
























소개
이전 블로그 에서는 Databricks CLI eXtensions 및 GitLab을 사용하여 CI 파이프라인을 구축하는 방법을 보여드렸습니다. 이 게시물에서는 권장되는 최신 Databricks 배포 프레임워크인 Databricks Asset Bundle을 사용하여 동일한 목표를 달성하는 방법을 보여 드리겠습니다. DAB는 Databricks 플랫폼을 위한 복잡한 데이터, 분석 및 ML 프로젝트 개발을 간소화하기 위한 새로운 도구로 Databricks 팀에서 적극적으로 지원하고 개발했습니다.
DAB 및 해당 기능에 대한 일반적인 소개는 건너뛰고 Databricks 설명서를 참조하겠습니다. 여기서는 이전 블로그의 dbx 프로젝트를 DAB로 마이그레이션하는 방법에 중점을 두겠습니다. 그 과정에서 각 단계를 더 잘 이해하는 데 도움이 되는 몇 가지 개념과 기능을 설명하겠습니다.
Databricks GUI를 사용한 개발 패턴
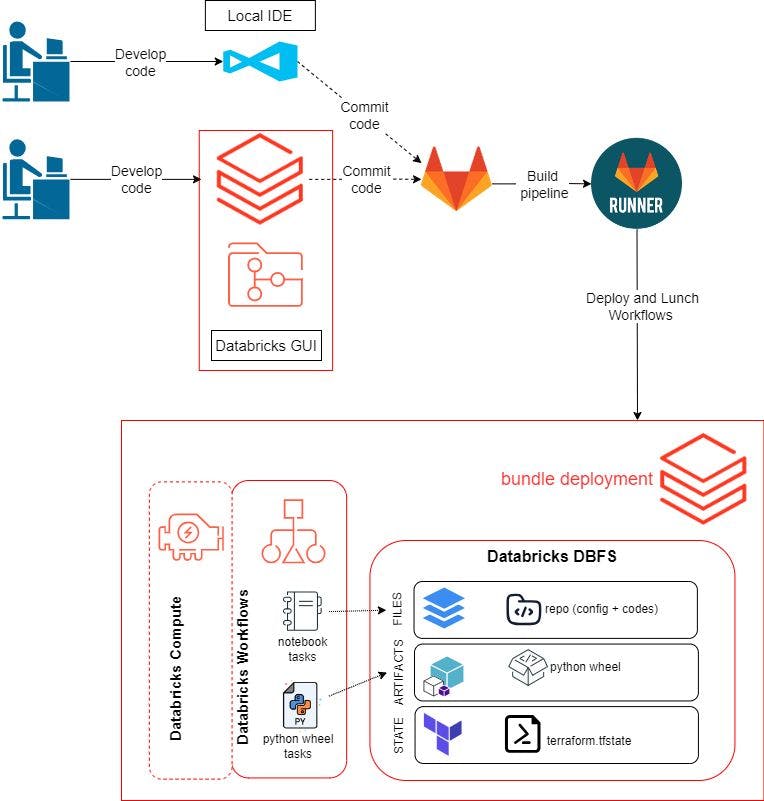
이전 게시물에서는 Databricks GUI를 사용하여 코드와 워크플로를 개발하고 테스트했습니다. 이 블로그 게시물에서는 로컬 환경을 사용하여 코드를 개발할 수 있기를 원합니다. 워크플로는 다음과 같습니다.
원격 저장소를 만들고 이를 로컬 환경 및 Databricks 작업 영역에 복제합니다. 여기서는 GitLab을 사용합니다.
프로그램 논리를 개발하고 Databricks GUI 내부 또는 로컬 IDE에서 테스트하세요. 여기에는 Python Wheel 패키지를 구축하기 위한 Python 스크립트, pytest를 사용하여 데이터 품질을 테스트하기 위한 스크립트, pytest를 실행하기 위한 노트북이 포함됩니다.
GitLab에 코드를 푸시합니다.
git pushGitLab Runner를 트리거하여 Databricks 자산 번들을 사용하여 Databricks에서 리소스를 구축, 배포 및 시작합니다.개발 환경 설정
데이터브릭스 CLI
우선 로컬 머신에 Databricks CLI 버전 0.205 이상을 설치해야 합니다. 설치된 Databricks CLI 버전을 확인하려면
databricks -v명령을 실행합니다. Databricks CLI 버전 0.205 이상을 설치하려면 Databricks CLI 설치 또는 업데이트를 참조하세요.입증
Databricks는 개발 머신의 Databricks CLI와 Databricks 작업 영역 간의 다양한 인증 방법을 지원합니다. 이 자습서에서는 Databricks 개인 액세스 토큰 인증을 사용합니다. 이는 두 단계로 구성됩니다.
- Databricks 작업 영역에서 개인 액세스 토큰을 만듭니다.
- 로컬 머신에서 Databricks 구성 프로필을 만듭니다.
Databricks 작업 영역에서 Databricks 토큰을 생성하려면 사용자 설정 → 개발자 → 액세스 토큰 → 관리 → 새 토큰 생성으로 이동합니다.
구성 프로필을 만들려면 다음 콘텐츠로 루트 폴더에
~/.databrickscfg파일을 만듭니다.

[asset-bundle-tutorial] host = https://xxxxxxxxxxx.cloud.databricks.com token = xxxxxxx 여기서 asset-bundle-tutorial 은 프로필 이름이고, 호스트는 작업 공간의 주소이며, 토큰은 방금 생성한 개인 액세스 토큰입니다.
터미널에서 databricks configure --profile asset-bundle-tutorial 실행하여 Databricks CLI를 사용하여 이 파일을 만들 수 있습니다. 이 명령은 Databricks Host 및 Personal Access Token 을 묻는 메시지를 표시합니다. --profile 플래그를 지정하지 않으면 프로필 이름이 DEFAULT 로 설정됩니다.
Git 통합(Databricks)
첫 번째 단계로 Git 자격 증명을 구성하고 원격 저장소를 Databricks에 연결합니다 . 다음으로 원격 저장소를 만들고 이를 Databricks repo 및 로컬 컴퓨터에 복제합니다 . 마지막으로 Gitlab 실행기의 Databricks CLI와 Databricks 작업 영역 간에 인증을 설정해야 합니다. 이를 위해서는 Gitlab CI/CD 파이프라인 구성에 DATABRICKS_HOST 및 DATABRICKS_TOKEN 이라는 두 가지 환경 변수를 추가해야 합니다. Gitlab에서 저장소를 열려면 설정→ CI/CD → 변수 → 변수 추가 로 이동하세요.


dbx와 DAB는 모두 Databricks REST API를 기반으로 구축되었으므로 핵심은 매우 유사합니다. 기존 dbx 프로젝트에서 수동으로 번들을 생성하는 단계를 진행하겠습니다.
DAB 프로젝트를 위해 가장 먼저 설정해야 할 것은 배포 구성입니다. dbx에서는 두 개의 파일을 사용하여 환경과 워크플로우(작업 및 파이프라인)를 정의하고 설정합니다. 환경을 설정하기 위해 .dbx/project.json 사용했고, 워크플로를 정의하기 위해 deployment.yml 사용했습니다.
DAB에서는 모든 것이 프로젝트의 루트 폴더에 있는 databricks.yml 로 들어갑니다. 그 모습은 다음과 같습니다.
bundle: name: DAB_tutorial #our bundle name # These are for any custom variables for use throughout the bundle. variables: my_cluster_id: description: The ID of an existing cluster. default: xxxx-xxxxx-xxxxxxxx #The remote workspace URL and workspace authentication credentials are read from the caller's local configuration profile named <asset-bundle-tutorial> workspace: profile: asset-bundle-tutorial # These are the default job and pipeline settings if not otherwise overridden in # the following "targets" top-level mapping. resources: jobs: etl_job: tasks: - task_key: "main" existing_cluster_id: ${var.my_cluster_id} python_wheel_task: package_name: "my_package" entry_point: "etl_job" # take a look at the setup.py entry_points section for details on how to define an entrypoint libraries: - whl: ../dist/*.whl - task_key: "eda" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/explorative_analysis.py source: WORKSPACE depends_on: - task_key: "main" test_job: tasks: - task_key: "main_notebook" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/run_unit_test.py source: WORKSPACE libraries: - pypi: package: pytest # These are the targets to use for deployments and workflow runs. One and only one of these # targets can be set to "default: true". targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: true workspace: profile: asset-bundle-tutorial root_path: /Users/${workspace.current_user.userName}/.bundle/${bundle.name}/my-envs/${bundle.target} host: <path to your databricks dev workspace>
databricks.yml 번들 구성 파일은 매핑이라는 섹션으로 구성됩니다. 이러한 매핑을 통해 구성 파일을 별도의 논리 블록으로 모듈화할 수 있습니다. 8개의 최상위 수준 매핑이 있습니다.
묶음
변수
작업 공간
인공물
포함하다
자원
동조
목표
여기서는 이러한 매핑 중 5개를 사용하여 프로젝트를 구성합니다.
번들 :
bundle 매핑에서 번들 이름을 정의합니다. 여기서는 개발 환경에 사용해야 하는 기본 클러스터 ID와 Git URL 및 분기에 대한 정보를 정의할 수도 있습니다.
변수 :
variables 매핑을 사용하여 사용자 정의 변수를 정의하고 구성 파일을 더욱 재사용 가능하게 만들 수 있습니다. 예를 들어 기존 클러스터의 ID에 대한 변수를 선언하고 이를 다양한 워크플로에서 사용합니다. 이제 다른 클러스터를 사용하려는 경우 변수 값을 변경하기만 하면 됩니다.
자원 :
resources 매핑은 워크플로를 정의하는 곳입니다. 여기에는 experiments , jobs , models 및 pipelines 매핑 중 0개 또는 1개가 포함됩니다. 이것은 기본적으로 dbx 프로젝트의 deployment.yml 파일입니다. 약간의 차이점이 있지만 다음과 같습니다.
-
python_wheel_task의 경우 휠 패키지 경로를 포함해야 합니다. 그렇지 않으면 Databricks가 라이브러리를 찾을 수 없습니다. 여기에서 DAB를 사용하여 휠 패키지를 만드는 방법에 대한 자세한 정보를 찾을 수 있습니다. - 전체 경로 대신 상대 경로를 사용하여 노트북 작업을 실행할 수 있습니다. 배포할 노트북의 경로는 이 작업이 선언된
databricks.yml파일을 기준으로 합니다.
대상 :
targets 매핑은 프로젝트의 다양한 단계/환경의 구성과 리소스를 정의하는 곳입니다. 예를 들어 일반적인 CI/CD 파이프라인의 경우 개발, 스테이징, 프로덕션이라는 세 가지 목표가 있습니다. 각 대상은 모든 최상위 매핑( targets 제외)을 하위 매핑으로 구성할 수 있습니다. 다음은 대상 매핑의 스키마( databricks.yml )입니다.
targets: <some-unique-programmatic-identifier-for-this-target>: artifacts: ... bundle: ... compute_id: string default: true | false mode: development resources: ... sync: ... variables: <preceding-unique-variable-name>: <non-default-value> workspace: ...
하위 매핑을 사용하면 이전에 최상위 매핑에서 정의한 기본 구성을 재정의할 수 있습니다. 예를 들어 CI/CD 파이프라인의 각 단계에 대해 격리된 Databricks 작업 영역을 갖고 싶다면 각 대상에 대해 작업 영역 하위 매핑을 설정해야 합니다.
workspace: profile: my-default-profile targets: dev: default: true test: workspace: host: https://<staging-workspace-url> prod: workspace: host: https://<production-workspace-url>
포함하다:
include 매핑을 사용하면 구성 파일을 여러 모듈로 나눌 수 있습니다. 예를 들어 리소스와 변수를 resources/dev_job.yml 파일에 저장하고 이를 databricks.yml 파일로 가져올 수 있습니다.
# yaml-language-server: $schema=bundle_config_schema.json bundle: name: DAB_tutorial #our bundle name workspace: profile: asset-bundle-tutorial include: - ./resources/*.yml targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: trueDAB 구성에 대한 자세한 설명은 Databricks 자산 번들 구성을 확인하세요.
워크플로
워크플로는 이전 블로그에서 설명한 것과 정확히 같습니다. 유일한 차이점은 아티팩트와 파일의 위치입니다.


프로젝트 뼈대
최종 프로젝트는 다음과 같습니다
ASSET-BUNDLE-TUTORAL/ ├─ my_package/ │ ├─ tasks/ │ │ ├─ __init__.py │ │ ├─ sample_etl_job.py │ ├─ __init__.py │ ├─ common.py ├─ test/ │ ├─ conftest.py │ ├─ test_sample.py ├─ notebooks/ │ ├─ explorative_analysis.py │ ├─ run_unit_test.py ├─ resources/ │ ├─ dev_jobs.yml ├─ .gitignore ├─ .gitlab-ci.yml ├─ databricks.yml ├─ README.md ├─ setup.py
검증, 배포 및 실행
이제 터미널을 열고 루트 디렉터리에서 다음 명령을 실행하세요.
유효성 검사: 먼저 구성 파일의 형식과 구문이 올바른지 확인해야 합니다. 유효성 검사가 성공하면 번들 구성의 JSON 표현을 얻게 됩니다. 오류가 발생하면 이를 수정하고 JSON 파일을 받을 때까지 명령을 다시 실행하세요.
databricks bundle validate
배포: 배포에는 Python 휠 패키지를 빌드하여 Databricks 작업 영역에 배포하고, 노트북 및 기타 파일을 Databricks 작업 영역에 배포하고, Databricks 워크플로에서 작업을 만드는 작업이 포함됩니다.
databricks bundle deploy명령 옵션을 지정하지 않으면 Databricks CLI는 번들 구성 파일 내에 선언된 기본 대상을 사용합니다. 여기서는 대상이 하나만 있으므로 중요하지 않습니다. 하지만 이를 보여주기 위해
-t dev플래그를 사용하여 특정 대상을 배포할 수도 있습니다.
실행: 배포된 작업을 실행합니다. 여기에서 실행할 작업을 지정할 수 있습니다. 예를 들어 다음 명령에서는 dev 대상에서
test_job작업을 실행합니다.databricks bundle run -t dev test_job
출력에는 작업공간에서 실행되는 작업을 가리키는 URL이 표시됩니다.


Databricks 작업 영역의 워크플로 섹션에서 작업을 찾을 수도 있습니다.
CI 파이프라인 구성
CI 파이프라인의 일반적인 설정은 이전 프로젝트와 동일하게 유지됩니다. 테스트 와 배포 라는 두 가지 주요 단계로 구성됩니다. 테스트 단계에서 unit-test-job 단위 테스트를 실행하고 테스트를 위해 별도의 워크플로를 배포합니다. 테스트 단계가 성공적으로 완료되면 활성화되는 배포 단계에서는 기본 ETL 워크플로의 배포를 처리합니다.
여기에서는 Databricks CLI를 설치하고 인증 프로필을 설정하기 위해 각 단계 전에 추가 단계를 추가해야 합니다. CI 파이프라인의 before_script 섹션에서 이 작업을 수행합니다. before_script 키워드는 각 작업의 script 명령 이전에 실행되어야 하는 명령 배열을 정의하는 데 사용됩니다. 이에 대한 자세한 내용은 여기에서 확인할 수 있습니다.
선택적으로 after_project 키워드를 사용하여 각 작업 후에 실행해야 하는 명령 배열을 정의할 수 있습니다. 여기서는 databricks bundle destroy --auto-approve 사용하여 각 작업이 끝난 후 정리할 수 있습니다. 일반적으로 우리 파이프라인은 다음 단계를 거칩니다.
- Databricks CLI를 설치하고 구성 프로필을 만듭니다.
- 프로젝트를 빌드합니다.
- 빌드 아티팩트를 Databricks 작업 영역으로 푸시합니다.
- 클러스터에 휠 패키지를 설치합니다.
- Databricks Workflows에서 작업을 만듭니다.
- 작업을 실행합니다.
.gitlab-ci.yml 은 다음과 같습니다.
image: python:3.9 stages: # List of stages for jobs, and their order of execution - test - deploy default: before_script: - echo "install databricks cli" - curl -V - curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh - echo "databricks CLI installation finished" - echo "create the configuration profile for token authentication" - echo "[asset-bundle-tutorial]" > ~/.databrickscfg - echo "token = $DATABRICKS_TOKEN" >> ~/.databrickscfg - echo "host = $DATABRICKS_HOST" >> ~/.databrickscfg - echo "validate the bundle" - databricks bundle validate after_script: - echo "remove all workflows" #- databricks bundle destroy --auto-approve unit-test-job: # This job runs in the test stage. stage: test script: - echo "Running unit tests." - pip3 install --upgrade wheel setuptools - pip install -e ".[local]" - databricks bundle deploy -t dev - databricks bundle run -t dev test_job deploy-job: # This job runs in the deploy stage. stage: deploy # It only runs when *both* jobs in the test stage complete successfully. script: - echo "Deploying application..." - echo "Install dependencies" - pip install -e ".[local]" - echo "Deploying Job" - databricks bundle deploy -t dev - databricks bundle run -t dev etl_job
노트
다음은 번들 프로젝트를 설정하는 데 도움이 될 수 있는 몇 가지 참고 사항입니다.
- 이 블로그에서는 번들을 수동으로 생성했습니다. 내 경험에 따르면 이는 기본 개념과 기능을 더 잘 이해하는 데 도움이 됩니다. 그러나 프로젝트를 빠르게 시작하려면 Databricks 또는 다른 당사자가 제공하는 기본 및 기본이 아닌 번들 템플릿을 사용할 수 있습니다. 기본 Python 템플릿을 사용하여 프로젝트를 시작하는 방법에 대해 알아보려면 이 Databricks 게시물을 확인하세요.
-
databricks bundle deploy사용하여 코드를 배포할 때 Databricks CLI는python3 setup.py bdist_wheel명령을 실행하여 setup.py 파일을 사용하여 패키지를 빌드합니다. python3이 이미 설치되어 있지만 컴퓨터가 python3 대신 python 별칭을 사용하는 경우 문제가 발생합니다. 그러나 이는 수정하기 쉽습니다. 예를 들어 여기 와 여기에 몇 가지 솔루션이 포함된 두 개의 스택 오버플로 스레드가 있습니다.
무엇 향후 계획
다음 블로그 게시물에서는 Databricks에서 기계 학습 프로젝트를 시작하는 방법에 대한 첫 번째 블로그 게시물부터 시작하겠습니다. 이는 개발부터 생산까지 모든 것을 다루는 다가오는 엔드투엔드 기계 학습 파이프라인의 첫 번째 게시물이 될 것입니다. 계속 지켜봐 주시기 바랍니다!
자원
resources/dev_jobs.yml 에서 Cluster_id를 업데이트했는지 확인하세요.
- dbx에서 번들로 마이그레이션 | AWS의 Databricks
- Databricks 자산 번들 개발 작업 | AWS의 Databricks
- Databricks 자산 번들 배포 모드 | AWS의 Databricks
- Databricks 자산 번들을 사용하여 Python 휠 개발 | AWS의 Databricks
- Databricks 자산 번들: Databricks에 데이터 제품을 배포하기 위한 표준 통합 접근 방식(youtube.com)








