























Предвиждането на връзка има за цел да предвиди вероятността от бъдеща или липсваща връзка между възлите в мрежата. Той се използва широко в различни приложения, като социални мрежи, системи за препоръки и биологични мрежи. Ще се съсредоточим върху предсказването на връзки в социалните мрежи и за това ще използваме същия набор от данни, който беше използван за предсказване на локални връзки с DGL в предишната публикация - данни за социалната мрежа Twitch . Този набор от данни съдържа графика с възли, представляващи потребители на Twitch, и ръбове, представляващи взаимно приятелство между потребителите. Ще използваме това, за да прогнозираме нови връзки („следвания“) между потребителите въз основа на съществуващи връзки и потребителски функции.
Както е показано на диаграмата, предвиждането на връзката включва множество стъпки, включително импортиране, експортиране и предварителна обработка на данните, обучение на модел и оптимизиране на неговите хиперпараметри и накрая настройка и запитване към крайна точка за извод, която генерира действителни прогнози.
В тази публикация ще се съсредоточим върху първата стъпка от процеса: подготовка на данните и зареждането им в клъстер Neptune.
КОНВЕРТИРАНЕ НА ДАННИТЕ ВЪВ ФОРМАТ ЗА ЗАРЕЖДАНЕ НА NEPTUNE
Първоначалните файлове в набора от данни изглеждат така:
Върхове (първоначално):
id,days,mature,views,partner,new_id 73045350,1459,False,9528,False,2299 61573865,1629,True,3615,False,153 ...
Ръбове (начално):
from,to 6194,255 6194,980 ...За да заредим тези данни в Neptune, първо трябва да конвертираме данните в един от поддържаните формати. Ще използваме графика Gremlin, така че данните трябва да са в CSV файлове с върхове и ръбове, а имената на колоните в CSV файловете трябва да следват този модел .
Ето как изглеждат конвертираните данни:
Върхове (преобразувани):
~id,~label,days:Int(single),mature:Bool(single),partner:Bool(single),views:Int(single) 2299,"user",1459,false,false,9528 153,"user",1629,true,false,3615 ...
Ръбове (преобразувани):
~from,~to,~label,~id 6194,255,"follows",0 255,6194,"follows",1 ...
И това е кодът, който преобразува файловете, предоставени с набора от данни, във формата, който Neptune Loader поддържа:
import pandas as pd # === Vertices === # load vertices from the CSV file provided in the dataset vertices_df = pd.read_csv('./musae_ENGB_target.csv') # drop old ID column, we'll use the new IDs only vertices_df.drop('id', axis=1, inplace=True) # rename columns for Neptune Bulk Loader: # add ~ to the id column, # add data types and cardinality to vertex property columns vertices_df.rename( columns={ 'new_id': '~id', 'days': 'days:Int(single)', 'mature': 'mature:Bool(single)', 'views': 'views:Int(single)', 'partner': 'partner:Bool(single)', }, inplace=True, ) # add vertex label column vertices_df['~label'] = 'user' # save vertices to a file, ignore the index column vertices_df.to_csv('vertices.csv', index=False) # === Edges === # load edges from the CSV file provided in the dataset edges_df = pd.read_csv('./musae_ENGB_edges.csv') # add reverse edges (the original edges represent mutual follows) reverse_edges_df = edges_df[['to', 'from']] reverse_edges_df.rename(columns={'from': 'to', 'to': 'from'}, inplace=True) reverse_edges_df.head() edges_df = pd.concat([edges_df, reverse_edges_df], ignore_index=True) # rename columns according to Neptune Bulk Loader format: # add ~ to 'from' and 'to' column names edges_df.rename(columns={ 'from': '~from', 'to': '~to', }, inplace=True, ) edges_df.head() # add edge label column edges_df['~label'] = 'follows' # add edge IDs edges_df['~id'] = range(len(edges_df)) # save edges to a file, ignore the index column edges_df.to_csv('edges.csv', index=False)РАЗРЕШАВАНЕ НА ДОСТЪП НА NEPTUNE DB ДАННИ В S3: IAM РОЛЯ И VPC КРАЙНА ТОЧКА
След като конвертираме файловете, ще ги качим в S3. За да направим това, първо трябва да създадем контейнер, който ще съдържа нашите файлове vertices.csv и edges.csv. Също така трябва да създадем IAM роля, която позволява достъп до тази S3 кофа (в приложената политика) и има политика за доверие, която позволява на Neptune да я приеме (вижте екранната снимка).

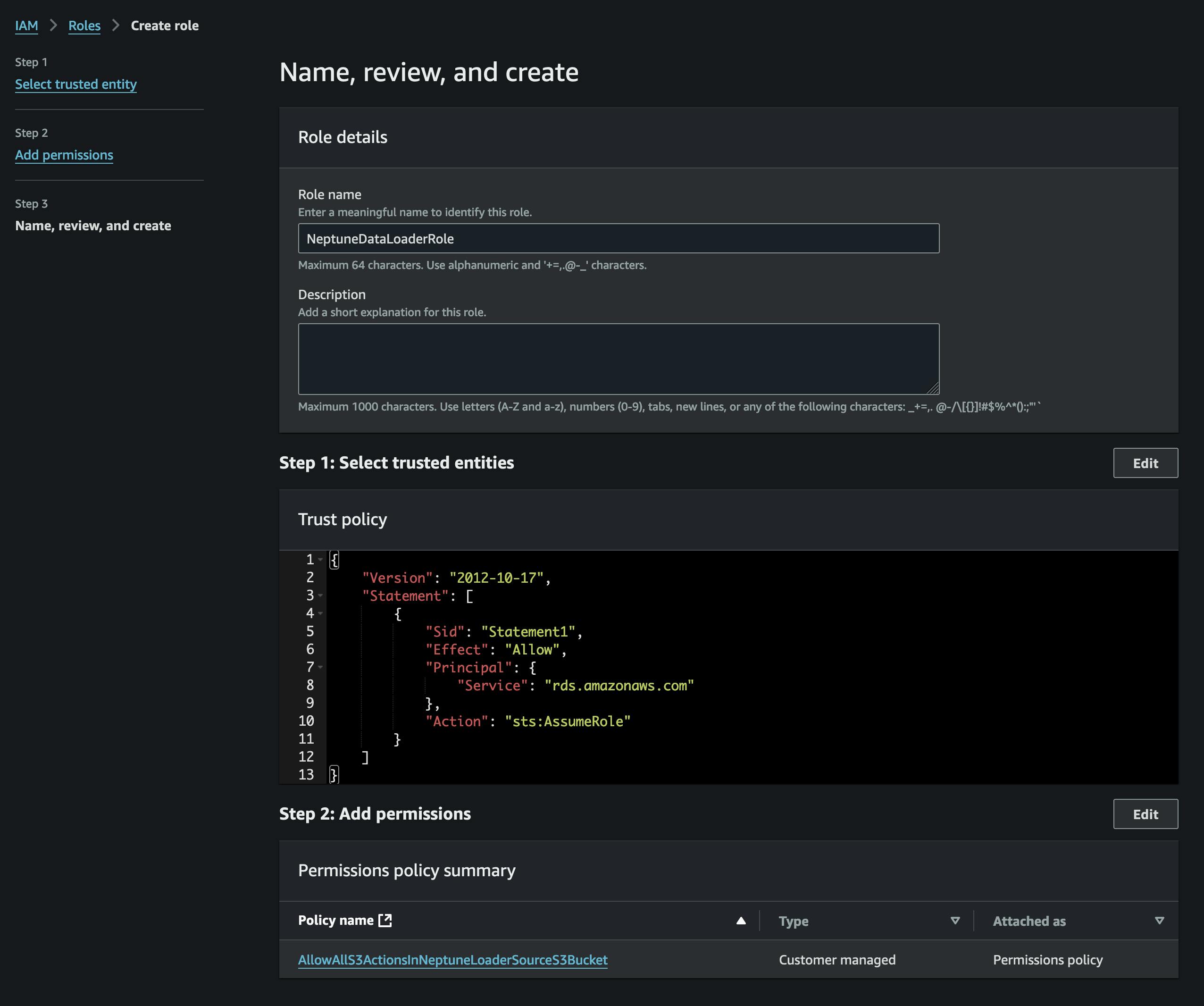
Ще добавим ролята към нашия клъстер Neptune (с помощта на конзолата на Neptune) и след това ще изчакаме да стане активна (или ще рестартираме клъстера).




Също така трябва да разрешим мрежов трафик от Neptune до S3 и за да направим това, се нуждаем от крайна точка на Gateway VPC за S3 в нашия VPC:


ДАННИТЕ СЕ ЗАРЕЖДАТ
Вече сме готови да започнем да зареждаме нашите данни. За да направим това, трябва да извикаме API на клъстера от VPC и да създадем 2 задания за зареждане: едно за vertices.csv и друго за edges.csv. Извикванията на API са идентични, само S3 обектният ключ варира. Конфигурацията на VPC и групите за сигурност трябва да позволяват трафик от екземпляра, където изпълнявате curl към клъстера Neptune.
curl -XPOST \ -H 'Content-Type: application/json' \ https://your-neptune-endpoint:8182/loader -d ' { "source" : "s3://bucket-name/vertices.csv", "format" : "csv", "iamRoleArn" : "arn:aws:iam::account-id:role/role-name", "region" : "us-east-1", "failOnError" : "TRUE", "parallelism" : "HIGH", "updateSingleCardinalityProperties" : "FALSE" }'
API за зареждане отговаря с JSON, който съдържа идентификатора на заданието („ loadId “):
{ "status" : "200 OK", "payload" : { "loadId" : "your-load-id" } }Можете да проверите дали зареждането е завършено, като използвате този API:
curl -XGET https://your-neptune-endpoint:8182/loader/your-load-idОтговаря с това:
{ "status" : "200 OK", "payload" : { "feedCount" : [ { "LOAD_COMPLETED" : 1 } ], "overallStatus" : { "fullUri" : "s3://bucket-name/vertices.csv", "runNumber" : 1, "retryNumber" : 1, "status" : "LOAD_COMPLETED", "totalTimeSpent" : 8, "startTime" : 1, "totalRecords" : 35630, "totalDuplicates" : 0, "parsingErrors" : 0, "datatypeMismatchErrors" : 0, "insertErrors" : 0 } } След като върховете се заредят от vertices.csv , можем да заредим ръбове, използвайки същия API. За да направим това, просто заменяме vertices.csv с edges.csv и изпълняваме отново първата curl команда.
ПРОВЕРКА НА ЗАРЕДЕНИТЕ ДАННИ
Когато задачите за зареждане приключат, можем да получим достъп до заредените данни, като изпратим заявки Gremlin до клъстера Neptune. За да изпълним тези заявки, можем или да се свържем с Neptune с конзола Gremlin, или да използваме Notebook Neptune / Sagemaker. Ще използваме бележник на Sagemaker, който може да бъде създаден заедно с клъстера Neptune или добавен по-късно, когато клъстерът вече работи.
Това е заявката, която получава броя на върховете, които създадохме:
%%gremlin gV().count()Можете също така да получите връх по ID и да проверите дали неговите свойства са заредени правилно с:
%%gremlin gV('some-vertex-id').elementMap() 

След като заредите ръбове, можете да проверите дали са заредени успешно
%%gremlin gE().count()и
%%gremlin gE('0').elementMap()


Това приключва частта от процеса за зареждане на данни. В следващата публикация ще разгледаме експортирането на данни от Neptune във формат, който може да се използва за обучение на ML модели.




