
























Introducción
En el blog anterior , le mostré cómo crear una canalización de CI utilizando Databricks CLI eXtensions y GitLab. En esta publicación, le mostraré cómo lograr el mismo objetivo con el marco de implementación de Databricks más reciente y recomendado, Databricks Asset Bundles . DAB cuenta con el apoyo y desarrollo activo del equipo de Databricks como una nueva herramienta para agilizar el desarrollo de proyectos complejos de datos, análisis y aprendizaje automático para la plataforma Databricks.
Me saltaré la introducción general de DAB y sus características y lo remitiré a la documentación de Databricks. Aquí, me centraré en cómo migrar nuestro proyecto dbx del blog anterior a DAB. A lo largo del camino, explicaré algunos conceptos y características que pueden ayudarte a comprender mejor cada paso.
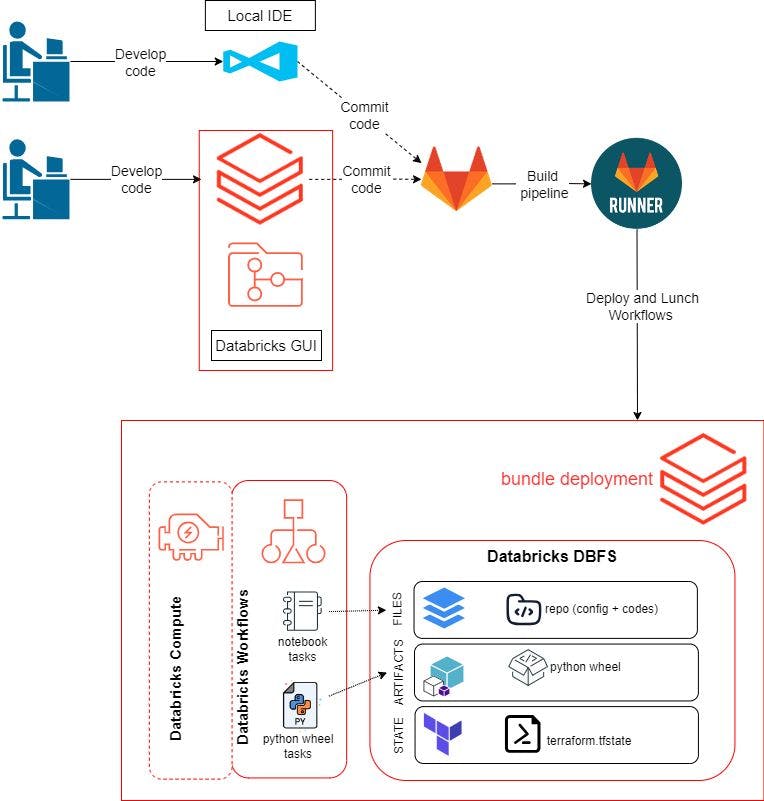
Patrón de desarrollo usando la GUI de Databricks
En la publicación anterior, utilizamos la GUI de Databricks para desarrollar y probar nuestro código y flujos de trabajo. Para esta publicación de blog, también queremos poder usar nuestro entorno local para desarrollar nuestro código. El flujo de trabajo será el siguiente:
Cree un repositorio remoto y clónelo en nuestro entorno local y espacio de trabajo de Databricks. Usamos GitLab aquí.
Desarrolle la lógica del programa y pruébela dentro de la GUI de Databricks o en nuestro IDE local. Esto incluye scripts de Python para crear un paquete Python Wheel, scripts para probar la calidad de los datos usando pytest y un cuaderno para ejecutar pytest.
Envíe el código a GitLab.
git pushactivará un GitLab Runner para crear, implementar y lanzar recursos en Databricks mediante Databricks Asset Bundles.Configurar sus entornos de desarrollo
CLI de ladrillos de datos
En primer lugar, necesitamos instalar la versión 0.205 o superior de la CLI de Databricks en su máquina local. Para comprobar su versión instalada de la CLI de Databricks, ejecute el comando
databricks -v. Para instalar la CLI de Databricks versión 0.205 o superior, consulte Instalar o actualizar la CLI de Databricks .Autenticación
Databricks admite varios métodos de autenticación entre la CLI de Databricks en nuestra máquina de desarrollo y su espacio de trabajo de Databricks. Para este tutorial, utilizamos la autenticación de token de acceso personal de Databricks. Consiste en dos pasos:
- Cree un token de acceso personal en nuestro espacio de trabajo de Databricks.
- Cree un perfil de configuración de Databricks en nuestra máquina local.
Para generar un token de Databricks en su espacio de trabajo de Databricks, vaya a Configuración de usuario → Desarrollador → Tokens de acceso → Administrar → Generar nuevo token.
Para crear un perfil de configuración, cree el archivo
~/.databrickscfgen su carpeta raíz con el siguiente contenido:

[asset-bundle-tutorial] host = https://xxxxxxxxxxx.cloud.databricks.com token = xxxxxxx Aquí, el asset-bundle-tutorial es nuestro nombre de perfil, el host es la dirección de nuestro espacio de trabajo y el token es el token de acceso personal que acabamos de crear.
Puede crear este archivo mediante la CLI de Databricks ejecutando databricks configure --profile asset-bundle-tutorial en su terminal. El comando le solicitará el host de Databricks y el token de acceso personal . Si no especifica el indicador --profile , el nombre del perfil se establecerá en DEFAULT .
Integración de Git (Databricks)
Como primer paso, configuramos las credenciales de Git y conectamos un repositorio remoto a Databricks . A continuación, creamos un repositorio remoto y lo clonamos en nuestro repositorio de Databricks , así como en nuestra máquina local. Finalmente, necesitamos configurar la autenticación entre la CLI de Databricks en el ejecutor de Gitlab y nuestro espacio de trabajo de Databricks. Para hacer eso, debemos agregar dos variables de entorno, DATABRICKS_HOST y DATABRICKS_TOKEN a nuestras configuraciones de canalización CI/CD de Gitlab. Para eso, abra su repositorio en Gitlab, vaya a Configuración → CI/CD → Variables → Agregar variables


Tanto dbx como DAB se basan en las API REST de Databricks , por lo que, en esencia, son muy similares. Seguiré los pasos para crear un paquete manualmente desde nuestro proyecto dbx existente.
Lo primero que debemos configurar para nuestro proyecto DAB es la configuración de implementación. En dbx, utilizamos dos archivos para definir y configurar nuestros entornos y flujos de trabajo (trabajos y canalizaciones). Para configurar el entorno, utilizamos .dbx/project.json y para definir los flujos de trabajo, utilizamos deployment.yml .
En DAB, todo va a databricks.yml , que se encuentra en la carpeta raíz de su proyecto. Así es como se ve:
bundle: name: DAB_tutorial #our bundle name # These are for any custom variables for use throughout the bundle. variables: my_cluster_id: description: The ID of an existing cluster. default: xxxx-xxxxx-xxxxxxxx #The remote workspace URL and workspace authentication credentials are read from the caller's local configuration profile named <asset-bundle-tutorial> workspace: profile: asset-bundle-tutorial # These are the default job and pipeline settings if not otherwise overridden in # the following "targets" top-level mapping. resources: jobs: etl_job: tasks: - task_key: "main" existing_cluster_id: ${var.my_cluster_id} python_wheel_task: package_name: "my_package" entry_point: "etl_job" # take a look at the setup.py entry_points section for details on how to define an entrypoint libraries: - whl: ../dist/*.whl - task_key: "eda" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/explorative_analysis.py source: WORKSPACE depends_on: - task_key: "main" test_job: tasks: - task_key: "main_notebook" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/run_unit_test.py source: WORKSPACE libraries: - pypi: package: pytest # These are the targets to use for deployments and workflow runs. One and only one of these # targets can be set to "default: true". targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: true workspace: profile: asset-bundle-tutorial root_path: /Users/${workspace.current_user.userName}/.bundle/${bundle.name}/my-envs/${bundle.target} host: <path to your databricks dev workspace>
El archivo de configuración del paquete databricks.yml consta de secciones denominadas asignaciones. Estas asignaciones nos permiten modularizar el archivo de configuración en bloques lógicos separados. Hay 8 asignaciones de nivel superior:
manojo
variables
espacio de trabajo
artefactos
incluir
recursos
sincronizar
objetivos
Aquí, utilizamos cinco de estos mapeos para organizar nuestro proyecto.
manojo :
En el mapeo bundle , definimos el nombre del paquete. Aquí, también podemos definir una ID de clúster predeterminada que debe usarse para nuestros entornos de desarrollo, así como información sobre la URL y la rama de Git.
variables :
Podemos usar el mapeo variables para definir variables personalizadas y hacer que nuestro archivo de configuración sea más reutilizable. Por ejemplo, declaramos una variable para el ID de un clúster existente y la usamos en diferentes flujos de trabajo. Ahora, en caso de que quieras utilizar un clúster diferente, todo lo que tienes que hacer es cambiar el valor de la variable.
recursos :
El mapeo resources es donde definimos nuestros flujos de trabajo. Incluye cero o una de cada una de las siguientes asignaciones: experiments , jobs , models y pipelines . Este es básicamente nuestro archivo deployment.yml en el proyecto dbx. Aunque hay algunas diferencias menores:
- Para
python_wheel_task, debemos incluir la ruta a nuestro paquete wheel; de lo contrario, Databricks no puede encontrar la biblioteca. Puede encontrar más información sobre la creación de paquetes de ruedas utilizando DAB aquí . - Podemos usar rutas relativas en lugar de rutas completas para ejecutar las tareas del cuaderno. La ruta de acceso para la implementación del cuaderno es relativa al archivo
databricks.ymlen el que se declara esta tarea.
objetivos :
El mapeo targets es donde definimos las configuraciones y recursos de las diferentes etapas/entornos de nuestros proyectos. Por ejemplo, para un proceso típico de CI/CD, tendríamos tres objetivos: desarrollo, puesta en escena y producción. Cada objetivo puede constar de todas las asignaciones de nivel superior (excepto targets ) como asignaciones secundarias. Este es el esquema de la asignación de destino ( databricks.yml ).
targets: <some-unique-programmatic-identifier-for-this-target>: artifacts: ... bundle: ... compute_id: string default: true | false mode: development resources: ... sync: ... variables: <preceding-unique-variable-name>: <non-default-value> workspace: ...
La asignación secundaria nos permite anular las configuraciones predeterminadas que definimos anteriormente en las asignaciones de nivel superior. Por ejemplo, si queremos tener un área de trabajo de Databricks aislada para cada etapa de nuestra canalización de CI/CD, debemos configurar la asignación secundaria del área de trabajo para cada destino.
workspace: profile: my-default-profile targets: dev: default: true test: workspace: host: https://<staging-workspace-url> prod: workspace: host: https://<production-workspace-url>
incluir:
El mapeo include nos permite dividir nuestro archivo de configuración en diferentes módulos. Por ejemplo, podemos guardar nuestros recursos y variables en el archivo resources/dev_job.yml e importarlo a nuestro archivo databricks.yml .
# yaml-language-server: $schema=bundle_config_schema.json bundle: name: DAB_tutorial #our bundle name workspace: profile: asset-bundle-tutorial include: - ./resources/*.yml targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: truePara obtener una explicación más detallada de las configuraciones de DAB, consulte las configuraciones de Databricks Asset Bundle
Flujos de trabajo
Los flujos de trabajo son exactamente lo que describí en el blog anterior. La única diferencia es la ubicación de los artefactos y archivos.


El esqueleto del proyecto
así es como se ve el proyecto final
ASSET-BUNDLE-TUTORAL/ ├─ my_package/ │ ├─ tasks/ │ │ ├─ __init__.py │ │ ├─ sample_etl_job.py │ ├─ __init__.py │ ├─ common.py ├─ test/ │ ├─ conftest.py │ ├─ test_sample.py ├─ notebooks/ │ ├─ explorative_analysis.py │ ├─ run_unit_test.py ├─ resources/ │ ├─ dev_jobs.yml ├─ .gitignore ├─ .gitlab-ci.yml ├─ databricks.yml ├─ README.md ├─ setup.py
Validar, implementar y ejecutar
Ahora, abra su terminal y ejecute los siguientes comandos desde el directorio raíz:
validar: Primero, debemos verificar si nuestro archivo de configuración tiene el formato y la sintaxis correctos. Si la validación tiene éxito, obtendrá una representación JSON de la configuración del paquete. En caso de error, corríjalo y ejecute el comando nuevamente hasta que reciba el archivo JSON.
databricks bundle validate
implementar: la implementación incluye crear el paquete de rueda de Python e implementarlo en nuestro espacio de trabajo de Databricks, implementar los cuadernos y otros archivos en nuestro espacio de trabajo de Databricks y crear los trabajos en nuestros flujos de trabajo de Databricks.
databricks bundle deploySi no se especifica ninguna opción de comando, la CLI de Databricks usa el destino predeterminado tal como se declara en los archivos de configuración del paquete. Aquí solo tenemos un objetivo, por lo que no importa, pero para demostrarlo, también podemos implementar un objetivo específico usando el indicador
-t dev.
ejecutar: ejecuta los trabajos implementados. Aquí podemos especificar qué trabajo queremos ejecutar. Por ejemplo, en el siguiente comando, ejecutamos el trabajo
test_joben el destino de desarrollo.databricks bundle run -t dev test_job
en el resultado obtienes una URL que apunta al trabajo ejecutado en tu espacio de trabajo.


También puede encontrar sus trabajos en la sección Flujo de trabajo de su espacio de trabajo de Databricks.
Configuración de canalización de CI
La configuración general de nuestro canal de CI sigue siendo la misma que la del proyecto anterior. Consta de dos etapas principales: prueba e implementación . En la etapa de prueba , el unit-test-job ejecuta las pruebas unitarias e implementa un flujo de trabajo separado para las pruebas. La etapa de implementación , que se activa al completar exitosamente la etapa de prueba, maneja la implementación de su flujo de trabajo ETL principal.
Aquí, tenemos que agregar pasos adicionales antes de cada etapa para instalar la CLI de Databricks y configurar el perfil de autenticación. Hacemos esto en la sección before_script de nuestra canalización de CI. La palabra clave before_script se utiliza para definir una serie de comandos que deben ejecutarse antes de los comandos script de cada trabajo. Puede encontrar más información aquí .
Opcionalmente, puede utilizar la palabra clave after_project para definir una serie de comandos que deben ejecutarse DESPUÉS de cada trabajo. Aquí, podemos usar databricks bundle destroy --auto-approve para limpiar después de finalizar cada trabajo. En general, nuestro proceso sigue estos pasos:
- Instale la CLI de Databricks y cree un perfil de configuración.
- Construya el proyecto.
- Inserte los artefactos de compilación en el área de trabajo de Databricks.
- Instale el paquete de ruedas en su grupo.
- Cree los trabajos en flujos de trabajo de Databricks.
- Ejecute los trabajos.
Así es como se ve nuestro .gitlab-ci.yml :
image: python:3.9 stages: # List of stages for jobs, and their order of execution - test - deploy default: before_script: - echo "install databricks cli" - curl -V - curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh - echo "databricks CLI installation finished" - echo "create the configuration profile for token authentication" - echo "[asset-bundle-tutorial]" > ~/.databrickscfg - echo "token = $DATABRICKS_TOKEN" >> ~/.databrickscfg - echo "host = $DATABRICKS_HOST" >> ~/.databrickscfg - echo "validate the bundle" - databricks bundle validate after_script: - echo "remove all workflows" #- databricks bundle destroy --auto-approve unit-test-job: # This job runs in the test stage. stage: test script: - echo "Running unit tests." - pip3 install --upgrade wheel setuptools - pip install -e ".[local]" - databricks bundle deploy -t dev - databricks bundle run -t dev test_job deploy-job: # This job runs in the deploy stage. stage: deploy # It only runs when *both* jobs in the test stage complete successfully. script: - echo "Deploying application..." - echo "Install dependencies" - pip install -e ".[local]" - echo "Deploying Job" - databricks bundle deploy -t dev - databricks bundle run -t dev etl_job
Notas
Aquí hay algunas notas que podrían ayudarlo a configurar su proyecto de paquete:
- En este blog, creamos nuestro paquete manualmente. En mi experiencia, esto ayuda a comprender mejor los conceptos y características subyacentes. Pero si desea comenzar rápidamente su proyecto, puede usar plantillas de paquete predeterminadas y no predeterminadas proporcionadas por Databricks u otras partes. Consulte esta publicación de Databricks para obtener información sobre cómo iniciar un proyecto con la plantilla predeterminada de Python.
- Cuando implementa su código mediante
databricks bundle deploy, la CLI de Databricks ejecuta el comandopython3 setup.py bdist_wheelpara compilar su paquete usando el archivo setup.py . Si ya tiene python3 instalado pero su máquina usa el alias de python en lugar de python3 , tendrá problemas. Sin embargo, esto es fácil de solucionar. Por ejemplo, aquí y aquí hay dos subprocesos de Stack Overflow con algunas soluciones.
Que sigue
En la próxima publicación de blog, comenzaré con mi primera publicación de blog sobre cómo iniciar un proyecto de aprendizaje automático en Databricks. Será la primera publicación de mi próximo proceso de aprendizaje automático de un extremo a otro, que cubrirá todo, desde el desarrollo hasta la producción. ¡Manténganse al tanto!
Recursos
Asegúrese de actualizar cluster_id en resources/dev_jobs.yml
- Migrar de dbx a paquetes | Ladrillos de datos en AWS
- Tareas de trabajo de desarrollo de Databricks Asset Bundles | Ladrillos de datos en AWS
- Modos de implementación del paquete de activos de Databricks | Ladrillos de datos en AWS
- Desarrollar una rueda de Python mediante paquetes de activos de Databricks | Ladrillos de datos en AWS
- Paquetes de activos de Databricks: un enfoque estándar y unificado para implementar productos de datos en Databricks (youtube.com)
- repositorio y diapositivas https://github.com/databricks/databricks-asset-bundles-dais2023








