























Bağlantı tahmini, bir ağdaki düğümler arasında gelecekteki veya eksik bir bağlantının olasılığını tahmin etmeyi amaçlar. Sosyal ağlar, öneri sistemleri ve biyolojik ağlar gibi çeşitli uygulamalarda yaygın olarak kullanılır. Sosyal ağlardaki bağlantı tahminine odaklanacağız ve bunun için önceki gönderide DGL ile yerel bağlantı tahmini için kullanılan aynı veri setini kullanacağız - Twitch sosyal ağ verileri . Bu veri seti, düğümleri Twitch kullanıcılarını ve kenarları kullanıcılar arasındaki karşılıklı arkadaşlığı temsil eden bir grafik içerir. Bunu, mevcut bağlantılara ve kullanıcı özelliklerine dayanarak kullanıcılar arasındaki yeni bağlantıları ('takipler') tahmin etmek için kullanacağız.
Diyagramda görüldüğü gibi, bağlantı tahmini; verilerin içe aktarılması, dışa aktarılması ve ön işlenmesi, bir modelin eğitilmesi ve hiperparametrelerinin optimize edilmesi ve son olarak gerçek tahminler üreten bir çıkarım uç noktasının kurulması ve sorgulanması gibi birden fazla adımı içerir.
Bu yazıda sürecin ilk adımına, yani verileri hazırlamaya ve bir Neptün kümesine yüklemeye odaklanacağız.
VERİLERİN NEPTUNE LOADER BİÇİMİNE DÖNÜŞTÜRÜLMESİ
Veri setindeki başlangıç dosyaları şu şekilde görünüyor:
Köşeler (başlangıç):
id,days,mature,views,partner,new_id 73045350,1459,False,9528,False,2299 61573865,1629,True,3615,False,153 ...
Kenarlar (başlangıç):
from,to 6194,255 6194,980 ...Bu verileri Neptune'e yüklemek için, önce verileri desteklenen biçimlerden birine dönüştürmemiz gerekir. Bir Gremlin grafiği kullanacağız, bu nedenle veriler köşeleri ve kenarları olan CSV dosyalarında olmalı ve CSV dosyalarındaki sütun adları bu deseni izlemelidir.
Dönüştürülen veriler şu şekilde görünüyor:
Köşeler (dönüştürülmüş):
~id,~label,days:Int(single),mature:Bool(single),partner:Bool(single),views:Int(single) 2299,"user",1459,false,false,9528 153,"user",1629,true,false,3615 ...
Kenarlar (dönüştürülmüş):
~from,~to,~label,~id 6194,255,"follows",0 255,6194,"follows",1 ...
Ve bu, veri kümesiyle birlikte sağlanan dosyaları Neptune Loader'ın desteklediği biçime dönüştüren koddur:
import pandas as pd # === Vertices === # load vertices from the CSV file provided in the dataset vertices_df = pd.read_csv('./musae_ENGB_target.csv') # drop old ID column, we'll use the new IDs only vertices_df.drop('id', axis=1, inplace=True) # rename columns for Neptune Bulk Loader: # add ~ to the id column, # add data types and cardinality to vertex property columns vertices_df.rename( columns={ 'new_id': '~id', 'days': 'days:Int(single)', 'mature': 'mature:Bool(single)', 'views': 'views:Int(single)', 'partner': 'partner:Bool(single)', }, inplace=True, ) # add vertex label column vertices_df['~label'] = 'user' # save vertices to a file, ignore the index column vertices_df.to_csv('vertices.csv', index=False) # === Edges === # load edges from the CSV file provided in the dataset edges_df = pd.read_csv('./musae_ENGB_edges.csv') # add reverse edges (the original edges represent mutual follows) reverse_edges_df = edges_df[['to', 'from']] reverse_edges_df.rename(columns={'from': 'to', 'to': 'from'}, inplace=True) reverse_edges_df.head() edges_df = pd.concat([edges_df, reverse_edges_df], ignore_index=True) # rename columns according to Neptune Bulk Loader format: # add ~ to 'from' and 'to' column names edges_df.rename(columns={ 'from': '~from', 'to': '~to', }, inplace=True, ) edges_df.head() # add edge label column edges_df['~label'] = 'follows' # add edge IDs edges_df['~id'] = range(len(edges_df)) # save edges to a file, ignore the index column edges_df.to_csv('edges.csv', index=False)S3: IAM ROLÜ VE VPC SON NOKTASINDA NEPTUNE DB ERİŞİM VERİLERİNE İZİN VERME
Dosyaları dönüştürdükten sonra bunları S3'e yükleyeceğiz. Bunu yapmak için, önce vertices.csv ve edges.csv dosyalarımızı içerecek bir kova oluşturmamız gerekiyor. Ayrıca, bu S3 kovasına erişime izin veren (ekli politikada) ve Neptune'ün bunu üstlenmesine izin veren bir güven politikasına sahip bir IAM rolü oluşturmamız gerekiyor (ekran görüntüsüne bakın).

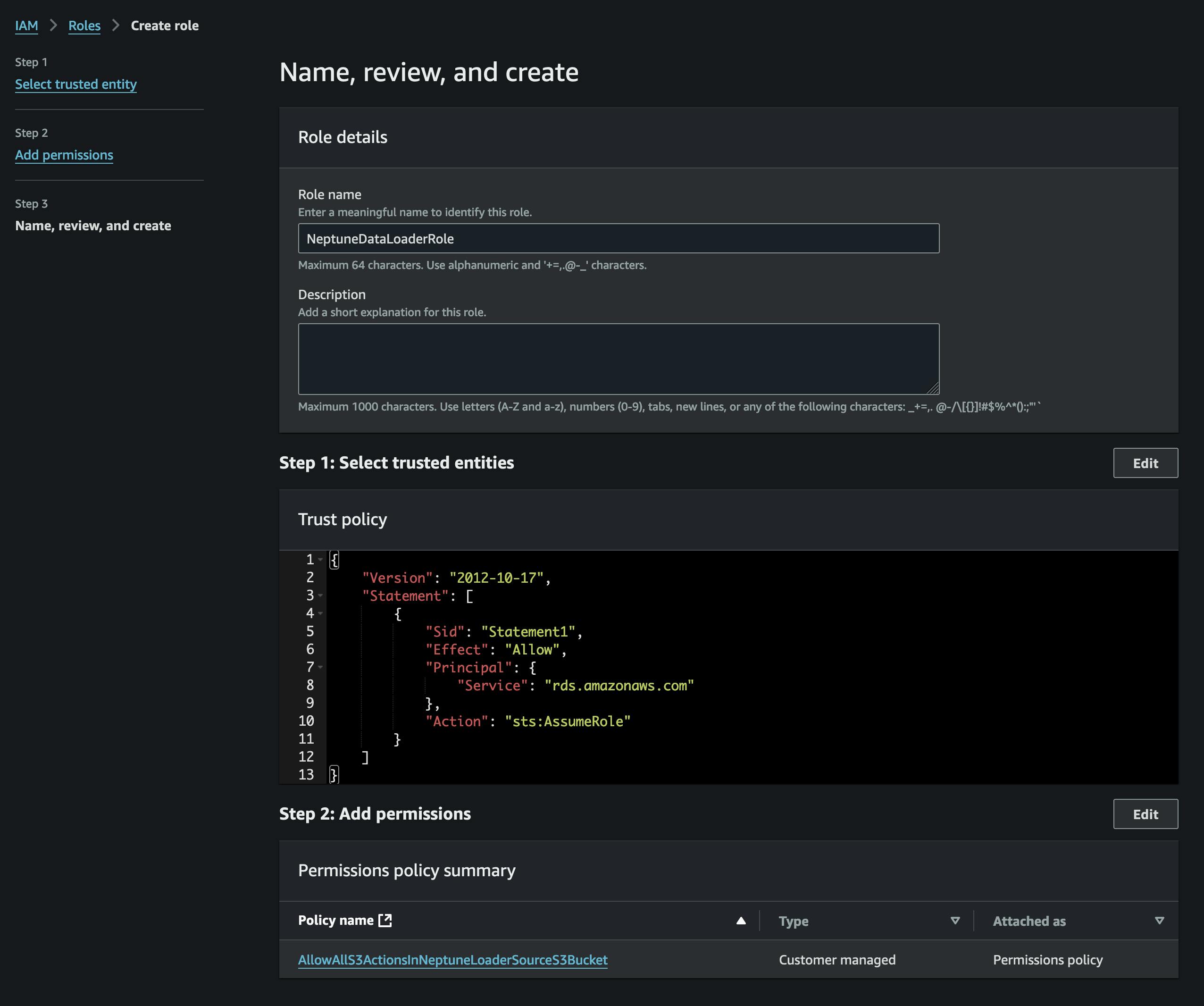
Rolü Neptune kümemize ekleyeceğiz (Neptune konsolunu kullanarak) ve ardından aktif hale gelmesini bekleyeceğiz (veya kümeyi yeniden başlatacağız).




Ayrıca Neptune'den S3'e ağ trafiğine izin vermemiz gerekiyor ve bunu yapmak için VPC'mizde S3 için bir Gateway VPC uç noktasına ihtiyacımız var:


VERİ YÜKLENİYOR
Artık verilerimizi yüklemeye başlamaya hazırız. Bunu yapmak için, VPC içinden kümenin API'sini çağırıp 2 yükleme işi oluşturmamız gerekir: biri vertices.csv için, diğeri ise edges.csv için. API çağrıları aynıdır, yalnızca S3 nesne anahtarı değişir. VPC yapılandırması ve güvenlik grupları, curl çalıştırdığınız örnekten Neptune kümesine trafiğe izin vermelidir.
curl -XPOST \ -H 'Content-Type: application/json' \ https://your-neptune-endpoint:8182/loader -d ' { "source" : "s3://bucket-name/vertices.csv", "format" : "csv", "iamRoleArn" : "arn:aws:iam::account-id:role/role-name", "region" : "us-east-1", "failOnError" : "TRUE", "parallelism" : "HIGH", "updateSingleCardinalityProperties" : "FALSE" }'
Yükleyici API'si, iş kimliğini (' loadId ') içeren bir JSON ile yanıt verir:
{ "status" : "200 OK", "payload" : { "loadId" : "your-load-id" } }Yüklemenin tamamlanıp tamamlanmadığını bu API'yi kullanarak kontrol edebilirsiniz:
curl -XGET https://your-neptune-endpoint:8182/loader/your-load-idŞöyle cevap veriyor:
{ "status" : "200 OK", "payload" : { "feedCount" : [ { "LOAD_COMPLETED" : 1 } ], "overallStatus" : { "fullUri" : "s3://bucket-name/vertices.csv", "runNumber" : 1, "retryNumber" : 1, "status" : "LOAD_COMPLETED", "totalTimeSpent" : 8, "startTime" : 1, "totalRecords" : 35630, "totalDuplicates" : 0, "parsingErrors" : 0, "datatypeMismatchErrors" : 0, "insertErrors" : 0 } } Vertices.csv'den köşeler yüklendikten sonra, aynı API'yi kullanarak kenarları yükleyebiliriz . Bunu yapmak için, vertices.csv'yi edges.csv ile değiştirmemiz ve ilk curl komutunu tekrar çalıştırmamız yeterlidir.
YÜKLENEN VERİLERİN DOĞRULANMASI
Yükleme işleri tamamlandığında, Neptune kümesine Gremlin sorguları göndererek yüklenen verilere erişebiliriz. Bu sorguları çalıştırmak için, bir Gremlin konsoluyla Neptune'e bağlanabilir veya bir Neptune / Sagemaker Notebook kullanabiliriz. Neptune kümesiyle birlikte oluşturulabilen veya küme zaten çalışırken daha sonra eklenebilen bir Sagemaker notebook kullanacağız.
Bu, oluşturduğumuz köşe sayısını getiren sorgudur:
%%gremlin gV().count()Ayrıca bir tepe noktasını ID'ye göre alabilir ve özelliklerinin doğru şekilde yüklendiğini şu şekilde doğrulayabilirsiniz:
%%gremlin gV('some-vertex-id').elementMap() 

Kenarları yükledikten sonra, bunların başarıyla yüklendiğini doğrulayabilirsiniz.
%%gremlin gE().count()Ve
%%gremlin gE('0').elementMap()


Bu, sürecin veri yükleme kısmını tamamlar. Bir sonraki yazıda, Neptune'den ML model eğitimi için kullanılabilecek bir biçimde veri aktarmaya bakacağız.








