























Сілтемені болжау желідегі түйіндер арасындағы болашақ немесе жоқ байланыс ықтималдығын болжауға бағытталған. Ол әлеуметтік желілер, ұсыныстар жүйелері және биологиялық желілер сияқты әртүрлі қолданбаларда кеңінен қолданылады. Біз әлеуметтік желілердегі сілтемелерді болжауға назар аударамыз және ол үшін Twitch әлеуметтік желісінің деректерінің алдыңғы постында DGL көмегімен жергілікті сілтемені болжау үшін пайдаланылған деректер жиынтығын қолданамыз. Бұл деректер жиынында Twitch пайдаланушыларын білдіретін түйіндері және пайдаланушылар арасындағы өзара достықты білдіретін жиектері бар график бар. Біз мұны бұрыннан бар сілтемелер мен пайдаланушы мүмкіндіктеріне негізделген пайдаланушылар арасындағы жаңа сілтемелерді ("іздестіру") болжау үшін қолданамыз.
Диаграммада көрсетілгендей, сілтемені болжау деректерді импорттауды, экспорттауды және алдын ала өңдеуді, үлгіні оқытуды және оның гиперпараметрлерін оңтайландыруды және соңында нақты болжамдарды жасайтын қорытынды нүктені орнатуды және сұрауды қамтитын бірнеше қадамдарды қамтиды.
Бұл постта біз процестің бірінші қадамына назар аударамыз: деректерді дайындау және оны Нептун кластеріне жүктеу.
ДЕРЕКТЕРДІ NEPTUNE LOADER ФОРМАТЫНА ТҰРНАЛУ
Деректер жиынындағы бастапқы файлдар келесідей болады:
Шыңдар (бастапқы):
id,days,mature,views,partner,new_id 73045350,1459,False,9528,False,2299 61573865,1629,True,3615,False,153 ...
Жиектер (бастапқы):
from,to 6194,255 6194,980 ...Бұл деректерді Нептунға жүктеу үшін алдымен деректерді қолдау көрсетілетін пішімдердің біріне түрлендіру керек. Біз Gremlin графигін қолданамыз, сондықтан деректер шыңдары мен жиектері бар CSV файлдарында болуы керек және CSV файлдарындағы баған атаулары осы үлгіге сәйкес болуы керек.
Түрлендірілген деректер келесідей:
Шыңдар (түрлендірілген):
~id,~label,days:Int(single),mature:Bool(single),partner:Bool(single),views:Int(single) 2299,"user",1459,false,false,9528 153,"user",1629,true,false,3615 ...
Жиектер (түрлендірілген):
~from,~to,~label,~id 6194,255,"follows",0 255,6194,"follows",1 ...
Бұл деректер жиынтығымен бірге берілген файлдарды Neptune Loader қолдайтын пішімге түрлендіретін код:
import pandas as pd # === Vertices === # load vertices from the CSV file provided in the dataset vertices_df = pd.read_csv('./musae_ENGB_target.csv') # drop old ID column, we'll use the new IDs only vertices_df.drop('id', axis=1, inplace=True) # rename columns for Neptune Bulk Loader: # add ~ to the id column, # add data types and cardinality to vertex property columns vertices_df.rename( columns={ 'new_id': '~id', 'days': 'days:Int(single)', 'mature': 'mature:Bool(single)', 'views': 'views:Int(single)', 'partner': 'partner:Bool(single)', }, inplace=True, ) # add vertex label column vertices_df['~label'] = 'user' # save vertices to a file, ignore the index column vertices_df.to_csv('vertices.csv', index=False) # === Edges === # load edges from the CSV file provided in the dataset edges_df = pd.read_csv('./musae_ENGB_edges.csv') # add reverse edges (the original edges represent mutual follows) reverse_edges_df = edges_df[['to', 'from']] reverse_edges_df.rename(columns={'from': 'to', 'to': 'from'}, inplace=True) reverse_edges_df.head() edges_df = pd.concat([edges_df, reverse_edges_df], ignore_index=True) # rename columns according to Neptune Bulk Loader format: # add ~ to 'from' and 'to' column names edges_df.rename(columns={ 'from': '~from', 'to': '~to', }, inplace=True, ) edges_df.head() # add edge label column edges_df['~label'] = 'follows' # add edge IDs edges_df['~id'] = range(len(edges_df)) # save edges to a file, ignore the index column edges_df.to_csv('edges.csv', index=False)S3: IAM РӨЛІ ЖӘНЕ VPC АЯҚТАУ НҰҚТАСЫНДА NEPTUNE DB ДЕРЕКТЕРІНЕ ҚАТЫНАСУҒА РҰҚСАТ БЕРУ
Файлдарды түрлендіруден кейін біз оларды S3 файлына жүктейміз. Мұны істеу үшін алдымен vertices.csv және edges.csv файлдарын қамтитын шелек жасау керек. Сондай-ақ, сол S3 шелегіне (қосалған саясатта) қол жеткізуге мүмкіндік беретін және Нептунға оны қабылдауға мүмкіндік беретін сенім саясаты бар IAM рөлін жасау керек (скриншотты қараңыз).

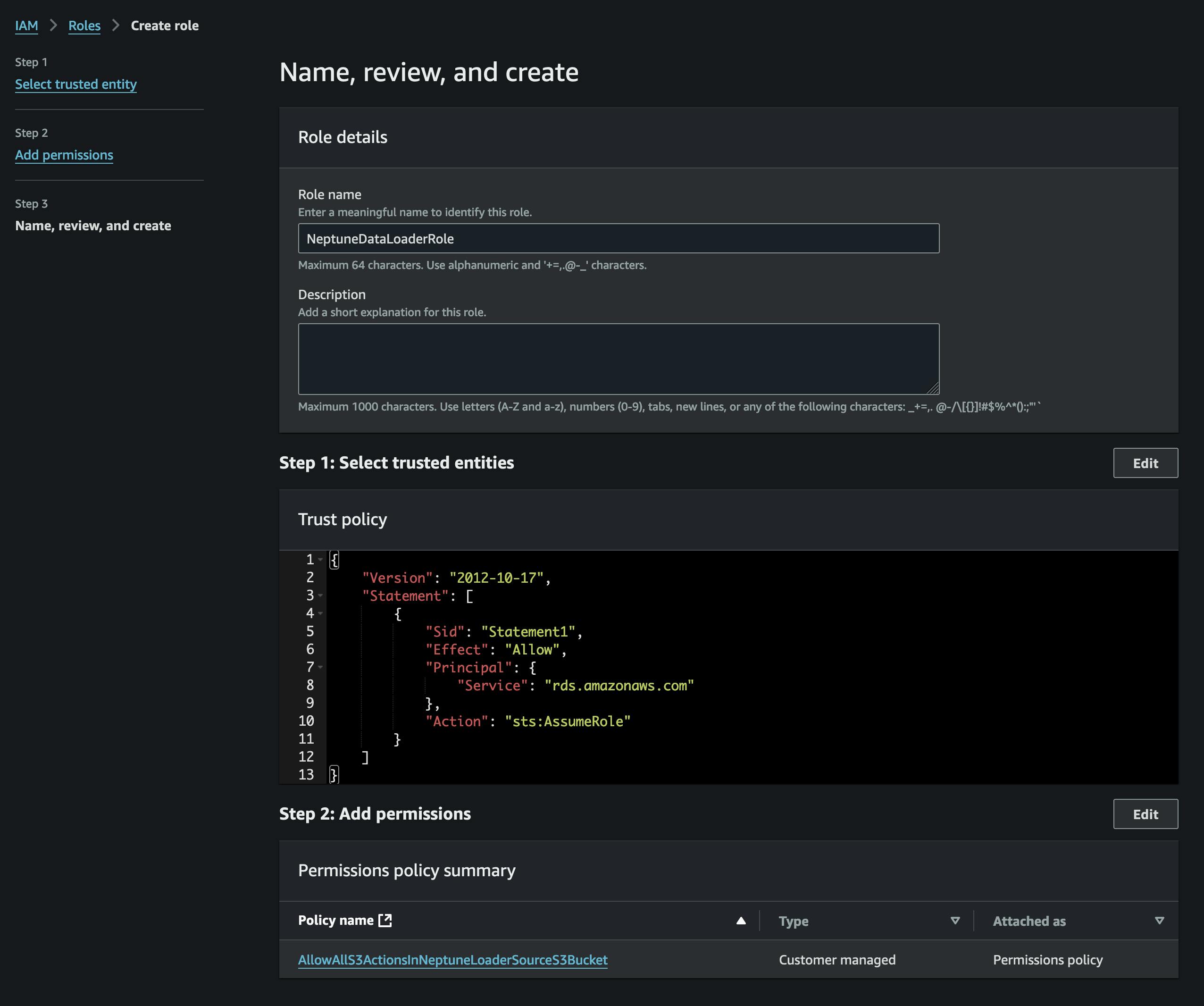
Біз рөлді Нептун кластеріне қосамыз (Нептун консолін пайдалану), содан кейін оның белсенді болуын күтеміз (немесе кластерді қайта жүктейміз).




Біз сондай-ақ Нептуннан S3-ке желілік трафикке рұқсат беруіміз керек және ол үшін VPC-де S3 үшін Gateway VPC соңғы нүктесі қажет:


ДЕРЕКТЕР ЖҮКТЕЛУДЕ
Біз қазір деректерімізді жүктеуге дайынбыз. Ол үшін кластердің API интерфейсін VPC ішінен шақырып, 2 жүктеу тапсырмасын жасауымыз керек: біреуі vertices.csv үшін, екіншісі edges.csv үшін. API шақырулары бірдей, тек S3 нысан кілті өзгереді. VPC конфигурациясы және қауіпсіздік топтары curl іске қосылған данадан Neptune кластеріне дейін трафикке рұқсат беруі керек.
curl -XPOST \ -H 'Content-Type: application/json' \ https://your-neptune-endpoint:8182/loader -d ' { "source" : "s3://bucket-name/vertices.csv", "format" : "csv", "iamRoleArn" : "arn:aws:iam::account-id:role/role-name", "region" : "us-east-1", "failOnError" : "TRUE", "parallelism" : "HIGH", "updateSingleCardinalityProperties" : "FALSE" }'
Жүктеуші API жұмыс идентификаторын (' loadId ') қамтитын JSON арқылы жауап береді:
{ "status" : "200 OK", "payload" : { "loadId" : "your-load-id" } }Осы API арқылы жүктеудің аяқталғанын тексеруге болады:
curl -XGET https://your-neptune-endpoint:8182/loader/your-load-idОл былай деп жауап береді:
{ "status" : "200 OK", "payload" : { "feedCount" : [ { "LOAD_COMPLETED" : 1 } ], "overallStatus" : { "fullUri" : "s3://bucket-name/vertices.csv", "runNumber" : 1, "retryNumber" : 1, "status" : "LOAD_COMPLETED", "totalTimeSpent" : 8, "startTime" : 1, "totalRecords" : 35630, "totalDuplicates" : 0, "parsingErrors" : 0, "datatypeMismatchErrors" : 0, "insertErrors" : 0 } } Шыңдар vertices.csv файлынан жүктелгеннен кейін, біз бірдей API арқылы жиектерді жүктей аламыз. Ол үшін vertices.csv файлын edges.csv деп ауыстырып, бірінші curl пәрменін қайта іске қосыңыз.
ЖҮКТЕЛГЕН ДЕРЕКТЕРДІ ТЕКСЕРУ
Жүктеу жұмыстары аяқталғанда, біз Neptune кластеріне Gremlin сұрауларын жіберу арқылы жүктелген деректерге қол жеткізе аламыз. Бұл сұрауларды орындау үшін біз Gremlin консолімен Нептунға қосыла аламыз немесе Neptune/Sagemaker ноутбукін пайдалана аламыз. Біз Neptune кластерімен бірге жасауға немесе кейінірек кластер жұмыс істеп тұрған кезде қосуға болатын Sagemaker жазу кітапшасын қолданамыз.
Бұл біз жасаған шыңдардың санын алатын сұрау:
%%gremlin gV().count()Сондай-ақ идентификатор бойынша шыңды алуға және оның сипаттарының дұрыс жүктелгенін тексеруге болады:
%%gremlin gV('some-vertex-id').elementMap() 

Жиектерді жүктегеннен кейін олардың сәтті жүктелгенін тексеруге болады
%%gremlin gE().count()және
%%gremlin gE('0').elementMap()


Бұл процестің деректерді жүктеу бөлігін аяқтайды. Келесі постта біз Нептуннан деректерді ML үлгісін оқыту үшін пайдалануға болатын форматта экспорттауды қарастырамыз.




