
























ভূমিকা
আগের ব্লগে , আমি আপনাকে দেখিয়েছিলাম কিভাবে ডেটাব্রিক্স সিএলআই এক্সটেনশন এবং গিটল্যাব ব্যবহার করে একটি সিআই পাইপলাইন তৈরি করতে হয়। এই পোস্টে, আমি আপনাকে দেখাব কিভাবে সর্বশেষ এবং প্রস্তাবিত Databricks স্থাপনার কাঠামো, Databricks Asset Bundles এর সাথে একই উদ্দেশ্য অর্জন করা যায়। ডাটাব্রিক্স প্ল্যাটফর্মের জন্য জটিল ডেটা, অ্যানালিটিক্স এবং এমএল প্রকল্পগুলির বিকাশকে স্ট্রিমলাইন করার জন্য একটি নতুন হাতিয়ার হিসাবে DAB সক্রিয়ভাবে ডেটাব্রিক্স দল দ্বারা সমর্থিত এবং বিকাশ করে।
আমি DAB এর সাধারণ পরিচিতি এবং এর বৈশিষ্ট্যগুলি এড়িয়ে যাব এবং আপনাকে ডেটাব্রিক্স ডকুমেন্টেশনে উল্লেখ করব। এখানে, আমি কীভাবে আমাদের dbx প্রজেক্টকে আগের ব্লগ থেকে DAB-তে স্থানান্তরিত করতে হয় তার উপর ফোকাস করব। পথ ধরে, আমি কিছু ধারণা এবং বৈশিষ্ট্য ব্যাখ্যা করব যা আপনাকে প্রতিটি পদক্ষেপকে আরও ভালভাবে বুঝতে সাহায্য করতে পারে।
Databricks GUI ব্যবহার করে ডেভেলপমেন্ট প্যাটার্ন
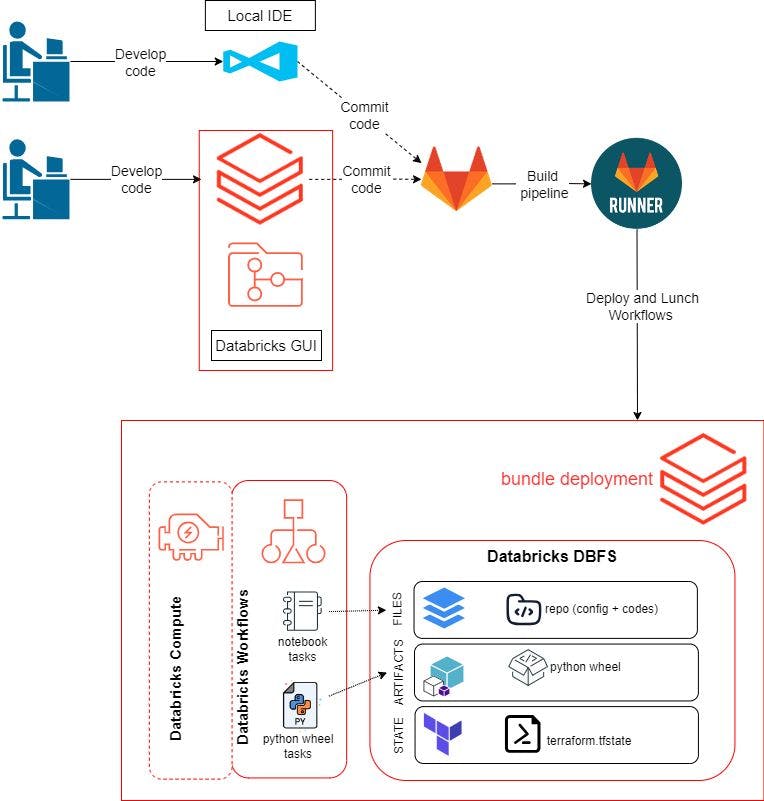
আগের পোস্টে, আমরা আমাদের কোড এবং ওয়ার্কফ্লোগুলি বিকাশ এবং পরীক্ষা করতে ডেটাব্রিক্স জিইউআই ব্যবহার করেছি। এই ব্লগ পোস্টের জন্য, আমরা আমাদের কোড বিকাশের জন্য আমাদের স্থানীয় পরিবেশ ব্যবহার করতে সক্ষম হতে চাই। কর্মপ্রবাহ নিম্নরূপ হবে:
একটি দূরবর্তী সংগ্রহস্থল তৈরি করুন এবং এটিকে আমাদের স্থানীয় পরিবেশ এবং ডেটাব্রিক্স কর্মক্ষেত্রে ক্লোন করুন। আমরা এখানে গিটল্যাব ব্যবহার করি।
প্রোগ্রাম লজিক ডেভেলপ করুন এবং ডেটাব্রিক্স GUI এর ভিতরে বা আমাদের স্থানীয় IDE-তে পরীক্ষা করুন। এর মধ্যে পাইথন হুইল প্যাকেজ তৈরি করার জন্য পাইথন স্ক্রিপ্ট, পাইটেস্ট ব্যবহার করে ডেটার গুণমান পরীক্ষা করার জন্য স্ক্রিপ্ট এবং পাইটেস্ট চালানোর জন্য একটি নোটবুক অন্তর্ভুক্ত রয়েছে।
কোডটি গিটল্যাবে পুশ করুন।
git pushডেটাব্রিক্স অ্যাসেট বান্ডেল ব্যবহার করে ডেটাব্রিক্সে সংস্থান তৈরি, স্থাপন এবং লঞ্চ করতে একটি গিটল্যাব রানারকে ট্রিগার করবে।আপনার উন্নয়ন পরিবেশ সেট আপ করা
ডেটাব্রিক্স CLI
প্রথমত, আমাদের আপনার স্থানীয় মেশিনে Databricks CLI সংস্করণ 0.205 বা তার উপরে ইনস্টল করতে হবে। Databricks CLI এর আপনার ইনস্টল করা সংস্করণ পরীক্ষা করতে, কমান্ড চালান
databricks -v। Databricks CLI সংস্করণ 0.205 বা তার উপরে ইনস্টল করতে, Databricks CLI ইনস্টল বা আপডেট দেখুন।প্রমাণীকরণ
Databricks আমাদের ডেভেলপমেন্ট মেশিনে Databricks CLI এবং আপনার Databricks ওয়ার্কস্পেসের মধ্যে বিভিন্ন প্রমাণীকরণ পদ্ধতি সমর্থন করে। এই টিউটোরিয়ালের জন্য, আমরা ডেটাব্রিক্স ব্যক্তিগত অ্যাক্সেস টোকেন প্রমাণীকরণ ব্যবহার করি। এটি দুটি ধাপ নিয়ে গঠিত:
- আমাদের Databricks কর্মক্ষেত্রে একটি ব্যক্তিগত অ্যাক্সেস টোকেন তৈরি করুন।
- আমাদের স্থানীয় মেশিনে একটি ডেটাব্রিক্স কনফিগারেশন প্রোফাইল তৈরি করুন।
আপনার Databricks ওয়ার্কস্পেসে একটি Databricks টোকেন তৈরি করতে, User Settings → Developer → Access Tokens → Manage → Generate New Token-এ যান।
একটি কনফিগারেশন প্রোফাইল তৈরি করতে, নিম্নলিখিত বিষয়বস্তু সহ আপনার রুট ফোল্ডারে
~/.databrickscfgফাইলটি তৈরি করুন:

[asset-bundle-tutorial] host = https://xxxxxxxxxxx.cloud.databricks.com token = xxxxxxx এখানে, asset-bundle-tutorial হল আমাদের প্রোফাইল নাম, হোস্ট হল আমাদের কর্মক্ষেত্রের ঠিকানা, এবং টোকেন হল ব্যক্তিগত অ্যাক্সেস টোকেন যা আমরা এইমাত্র তৈরি করেছি।
আপনি আপনার টার্মিনালে databricks configure --profile asset-bundle-tutorial চালিয়ে Databricks CLI ব্যবহার করে এই ফাইলটি তৈরি করতে পারেন। কমান্ড আপনাকে ডেটাব্রিক্স হোস্ট এবং ব্যক্তিগত অ্যাক্সেস টোকেনের জন্য অনুরোধ করবে। আপনি যদি --profile পতাকা নির্দিষ্ট না করেন, প্রোফাইল নামটি DEFAULT সেট করা হবে।
গিট ইন্টিগ্রেশন (ডেটাব্রিক্স)
প্রথম পদক্ষেপ হিসাবে, আমরা গিট শংসাপত্রগুলি কনফিগার করি এবং ডেটাব্রিক্সে একটি দূরবর্তী রেপো সংযুক্ত করি । এর পরে, আমরা একটি দূরবর্তী সংগ্রহস্থল তৈরি করি এবং এটিকে আমাদের ডেটাব্রিক্স রেপোতে, সেইসাথে আমাদের স্থানীয় মেশিনে ক্লোন করি । অবশেষে আমাদের গিটল্যাব রানারে ডেটাব্রিক্স সিএলআই এবং আমাদের ডেটাব্রিক্স ওয়ার্কস্পেসের মধ্যে প্রমাণীকরণ সেট আপ করতে হবে। এটি করার জন্য, আমাদের Gitlab CI/CD পাইপলাইন কনফিগারেশনে দুটি পরিবেশের ভেরিয়েবল, DATABRICKS_HOST এবং DATABRICKS_TOKEN যোগ করতে হবে। এর জন্য গিটল্যাবে আপনার রেপো খুলুন, সেটিংস → CI/CD → ভেরিয়েবল → ভেরিয়েবল যোগ করুন এ যান


dbx এবং DAB উভয়ই Databricks REST API-এর চারপাশে তৈরি করা হয়েছে, তাই তাদের মূলে, তারা খুব একই রকম। আমি আমাদের বিদ্যমান dbx প্রকল্প থেকে ম্যানুয়ালি একটি বান্ডিল তৈরি করার ধাপগুলি দিয়ে যাব।
আমাদের DAB প্রকল্পের জন্য প্রথম যে জিনিসটি সেট আপ করতে হবে তা হল স্থাপনার কনফিগারেশন। dbx-এ, আমরা আমাদের পরিবেশ এবং কর্মপ্রবাহ (চাকরি এবং পাইপলাইন) সংজ্ঞায়িত এবং সেট আপ করতে দুটি ফাইল ব্যবহার করি । এনভায়রনমেন্ট সেট আপ করতে, আমরা .dbx/project.json ব্যবহার করেছি, এবং ওয়ার্কফ্লো সংজ্ঞায়িত করতে, আমরা deployment.yml ব্যবহার করেছি।
DAB-তে, সবকিছু databricks.yml এ যায়, যা আপনার প্রকল্পের রুট ফোল্ডারে অবস্থিত। এটি দেখতে কেমন তা এখানে:
bundle: name: DAB_tutorial #our bundle name # These are for any custom variables for use throughout the bundle. variables: my_cluster_id: description: The ID of an existing cluster. default: xxxx-xxxxx-xxxxxxxx #The remote workspace URL and workspace authentication credentials are read from the caller's local configuration profile named <asset-bundle-tutorial> workspace: profile: asset-bundle-tutorial # These are the default job and pipeline settings if not otherwise overridden in # the following "targets" top-level mapping. resources: jobs: etl_job: tasks: - task_key: "main" existing_cluster_id: ${var.my_cluster_id} python_wheel_task: package_name: "my_package" entry_point: "etl_job" # take a look at the setup.py entry_points section for details on how to define an entrypoint libraries: - whl: ../dist/*.whl - task_key: "eda" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/explorative_analysis.py source: WORKSPACE depends_on: - task_key: "main" test_job: tasks: - task_key: "main_notebook" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/run_unit_test.py source: WORKSPACE libraries: - pypi: package: pytest # These are the targets to use for deployments and workflow runs. One and only one of these # targets can be set to "default: true". targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: true workspace: profile: asset-bundle-tutorial root_path: /Users/${workspace.current_user.userName}/.bundle/${bundle.name}/my-envs/${bundle.target} host: <path to your databricks dev workspace>
databricks.yml বান্ডেল কনফিগারেশন ফাইলটি ম্যাপিং নামক বিভাগগুলি নিয়ে গঠিত। এই ম্যাপিংগুলি আমাদের কনফিগারেশন ফাইলটিকে আলাদা লজিক্যাল ব্লকে মডুলারাইজ করার অনুমতি দেয়। 8টি শীর্ষ-স্তরের ম্যাপিং রয়েছে:
পাঁজা
ভেরিয়েবল
কর্মক্ষেত্র
শিল্পকর্ম
অন্তর্ভুক্ত
সম্পদ
সুসংগত
লক্ষ্য
এখানে, আমরা আমাদের প্রকল্প সংগঠিত করতে এই পাঁচটি ম্যাপিং ব্যবহার করি।
পাঁজা :
bundle ম্যাপিং এ, আমরা বান্ডেলের নাম সংজ্ঞায়িত করি। এখানে, আমরা একটি ডিফল্ট ক্লাস্টার আইডিও সংজ্ঞায়িত করতে পারি যা আমাদের উন্নয়ন পরিবেশের জন্য ব্যবহার করা উচিত, সেইসাথে গিট URL এবং শাখা সম্পর্কে তথ্য।
ভেরিয়েবল :
আমরা কাস্টম ভেরিয়েবল সংজ্ঞায়িত করতে এবং আমাদের কনফিগারেশন ফাইলটিকে আরও পুনঃব্যবহারযোগ্য করতে variables ম্যাপিং ব্যবহার করতে পারি। উদাহরণস্বরূপ, আমরা বিদ্যমান ক্লাস্টারের আইডির জন্য একটি পরিবর্তনশীল ঘোষণা করি এবং বিভিন্ন কর্মপ্রবাহে এটি ব্যবহার করি। এখন, যদি আপনি একটি ভিন্ন ক্লাস্টার ব্যবহার করতে চান, আপনাকে যা করতে হবে তা হল পরিবর্তনশীল মান পরিবর্তন করা।
সম্পদ :
resources ম্যাপিং হল যেখানে আমরা আমাদের কর্মপ্রবাহকে সংজ্ঞায়িত করি। এতে শূন্য বা নিম্নলিখিত ম্যাপিংয়ের প্রতিটির একটি অন্তর্ভুক্ত রয়েছে: experiments , jobs , models এবং pipelines । এটি মূলত dbx প্রজেক্টে আমাদের deployment.yml ফাইল। যদিও কিছু ছোটখাটো পার্থক্য আছে:
-
python_wheel_taskএর জন্য, আমাদের চাকা প্যাকেজের পথটি অন্তর্ভুক্ত করতে হবে; অন্যথায়, ডেটাব্রিক্স লাইব্রেরি খুঁজে পাবে না। আপনি এখানে DAB ব্যবহার করে হুইল প্যাকেজ তৈরির বিষয়ে আরও তথ্য পেতে পারেন। - আমরা নোটবুকের কাজ চালানোর জন্য সম্পূর্ণ পাথের পরিবর্তে আপেক্ষিক পাথ ব্যবহার করতে পারি। নোটবুক স্থাপনের পথটি
databricks.ymlফাইলের সাথে আপেক্ষিক যেখানে এই কাজটি ঘোষণা করা হয়েছে।
লক্ষ্য :
targets ম্যাপিং হল যেখানে আমরা আমাদের প্রকল্পের বিভিন্ন স্তর/পরিবেশের কনফিগারেশন এবং সংস্থানগুলিকে সংজ্ঞায়িত করি। উদাহরণস্বরূপ, একটি সাধারণ CI/CD পাইপলাইনের জন্য, আমাদের তিনটি লক্ষ্য থাকবে: উন্নয়ন, মঞ্চায়ন এবং উৎপাদন। প্রতিটি লক্ষ্যবস্তুতে চাইল্ড ম্যাপিং হিসাবে সমস্ত শীর্ষ-স্তরের ম্যাপিং ( targets ছাড়া) থাকতে পারে। এখানে টার্গেট ম্যাপিং এর স্কিমা ( databricks.yml )।
targets: <some-unique-programmatic-identifier-for-this-target>: artifacts: ... bundle: ... compute_id: string default: true | false mode: development resources: ... sync: ... variables: <preceding-unique-variable-name>: <non-default-value> workspace: ...
চাইল্ড ম্যাপিং আমাদের ডিফল্ট কনফিগারেশনগুলিকে ওভাররাইড করতে দেয় যা আমরা শীর্ষ-স্তরের ম্যাপিংগুলিতে আগে সংজ্ঞায়িত করেছি। উদাহরণস্বরূপ, যদি আমরা আমাদের CI/CD পাইপলাইনের প্রতিটি পর্যায়ের জন্য একটি বিচ্ছিন্ন ডেটাব্রিক্স ওয়ার্কস্পেস রাখতে চাই, আমাদের প্রতিটি টার্গেটের জন্য ওয়ার্কস্পেস চাইল্ড ম্যাপিং সেট করা উচিত।
workspace: profile: my-default-profile targets: dev: default: true test: workspace: host: https://<staging-workspace-url> prod: workspace: host: https://<production-workspace-url>
অন্তর্ভুক্ত:
include ম্যাপিং আমাদের কনফিগারেশন ফাইলকে বিভিন্ন মডিউলে ভাঙতে দেয়। উদাহরণস্বরূপ, আমরা resources/dev_job.yml ফাইলে আমাদের সম্পদ এবং ভেরিয়েবল সংরক্ষণ করতে পারি এবং এটি আমাদের databricks.yml ফাইলে আমদানি করতে পারি।
# yaml-language-server: $schema=bundle_config_schema.json bundle: name: DAB_tutorial #our bundle name workspace: profile: asset-bundle-tutorial include: - ./resources/*.yml targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: trueDAB কনফিগারেশনের আরো বিস্তারিত ব্যাখ্যার জন্য Databricks Asset Bundle কনফিগারেশন দেখুন
কর্মপ্রবাহ
কার্যপ্রবাহ ঠিক যা আমি পূর্ববর্তী ব্লগে বর্ণনা করেছি। শুধুমাত্র পার্থক্য হল আর্টিফ্যাক্ট এবং ফাইলের অবস্থান।


প্রকল্পের কঙ্কাল
এখানে চূড়ান্ত প্রকল্প মত দেখায় কিভাবে
ASSET-BUNDLE-TUTORAL/ ├─ my_package/ │ ├─ tasks/ │ │ ├─ __init__.py │ │ ├─ sample_etl_job.py │ ├─ __init__.py │ ├─ common.py ├─ test/ │ ├─ conftest.py │ ├─ test_sample.py ├─ notebooks/ │ ├─ explorative_analysis.py │ ├─ run_unit_test.py ├─ resources/ │ ├─ dev_jobs.yml ├─ .gitignore ├─ .gitlab-ci.yml ├─ databricks.yml ├─ README.md ├─ setup.py
যাচাই করুন, স্থাপন করুন এবং চালান
এখন, আপনার টার্মিনাল খুলুন এবং রুট ডিরেক্টরি থেকে নিম্নলিখিত কমান্ডগুলি চালান:
validate: প্রথমত, আমাদের কনফিগারেশন ফাইলের সঠিক বিন্যাস এবং সিনট্যাক্স আছে কিনা তা পরীক্ষা করা উচিত। বৈধতা সফল হলে, আপনি বান্ডেল কনফিগারেশনের একটি JSON উপস্থাপনা পাবেন। একটি ত্রুটির ক্ষেত্রে, এটি ঠিক করুন এবং আপনি JSON ফাইলটি না পাওয়া পর্যন্ত আবার কমান্ডটি চালান৷
databricks bundle validate
ডিপ্লয়: ডিপ্লোয়মেন্টের মধ্যে রয়েছে পাইথন হুইল প্যাকেজ তৈরি করা এবং এটিকে আমাদের ডেটাব্রিক্স ওয়ার্কস্পেসে স্থাপন করা, আমাদের ডেটাব্রিক্স ওয়ার্কস্পেসে নোটবুক এবং অন্যান্য ফাইল স্থাপন করা এবং আমাদের ডেটাব্রিক্স ওয়ার্কফ্লোতে কাজ তৈরি করা।
databricks bundle deployযদি কোন কমান্ড অপশন নির্দিষ্ট করা না থাকে, Databricks CLI ডিফল্ট টার্গেট ব্যবহার করে যেমন বান্ডেল কনফিগারেশন ফাইলের মধ্যে ঘোষণা করা হয়েছে। এখানে, আমাদের শুধুমাত্র একটি টার্গেট আছে তাই এটি কোন ব্যাপার না, কিন্তু এটি প্রদর্শন করার জন্য, আমরা
-t devপতাকা ব্যবহার করে একটি নির্দিষ্ট লক্ষ্য স্থাপন করতে পারি।
রান: স্থাপন করা কাজ চালান। এখানে, আমরা কোন কাজ চালাতে চাই তা নির্দিষ্ট করতে পারি। উদাহরণস্বরূপ, নিম্নলিখিত কমান্ডে, আমরা dev টার্গেটে
test_jobকাজ চালাই।databricks bundle run -t dev test_job
আউটপুটে আপনি একটি URL পাবেন যা আপনার কর্মক্ষেত্রে কাজ চালানোর নির্দেশ করে।


এছাড়াও আপনি আপনার Databricks ওয়ার্কস্পেসের He Workflow বিভাগে আপনার কাজ খুঁজে পেতে পারেন।
CI পাইপলাইন কনফিগারেশন
আমাদের CI পাইপলাইনের সাধারণ সেটআপ আগের প্রকল্পের মতোই থাকে। এটি দুটি প্রধান পর্যায় নিয়ে গঠিত: পরীক্ষা এবং স্থাপন । পরীক্ষার পর্যায়ে, unit-test-job ইউনিট পরীক্ষা চালায় এবং পরীক্ষার জন্য একটি পৃথক কর্মপ্রবাহ স্থাপন করে। পরীক্ষা পর্যায় সফলভাবে সমাপ্ত হওয়ার পরে সক্রিয় করা ডিপ্লোয় স্টেজ, আপনার প্রধান ETL ওয়ার্কফ্লো ডিপ্লয়মেন্ট পরিচালনা করে।
এখানে, Databricks CLI ইনস্টল করার এবং প্রমাণীকরণ প্রোফাইল সেট আপ করার জন্য প্রতিটি পর্যায়ের আগে আমাদের অতিরিক্ত পদক্ষেপ যোগ করতে হবে। আমরা আমাদের CI পাইপলাইনের before_script বিভাগে এটি করি। before_script কীওয়ার্ডটি কমান্ডের একটি অ্যারে নির্ধারণ করতে ব্যবহৃত হয় যা প্রতিটি কাজের script কমান্ডের আগে চালানো উচিত। এটি সম্পর্কে আরও এখানে পাওয়া যাবে।
ঐচ্ছিকভাবে, আপনি after_project কীওয়ার্ড ব্যবহার করে কমান্ডের একটি অ্যারে নির্ধারণ করতে পারেন যা প্রতিটি কাজের পরে চালানো উচিত। এখানে, আমরা প্রতিটি কাজ শেষ হওয়ার পরে পরিষ্কার করার জন্য databricks bundle destroy --auto-approve ব্যবহার করতে পারি। সাধারণভাবে, আমাদের পাইপলাইন এই ধাপগুলির মধ্য দিয়ে যায়:
- Databricks CLI ইনস্টল করুন এবং কনফিগারেশন প্রোফাইল তৈরি করুন।
- প্রকল্পটি তৈরি করুন।
- বিল্ড আর্টিফ্যাক্টগুলিকে ডেটাব্রিক্স ওয়ার্কস্পেসে পুশ করুন।
- আপনার ক্লাস্টারে চাকা প্যাকেজ ইনস্টল করুন।
- ডেটাব্রিক্স ওয়ার্কফ্লোতে চাকরি তৈরি করুন।
- কাজ চালান।
এখানে আমাদের .gitlab-ci.yml কেমন দেখাচ্ছে:
image: python:3.9 stages: # List of stages for jobs, and their order of execution - test - deploy default: before_script: - echo "install databricks cli" - curl -V - curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh - echo "databricks CLI installation finished" - echo "create the configuration profile for token authentication" - echo "[asset-bundle-tutorial]" > ~/.databrickscfg - echo "token = $DATABRICKS_TOKEN" >> ~/.databrickscfg - echo "host = $DATABRICKS_HOST" >> ~/.databrickscfg - echo "validate the bundle" - databricks bundle validate after_script: - echo "remove all workflows" #- databricks bundle destroy --auto-approve unit-test-job: # This job runs in the test stage. stage: test script: - echo "Running unit tests." - pip3 install --upgrade wheel setuptools - pip install -e ".[local]" - databricks bundle deploy -t dev - databricks bundle run -t dev test_job deploy-job: # This job runs in the deploy stage. stage: deploy # It only runs when *both* jobs in the test stage complete successfully. script: - echo "Deploying application..." - echo "Install dependencies" - pip install -e ".[local]" - echo "Deploying Job" - databricks bundle deploy -t dev - databricks bundle run -t dev etl_job
মন্তব্য
এখানে কিছু নোট রয়েছে যা আপনাকে আপনার বান্ডিল প্রকল্প সেট আপ করতে সাহায্য করতে পারে:
- এই ব্লগে, আমরা ম্যানুয়ালি আমাদের বান্ডেল তৈরি করেছি। আমার অভিজ্ঞতায়, এটি অন্তর্নিহিত ধারণা এবং বৈশিষ্ট্যগুলিকে আরও ভালভাবে বুঝতে সহায়তা করে। কিন্তু আপনি যদি আপনার প্রকল্পের সাথে দ্রুত শুরু করতে চান, আপনি ডিফল্ট এবং নন-ডিফল্ট বান্ডিল টেমপ্লেটগুলি ব্যবহার করতে পারেন যা ডেটাব্রিক্স বা অন্যান্য পক্ষের দ্বারা সরবরাহ করা হয়। কিভাবে ডিফল্ট পাইথন টেমপ্লেট দিয়ে একটি প্রকল্প শুরু করতে হয় সে সম্পর্কে জানতে এই Databricks পোস্টটি দেখুন।
- যখন আপনি
databricks bundle deployব্যবহার করে আপনার কোড স্থাপন করেন, তখন setup.py ফাইল ব্যবহার করে আপনার প্যাকেজ তৈরি করতে Databricks CLIpython3 setup.py bdist_wheelকমান্ডটি চালায়। আপনার যদি ইতিমধ্যে python3 ইনস্টল করা থাকে তবে আপনার মেশিনটি python3 এর পরিবর্তে python alias ব্যবহার করে, আপনি সমস্যায় পড়বেন। যাইহোক, এটি ঠিক করা সহজ। উদাহরণস্বরূপ, এখানে এবং এখানে কিছু সমাধান সহ দুটি স্ট্যাক ওভারফ্লো থ্রেড রয়েছে।
এরপর কি
পরবর্তী ব্লগ পোস্টে, আমি আমার প্রথম ব্লগ পোস্ট দিয়ে শুরু করব কিভাবে Databricks এ একটি মেশিন লার্নিং প্রকল্প শুরু করতে হয়। এটি হবে আমার আসন্ন এন্ড-টু-এন্ড মেশিন লার্নিং পাইপলাইনের প্রথম পোস্ট, যা ডেভেলপমেন্ট থেকে প্রোডাকশন পর্যন্ত সবকিছু কভার করে। সাথে থাকুন!
সম্পদ
আপনি resources/dev_jobs.yml এ cluster_id আপডেট করেছেন তা নিশ্চিত করুন
- dbx থেকে বান্ডিলে স্থানান্তর করুন | AWS-এ ডেটাব্রিক্স
- Databricks সম্পদ বান্ডেল উন্নয়ন কাজের কাজ | AWS-এ ডেটাব্রিক্স
- ডাটাব্রিক্স অ্যাসেট বান্ডেল ডিপ্লয়মেন্ট মোড | AWS-এ ডেটাব্রিক্স
- ডেটাব্রিক্স অ্যাসেট বান্ডেল ব্যবহার করে একটি পাইথন চাকা তৈরি করুন | AWS-এ ডেটাব্রিক্স
- Databricks সম্পদ বান্ডিল: Databricks (youtube.com) এ ডেটা পণ্য স্থাপনের জন্য একটি স্ট্যান্ডার্ড, ইউনিফাইড অ্যাপ্রোচ
- রেপো এবং স্লাইডগুলি https://github.com/databricks/databricks-asset-bundles-dais2023








