
























Giới thiệu
Trong blog trước , tôi đã hướng dẫn bạn cách xây dựng quy trình CI bằng cách sử dụng Databricks CLI eXtensions và GitLab. Trong bài đăng này, tôi sẽ chỉ cho bạn cách đạt được mục tiêu tương tự với khung triển khai Databricks mới nhất và được đề xuất, Gói tài sản Databricks . DAB được nhóm Databricks hỗ trợ và phát triển tích cực như một công cụ mới để hợp lý hóa việc phát triển các dự án dữ liệu, phân tích và ML phức tạp cho nền tảng Databricks.
Tôi sẽ bỏ qua phần giới thiệu chung về DAB và các tính năng của nó và giới thiệu cho bạn tài liệu về Databricks. Ở đây, tôi sẽ tập trung vào cách di chuyển dự án dbx của chúng tôi từ blog trước sang DAB. Trong quá trình này, tôi sẽ giải thích một số khái niệm và tính năng có thể giúp bạn nắm bắt từng bước tốt hơn.
Mẫu phát triển sử dụng GUI Databricks
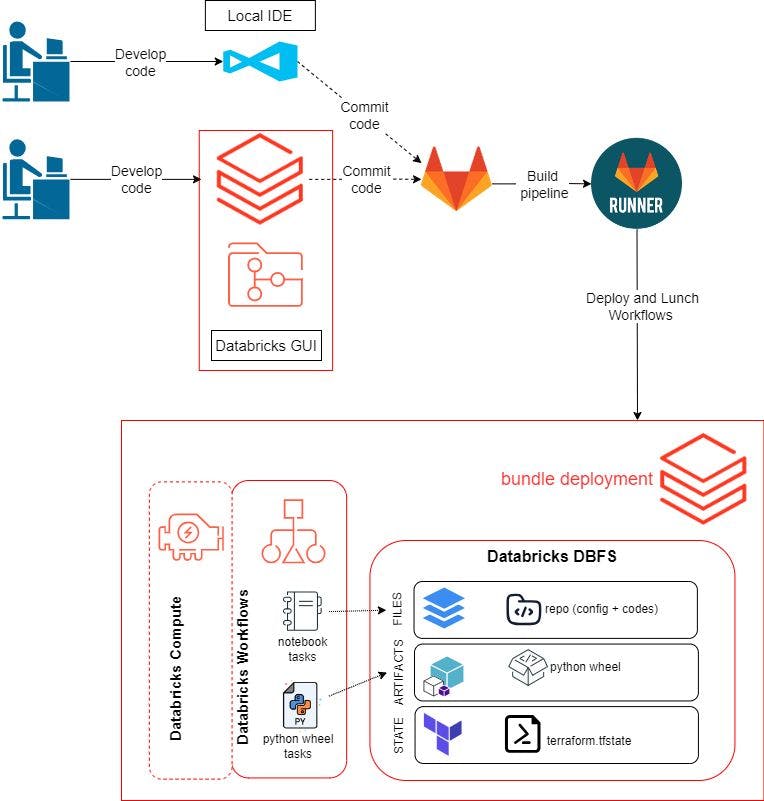
Trong bài đăng trước, chúng tôi đã sử dụng GUI Databricks để phát triển và kiểm tra mã cũng như quy trình công việc của mình. Đối với bài đăng blog này, chúng tôi muốn có thể sử dụng môi trường cục bộ để phát triển mã của mình. Quy trình làm việc sẽ như sau:
Tạo một kho lưu trữ từ xa và sao chép nó vào môi trường cục bộ và không gian làm việc Databricks của chúng tôi. Chúng tôi sử dụng GitLab ở đây.
Phát triển logic chương trình và kiểm tra nó bên trong GUI Databricks hoặc trên IDE cục bộ của chúng tôi. Điều này bao gồm các tập lệnh Python để xây dựng gói Python Wheel, các tập lệnh để kiểm tra chất lượng dữ liệu bằng pytest và một sổ ghi chép để chạy pytest.
Đẩy mã vào GitLab. Lệnh
git pushsẽ kích hoạt Người chạy GitLab xây dựng, triển khai và khởi chạy tài nguyên trên Databricks bằng cách sử dụng Gói tài sản Databricks.Thiết lập môi trường phát triển của bạn
Databricks CLI
Trước hết, chúng ta cần cài đặt Databricks CLI phiên bản 0.205 trở lên trên máy cục bộ của bạn. Để kiểm tra phiên bản Databricks CLI đã cài đặt của bạn, hãy chạy lệnh
databricks -v. Để cài đặt Databricks CLI phiên bản 0.205 trở lên, hãy xem Cài đặt hoặc cập nhật Databricks CLI .Xác thực
Databricks hỗ trợ nhiều phương thức xác thực khác nhau giữa Databricks CLI trên máy phát triển của chúng tôi và không gian làm việc Databricks của bạn. Đối với hướng dẫn này, chúng tôi sử dụng xác thực mã thông báo truy cập cá nhân Databricks. Nó bao gồm hai bước:
- Tạo mã thông báo truy cập cá nhân trên không gian làm việc Databricks của chúng tôi.
- Tạo hồ sơ cấu hình Databricks trên máy cục bộ của chúng tôi.
Để tạo mã thông báo Databricks trong không gian làm việc Databricks của bạn, hãy đi tới Cài đặt người dùng → Nhà phát triển → Mã thông báo truy cập → Quản lý → Tạo mã thông báo mới.
Để tạo hồ sơ cấu hình, hãy tạo tệp
~/.databrickscfgtrong thư mục gốc của bạn với nội dung sau:

[asset-bundle-tutorial] host = https://xxxxxxxxxxx.cloud.databricks.com token = xxxxxxx Ở đây, asset-bundle-tutorial là tên hồ sơ của chúng tôi, máy chủ là địa chỉ không gian làm việc của chúng tôi và mã thông báo là mã thông báo truy cập cá nhân mà chúng tôi vừa tạo.
Bạn có thể tạo tệp này bằng Databricks CLI bằng cách chạy databricks configure --profile asset-bundle-tutorial trong thiết bị đầu cuối của mình. Lệnh sẽ nhắc bạn về Databricks Host và Personal Access Token . Nếu bạn không chỉ định cờ --profile , tên hồ sơ sẽ được đặt thành DEFAULT .
Tích hợp Git (Databricks)
Bước đầu tiên, chúng tôi định cấu hình thông tin xác thực Git và kết nối kho lưu trữ từ xa với Databricks . Tiếp theo, chúng tôi tạo một kho lưu trữ từ xa và sao chép nó vào kho lưu trữ Databricks cũng như trên máy cục bộ của chúng tôi. Cuối cùng, chúng ta cần thiết lập xác thực giữa Databricks CLI trên trình chạy Gitlab và không gian làm việc Databricks của chúng ta. Để làm điều đó, chúng ta nên thêm hai biến môi trường, DATABRICKS_HOST và DATABRICKS_TOKEN vào cấu hình đường dẫn Gitlab CI/CD của mình. Để mở repo của bạn trong Gitlab, hãy đi tới Cài đặt→ CI/CD → Biến → Thêm biến


Cả dbx và DAB đều được xây dựng xung quanh API REST của Databricks , vì vậy về cốt lõi, chúng rất giống nhau. Tôi sẽ thực hiện các bước để tạo gói theo cách thủ công từ dự án dbx hiện có của chúng tôi.
Điều đầu tiên chúng ta cần thiết lập cho dự án DAB của mình là cấu hình triển khai. Trong dbx, chúng tôi sử dụng hai tệp để xác định và thiết lập môi trường cũng như quy trình làm việc của mình (công việc và quy trình). Để thiết lập môi trường, chúng tôi đã sử dụng .dbx/project.json và để xác định quy trình công việc, chúng tôi đã sử dụng deployment.yml .
Trong DAB, mọi thứ đều đi vào databricks.yml , nằm trong thư mục gốc của dự án của bạn. Đây là giao diện của nó:
bundle: name: DAB_tutorial #our bundle name # These are for any custom variables for use throughout the bundle. variables: my_cluster_id: description: The ID of an existing cluster. default: xxxx-xxxxx-xxxxxxxx #The remote workspace URL and workspace authentication credentials are read from the caller's local configuration profile named <asset-bundle-tutorial> workspace: profile: asset-bundle-tutorial # These are the default job and pipeline settings if not otherwise overridden in # the following "targets" top-level mapping. resources: jobs: etl_job: tasks: - task_key: "main" existing_cluster_id: ${var.my_cluster_id} python_wheel_task: package_name: "my_package" entry_point: "etl_job" # take a look at the setup.py entry_points section for details on how to define an entrypoint libraries: - whl: ../dist/*.whl - task_key: "eda" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/explorative_analysis.py source: WORKSPACE depends_on: - task_key: "main" test_job: tasks: - task_key: "main_notebook" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/run_unit_test.py source: WORKSPACE libraries: - pypi: package: pytest # These are the targets to use for deployments and workflow runs. One and only one of these # targets can be set to "default: true". targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: true workspace: profile: asset-bundle-tutorial root_path: /Users/${workspace.current_user.userName}/.bundle/${bundle.name}/my-envs/${bundle.target} host: <path to your databricks dev workspace>
Tệp cấu hình gói databricks.yml bao gồm các phần được gọi là ánh xạ. Các ánh xạ này cho phép chúng tôi mô-đun hóa tệp cấu hình thành các khối logic riêng biệt. Có 8 ánh xạ cấp cao nhất:
bó
biến
không gian làm việc
hiện vật
bao gồm
tài nguyên
đồng bộ hóa
mục tiêu
Ở đây, chúng tôi sử dụng năm ánh xạ này để tổ chức dự án của mình.
bó :
Trong ánh xạ bundle , chúng tôi xác định tên của gói. Tại đây, chúng tôi cũng có thể xác định ID cụm mặc định sẽ được sử dụng cho môi trường phát triển của mình, cũng như thông tin về URL và nhánh Git.
biến :
Chúng ta có thể sử dụng ánh xạ variables để xác định các biến tùy chỉnh và làm cho tệp cấu hình của mình có thể tái sử dụng nhiều hơn. Ví dụ: chúng tôi khai báo một biến cho ID của cụm hiện có và sử dụng biến đó trong các quy trình công việc khác nhau. Bây giờ, trong trường hợp bạn muốn sử dụng một cụm khác, tất cả những gì bạn phải làm là thay đổi giá trị biến.
tài nguyên :
Ánh xạ resources là nơi chúng tôi xác định quy trình công việc của mình. Nó bao gồm 0 hoặc một trong các ánh xạ sau: experiments , jobs , models và pipelines . Về cơ bản đây là tệp deployment.yml của chúng tôi trong dự án dbx. Mặc dù có một số khác biệt nhỏ:
- Đối với
python_wheel_task, chúng ta phải bao gồm đường dẫn đến gói bánh xe của mình; nếu không thì Databricks không thể tìm thấy thư viện. Bạn có thể tìm thêm thông tin về việc xây dựng các gói bánh xe bằng DAB tại đây . - Chúng ta có thể sử dụng đường dẫn tương đối thay vì đường dẫn đầy đủ để chạy các tác vụ sổ ghi chép. Đường dẫn để triển khai sổ tay có liên quan đến tệp
databricks.ymltrong đó tác vụ này được khai báo.
mục tiêu :
Ánh xạ targets là nơi chúng tôi xác định cấu hình và tài nguyên của các giai đoạn/môi trường khác nhau trong dự án của mình. Ví dụ: đối với quy trình CI/CD điển hình, chúng tôi sẽ có ba mục tiêu: phát triển, dàn dựng và sản xuất. Mỗi mục tiêu có thể bao gồm tất cả các ánh xạ cấp cao nhất (ngoại trừ targets ) dưới dạng ánh xạ con. Đây là lược đồ của ánh xạ mục tiêu ( databricks.yml ).
targets: <some-unique-programmatic-identifier-for-this-target>: artifacts: ... bundle: ... compute_id: string default: true | false mode: development resources: ... sync: ... variables: <preceding-unique-variable-name>: <non-default-value> workspace: ...
Ánh xạ con cho phép chúng tôi ghi đè các cấu hình mặc định mà chúng tôi đã xác định trước đó trong ánh xạ cấp cao nhất. Ví dụ: nếu chúng ta muốn có một không gian làm việc Databricks riêng biệt cho từng giai đoạn của quy trình CI/CD, chúng ta nên đặt ánh xạ con của không gian làm việc cho từng mục tiêu.
workspace: profile: my-default-profile targets: dev: default: true test: workspace: host: https://<staging-workspace-url> prod: workspace: host: https://<production-workspace-url>
bao gồm:
Ánh xạ include cho phép chúng tôi chia tệp cấu hình của mình thành các mô-đun khác nhau. Ví dụ: chúng ta có thể lưu tài nguyên và biến của mình vào tệp resources/dev_job.yml và nhập nó vào tệp databricks.yml .
# yaml-language-server: $schema=bundle_config_schema.json bundle: name: DAB_tutorial #our bundle name workspace: profile: asset-bundle-tutorial include: - ./resources/*.yml targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: trueĐể được giải thích chi tiết hơn về cấu hình DAB, hãy xem cấu hình Gói tài sản Databricks
Quy trình làm việc
Quy trình làm việc chính xác như những gì tôi đã mô tả trong blog trước. Sự khác biệt duy nhất là vị trí của hiện vật và tập tin.


Bộ xương dự án
đây là dự án cuối cùng trông như thế nào
ASSET-BUNDLE-TUTORAL/ ├─ my_package/ │ ├─ tasks/ │ │ ├─ __init__.py │ │ ├─ sample_etl_job.py │ ├─ __init__.py │ ├─ common.py ├─ test/ │ ├─ conftest.py │ ├─ test_sample.py ├─ notebooks/ │ ├─ explorative_analysis.py │ ├─ run_unit_test.py ├─ resources/ │ ├─ dev_jobs.yml ├─ .gitignore ├─ .gitlab-ci.yml ├─ databricks.yml ├─ README.md ├─ setup.py
Xác thực, triển khai và chạy
Bây giờ, hãy mở terminal của bạn và chạy các lệnh sau từ thư mục gốc:
xác thực: Đầu tiên, chúng ta nên kiểm tra xem tệp cấu hình của mình có đúng định dạng và cú pháp hay không. Nếu xác thực thành công, bạn sẽ nhận được bản trình bày JSON của cấu hình gói. Trong trường hợp xảy ra lỗi, hãy sửa nó và chạy lại lệnh cho đến khi bạn nhận được tệp JSON.
databricks bundle validate
triển khai: Triển khai bao gồm xây dựng gói bánh xe Python và triển khai nó vào không gian làm việc Databricks của chúng tôi, triển khai sổ ghi chép và các tệp khác vào không gian làm việc Databricks của chúng tôi, đồng thời tạo các công việc trong quy trình làm việc Databricks của chúng tôi.
databricks bundle deployNếu không có tùy chọn lệnh nào được chỉ định, Databricks CLI sẽ sử dụng mục tiêu mặc định như được khai báo trong các tệp cấu hình gói. Ở đây, chúng ta chỉ có một mục tiêu nên không thành vấn đề, nhưng để chứng minh điều này, chúng ta cũng có thể triển khai một mục tiêu cụ thể bằng cách sử dụng cờ
-t dev.
run: Chạy các công việc đã triển khai. Ở đây, chúng ta có thể chỉ định công việc nào chúng ta muốn chạy. Ví dụ: trong lệnh sau, chúng tôi chạy công việc
test_jobtrong mục tiêu nhà phát triển.databricks bundle run -t dev test_job
ở đầu ra, bạn nhận được một URL trỏ tới công việc đang chạy trong không gian làm việc của bạn.


bạn cũng có thể tìm thấy công việc của mình trong phần Quy trình làm việc của không gian làm việc Databricks.
Cấu hình đường ống CI
Thiết lập chung của quy trình CI của chúng tôi vẫn giống như dự án trước đó. Nó bao gồm hai giai đoạn chính: thử nghiệm và triển khai . Trong giai đoạn thử nghiệm , unit-test-job sẽ chạy các thử nghiệm đơn vị và triển khai một quy trình làm việc riêng để thử nghiệm. Giai đoạn triển khai , được kích hoạt sau khi hoàn thành thành công giai đoạn thử nghiệm, xử lý việc triển khai quy trình làm việc ETL chính của bạn.
Ở đây, chúng tôi phải thêm các bước bổ sung trước mỗi giai đoạn cài đặt Databricks CLI và thiết lập hồ sơ xác thực. Chúng tôi thực hiện việc này trong phần before_script của quy trình CI. Từ khóa before_script được sử dụng để xác định một mảng lệnh sẽ chạy trước các lệnh script của mỗi công việc. Thông tin thêm về nó có thể được tìm thấy ở đây .
Theo tùy chọn, bạn có thể sử dụng từ khóa after_project để xác định một mảng lệnh sẽ chạy SAU mỗi công việc. Ở đây, chúng ta có thể sử dụng databricks bundle destroy --auto-approve để dọn dẹp sau khi mỗi công việc kết thúc. Nói chung, quy trình của chúng tôi trải qua các bước sau:
- Cài đặt Databricks CLI và tạo hồ sơ cấu hình.
- Xây dựng dự án.
- Đẩy các tạo phẩm bản dựng vào không gian làm việc của Databricks.
- Cài đặt gói bánh xe trên cụm của bạn.
- Tạo công việc trên Quy trình làm việc của Databricks.
- Chạy các công việc.
đây là cách .gitlab-ci.yml của chúng tôi trông như thế nào:
image: python:3.9 stages: # List of stages for jobs, and their order of execution - test - deploy default: before_script: - echo "install databricks cli" - curl -V - curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh - echo "databricks CLI installation finished" - echo "create the configuration profile for token authentication" - echo "[asset-bundle-tutorial]" > ~/.databrickscfg - echo "token = $DATABRICKS_TOKEN" >> ~/.databrickscfg - echo "host = $DATABRICKS_HOST" >> ~/.databrickscfg - echo "validate the bundle" - databricks bundle validate after_script: - echo "remove all workflows" #- databricks bundle destroy --auto-approve unit-test-job: # This job runs in the test stage. stage: test script: - echo "Running unit tests." - pip3 install --upgrade wheel setuptools - pip install -e ".[local]" - databricks bundle deploy -t dev - databricks bundle run -t dev test_job deploy-job: # This job runs in the deploy stage. stage: deploy # It only runs when *both* jobs in the test stage complete successfully. script: - echo "Deploying application..." - echo "Install dependencies" - pip install -e ".[local]" - echo "Deploying Job" - databricks bundle deploy -t dev - databricks bundle run -t dev etl_job
Ghi chú
Dưới đây là một số lưu ý có thể giúp bạn thiết lập dự án gói của mình:
- Trong blog này, chúng tôi đã tạo gói của mình theo cách thủ công. Theo kinh nghiệm của tôi, điều này giúp hiểu rõ hơn các khái niệm và tính năng cơ bản. Nhưng nếu muốn bắt đầu nhanh chóng với dự án của mình, bạn có thể sử dụng các mẫu gói mặc định và không mặc định do Databricks hoặc các bên khác cung cấp. Hãy xem bài đăng Databricks này để tìm hiểu về cách bắt đầu một dự án với mẫu Python mặc định.
- Khi bạn triển khai mã bằng cách sử
databricks bundle deploy, Databricks CLI sẽ chạy lệnhpython3 setup.py bdist_wheelđể xây dựng gói của bạn bằng tệp setup.py . Nếu bạn đã cài đặt python3 nhưng máy của bạn sử dụng bí danh python thay vì python3 , bạn sẽ gặp vấn đề. Tuy nhiên, điều này rất dễ khắc phục. Ví dụ: đây và đây là hai luồng Stack Overflow kèm theo một số giải pháp.
Cái gì tiếp theo
Trong bài đăng blog tiếp theo, tôi sẽ bắt đầu với bài đăng blog đầu tiên của mình về cách bắt đầu dự án máy học trên Databricks. Đây sẽ là bài đăng đầu tiên trong quy trình học máy toàn diện sắp tới của tôi, bao gồm mọi thứ từ phát triển đến sản xuất. Giữ nguyên!
Tài nguyên
Đảm bảo bạn cập nhật cluster_id trong resources/dev_jobs.yml
- Di chuyển từ dbx sang gói | Databricks trên AWS
- Nhiệm vụ công việc phát triển Gói tài sản Databricks | Databricks trên AWS
- Chế độ triển khai Gói tài sản Databricks | Databricks trên AWS
- Phát triển bánh xe Python bằng cách sử dụng Gói tài sản Databricks | Databricks trên AWS
- Gói tài sản Databricks: Cách tiếp cận tiêu chuẩn, thống nhất để triển khai sản phẩm dữ liệu trên Databricks (youtube.com)








