте артефакты сборки в рабочую область Databricks.
- Установите пакет Wheel в свой кластер.
- Создайте задания в рабочих процессах Databricks.
- Выполняйте задания.
вот как выглядит наш .gitlab-ci.yml :
image: python:3.9 stages: # List of stages for jobs, and their order of execution - test - deploy default: before_script: - echo "install databricks cli" - curl -V - curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh - echo "databricks CLI installation finished" - echo "create the configuration profile for token authentication" - echo "[asset-bundle-tutorial]" > ~/.databrickscfg - echo "token = $DATABRICKS_TOKEN" >> ~/.databrickscfg - echo "host = $DATABRICKS_HOST" >> ~/.databrickscfg - echo "validate the bundle" - databricks bundle validate after_script: - echo "remove all workflows" #- databricks bundle destroy --auto-approve unit-test-job: # This job runs in the test stage. stage: test script: - echo "Running unit tests." - pip3 install --upgrade wheel setuptools - pip install -e ".[local]" - databricks bundle deploy -t dev - databricks bundle run -t dev test_job deploy-job: # This job runs in the deploy stage. stage: deploy # It only runs when *both* jobs in the test stage complete successfully. script: - echo "Deploying application..." - echo "Install dependencies" - pip install -e ".[local]" - echo "Deploying Job" - databricks bundle deploy -t dev - databricks bundle run -t dev etl_job
Примечания
Вот несколько примечаний, которые могут помочь вам настроить проект пакета:
- В этом блоге мы создали наш пакет вручную. По моему опыту, это помогает лучше понять основные концепции и функции. Но если вы хотите быстро начать работу над своим проектом, вы можете использовать шаблоны пакетов по умолчанию и не по умолчанию, предоставленные Databricks или другими сторонами. Прочтите этот пост Databricks, чтобы узнать, как инициировать проект с помощью шаблона Python по умолчанию.
- Когда вы развертываете свой код с помощью
databricks bundle deploy, Databricks CLI запускает командуpython3 setup.py bdist_wheelдля сборки вашего пакета с использованием файла setup.py . Если у вас уже установлен Python3 , но ваш компьютер использует псевдоним Python вместо Python3 , у вас возникнут проблемы. Однако это легко исправить. Например, здесь и здесь есть две темы Stack Overflow с некоторыми решениями.
Что дальше
В следующем посте я начну со своего первого поста о том, как запустить проект машинного обучения на Databricks. Это будет первая статья в моем предстоящем комплексном цикле машинного обучения, охватывающем все: от разработки до производства. Следите за обновлениями!
Ресурсы
Обязательно обновите идентификатор кластера в resources/dev_jobs.yml
- Переход с dbx на пакеты | Блоки данных на AWS
- Рабочие задачи по разработке Databricks Asset Bundles | Блоки данных на AWS
- Режимы развертывания Databricks Asset Bundle | Блоки данных на AWS
- Разработайте колесо Python с помощью пакетов ресурсов Databricks | Блоки данных на AWS
- Пакеты активов Databricks: стандартный унифицированный подход к развертыванию продуктов данных на Databricks (youtube.com)
- репозиторий и слайды https://github.com/databricks/databricks-asset-bundles-dais2023








