























Ramalan pautan bertujuan untuk meramalkan kemungkinan sambungan masa hadapan atau hilang antara nod dalam rangkaian. Ia digunakan secara meluas dalam pelbagai aplikasi, seperti rangkaian sosial, sistem pengesyoran, dan rangkaian biologi. Kami akan menumpukan pada ramalan pautan dalam rangkaian sosial, dan untuk itu kami akan menggunakan set data yang sama yang digunakan untuk ramalan pautan setempat dengan DGL dalam catatan sebelumnya - Twitch data rangkaian sosial . Set data ini mengandungi graf dengan nodnya mewakili pengguna Twitch dan tepi mewakili persahabatan bersama antara pengguna. Kami akan menggunakannya untuk meramalkan pautan baharu ('mengikut') antara pengguna, berdasarkan pautan sedia ada dan ciri pengguna.
Seperti yang ditunjukkan dalam rajah, ramalan pautan melibatkan berbilang langkah termasuk mengimport, mengeksport dan memproses data, melatih model dan mengoptimumkan hiperparameternya, dan akhirnya menyediakan dan menanyakan titik akhir inferens yang menjana ramalan sebenar.
Dalam siaran ini, kami akan menumpukan pada langkah pertama proses: menyediakan data dan memuatkannya ke dalam gugusan Neptun.
MENUKARKAN DATA KEPADA FORMAT NEPTUNE LOADER
Fail awal dalam set data kelihatan seperti ini:
Bucu (awal):
id,days,mature,views,partner,new_id 73045350,1459,False,9528,False,2299 61573865,1629,True,3615,False,153 ...
Tepi (awal):
from,to 6194,255 6194,980 ...Untuk memuatkan data tersebut ke dalam Neptune, mula-mula kita perlu menukar data ke dalam salah satu format yang disokong. Kami akan menggunakan graf Gremlin, jadi data mestilah dalam fail CSV dengan bucu dan tepi, dan nama lajur dalam fail CSV mesti mengikut corak ini.
Begini rupa data yang ditukar:
Bucu (ditukar):
~id,~label,days:Int(single),mature:Bool(single),partner:Bool(single),views:Int(single) 2299,"user",1459,false,false,9528 153,"user",1629,true,false,3615 ...
Tepi (ditukar):
~from,~to,~label,~id 6194,255,"follows",0 255,6194,"follows",1 ...
Dan ini ialah kod yang menukar fail yang disediakan dengan set data kepada format yang disokong oleh Neptune Loader:
import pandas as pd # === Vertices === # load vertices from the CSV file provided in the dataset vertices_df = pd.read_csv('./musae_ENGB_target.csv') # drop old ID column, we'll use the new IDs only vertices_df.drop('id', axis=1, inplace=True) # rename columns for Neptune Bulk Loader: # add ~ to the id column, # add data types and cardinality to vertex property columns vertices_df.rename( columns={ 'new_id': '~id', 'days': 'days:Int(single)', 'mature': 'mature:Bool(single)', 'views': 'views:Int(single)', 'partner': 'partner:Bool(single)', }, inplace=True, ) # add vertex label column vertices_df['~label'] = 'user' # save vertices to a file, ignore the index column vertices_df.to_csv('vertices.csv', index=False) # === Edges === # load edges from the CSV file provided in the dataset edges_df = pd.read_csv('./musae_ENGB_edges.csv') # add reverse edges (the original edges represent mutual follows) reverse_edges_df = edges_df[['to', 'from']] reverse_edges_df.rename(columns={'from': 'to', 'to': 'from'}, inplace=True) reverse_edges_df.head() edges_df = pd.concat([edges_df, reverse_edges_df], ignore_index=True) # rename columns according to Neptune Bulk Loader format: # add ~ to 'from' and 'to' column names edges_df.rename(columns={ 'from': '~from', 'to': '~to', }, inplace=True, ) edges_df.head() # add edge label column edges_df['~label'] = 'follows' # add edge IDs edges_df['~id'] = range(len(edges_df)) # save edges to a file, ignore the index column edges_df.to_csv('edges.csv', index=False)MEMBENARKAN DATA AKSES DB NEPTUNE DALAM S3: PERANAN IAM DAN ENDPOINT VPC
Selepas menukar fail, kami akan memuat naiknya ke S3. Untuk melakukan itu, mula-mula kita perlu mencipta baldi yang akan mengandungi fail vertices.csv dan edges.csv kami. Kami juga perlu mencipta peranan IAM yang membenarkan akses kepada baldi S3 itu (dalam dasar yang dilampirkan) dan mempunyai dasar amanah yang membolehkan Neptune mengambil alihnya (rujuk tangkapan skrin).

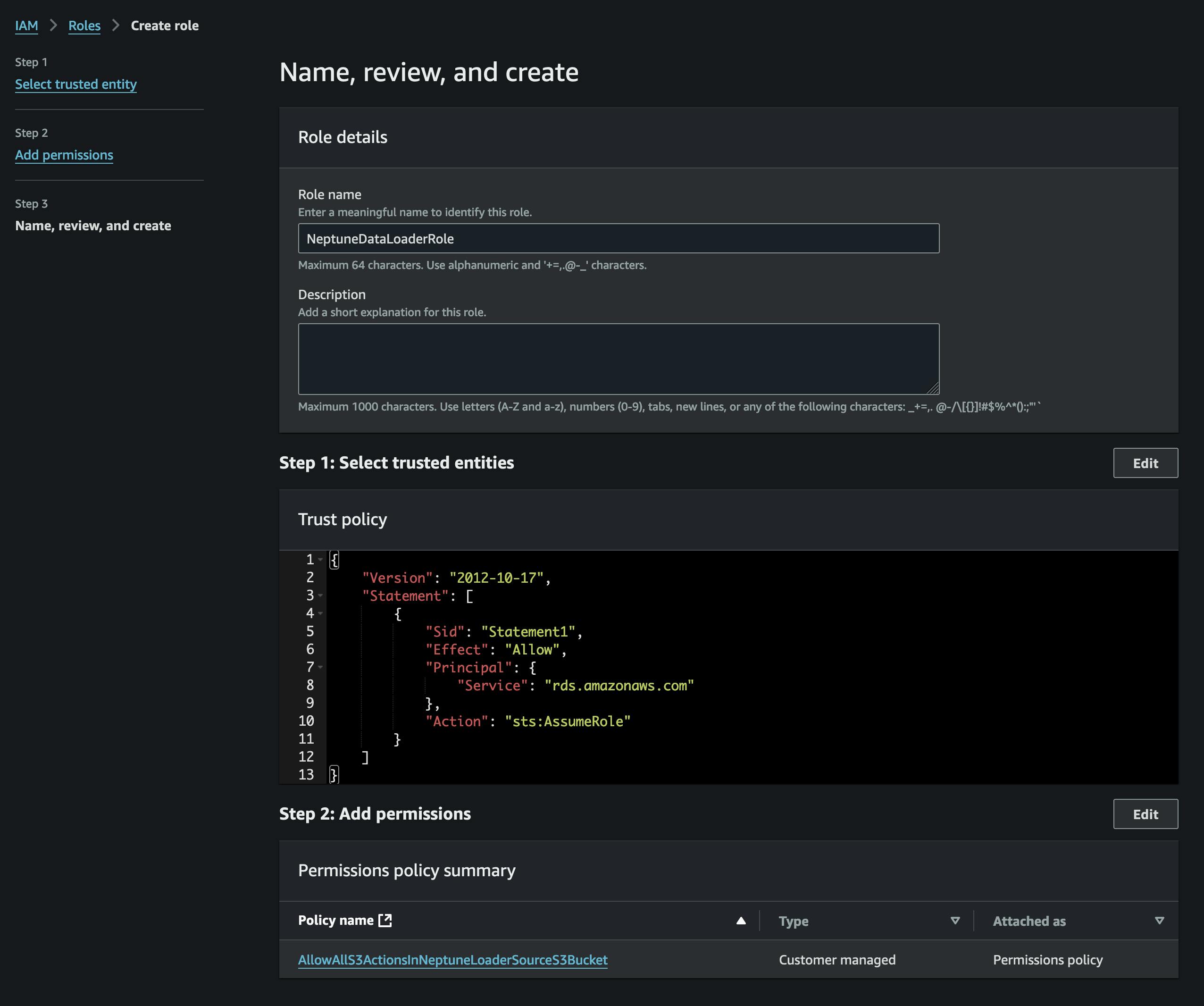
Kami akan menambah peranan pada gugusan Neptune kami (menggunakan konsol Neptune), dan kemudian kami akan menunggu untuk ia menjadi aktif (atau but semula gugusan).




Kami juga perlu membenarkan trafik rangkaian dari Neptune ke S3, dan untuk melakukan itu kami memerlukan titik akhir VPC Gateway untuk S3 dalam VPC kami:


MEMUAT DATA
Kami kini bersedia untuk mula memuatkan data kami. Untuk melakukan itu, kita perlu memanggil API kluster dari dalam VPC ke dan mencipta 2 kerja pemuatan: satu untuk vertices.csv dan satu lagi untuk edges.csv. Panggilan API adalah sama, hanya kunci objek S3 berbeza-beza. Konfigurasi VPC dan kumpulan keselamatan mesti membenarkan trafik dari contoh di mana anda menjalankan curl ke gugusan Neptune.
curl -XPOST \ -H 'Content-Type: application/json' \ https://your-neptune-endpoint:8182/loader -d ' { "source" : "s3://bucket-name/vertices.csv", "format" : "csv", "iamRoleArn" : "arn:aws:iam::account-id:role/role-name", "region" : "us-east-1", "failOnError" : "TRUE", "parallelism" : "HIGH", "updateSingleCardinalityProperties" : "FALSE" }'
API pemuat bertindak balas dengan JSON yang mengandungi id kerja (' loadId '):
{ "status" : "200 OK", "payload" : { "loadId" : "your-load-id" } }Anda boleh menyemak sama ada pemuatan selesai dengan menggunakan API ini:
curl -XGET https://your-neptune-endpoint:8182/loader/your-load-idIa bertindak balas dengan ini:
{ "status" : "200 OK", "payload" : { "feedCount" : [ { "LOAD_COMPLETED" : 1 } ], "overallStatus" : { "fullUri" : "s3://bucket-name/vertices.csv", "runNumber" : 1, "retryNumber" : 1, "status" : "LOAD_COMPLETED", "totalTimeSpent" : 8, "startTime" : 1, "totalRecords" : 35630, "totalDuplicates" : 0, "parsingErrors" : 0, "datatypeMismatchErrors" : 0, "insertErrors" : 0 } } Setelah bucu dimuatkan daripada vertices.csv , kita boleh memuatkan tepi menggunakan API yang sama. Untuk melakukan itu, kami hanya menggantikan vertices.csv dengan edges.csv dan menjalankan perintah curl pertama sekali lagi.
MENGESAHKAN DATA YANG DIMUAT
Apabila kerja pemuatan selesai, kami boleh mengakses data yang dimuatkan dengan menghantar pertanyaan Gremlin kepada gugusan Neptune. Untuk menjalankan pertanyaan ini, kita boleh menyambung ke Neptune dengan konsol Gremlin atau menggunakan Buku Nota Neptune / Sagemaker. Kami akan menggunakan buku nota Sagemaker yang boleh dibuat sama ada dengan gugusan Neptune atau ditambah kemudian apabila gugusan itu sudah berjalan.
Ini ialah pertanyaan yang mendapat bilangan bucu yang kami buat:
%%gremlin gV().count()Anda juga boleh mendapatkan bucu mengikut ID dan mengesahkan bahawa sifatnya telah dimuatkan dengan betul dengan:
%%gremlin gV('some-vertex-id').elementMap() 

Selepas memuatkan tepi, anda boleh mengesahkan bahawa ia berjaya dimuatkan
%%gremlin gE().count()dan
%%gremlin gE('0').elementMap()


Ini menyimpulkan bahagian pemuatan data proses. Dalam siaran seterusnya kita akan melihat mengeksport data daripada Neptune dalam format yang boleh digunakan untuk latihan model ML.




