























Prediksi tautan bertujuan untuk memprediksi kemungkinan koneksi yang akan datang atau yang hilang antara node dalam jaringan. Prediksi ini banyak digunakan dalam berbagai aplikasi, seperti jaringan sosial, sistem rekomendasi, dan jaringan biologis. Kami akan fokus pada prediksi tautan di jaringan sosial, dan untuk itu kami akan menggunakan kumpulan data yang sama yang digunakan untuk prediksi tautan lokal dengan DGL di postingan sebelumnya - Data jaringan sosial Twitch . Kumpulan data ini berisi grafik dengan node-node yang mewakili pengguna Twitch dan tepi yang mewakili persahabatan timbal balik antara pengguna. Kami akan menggunakannya untuk memprediksi tautan baru ('follows') antara pengguna, berdasarkan tautan yang ada dan fitur pengguna.
Seperti ditunjukkan dalam diagram, prediksi tautan melibatkan beberapa langkah termasuk mengimpor, mengekspor, dan memproses awal data, melatih model dan mengoptimalkan hiperparameternya, serta akhirnya menyiapkan dan mengajukan kueri titik akhir inferensi yang menghasilkan prediksi aktual.
Dalam postingan ini kita akan fokus pada langkah pertama dari proses tersebut: menyiapkan data dan memuatnya ke dalam gugus Neptune.
MENGUBAH DATA KE FORMAT LOADER NEPTUNE
File awal dalam dataset terlihat seperti ini:
Titik sudut (awal):
id,days,mature,views,partner,new_id 73045350,1459,False,9528,False,2299 61573865,1629,True,3615,False,153 ...
Tepi (awal):
from,to 6194,255 6194,980 ...Untuk memuat data tersebut ke Neptune, pertama-tama kita perlu mengonversi data tersebut ke salah satu format yang didukung. Kita akan menggunakan grafik Gremlin, jadi datanya harus dalam berkas CSV dengan titik sudut dan tepi, dan nama kolom dalam berkas CSV harus mengikuti pola ini.
Berikut tampilan data yang dikonversi:
Titik sudut (dikonversi):
~id,~label,days:Int(single),mature:Bool(single),partner:Bool(single),views:Int(single) 2299,"user",1459,false,false,9528 153,"user",1629,true,false,3615 ...
Tepi (dikonversi):
~from,~to,~label,~id 6194,255,"follows",0 255,6194,"follows",1 ...
Dan ini adalah kode yang mengonversi file yang disertakan dengan dataset ke format yang didukung Neptune Loader:
import pandas as pd # === Vertices === # load vertices from the CSV file provided in the dataset vertices_df = pd.read_csv('./musae_ENGB_target.csv') # drop old ID column, we'll use the new IDs only vertices_df.drop('id', axis=1, inplace=True) # rename columns for Neptune Bulk Loader: # add ~ to the id column, # add data types and cardinality to vertex property columns vertices_df.rename( columns={ 'new_id': '~id', 'days': 'days:Int(single)', 'mature': 'mature:Bool(single)', 'views': 'views:Int(single)', 'partner': 'partner:Bool(single)', }, inplace=True, ) # add vertex label column vertices_df['~label'] = 'user' # save vertices to a file, ignore the index column vertices_df.to_csv('vertices.csv', index=False) # === Edges === # load edges from the CSV file provided in the dataset edges_df = pd.read_csv('./musae_ENGB_edges.csv') # add reverse edges (the original edges represent mutual follows) reverse_edges_df = edges_df[['to', 'from']] reverse_edges_df.rename(columns={'from': 'to', 'to': 'from'}, inplace=True) reverse_edges_df.head() edges_df = pd.concat([edges_df, reverse_edges_df], ignore_index=True) # rename columns according to Neptune Bulk Loader format: # add ~ to 'from' and 'to' column names edges_df.rename(columns={ 'from': '~from', 'to': '~to', }, inplace=True, ) edges_df.head() # add edge label column edges_df['~label'] = 'follows' # add edge IDs edges_df['~id'] = range(len(edges_df)) # save edges to a file, ignore the index column edges_df.to_csv('edges.csv', index=False)MENGIZINKAN NEPTUNE DB MENGAKSES DATA DI S3: PERAN IAM DAN TITIK AKHIR VPC
Setelah mengonversi file, kami akan mengunggahnya ke S3. Untuk melakukannya, pertama-tama kami perlu membuat bucket yang akan berisi file vertices.csv dan edge.csv. Kami juga perlu membuat peran IAM yang memungkinkan akses ke bucket S3 tersebut (dalam kebijakan terlampir) dan memiliki kebijakan kepercayaan yang memungkinkan Neptune untuk mengambilnya (lihat tangkapan layar).

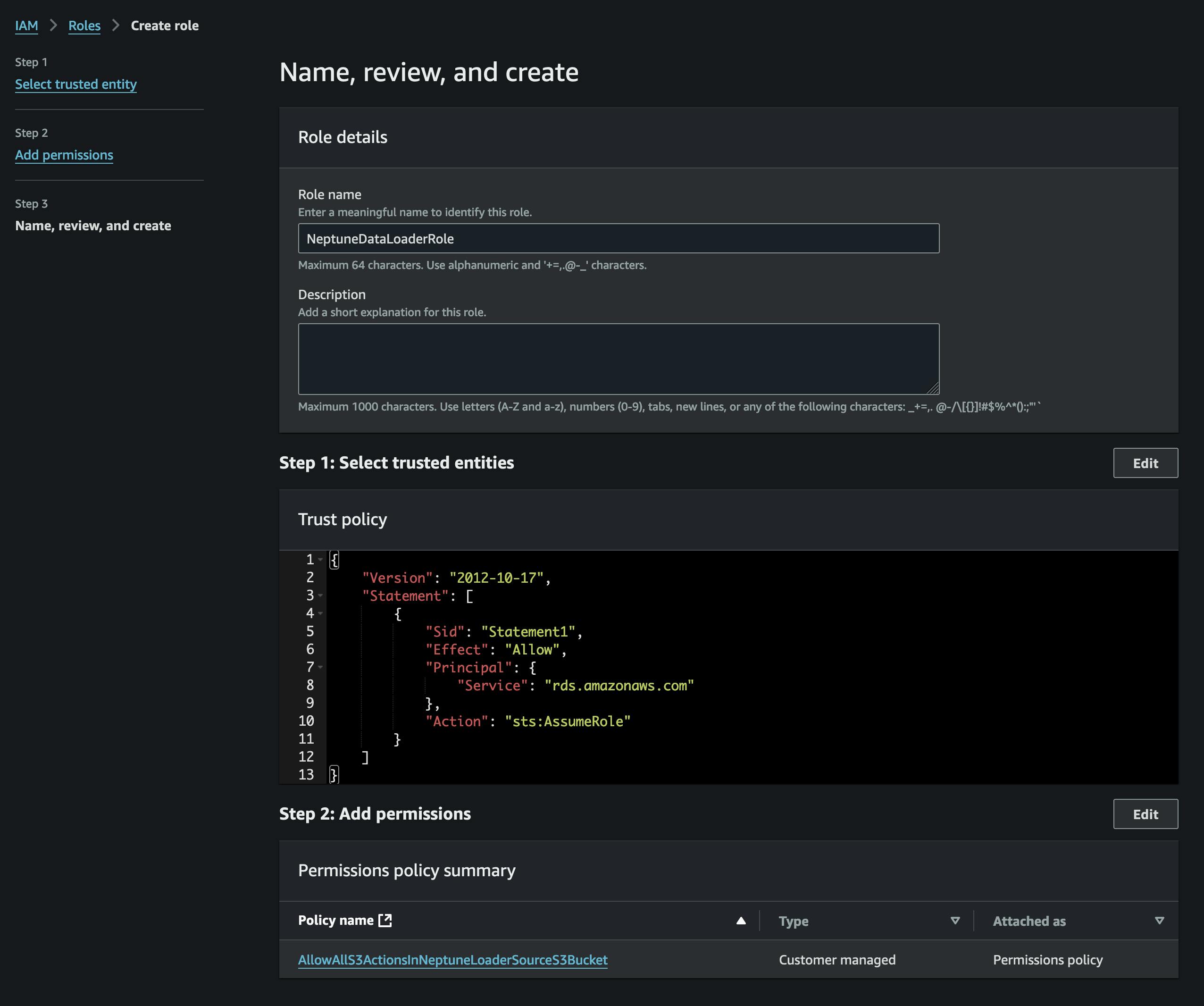
Kami akan menambahkan peran tersebut ke kluster Neptune kami (menggunakan konsol Neptune), lalu kami akan menunggu hingga peran tersebut aktif (atau mem-boot ulang kluster).




Kita juga perlu mengizinkan lalu lintas jaringan dari Neptune ke S3, dan untuk melakukannya kita memerlukan titik akhir Gateway VPC untuk S3 di VPC kita:


MEMUAT DATA
Sekarang kita siap untuk mulai memuat data kita. Untuk melakukannya, kita perlu memanggil API kluster dari dalam VPC dan membuat 2 tugas pemuatan: satu untuk vertices.csv, dan satu lagi untuk sides.csv. Panggilan API identik, hanya kunci objek S3 yang bervariasi. Konfigurasi VPC dan grup keamanan harus mengizinkan lalu lintas dari instans tempat Anda menjalankan curl ke kluster Neptune.
curl -XPOST \ -H 'Content-Type: application/json' \ https://your-neptune-endpoint:8182/loader -d ' { "source" : "s3://bucket-name/vertices.csv", "format" : "csv", "iamRoleArn" : "arn:aws:iam::account-id:role/role-name", "region" : "us-east-1", "failOnError" : "TRUE", "parallelism" : "HIGH", "updateSingleCardinalityProperties" : "FALSE" }'
API loader merespons dengan JSON yang berisi ID pekerjaan (' loadId '):
{ "status" : "200 OK", "payload" : { "loadId" : "your-load-id" } }Anda dapat memeriksa apakah pemuatan telah selesai dengan menggunakan API ini:
curl -XGET https://your-neptune-endpoint:8182/loader/your-load-idIa menjawab dengan ini:
{ "status" : "200 OK", "payload" : { "feedCount" : [ { "LOAD_COMPLETED" : 1 } ], "overallStatus" : { "fullUri" : "s3://bucket-name/vertices.csv", "runNumber" : 1, "retryNumber" : 1, "status" : "LOAD_COMPLETED", "totalTimeSpent" : 8, "startTime" : 1, "totalRecords" : 35630, "totalDuplicates" : 0, "parsingErrors" : 0, "datatypeMismatchErrors" : 0, "insertErrors" : 0 } } Setelah vertices dimuat dari vertices.csv , kita dapat memuat edge menggunakan API yang sama. Untuk melakukannya, kita tinggal mengganti vertices.csv dengan edge.csv dan menjalankan perintah curl pertama lagi.
MEMVERIFIKASI DATA YANG DIMUAT
Saat pekerjaan pemuatan selesai, kita dapat mengakses data yang dimuat dengan mengirimkan kueri Gremlin ke kluster Neptune. Untuk menjalankan kueri ini, kita dapat terhubung ke Neptune dengan konsol Gremlin atau menggunakan Buku Catatan Neptune/Sagemaker. Kita akan menggunakan buku catatan Sagemaker yang dapat dibuat bersama dengan kluster Neptune atau ditambahkan kemudian saat kluster sudah berjalan.
Ini adalah kueri yang mendapatkan jumlah simpul yang kita buat:
%%gremlin gV().count()Anda juga bisa mendapatkan simpul berdasarkan ID dan memverifikasi bahwa propertinya telah dimuat dengan benar dengan:
%%gremlin gV('some-vertex-id').elementMap() 

Setelah memuat tepi, Anda dapat memverifikasi bahwa tepi tersebut berhasil dimuat dengan
%%gremlin gE().count()Dan
%%gremlin gE('0').elementMap()


Ini mengakhiri bagian pemuatan data dari proses ini. Dalam postingan berikutnya, kita akan melihat cara mengekspor data dari Neptune dalam format yang dapat digunakan untuk pelatihan model ML.








