
























Introdução
No blog anterior , mostrei como construir um pipeline de CI usando databricks CLI eXtensions e GitLab. Nesta postagem, mostrarei como atingir o mesmo objetivo com a estrutura de implantação do Databricks mais recente e recomendada, Databricks Asset Bundles . O DAB é ativamente apoiado e desenvolvido pela equipe do Databricks como uma nova ferramenta para agilizar o desenvolvimento de dados complexos, análises e projetos de ML para a plataforma Databricks.
Vou pular a introdução geral do DAB e seus recursos e encaminhá-lo para a documentação do Databricks. Aqui, vou me concentrar em como migrar nosso projeto dbx do blog anterior para DAB. Ao longo do caminho, explicarei alguns conceitos e recursos que podem ajudá-lo a compreender melhor cada etapa.
Padrão de desenvolvimento usando Databricks GUI
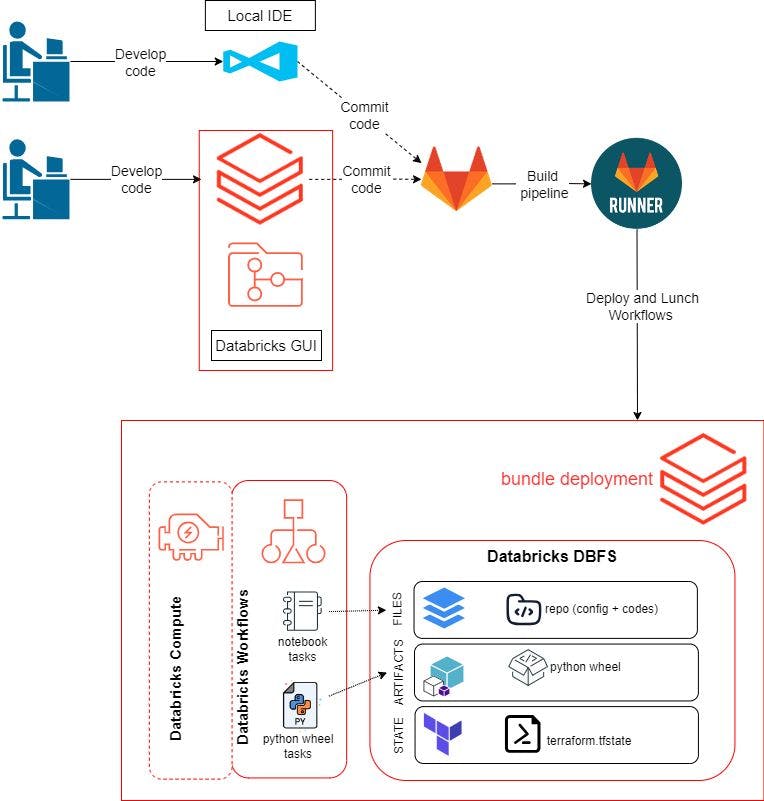
Na postagem anterior, usamos a GUI do Databricks para desenvolver e testar nosso código e fluxos de trabalho. Para esta postagem do blog, queremos poder usar nosso ambiente local para desenvolver nosso código também. O fluxo de trabalho será o seguinte:
Crie um repositório remoto e clone-o em nosso ambiente local e no espaço de trabalho do Databricks. Usamos GitLab aqui.
Desenvolva a lógica do programa e teste-a dentro da GUI do Databricks ou em nosso IDE local. Isso inclui scripts Python para construir um pacote Python Wheel, scripts para testar a qualidade dos dados usando pytest e um notebook para executar o pytest.
Envie o código para o GitLab. O
git pushacionará um GitLab Runner para construir, implantar e lançar recursos em Databricks usando Databricks Asset Bundles.Configurando seus ambientes de desenvolvimento
CLI do Databricks
Em primeiro lugar, precisamos instalar o Databricks CLI versão 0.205 ou superior em sua máquina local. Para verificar a versão instalada da CLI do Databricks, execute o comando
databricks -v. Para instalar a CLI do Databricks versão 0.205 ou superior, consulte Instalar ou atualizar a CLI do Databricks .Autenticação
O Databricks dá suporte a vários métodos de autenticação entre a CLI do Databricks em nossa máquina de desenvolvimento e seu espaço de trabalho do Databricks. Para este tutorial, usamos a autenticação de token de acesso pessoal do Databricks. Consiste em duas etapas:
- Crie um token de acesso pessoal em nosso workspace do Databricks.
- Crie um perfil de configuração do Databricks em nossa máquina local.
Para gerar um token do Databricks em seu espaço de trabalho do Databricks, vá para Configurações do usuário → Desenvolvedor → Tokens de acesso → Gerenciar → Gerar novo token.
Para criar um perfil de configuração, crie o arquivo
~/.databrickscfgna sua pasta raiz com o seguinte conteúdo:

[asset-bundle-tutorial] host = https://xxxxxxxxxxx.cloud.databricks.com token = xxxxxxx Aqui, o asset-bundle-tutorial é o nome do nosso perfil, o host é o endereço do nosso espaço de trabalho e o token é o token de acesso pessoal que acabamos de criar.
Você pode criar esse arquivo usando a CLI do Databricks executando databricks configure --profile asset-bundle-tutorial em seu terminal. O comando solicitará o host do Databricks e o token de acesso pessoal . Se você não especificar o sinalizador --profile , o nome do perfil será definido como DEFAULT .
Integração Git (Databricks)
Como primeira etapa, configuramos as credenciais do Git e conectamos um repositório remoto ao Databricks . Em seguida, criamos um repositório remoto e clonamos-o em nosso repositório Databricks , bem como em nossa máquina local. Finalmente, precisamos configurar a autenticação entre a CLI do Databricks no executor do Gitlab e nosso espaço de trabalho do Databricks. Para fazer isso, devemos adicionar duas variáveis de ambiente, DATABRICKS_HOST e DATABRICKS_TOKEN às nossas configurações de pipeline CI/CD do Gitlab. Para isso abra seu repositório no Gitlab, vá em Configurações → CI/CD → Variáveis → Adicionar variáveis


Tanto o dbx quanto o DAB são construídos em torno das APIs REST do Databricks , portanto, em sua essência, eles são muito semelhantes. Seguirei as etapas para criar um pacote manualmente a partir de nosso projeto dbx existente.
A primeira coisa que precisamos configurar para nosso projeto DAB é a configuração de implantação. No dbx, usamos dois arquivos para definir e configurar nossos ambientes e fluxos de trabalho (jobs e pipelines). Para configurar o ambiente, utilizamos .dbx/project.json e para definir os fluxos de trabalho, utilizamos deployment.yml .
No DAB, tudo vai para databricks.yml , que está localizado na pasta raiz do seu projeto. Veja como parece:
bundle: name: DAB_tutorial #our bundle name # These are for any custom variables for use throughout the bundle. variables: my_cluster_id: description: The ID of an existing cluster. default: xxxx-xxxxx-xxxxxxxx #The remote workspace URL and workspace authentication credentials are read from the caller's local configuration profile named <asset-bundle-tutorial> workspace: profile: asset-bundle-tutorial # These are the default job and pipeline settings if not otherwise overridden in # the following "targets" top-level mapping. resources: jobs: etl_job: tasks: - task_key: "main" existing_cluster_id: ${var.my_cluster_id} python_wheel_task: package_name: "my_package" entry_point: "etl_job" # take a look at the setup.py entry_points section for details on how to define an entrypoint libraries: - whl: ../dist/*.whl - task_key: "eda" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/explorative_analysis.py source: WORKSPACE depends_on: - task_key: "main" test_job: tasks: - task_key: "main_notebook" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/run_unit_test.py source: WORKSPACE libraries: - pypi: package: pytest # These are the targets to use for deployments and workflow runs. One and only one of these # targets can be set to "default: true". targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: true workspace: profile: asset-bundle-tutorial root_path: /Users/${workspace.current_user.userName}/.bundle/${bundle.name}/my-envs/${bundle.target} host: <path to your databricks dev workspace>
O arquivo de configuração do pacote databricks.yml consiste em seções chamadas mapeamentos. Esses mapeamentos nos permitem modularizar o arquivo de configuração em blocos lógicos separados. Existem 8 mapeamentos de nível superior:
pacote
variáveis
área de trabalho
artefatos
incluir
recursos
sincronizar
alvos
Aqui, usamos cinco desses mapeamentos para organizar nosso projeto.
pacote :
No mapeamento do bundle , definimos o nome do pacote configurável. Aqui também podemos definir um ID de cluster padrão que deve ser usado para nossos ambientes de desenvolvimento, bem como informações sobre a URL e branch do Git.
variáveis :
Podemos usar o mapeamento variables para definir variáveis personalizadas e tornar nosso arquivo de configuração mais reutilizável. Por exemplo, declaramos uma variável para o ID de um cluster existente e a usamos em diferentes fluxos de trabalho. Agora, caso queira utilizar um cluster diferente, basta alterar o valor da variável.
recursos :
O mapeamento resources é onde definimos nossos fluxos de trabalho. Inclui zero ou um de cada um dos seguintes mapeamentos: experiments , jobs , models e pipelines . Este é basicamente nosso arquivo deployment.yml no projeto dbx. Embora existam algumas pequenas diferenças:
- Para
python_wheel_task, devemos incluir o caminho para nosso pacote wheel; caso contrário, o Databricks não conseguirá encontrar a biblioteca. Você pode encontrar mais informações sobre como construir pacotes de rodas usando DAB aqui . - Podemos usar caminhos relativos em vez de caminhos completos para executar as tarefas do notebook. O caminho para a implantação do notebook é relativo ao arquivo
databricks.ymlno qual esta tarefa é declarada.
alvos :
O mapeamento targets é onde definimos as configurações e recursos das diferentes etapas/ambientes dos nossos projetos. Por exemplo, para um pipeline típico de CI/CD, teríamos três alvos: desenvolvimento, preparação e produção. Cada destino pode consistir em todos os mapeamentos de nível superior (exceto targets ) como mapeamentos filhos. Aqui está o esquema do mapeamento de destino ( databricks.yml ).
targets: <some-unique-programmatic-identifier-for-this-target>: artifacts: ... bundle: ... compute_id: string default: true | false mode: development resources: ... sync: ... variables: <preceding-unique-variable-name>: <non-default-value> workspace: ...
O mapeamento filho nos permite substituir as configurações padrão que definimos anteriormente nos mapeamentos de nível superior. Por exemplo, se quisermos ter um espaço de trabalho isolado do Databricks para cada estágio do nosso pipeline de CI/CD, devemos definir o mapeamento filho do espaço de trabalho para cada destino.
workspace: profile: my-default-profile targets: dev: default: true test: workspace: host: https://<staging-workspace-url> prod: workspace: host: https://<production-workspace-url>
incluir:
O mapeamento include nos permite dividir nosso arquivo de configuração em módulos diferentes. Por exemplo, podemos salvar nossos recursos e variáveis no arquivo resources/dev_job.yml e importá-los para nosso arquivo databricks.yml .
# yaml-language-server: $schema=bundle_config_schema.json bundle: name: DAB_tutorial #our bundle name workspace: profile: asset-bundle-tutorial include: - ./resources/*.yml targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: truePara uma explicação mais detalhada das configurações DAB, confira configurações do Databricks Asset Bundle
Fluxos de trabalho
Os fluxos de trabalho são exatamente o que descrevi no blog anterior. As únicas diferenças são a localização dos artefatos e arquivos.


O esqueleto do projeto
aqui está como é o projeto final
ASSET-BUNDLE-TUTORAL/ ├─ my_package/ │ ├─ tasks/ │ │ ├─ __init__.py │ │ ├─ sample_etl_job.py │ ├─ __init__.py │ ├─ common.py ├─ test/ │ ├─ conftest.py │ ├─ test_sample.py ├─ notebooks/ │ ├─ explorative_analysis.py │ ├─ run_unit_test.py ├─ resources/ │ ├─ dev_jobs.yml ├─ .gitignore ├─ .gitlab-ci.yml ├─ databricks.yml ├─ README.md ├─ setup.py
Validar, implantar e executar
Agora, abra seu terminal e execute os seguintes comandos no diretório raiz:
validar: Primeiro, devemos verificar se nosso arquivo de configuração tem o formato e a sintaxe corretos. Se a validação for bem-sucedida, você obterá uma representação JSON da configuração do pacote configurável. Em caso de erro, corrija-o e execute o comando novamente até receber o arquivo JSON.
databricks bundle validate
implantar: a implantação inclui a construção do pacote Python wheel e sua implantação em nosso espaço de trabalho do Databricks, a implantação dos notebooks e outros arquivos em nosso espaço de trabalho do Databricks e a criação de trabalhos em nossos fluxos de trabalho do Databricks.
databricks bundle deploySe nenhuma opção de comando for especificada, a CLI do Databricks usará o destino padrão conforme declarado nos arquivos de configuração do pacote configurável. Aqui, temos apenas um alvo, então isso não importa, mas para demonstrar isso, também podemos implantar um alvo específico usando o sinalizador
-t dev.
run: execute os trabalhos implantados. Aqui, podemos especificar qual trabalho queremos executar. Por exemplo, no comando a seguir, executamos o trabalho
test_jobno destino dev.databricks bundle run -t dev test_job
na saída você obtém um URL que aponta para o trabalho executado em seu espaço de trabalho.


você também pode encontrar seus trabalhos na seção Workflow do seu espaço de trabalho do Databricks.
Configuração do pipeline de CI
A configuração geral do nosso pipeline de CI permanece a mesma do projeto anterior. Consiste em duas etapas principais: teste e implantação . No estágio de teste , o unit-test-job executa os testes de unidade e implanta um fluxo de trabalho separado para teste. O estágio de implantação , ativado após a conclusão bem-sucedida do estágio de teste, cuida da implantação do seu fluxo de trabalho ETL principal.
Aqui, temos que adicionar etapas adicionais antes de cada estágio para instalar a CLI do Databricks e configurar o perfil de autenticação. Fazemos isso na seção before_script do nosso pipeline de CI. A palavra-chave before_script é usada para definir uma matriz de comandos que devem ser executados antes dos comandos script de cada tarefa. Mais sobre isso pode ser encontrado aqui .
Opcionalmente, você pode usar a palavra-chave after_project para definir uma matriz de comandos que devem ser executados APÓS cada trabalho. Aqui, podemos usar databricks bundle destroy --auto-approve para limpar após o término de cada trabalho. Em geral, nosso pipeline passa por estas etapas:
- Instale a CLI do Databricks e crie o perfil de configuração.
- Construa o projeto.
- Envie os artefatos de build para o workspace do Databricks.
- Instale o pacote wheel em seu cluster.
- Crie os trabalhos em fluxos de trabalho do Databricks.
- Execute os trabalhos.
aqui está a aparência do nosso .gitlab-ci.yml :
image: python:3.9 stages: # List of stages for jobs, and their order of execution - test - deploy default: before_script: - echo "install databricks cli" - curl -V - curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh - echo "databricks CLI installation finished" - echo "create the configuration profile for token authentication" - echo "[asset-bundle-tutorial]" > ~/.databrickscfg - echo "token = $DATABRICKS_TOKEN" >> ~/.databrickscfg - echo "host = $DATABRICKS_HOST" >> ~/.databrickscfg - echo "validate the bundle" - databricks bundle validate after_script: - echo "remove all workflows" #- databricks bundle destroy --auto-approve unit-test-job: # This job runs in the test stage. stage: test script: - echo "Running unit tests." - pip3 install --upgrade wheel setuptools - pip install -e ".[local]" - databricks bundle deploy -t dev - databricks bundle run -t dev test_job deploy-job: # This job runs in the deploy stage. stage: deploy # It only runs when *both* jobs in the test stage complete successfully. script: - echo "Deploying application..." - echo "Install dependencies" - pip install -e ".[local]" - echo "Deploying Job" - databricks bundle deploy -t dev - databricks bundle run -t dev etl_job
Notas
Aqui estão algumas notas que podem ajudá-lo a configurar seu projeto de pacote:
- Neste blog, criamos nosso pacote manualmente. Na minha experiência, isso ajuda a compreender melhor os conceitos e recursos subjacentes. Mas se quiser iniciar seu projeto rapidamente, você pode usar modelos de pacote padrão e não padrão fornecidos pela Databricks ou outras partes. Confira esta postagem do Databricks para saber como iniciar um projeto com o modelo Python padrão.
- Quando você implanta seu código usando
databricks bundle deploy, a CLI do Databricks executa o comandopython3 setup.py bdist_wheelpara construir seu pacote usando o arquivo setup.py . Se você já possui o python3 instalado, mas sua máquina usa o alias python em vez de python3 , você terá problemas. No entanto, isso é fácil de corrigir. Por exemplo, aqui e aqui estão dois threads Stack Overflow com algumas soluções.
Qual é o próximo
Na próxima postagem do blog, começarei com minha primeira postagem sobre como iniciar um projeto de aprendizado de máquina no Databricks. Será a primeira postagem do meu próximo pipeline de aprendizado de máquina de ponta a ponta, cobrindo tudo, desde o desenvolvimento até a produção. Fique atento!
Recursos
Certifique-se de atualizar o cluster_id em resources/dev_jobs.yml
- Migrar de dbx para pacotes | Blocos de dados na AWS
- Tarefas de trabalho de desenvolvimento do Databricks Asset Bundles | Blocos de dados na AWS
- Modos de implantação do Databricks Asset Bundle | Blocos de dados na AWS
- Desenvolva uma roda Python usando Databricks Asset Bundles | Blocos de dados na AWS
- Pacotes de ativos do Databricks: uma abordagem padrão e unificada para implantação de produtos de dados no Databricks (youtube.com)
- repositório e slides https://github.com/databricks/databricks-asset-bundles-dais2023








