























La predicción de enlaces tiene como objetivo predecir la probabilidad de una conexión futura o perdida entre nodos de una red. Se utiliza ampliamente en diversas aplicaciones, como redes sociales, sistemas de recomendación y redes biológicas. Nos centraremos en la predicción de enlaces en redes sociales y, para ello, utilizaremos el mismo conjunto de datos que se utilizó para la predicción de enlaces locales con DGL en la publicación anterior: datos de la red social Twitch . Este conjunto de datos contiene un gráfico con sus nodos que representan a los usuarios de Twitch y los bordes que representan la amistad mutua entre usuarios. Lo utilizaremos para predecir nuevos enlaces ("follows") entre usuarios, en función de los enlaces existentes y las características del usuario.
Como se muestra en el diagrama, la predicción de enlaces implica varios pasos que incluyen la importación, la exportación y el preprocesamiento de los datos, el entrenamiento de un modelo y la optimización de sus hiperparámetros y, finalmente, la configuración y consulta de un punto final de inferencia que genera predicciones reales.
En esta publicación nos centraremos en el primer paso del proceso: preparar los datos y cargarlos en un clúster de Neptune.
CONVERSIÓN DE DATOS AL FORMATO NEPTUNE LOADER
Los archivos iniciales del conjunto de datos se ven así:
Vértices (iniciales):
id,days,mature,views,partner,new_id 73045350,1459,False,9528,False,2299 61573865,1629,True,3615,False,153 ...
Aristas (iniciales):
from,to 6194,255 6194,980 ...Para cargar esos datos en Neptune, primero debemos convertirlos a uno de los formatos admitidos. Usaremos un gráfico Gremlin, por lo que los datos deben estar en archivos CSV con vértices y aristas, y los nombres de las columnas en los archivos CSV deben seguir este patrón .
Así es como se ven los datos convertidos:
Vértices (convertidos):
~id,~label,days:Int(single),mature:Bool(single),partner:Bool(single),views:Int(single) 2299,"user",1459,false,false,9528 153,"user",1629,true,false,3615 ...
Bordes (convertidos):
~from,~to,~label,~id 6194,255,"follows",0 255,6194,"follows",1 ...
Y este es el código que convierte los archivos proporcionados con el conjunto de datos al formato que admite Neptune Loader:
import pandas as pd # === Vertices === # load vertices from the CSV file provided in the dataset vertices_df = pd.read_csv('./musae_ENGB_target.csv') # drop old ID column, we'll use the new IDs only vertices_df.drop('id', axis=1, inplace=True) # rename columns for Neptune Bulk Loader: # add ~ to the id column, # add data types and cardinality to vertex property columns vertices_df.rename( columns={ 'new_id': '~id', 'days': 'days:Int(single)', 'mature': 'mature:Bool(single)', 'views': 'views:Int(single)', 'partner': 'partner:Bool(single)', }, inplace=True, ) # add vertex label column vertices_df['~label'] = 'user' # save vertices to a file, ignore the index column vertices_df.to_csv('vertices.csv', index=False) # === Edges === # load edges from the CSV file provided in the dataset edges_df = pd.read_csv('./musae_ENGB_edges.csv') # add reverse edges (the original edges represent mutual follows) reverse_edges_df = edges_df[['to', 'from']] reverse_edges_df.rename(columns={'from': 'to', 'to': 'from'}, inplace=True) reverse_edges_df.head() edges_df = pd.concat([edges_df, reverse_edges_df], ignore_index=True) # rename columns according to Neptune Bulk Loader format: # add ~ to 'from' and 'to' column names edges_df.rename(columns={ 'from': '~from', 'to': '~to', }, inplace=True, ) edges_df.head() # add edge label column edges_df['~label'] = 'follows' # add edge IDs edges_df['~id'] = range(len(edges_df)) # save edges to a file, ignore the index column edges_df.to_csv('edges.csv', index=False)PERMITIR EL ACCESO A DATOS DE NEPTUNE DB EN S3: FUNCIÓN DE IAM Y PUNTO EXTREMO DE VPC
Después de convertir los archivos, los subiremos a S3. Para ello, primero debemos crear un depósito que contendrá nuestros archivos vertices.csv y edges.csv. También debemos crear un rol de IAM que permita el acceso a ese depósito de S3 (en la política adjunta) y que tenga una política de confianza que permita que Neptune la asuma (consulte la captura de pantalla).

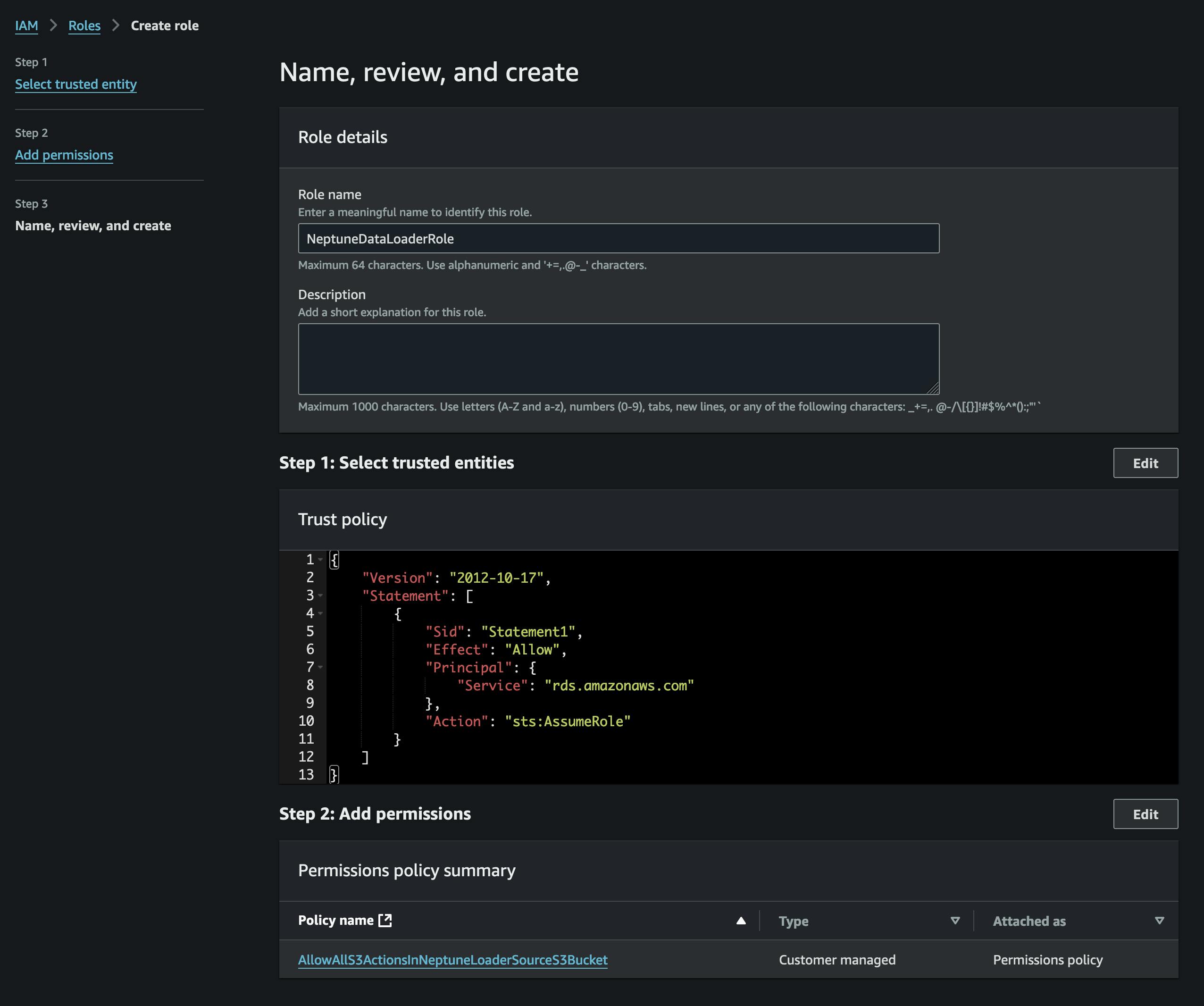
Agregaremos el rol a nuestro clúster Neptune (usando la consola Neptune) y luego esperaremos a que se active (o reiniciaremos el clúster).




También necesitamos permitir el tráfico de red desde Neptune a S3, y para ello necesitamos un punto final de VPC de puerta de enlace para S3 en nuestra VPC:


CARGANDO DATOS
Ahora estamos listos para comenzar a cargar nuestros datos. Para ello, debemos llamar a la API del clúster desde dentro de la VPC y crear dos trabajos de carga: uno para vertices.csv y otro para edges.csv. Las llamadas a la API son idénticas, solo varía la clave del objeto S3. La configuración de la VPC y los grupos de seguridad deben permitir el tráfico desde la instancia en la que ejecuta curl hasta el clúster de Neptune.
curl -XPOST \ -H 'Content-Type: application/json' \ https://your-neptune-endpoint:8182/loader -d ' { "source" : "s3://bucket-name/vertices.csv", "format" : "csv", "iamRoleArn" : "arn:aws:iam::account-id:role/role-name", "region" : "us-east-1", "failOnError" : "TRUE", "parallelism" : "HIGH", "updateSingleCardinalityProperties" : "FALSE" }'
La API del cargador responde con un JSON que contiene el identificador del trabajo (' loadId '):
{ "status" : "200 OK", "payload" : { "loadId" : "your-load-id" } }Puede comprobar si la carga se ha completado utilizando esta API:
curl -XGET https://your-neptune-endpoint:8182/loader/your-load-idResponde con esto:
{ "status" : "200 OK", "payload" : { "feedCount" : [ { "LOAD_COMPLETED" : 1 } ], "overallStatus" : { "fullUri" : "s3://bucket-name/vertices.csv", "runNumber" : 1, "retryNumber" : 1, "status" : "LOAD_COMPLETED", "totalTimeSpent" : 8, "startTime" : 1, "totalRecords" : 35630, "totalDuplicates" : 0, "parsingErrors" : 0, "datatypeMismatchErrors" : 0, "insertErrors" : 0 } } Una vez que se cargan los vértices desde vertices.csv , podemos cargar los bordes usando la misma API. Para ello, simplemente reemplazamos vertices.csv con edges.csv y ejecutamos nuevamente el primer comando curl .
VERIFICANDO LOS DATOS CARGADOS
Cuando se completen los trabajos de carga, podremos acceder a los datos cargados enviando consultas de Gremlin al clúster de Neptune. Para ejecutar estas consultas, podemos conectarnos a Neptune con una consola de Gremlin o utilizar un Notebook de Neptune/Sagemaker. Utilizaremos un Notebook de Sagemaker que se puede crear junto con el clúster de Neptune o agregar más tarde cuando el clúster ya esté en ejecución.
Esta es la consulta que obtiene el número de vértices que creamos:
%%gremlin gV().count()También puedes obtener un vértice por ID y verificar que sus propiedades se cargaron correctamente con:
%%gremlin gV('some-vertex-id').elementMap() 

Después de cargar los bordes, puede verificar que se hayan cargado correctamente con
%%gremlin gE().count()y
%%gremlin gE('0').elementMap()


Con esto finaliza la parte de carga de datos del proceso. En la próxima publicación, veremos cómo exportar datos desde Neptune en un formato que se pueda usar para el entrenamiento de modelos de ML.








