










































Jan 01, 1970
3,864 रीडिंग
डेटाब्रिक्स एसेट बंडल और गिटलैब के साथ CI पाइपलाइन का निर्माण
बहुत लंबा; पढ़ने के लिए
पिछले ब्लॉग में, मैंने आपको दिखाया था कि डेटाब्रिक्स CLI एक्सटेंशन और GitLab का उपयोग करके CI पाइपलाइन कैसे बनाई जाती है। इस पोस्ट में, मैं आपको दिखाऊंगा कि नवीनतम और अनुशंसित डेटाब्रिक्स परिनियोजन फ्रेमवर्क, डेटाब्रिक्स एसेट बंडल के साथ समान उद्देश्य कैसे प्राप्त किया जाए।‘vibrant, futuristic lego land emerges from the depths, with neon lights illuminating the skyline. Amidst the bustling particles in the sky, various cranes are building some structure with bricks on top of each other.’ Image created by HackerNoon AI Image Generator
परिचय
पिछले ब्लॉग में, मैंने आपको दिखाया कि डेटाब्रिक्स CLI एक्सटेंशन और GitLab का उपयोग करके CI पाइपलाइन कैसे बनाई जाती है। इस पोस्ट में, मैं आपको दिखाऊंगा कि नवीनतम और अनुशंसित डेटाब्रिक्स परिनियोजन ढांचे, डेटाब्रिक्स एसेट बंडल के साथ समान उद्देश्य कैसे प्राप्त किया जाए। डेटाब्रिक्स प्लेटफ़ॉर्म के लिए जटिल डेटा, एनालिटिक्स और एमएल परियोजनाओं के विकास को सुव्यवस्थित करने के लिए एक नए उपकरण के रूप में डेटाब्रिक्स टीम द्वारा DAB को सक्रिय रूप से समर्थित और विकसित किया गया है।
मैं DAB और इसकी विशेषताओं के सामान्य परिचय को छोड़कर आपको Databricks दस्तावेज़ों का संदर्भ दूंगा। यहाँ, मैं इस बात पर ध्यान केंद्रित करूँगा कि हमारे dbx प्रोजेक्ट को पिछले ब्लॉग से DAB में कैसे माइग्रेट किया जाए। साथ ही, मैं कुछ अवधारणाओं और विशेषताओं के बारे में बताऊंगा जो आपको प्रत्येक चरण को बेहतर ढंग से समझने में मदद कर सकती हैं।
डेटाब्रिक्स GUI का उपयोग करके विकास पैटर्न
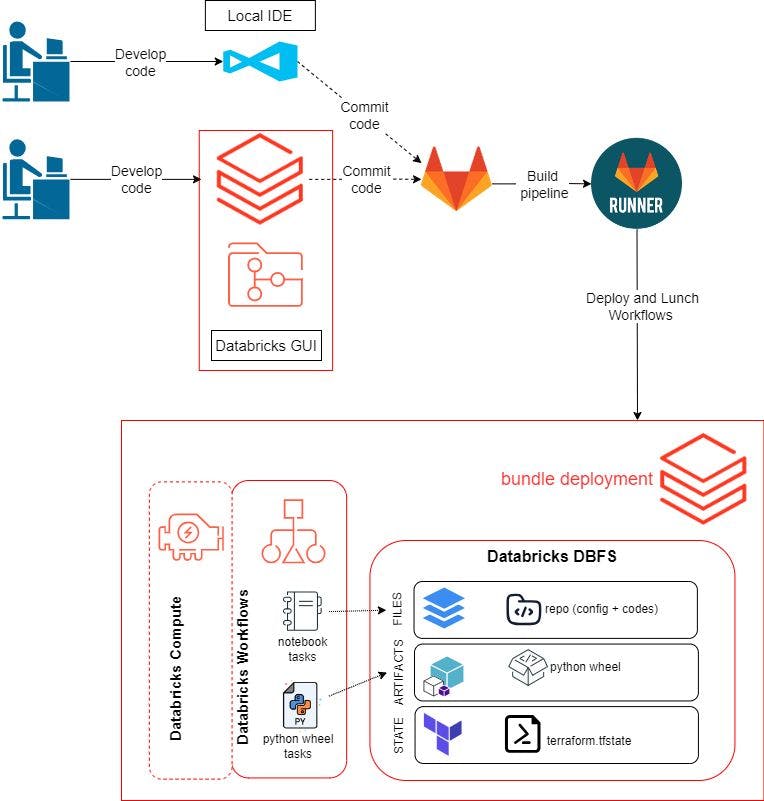
पिछली पोस्ट में, हमने अपने कोड और वर्कफ़्लो को विकसित करने और परीक्षण करने के लिए डेटाब्रिक्स GUI का उपयोग किया था। इस ब्लॉग पोस्ट के लिए, हम अपने कोड को विकसित करने के लिए अपने स्थानीय वातावरण का उपयोग करने में सक्षम होना चाहते हैं। वर्कफ़्लो इस प्रकार होगा:
एक रिमोट रिपॉजिटरी बनाएं और इसे हमारे स्थानीय वातावरण और डेटाब्रिक्स वर्कस्पेस पर क्लोन करें। हम यहां GitLab का उपयोग करते हैं।
प्रोग्राम लॉजिक विकसित करें और इसे डेटाब्रिक्स GUI के अंदर या हमारे स्थानीय IDE पर परीक्षण करें। इसमें पायथन व्हील पैकेज बनाने के लिए पायथन स्क्रिप्ट, pytest का उपयोग करके डेटा गुणवत्ता का परीक्षण करने के लिए स्क्रिप्ट और pytest चलाने के लिए एक नोटबुक शामिल है।
कोड को GitLab पर पुश करें।
git push, Databricks Asset Bundles का उपयोग करके Databricks पर संसाधनों का निर्माण, परिनियोजन और लॉन्च करने के लिए GitLab Runner को ट्रिगर करेगा।अपना विकास परिवेश स्थापित करना
डेटाब्रिक्स सीएलआई
सबसे पहले, हमें आपके स्थानीय मशीन पर Databricks CLI संस्करण 0.205 या उससे ऊपर स्थापित करने की आवश्यकता है। Databricks CLI के अपने स्थापित संस्करण की जाँच करने के लिए, कमांड
databricks -vचलाएँ। Databricks CLI संस्करण 0.205 या उससे ऊपर स्थापित करने के लिए, Databricks CLI को स्थापित या अपडेट करें देखें।प्रमाणीकरण
डेटाब्रिक्स हमारे विकास मशीन पर डेटाब्रिक्स CLI और आपके डेटाब्रिक्स कार्यक्षेत्र के बीच विभिन्न प्रमाणीकरण विधियों का समर्थन करता है। इस ट्यूटोरियल के लिए, हम डेटाब्रिक्स व्यक्तिगत एक्सेस टोकन प्रमाणीकरण का उपयोग करते हैं। इसमें दो चरण होते हैं:
- हमारे डेटाब्रिक्स कार्यक्षेत्र पर एक व्यक्तिगत एक्सेस टोकन बनाएं।
- अपनी स्थानीय मशीन पर एक डेटाब्रिक्स कॉन्फ़िगरेशन प्रोफ़ाइल बनाएं।
अपने डेटाब्रिक्स कार्यक्षेत्र में डेटाब्रिक्स टोकन उत्पन्न करने के लिए, उपयोगकर्ता सेटिंग्स → डेवलपर → एक्सेस टोकन → प्रबंधित करें → नया टोकन उत्पन्न करें पर जाएं।
कॉन्फ़िगरेशन प्रोफ़ाइल बनाने के लिए, अपने रूट फ़ोल्डर में निम्नलिखित सामग्री के साथ
~/.databrickscfgफ़ाइल बनाएँ:
[asset-bundle-tutorial] host = https://xxxxxxxxxxx.cloud.databricks.com token = xxxxxxx यहां, asset-bundle-tutorial हमारा प्रोफ़ाइल नाम है, होस्ट हमारे कार्यक्षेत्र का पता है, और टोकन व्यक्तिगत एक्सेस टोकन है जिसे हमने अभी बनाया है।
आप अपने टर्मिनल में databricks configure --profile asset-bundle-tutorial चलाकर Databricks CLI का उपयोग करके यह फ़ाइल बना सकते हैं। कमांड आपको Databricks होस्ट और पर्सनल एक्सेस टोकन के लिए संकेत देगा। यदि आप --profile फ़्लैग निर्दिष्ट नहीं करते हैं, तो प्रोफ़ाइल नाम DEFAULT पर सेट हो जाएगा।
Git एकीकरण (डेटाब्रिक्स)
पहले चरण के रूप में, हम Git क्रेडेंशियल कॉन्फ़िगर करते हैं और एक रिमोट रिपो को Databricks से जोड़ते हैं। इसके बाद, हम एक रिमोट रिपोजिटरी बनाते हैं और इसे अपने Databricks रिपो के साथ-साथ अपनी स्थानीय मशीन पर क्लोन करते हैं । अंत में हमें Gitlab रनर पर Databricks CLI और हमारे Databricks वर्कस्पेस के बीच प्रमाणीकरण सेट अप करने की आवश्यकता है। ऐसा करने के लिए, हमें अपने Gitlab CI/CD पाइपलाइन कॉन्फ़िगरेशन में दो पर्यावरण चर, DATABRICKS_HOST और DATABRICKS_TOKEN जोड़ने चाहिए। इसके लिए Gitlab में अपना रिपो खोलें, सेटिंग्स→ CI/CD → वैरिएबल्स → वैरिएबल्स जोड़ें पर जाएँ
dbx और DAB दोनों ही Databricks REST API के इर्द-गिर्द बने हैं, इसलिए उनके मूल में, वे बहुत समान हैं। मैं अपने मौजूदा dbx प्रोजेक्ट से मैन्युअल रूप से बंडल बनाने के लिए चरणों से गुज़रूँगा।
पहली चीज़ जो हमें अपने DAB प्रोजेक्ट के लिए सेट अप करने की ज़रूरत है, वह है डिप्लॉयमेंट कॉन्फ़िगरेशन। dbx में, हम अपने वातावरण और वर्कफ़्लो (जॉब और पाइपलाइन) को परिभाषित करने और सेट अप करने के लिए दो फ़ाइलों का उपयोग करते हैं । वातावरण को सेट अप करने के लिए, हमने .dbx/project.json उपयोग किया, और वर्कफ़्लो को परिभाषित करने के लिए, हमने deployment.yml उपयोग किया।
DAB में, सब कुछ databricks.yml में चला जाता है, जो आपके प्रोजेक्ट के रूट फ़ोल्डर में स्थित होता है। यह इस तरह दिखता है:
bundle: name: DAB_tutorial #our bundle name # These are for any custom variables for use throughout the bundle. variables: my_cluster_id: description: The ID of an existing cluster. default: xxxx-xxxxx-xxxxxxxx #The remote workspace URL and workspace authentication credentials are read from the caller's local configuration profile named <asset-bundle-tutorial> workspace: profile: asset-bundle-tutorial # These are the default job and pipeline settings if not otherwise overridden in # the following "targets" top-level mapping. resources: jobs: etl_job: tasks: - task_key: "main" existing_cluster_id: ${var.my_cluster_id} python_wheel_task: package_name: "my_package" entry_point: "etl_job" # take a look at the setup.py entry_points section for details on how to define an entrypoint libraries: - whl: ../dist/*.whl - task_key: "eda" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/explorative_analysis.py source: WORKSPACE depends_on: - task_key: "main" test_job: tasks: - task_key: "main_notebook" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/run_unit_test.py source: WORKSPACE libraries: - pypi: package: pytest # These are the targets to use for deployments and workflow runs. One and only one of these # targets can be set to "default: true". targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: true workspace: profile: asset-bundle-tutorial root_path: /Users/${workspace.current_user.userName}/.bundle/${bundle.name}/my-envs/${bundle.target} host: <path to your databricks dev workspace>
databricks.yml बंडल कॉन्फ़िगरेशन फ़ाइल में मैपिंग नामक अनुभाग होते हैं। ये मैपिंग हमें कॉन्फ़िगरेशन फ़ाइल को अलग-अलग तार्किक ब्लॉक में मॉड्यूलर करने की अनुमति देते हैं। 8 शीर्ष-स्तरीय मैपिंग हैं:
बंडल
चर
कार्यस्थान
कलाकृतियों
शामिल करना
संसाधन
साथ-साथ करना
लक्ष्यों को
यहां, हम अपनी परियोजना को व्यवस्थित करने के लिए इनमें से पांच मैपिंग का उपयोग करते हैं।
बंडल :
bundle मैपिंग में, हम बंडल का नाम परिभाषित करते हैं। यहाँ, हम एक डिफ़ॉल्ट क्लस्टर आईडी भी परिभाषित कर सकते हैं जिसका उपयोग हमारे विकास वातावरण के लिए किया जाना चाहिए, साथ ही Git URL और शाखा के बारे में जानकारी भी।
चर :
हम कस्टम वैरिएबल को परिभाषित करने और अपनी कॉन्फ़िगरेशन फ़ाइल को अधिक पुन: प्रयोज्य बनाने के लिए variables मैपिंग का उपयोग कर सकते हैं। उदाहरण के लिए, हम किसी मौजूदा क्लस्टर की आईडी के लिए एक वैरिएबल घोषित करते हैं और इसे विभिन्न वर्कफ़्लो में उपयोग करते हैं। अब, यदि आप किसी भिन्न क्लस्टर का उपयोग करना चाहते हैं, तो आपको बस वैरिएबल मान बदलना होगा।
संसाधन :
resources मैपिंग वह जगह है जहाँ हम अपने वर्कफ़्लो को परिभाषित करते हैं। इसमें निम्नलिखित मैपिंग में से प्रत्येक में से शून्य या एक शामिल है: experiments , jobs , models और pipelines । यह मूल रूप से dbx प्रोजेक्ट में हमारी deployment.yml फ़ाइल है। हालाँकि कुछ छोटे अंतर हैं:
-
python_wheel_taskके लिए, हमें अपने व्हील पैकेज का पथ शामिल करना होगा; अन्यथा, डेटाब्रिक्स लाइब्रेरी नहीं ढूँढ सकता। आप DAB का उपयोग करके व्हील पैकेज बनाने के बारे में अधिक जानकारी यहाँ पा सकते हैं। - हम नोटबुक कार्यों को चलाने के लिए पूर्ण पथों के बजाय सापेक्ष पथों का उपयोग कर सकते हैं। नोटबुक को तैनात करने के लिए पथ उस
databricks.ymlफ़ाइल से सापेक्ष है जिसमें यह कार्य घोषित किया गया है।
लक्ष्य :
targets मैपिंग वह जगह है जहाँ हम अपनी परियोजनाओं के विभिन्न चरणों/वातावरणों के विन्यास और संसाधनों को परिभाषित करते हैं। उदाहरण के लिए, एक सामान्य CI/CD पाइपलाइन के लिए, हमारे पास तीन लक्ष्य होंगे: विकास, स्टेजिंग और उत्पादन। प्रत्येक लक्ष्य में चाइल्ड मैपिंग के रूप में सभी शीर्ष-स्तरीय मैपिंग ( targets छोड़कर) शामिल हो सकते हैं। यहाँ लक्ष्य मैपिंग ( databricks.yml ) की स्कीमा दी गई है।
targets: <some-unique-programmatic-identifier-for-this-target>: artifacts: ... bundle: ... compute_id: string default: true | false mode: development resources: ... sync: ... variables: <preceding-unique-variable-name>: <non-default-value> workspace: ...
चाइल्ड मैपिंग हमें डिफ़ॉल्ट कॉन्फ़िगरेशन को ओवरराइड करने की अनुमति देती है जिसे हमने पहले शीर्ष-स्तरीय मैपिंग में परिभाषित किया था। उदाहरण के लिए, यदि हम अपनी CI/CD पाइपलाइन के प्रत्येक चरण के लिए एक अलग डेटाब्रिक्स वर्कस्पेस रखना चाहते हैं, तो हमें प्रत्येक लक्ष्य के लिए वर्कस्पेस चाइल्ड मैपिंग सेट करनी चाहिए।
workspace: profile: my-default-profile targets: dev: default: true test: workspace: host: https://<staging-workspace-url> prod: workspace: host: https://<production-workspace-url>
शामिल करना:
include मैपिंग हमें अपनी कॉन्फ़िगरेशन फ़ाइल को अलग-अलग मॉड्यूल में विभाजित करने की अनुमति देती है। उदाहरण के लिए, हम अपने संसाधनों और चर को resources/dev_job.yml फ़ाइल में सहेज सकते हैं और इसे अपनी databricks.yml फ़ाइल में आयात कर सकते हैं।
# yaml-language-server: $schema=bundle_config_schema.json bundle: name: DAB_tutorial #our bundle name workspace: profile: asset-bundle-tutorial include: - ./resources/*.yml targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: trueDAB कॉन्फ़िगरेशन के अधिक विस्तृत विवरण के लिए डेटाब्रिक्स एसेट बंडल कॉन्फ़िगरेशन देखें
वर्कफ़्लो
वर्कफ़्लो बिल्कुल वैसा ही है जैसा मैंने पिछले ब्लॉग में बताया था। अंतर केवल आर्टिफैक्ट्स और फ़ाइलों के स्थान का है।
परियोजना का ढांचा
अंतिम परियोजना कुछ इस प्रकार दिखती है
ASSET-BUNDLE-TUTORAL/ ├─ my_package/ │ ├─ tasks/ │ │ ├─ __init__.py │ │ ├─ sample_etl_job.py │ ├─ __init__.py │ ├─ common.py ├─ test/ │ ├─ conftest.py │ ├─ test_sample.py ├─ notebooks/ │ ├─ explorative_analysis.py │ ├─ run_unit_test.py ├─ resources/ │ ├─ dev_jobs.yml ├─ .gitignore ├─ .gitlab-ci.yml ├─ databricks.yml ├─ README.md ├─ setup.py
सत्यापित करें, तैनात करें और चलाएं
अब, अपना टर्मिनल खोलें और रूट निर्देशिका से निम्नलिखित कमांड चलाएँ:
मान्य करें: सबसे पहले, हमें यह जांचना चाहिए कि हमारी कॉन्फ़िगरेशन फ़ाइल में सही फ़ॉर्मेट और सिंटैक्स है या नहीं। अगर सत्यापन सफल होता है, तो आपको बंडल कॉन्फ़िगरेशन का JSON प्रतिनिधित्व मिलेगा। किसी त्रुटि के मामले में, इसे ठीक करें और JSON फ़ाइल प्राप्त होने तक कमांड को फिर से चलाएँ।
databricks bundle validate
तैनाती: तैनाती में पायथन व्हील पैकेज का निर्माण करना और इसे हमारे डेटाब्रिक्स कार्यक्षेत्र में तैनात करना, नोटबुक और अन्य फ़ाइलों को हमारे डेटाब्रिक्स कार्यक्षेत्र में तैनात करना और हमारे डेटाब्रिक्स वर्कफ़्लो में नौकरियों का निर्माण करना शामिल है।
databricks bundle deployयदि कोई कमांड विकल्प निर्दिष्ट नहीं है, तो डेटाब्रिक्स CLI बंडल कॉन्फ़िगरेशन फ़ाइलों के भीतर घोषित डिफ़ॉल्ट लक्ष्य का उपयोग करता है। यहाँ, हमारे पास केवल एक लक्ष्य है इसलिए इससे कोई फर्क नहीं पड़ता, लेकिन इसे प्रदर्शित करने के लिए, हम
-t devफ़्लैग का उपयोग करके एक विशिष्ट लक्ष्य को भी तैनात कर सकते हैं।
रन: तैनात जॉब्स को चलाएं। यहां, हम निर्दिष्ट कर सकते हैं कि हम कौन सी जॉब चलाना चाहते हैं। उदाहरण के लिए, निम्न कमांड में, हम dev लक्ष्य में
test_jobजॉब चलाते हैं।databricks bundle run -t dev test_job
आउटपुट में आपको एक यूआरएल मिलता है जो आपके कार्यक्षेत्र में चल रहे कार्य की ओर इशारा करता है।
आप अपने डेटाब्रिक्स कार्यक्षेत्र के वर्कफ़्लो अनुभाग में भी अपनी नौकरियां पा सकते हैं।
CI पाइपलाइन कॉन्फ़िगरेशन
हमारी CI पाइपलाइन का सामान्य सेटअप पिछले प्रोजेक्ट जैसा ही रहता है। इसमें दो मुख्य चरण होते हैं: परीक्षण और तैनाती । परीक्षण चरण में, unit-test-job यूनिट परीक्षण चलाता है और परीक्षण के लिए एक अलग वर्कफ़्लो तैनात करता है। परीक्षण चरण के सफल समापन पर सक्रिय किया गया तैनाती चरण आपके मुख्य ETL वर्कफ़्लो की तैनाती को संभालता है।
यहाँ, हमें Databricks CLI को स्थापित करने और प्रमाणीकरण प्रोफ़ाइल सेट अप करने के लिए प्रत्येक चरण से पहले अतिरिक्त चरण जोड़ने होंगे। हम इसे अपने CI पाइपलाइन के before_script अनुभाग में करते हैं। before_script कीवर्ड का उपयोग कमांड की एक सरणी को परिभाषित करने के लिए किया जाता है जिसे प्रत्येक जॉब के script कमांड से पहले चलाया जाना चाहिए। इसके बारे में अधिक जानकारी यहाँ पाई जा सकती है।
वैकल्पिक रूप से, आप after_project कीवर्ड का उपयोग करके कमांड की एक सरणी निर्धारित कर सकते हैं जिसे प्रत्येक कार्य के बाद चलाया जाना चाहिए। यहाँ, हम प्रत्येक कार्य के समाप्त होने के बाद सफाई करने के लिए databricks bundle destroy --auto-approve उपयोग कर सकते हैं। सामान्य तौर पर, हमारी पाइपलाइन इन चरणों से गुज़रती है:
- डेटाब्रिक्स CLI स्थापित करें और कॉन्फ़िगरेशन प्रोफ़ाइल बनाएं।
- परियोजना का निर्माण करें.
- बिल्ड आर्टिफैक्ट्स को डेटाब्रिक्स वर्कस्पेस पर पुश करें।
- अपने क्लस्टर पर व्हील पैकेज स्थापित करें।
- डेटाब्रिक्स वर्कफ़्लोज़ पर नौकरियां बनाएं।
- नौकरियाँ चलाओ.
हमारा .gitlab-ci.yml इस प्रकार दिखता है:
image: python:3.9 stages: # List of stages for jobs, and their order of execution - test - deploy default: before_script: - echo "install databricks cli" - curl -V - curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh - echo "databricks CLI installation finished" - echo "create the configuration profile for token authentication" - echo "[asset-bundle-tutorial]" > ~/.databrickscfg - echo "token = $DATABRICKS_TOKEN" >> ~/.databrickscfg - echo "host = $DATABRICKS_HOST" >> ~/.databrickscfg - echo "validate the bundle" - databricks bundle validate after_script: - echo "remove all workflows" #- databricks bundle destroy --auto-approve unit-test-job: # This job runs in the test stage. stage: test script: - echo "Running unit tests." - pip3 install --upgrade wheel setuptools - pip install -e ".[local]" - databricks bundle deploy -t dev - databricks bundle run -t dev test_job deploy-job: # This job runs in the deploy stage. stage: deploy # It only runs when *both* jobs in the test stage complete successfully. script: - echo "Deploying application..." - echo "Install dependencies" - pip install -e ".[local]" - echo "Deploying Job" - databricks bundle deploy -t dev - databricks bundle run -t dev etl_job
टिप्पणियाँ
यहां कुछ नोट्स दिए गए हैं जो आपको अपना बंडल प्रोजेक्ट सेट करने में मदद कर सकते हैं:
- इस ब्लॉग में, हमने अपना बंडल मैन्युअल रूप से बनाया है। मेरे अनुभव में, यह अंतर्निहित अवधारणाओं और सुविधाओं को बेहतर ढंग से समझने में मदद करता है। लेकिन अगर आप अपने प्रोजेक्ट को तेज़ी से शुरू करना चाहते हैं, तो आप डेटाब्रिक्स या अन्य पार्टियों द्वारा प्रदान किए गए डिफ़ॉल्ट और गैर-डिफ़ॉल्ट बंडल टेम्प्लेट का उपयोग कर सकते हैं। डिफ़ॉल्ट पायथन टेम्प्लेट के साथ प्रोजेक्ट शुरू करने के तरीके के बारे में जानने के लिए इस डेटाब्रिक्स पोस्ट को देखें।
- जब आप
databricks bundle deployका उपयोग करके अपना कोड तैनात करते हैं, तो डेटाब्रिक्स CLI सेटअप .py फ़ाइल का उपयोग करके आपके पैकेज को बनाने के लिएpython3 setup.py bdist_wheelकमांड चलाता है। यदि आपके पास पहले से ही python3 इंस्टॉल है, लेकिन आपकी मशीन python3 के बजाय python उपनाम का उपयोग करती है, तो आपको समस्याओं का सामना करना पड़ेगा। हालाँकि, इसे ठीक करना आसान है। उदाहरण के लिए, यहाँ और यहाँ कुछ समाधानों के साथ दो स्टैक ओवरफ़्लो थ्रेड हैं।
आगे क्या होगा
अगले ब्लॉग पोस्ट में, मैं डेटाब्रिक्स पर मशीन लर्निंग प्रोजेक्ट कैसे शुरू करें, इस पर अपने पहले ब्लॉग पोस्ट से शुरुआत करूँगा। यह मेरी आगामी एंड-टू-एंड मशीन लर्निंग पाइपलाइन में पहला पोस्ट होगा, जिसमें विकास से लेकर उत्पादन तक सब कुछ शामिल होगा। बने रहें!
साधन
सुनिश्चित करें कि आपने resources/dev_jobs.yml में cluster_id को अपडेट कर दिया है
- dbx से बंडलों पर माइग्रेट करें | AWS पर डेटाब्रिक्स
- डेटाब्रिक्स एसेट बंडल्स विकास कार्य | AWS पर डेटाब्रिक्स
- डेटाब्रिक्स एसेट बंडल परिनियोजन मोड | AWS पर डेटाब्रिक्स
- डेटाब्रिक्स एसेट बंडल का उपयोग करके पायथन व्हील विकसित करें | AWS पर डेटाब्रिक्स
- डेटाब्रिक्स एसेट बंडल: डेटाब्रिक्स पर डेटा उत्पादों को तैनात करने के लिए एक मानक, एकीकृत दृष्टिकोण (youtube.com)
- रेपो और स्लाइड्स https://github.com/databricks/databricks-asset-bundles-dais2023
L O A D I N G
. . . comments & more!
. . . comments & more!



