























Parashikimi i lidhjes synon të parashikojë gjasat e një lidhjeje të ardhshme ose të munguar midis nyjeve në një rrjet. Përdoret gjerësisht në aplikacione të ndryshme, si rrjetet sociale, sistemet e rekomandimeve dhe rrjetet biologjike. Ne do të fokusohemi në parashikimin e lidhjeve në rrjetet sociale dhe për këtë do të përdorim të njëjtin grup të dhënash që është përdorur për parashikimin e lidhjeve lokale me DGL në postimin e mëparshëm - Të dhënat e rrjetit social Twitch . Ky grup të dhënash përmban një grafik me nyjet e tij që përfaqësojnë përdoruesit e Twitch dhe skajet që përfaqësojnë miqësinë e ndërsjellë midis përdoruesve. Ne do ta përdorim atë për të parashikuar lidhje të reja ('ndjekje') midis përdoruesve, bazuar në lidhjet ekzistuese dhe veçoritë e përdoruesit.
Siç tregohet në diagram, parashikimi i lidhjes përfshin hapa të shumtë duke përfshirë importimin, eksportimin dhe përpunimin paraprak të të dhënave, trajnimin e një modeli dhe optimizimin e hiperparametrave të tij, dhe në fund vendosjen dhe kërkimin e një pike përfundimi që gjeneron parashikimet aktuale.
Në këtë postim do të përqendrohemi në hapin e parë të procesit: përgatitjen e të dhënave dhe ngarkimin e tyre në një grup Neptuni.
KONVERTIMI I TË DHËNAVE NË FORMATIN E NGARKESIT NEPTUNI
Skedarët fillestarë në grupin e të dhënave duken kështu:
Kulmet (fillestare):
id,days,mature,views,partner,new_id 73045350,1459,False,9528,False,2299 61573865,1629,True,3615,False,153 ...
Skajet (fillestare):
from,to 6194,255 6194,980 ...Për të ngarkuar ato të dhëna në Neptun, së pari duhet t'i konvertojmë të dhënat në një nga formatet e mbështetura. Ne do të përdorim një grafik Gremlin, kështu që të dhënat duhet të jenë në skedarët CSV me kulme dhe skaje, dhe emrat e kolonave në skedarët CSV duhet të ndjekin këtë model .
Ja se si duken të dhënat e konvertuara:
Kulmet (të konvertuara):
~id,~label,days:Int(single),mature:Bool(single),partner:Bool(single),views:Int(single) 2299,"user",1459,false,false,9528 153,"user",1629,true,false,3615 ...
Skajet (të konvertuara):
~from,~to,~label,~id 6194,255,"follows",0 255,6194,"follows",1 ...
Dhe ky është kodi që konverton skedarët e dhënë me grupin e të dhënave në formatin që mbështet Neptune Loader:
import pandas as pd # === Vertices === # load vertices from the CSV file provided in the dataset vertices_df = pd.read_csv('./musae_ENGB_target.csv') # drop old ID column, we'll use the new IDs only vertices_df.drop('id', axis=1, inplace=True) # rename columns for Neptune Bulk Loader: # add ~ to the id column, # add data types and cardinality to vertex property columns vertices_df.rename( columns={ 'new_id': '~id', 'days': 'days:Int(single)', 'mature': 'mature:Bool(single)', 'views': 'views:Int(single)', 'partner': 'partner:Bool(single)', }, inplace=True, ) # add vertex label column vertices_df['~label'] = 'user' # save vertices to a file, ignore the index column vertices_df.to_csv('vertices.csv', index=False) # === Edges === # load edges from the CSV file provided in the dataset edges_df = pd.read_csv('./musae_ENGB_edges.csv') # add reverse edges (the original edges represent mutual follows) reverse_edges_df = edges_df[['to', 'from']] reverse_edges_df.rename(columns={'from': 'to', 'to': 'from'}, inplace=True) reverse_edges_df.head() edges_df = pd.concat([edges_df, reverse_edges_df], ignore_index=True) # rename columns according to Neptune Bulk Loader format: # add ~ to 'from' and 'to' column names edges_df.rename(columns={ 'from': '~from', 'to': '~to', }, inplace=True, ) edges_df.head() # add edge label column edges_df['~label'] = 'follows' # add edge IDs edges_df['~id'] = range(len(edges_df)) # save edges to a file, ignore the index column edges_df.to_csv('edges.csv', index=False)LEJIMI I TË DHËNAVE TË QASJES SË NEPTUNE DB NË S3: ROLI IAM DHE POINTA VPC
Pas konvertimit të skedarëve, ne do t'i ngarkojmë ato në S3. Për ta bërë këtë, së pari duhet të krijojmë një kovë që do të përmbajë skedarët tanë vertices.csv dhe edges.csv. Ne gjithashtu duhet të krijojmë një rol IAM që lejon aksesin në atë kovë S3 (në politikën e bashkangjitur) dhe ka një politikë besimi që lejon Neptun ta marrë atë (referojuni pamjes së ekranit).

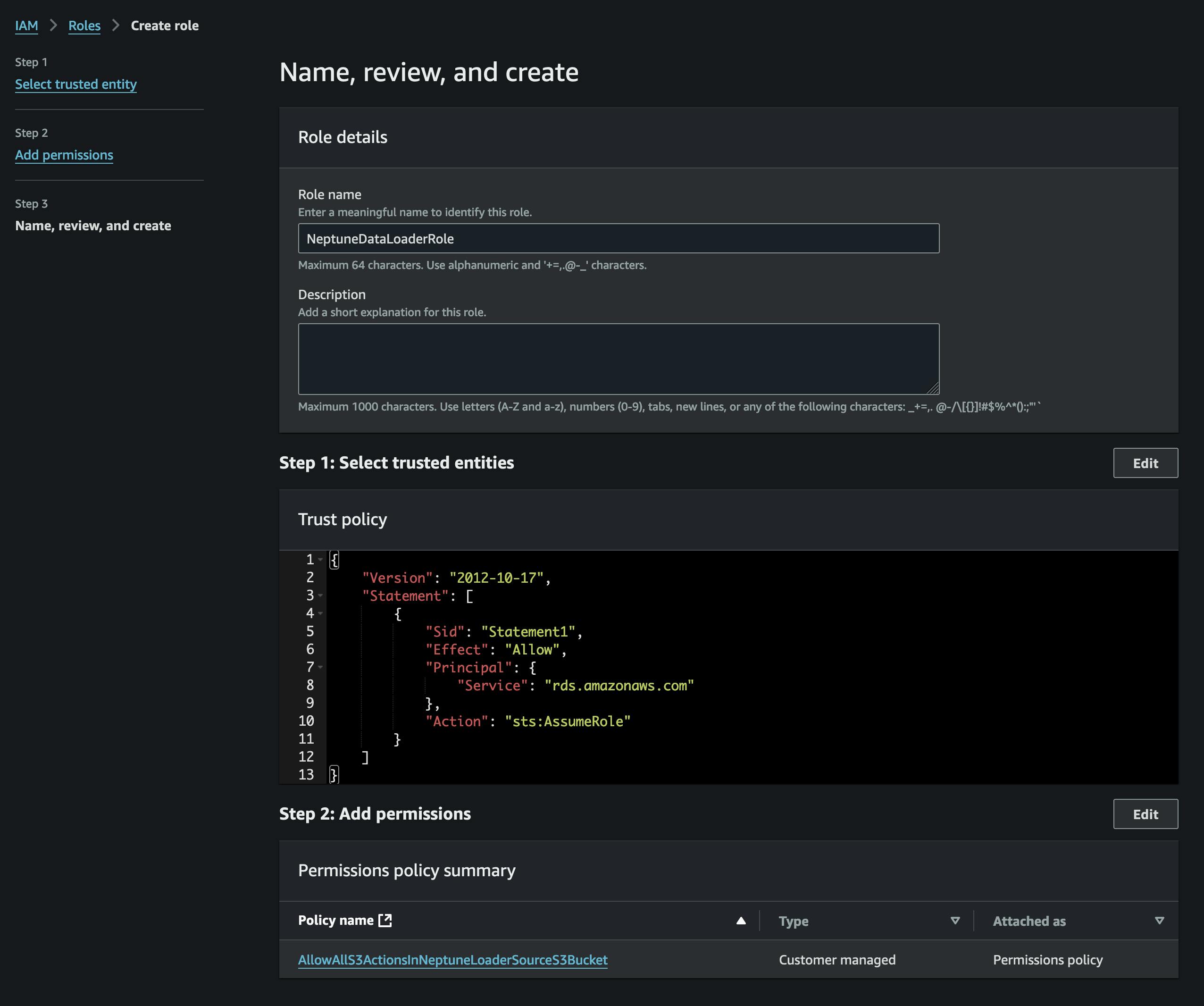
Ne do ta shtojmë rolin në grupin tonë të Neptunit (duke përdorur konsolën e Neptunit) dhe më pas do të presim që ai të bëhet aktiv (ose të rindizni grupin).




Ne gjithashtu duhet të lejojmë trafikun e rrjetit nga Neptuni në S3, dhe për ta bërë këtë na duhet një pikë fundore Gateway VPC për S3 në VPC-në tonë:


NGARKONI TË DHËNAT
Tani jemi gati të fillojmë ngarkimin e të dhënave tona. Për ta bërë këtë, ne duhet të thërrasim API-në e grupit nga brenda VPC dhe të krijojmë 2 punë ngarkimi: një për vertices.csv dhe një tjetër për edges.csv. Thirrjet API janë identike, vetëm tasti i objektit S3 ndryshon. Konfigurimi VPC dhe grupet e sigurisë duhet të lejojnë trafikun nga shembulli ku drejtoni curl deri në grupimin e Neptunit.
curl -XPOST \ -H 'Content-Type: application/json' \ https://your-neptune-endpoint:8182/loader -d ' { "source" : "s3://bucket-name/vertices.csv", "format" : "csv", "iamRoleArn" : "arn:aws:iam::account-id:role/role-name", "region" : "us-east-1", "failOnError" : "TRUE", "parallelism" : "HIGH", "updateSingleCardinalityProperties" : "FALSE" }'
API-ja e ngarkuesit përgjigjet me një JSON që përmban ID-në e punës (' loadId '):
{ "status" : "200 OK", "payload" : { "loadId" : "your-load-id" } }Ju mund të kontrolloni nëse ngarkimi ka përfunduar duke përdorur këtë API:
curl -XGET https://your-neptune-endpoint:8182/loader/your-load-idAi përgjigjet me këtë:
{ "status" : "200 OK", "payload" : { "feedCount" : [ { "LOAD_COMPLETED" : 1 } ], "overallStatus" : { "fullUri" : "s3://bucket-name/vertices.csv", "runNumber" : 1, "retryNumber" : 1, "status" : "LOAD_COMPLETED", "totalTimeSpent" : 8, "startTime" : 1, "totalRecords" : 35630, "totalDuplicates" : 0, "parsingErrors" : 0, "datatypeMismatchErrors" : 0, "insertErrors" : 0 } } Pasi kulmet janë ngarkuar nga vertices.csv , ne mund të ngarkojmë skajet duke përdorur të njëjtin API. Për ta bërë këtë, ne thjesht zëvendësojmë vertices.csv me edges.csv dhe ekzekutojmë sërish komandën e parë curl .
VERIFIKIMI I TË DHËNAVE TË NGARKUARA
Kur të përfundojnë punët e ngarkimit, ne mund t'i qasemi të dhënave të ngarkuara duke dërguar pyetje Gremlin në grupimin e Neptunit. Për të ekzekutuar këto pyetje, ne mund të lidhemi me Neptun me një tastierë Gremlin ose të përdorim një fletore Neptune / Sagemaker. Ne do të përdorim një fletore Sagemaker që mund të krijohet së bashku me grupin e Neptunit ose të shtohet më vonë kur grupi është tashmë në punë.
Ky është pyetja që merr numrin e kulmeve që kemi krijuar:
%%gremlin gV().count()Ju gjithashtu mund të merrni një kulm me ID dhe të verifikoni që vetitë e tij janë ngarkuar saktë me:
%%gremlin gV('some-vertex-id').elementMap() 

Pas ngarkimit të skajeve, mund të verifikoni që ato janë ngarkuar me sukses
%%gremlin gE().count()dhe
%%gremlin gE('0').elementMap()


Kjo përfundon pjesën e ngarkimit të të dhënave të procesit. Në postimin tjetër do të shikojmë eksportimin e të dhënave nga Neptuni në një format që mund të përdoret për trajnimin e modelit ML.




