























リンク予測は、ネットワーク内のノード間の将来の接続または接続が失われる可能性を予測することを目的としています。これは、ソーシャル ネットワーク、推奨システム、生物学的ネットワークなど、さまざまなアプリケーションで広く使用されています。ここではソーシャル ネットワークのリンク予測に焦点を当て、前回の投稿で DGL を使用したローカル リンク予測に使用されたものと同じデータセット ( Twitch ソーシャル ネットワーク データ) を使用します。このデータセットには、Twitch ユーザーを表すノードとユーザー間の相互の友情を表すエッジを持つグラフが含まれています。これを使用して、既存のリンクとユーザーの特徴に基づいて、ユーザー間の新しいリンク (「フォロー」) を予測します。
図に示すように、リンク予測には、データのインポート、エクスポート、前処理、モデルのトレーニングとハイパーパラメータの最適化、そして最後に実際の予測を生成する推論エンドポイントの設定とクエリなど、複数のステップが含まれます。
この投稿では、プロセスの最初のステップである、データの準備と Neptune クラスターへのロードに焦点を当てます。
データを NEPTUNE ローダー形式に変換する
データセット内の初期ファイルは次のようになります。
頂点(初期):
id,days,mature,views,partner,new_id 73045350,1459,False,9528,False,2299 61573865,1629,True,3615,False,153 ...
エッジ(初期):
from,to 6194,255 6194,980 ...そのデータを Neptune にロードするには、まずデータをサポートされている形式のいずれかに変換する必要があります。Gremlin グラフを使用するため、データは頂点とエッジを含む CSV ファイルである必要があり、CSV ファイル内の列名はこのパターンに従う必要があります。
変換されたデータは次のようになります。
頂点(変換済み):
~id,~label,days:Int(single),mature:Bool(single),partner:Bool(single),views:Int(single) 2299,"user",1459,false,false,9528 153,"user",1629,true,false,3615 ...
エッジ(変換済み):
~from,~to,~label,~id 6194,255,"follows",0 255,6194,"follows",1 ...
これは、データセットで提供されるファイルを Neptune Loader がサポートする形式に変換するコードです。
import pandas as pd # === Vertices === # load vertices from the CSV file provided in the dataset vertices_df = pd.read_csv('./musae_ENGB_target.csv') # drop old ID column, we'll use the new IDs only vertices_df.drop('id', axis=1, inplace=True) # rename columns for Neptune Bulk Loader: # add ~ to the id column, # add data types and cardinality to vertex property columns vertices_df.rename( columns={ 'new_id': '~id', 'days': 'days:Int(single)', 'mature': 'mature:Bool(single)', 'views': 'views:Int(single)', 'partner': 'partner:Bool(single)', }, inplace=True, ) # add vertex label column vertices_df['~label'] = 'user' # save vertices to a file, ignore the index column vertices_df.to_csv('vertices.csv', index=False) # === Edges === # load edges from the CSV file provided in the dataset edges_df = pd.read_csv('./musae_ENGB_edges.csv') # add reverse edges (the original edges represent mutual follows) reverse_edges_df = edges_df[['to', 'from']] reverse_edges_df.rename(columns={'from': 'to', 'to': 'from'}, inplace=True) reverse_edges_df.head() edges_df = pd.concat([edges_df, reverse_edges_df], ignore_index=True) # rename columns according to Neptune Bulk Loader format: # add ~ to 'from' and 'to' column names edges_df.rename(columns={ 'from': '~from', 'to': '~to', }, inplace=True, ) edges_df.head() # add edge label column edges_df['~label'] = 'follows' # add edge IDs edges_df['~id'] = range(len(edges_df)) # save edges to a file, ignore the index column edges_df.to_csv('edges.csv', index=False)S3 内の NEPTUNE DB アクセス データを許可する: IAM ロールと VPC エンドポイント
ファイルを変換したら、S3 にアップロードします。そのためには、まず vertices.csv ファイルと edges.csv ファイルを格納するバケットを作成する必要があります。また、その S3 バケットへのアクセスを許可し (添付ポリシー内)、Neptune がそれを引き受けることができる信頼ポリシーを持つ IAM ロールを作成する必要があります (スクリーンショットを参照)。

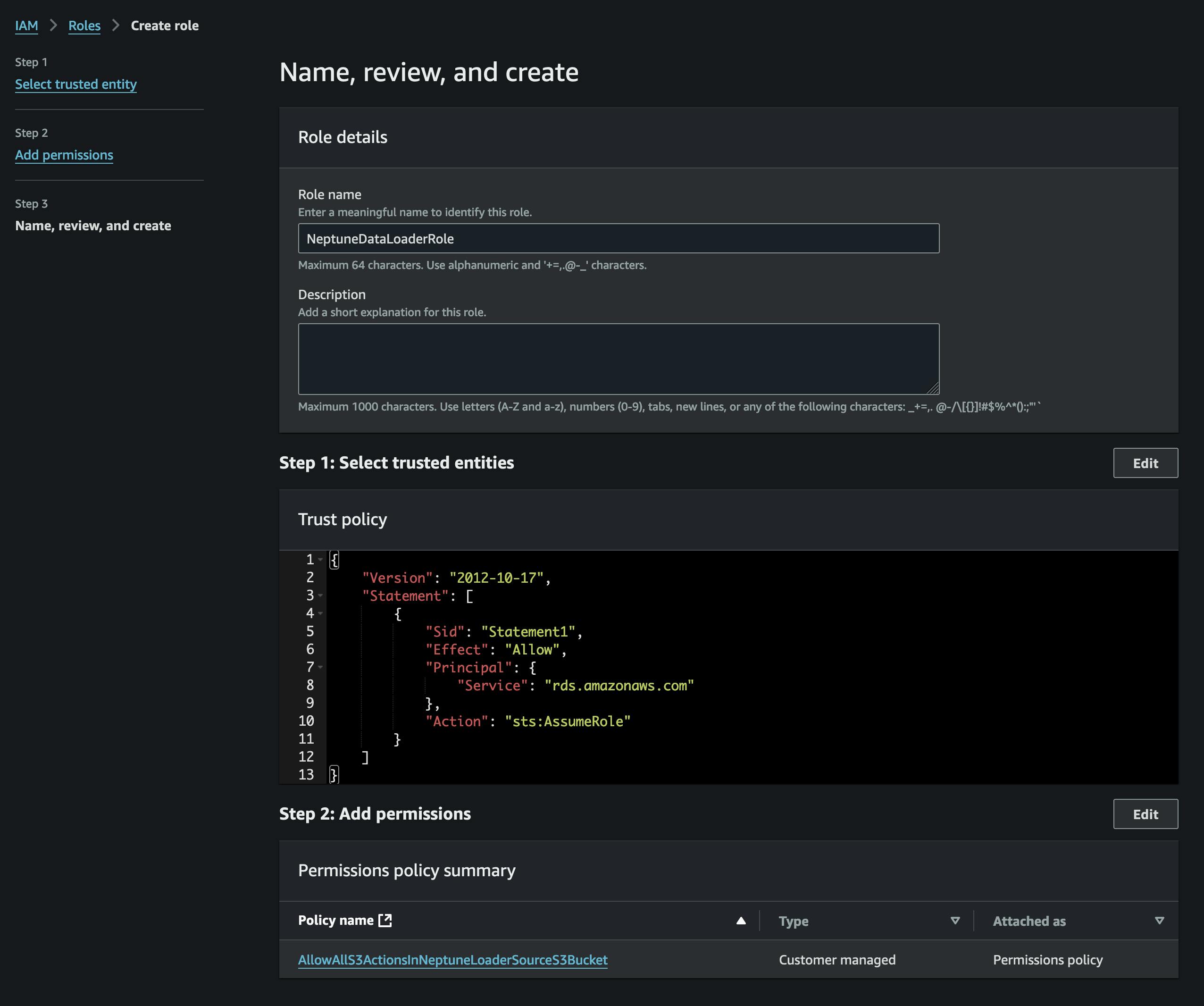
Neptune コンソールを使用して Neptune クラスターにロールを追加し、ロールがアクティブになるまで待機します (またはクラスターを再起動します)。




また、Neptune から S3 へのネットワーク トラフィックを許可する必要があり、そのためには VPC 内に S3 用のゲートウェイ VPC エンドポイントが必要です。


データの読み込み
これで、データのロードを開始する準備ができました。そのためには、VPC 内からクラスターの API を呼び出して、2 つのロードジョブを作成する必要があります。1 つは vertices.csv 用、もう 1 つは edges.csv 用です。API 呼び出しは同じで、S3 オブジェクト キーのみが異なります。VPC 構成とセキュリティ グループでは、 curl実行するインスタンスから Neptune クラスターへのトラフィックを許可する必要があります。
curl -XPOST \ -H 'Content-Type: application/json' \ https://your-neptune-endpoint:8182/loader -d ' { "source" : "s3://bucket-name/vertices.csv", "format" : "csv", "iamRoleArn" : "arn:aws:iam::account-id:role/role-name", "region" : "us-east-1", "failOnError" : "TRUE", "parallelism" : "HIGH", "updateSingleCardinalityProperties" : "FALSE" }'
ローダー API は、ジョブ ID (' loadId ') を含む JSON で応答します。
{ "status" : "200 OK", "payload" : { "loadId" : "your-load-id" } }次の API を使用して、読み込みが完了したかどうかを確認できます。
curl -XGET https://your-neptune-endpoint:8182/loader/your-load-id次のように応答します。
{ "status" : "200 OK", "payload" : { "feedCount" : [ { "LOAD_COMPLETED" : 1 } ], "overallStatus" : { "fullUri" : "s3://bucket-name/vertices.csv", "runNumber" : 1, "retryNumber" : 1, "status" : "LOAD_COMPLETED", "totalTimeSpent" : 8, "startTime" : 1, "totalRecords" : 35630, "totalDuplicates" : 0, "parsingErrors" : 0, "datatypeMismatchErrors" : 0, "insertErrors" : 0 } } vertices.csv から頂点が読み込まれたら、同じ API を使用してエッジを読み込むことができます。そのためには、 vertices.csv をedges.csvに置き換えて、最初のcurlコマンドを再度実行するだけです。
ロードされたデータの検証
ロードジョブが完了すると、Gremlin クエリを Neptune クラスターに送信することで、ロードされたデータにアクセスできます。これらのクエリを実行するには、Gremlin コンソールを使用して Neptune に接続するか、Neptune / Sagemaker Notebook を使用します。Neptune クラスターと一緒に作成することも、クラスターがすでに実行されているときに後で追加することもできる Sagemaker ノートブックを使用します。
これは、作成した頂点の数を取得するクエリです。
%%gremlin gV().count()次のようにして、ID で頂点を取得し、そのプロパティが正しく読み込まれたかどうかを確認することもできます。
%%gremlin gV('some-vertex-id').elementMap() 

エッジをロードした後、正常にロードされたかどうかを確認できます。
%%gremlin gE().count()そして
%%gremlin gE('0').elementMap()


これで、プロセスのデータロード部分は完了です。次の投稿では、ML モデルのトレーニングに使用できる形式で Neptune からデータをエクスポートする方法について説明します。








