























Linkin ennustaminen pyrkii ennustamaan tulevan tai puuttuvan yhteyden todennäköisyyttä verkon solmujen välillä. Sitä käytetään laajasti erilaisissa sovelluksissa, kuten sosiaalisissa verkostoissa, suositusjärjestelmissä ja biologisissa verkostoissa. Keskitymme linkkien ennustamiseen sosiaalisissa verkostoissa ja käytämme sitä varten samaa tietojoukkoa, jota käytettiin paikallisten linkkien ennustamiseen DGL:n kanssa edellisessä Twitchin jälkeisessä sosiaalisen verkoston tiedoissa . Tämä tietojoukko sisältää kaavion, jonka solmut edustavat Twitch-käyttäjiä ja reunat, jotka edustavat käyttäjien keskinäistä ystävyyttä. Käytämme sitä ennustaaksemme uusia linkkejä ("seuraa") käyttäjien välillä olemassa olevien linkkien ja käyttäjän ominaisuuksien perusteella.
Kuten kaaviossa näkyy, linkin ennustamiseen kuuluu useita vaiheita, mukaan lukien tietojen tuonti, vienti ja esikäsittely, mallin koulutus ja sen hyperparametrien optimointi sekä lopuksi todellisia ennusteita luovan päättelypäätepisteen määrittäminen ja kysely.
Tässä viestissä keskitymme prosessin ensimmäiseen vaiheeseen: tietojen valmisteluun ja sen lataamiseen Neptune-klusteriin.
TIETOJEN MUUNTAMINEN NEPTUNE LOADER -muotoon
Tietojoukon alkuperäiset tiedostot näyttävät tältä:
Vertices (alkuperäinen):
id,days,mature,views,partner,new_id 73045350,1459,False,9528,False,2299 61573865,1629,True,3615,False,153 ...
Reunat (alkuperäinen):
from,to 6194,255 6194,980 ...Tietojen lataamiseksi Neptunukseen meidän on ensin muutettava tiedot johonkin tuettuun muotoon. Käytämme Gremlin-graafia, joten tietojen on oltava CSV-tiedostoissa, joissa on kärjet ja reunat, ja CSV-tiedostojen sarakkeiden nimien on noudatettava tätä mallia .
Muunnetut tiedot näyttävät tältä:
Vertices (muunnettu):
~id,~label,days:Int(single),mature:Bool(single),partner:Bool(single),views:Int(single) 2299,"user",1459,false,false,9528 153,"user",1629,true,false,3615 ...
Reunat (muunnettu):
~from,~to,~label,~id 6194,255,"follows",0 255,6194,"follows",1 ...
Ja tämä on koodi, joka muuntaa tietojoukon mukana toimitetut tiedostot muotoon, jota Neptune Loader tukee:
import pandas as pd # === Vertices === # load vertices from the CSV file provided in the dataset vertices_df = pd.read_csv('./musae_ENGB_target.csv') # drop old ID column, we'll use the new IDs only vertices_df.drop('id', axis=1, inplace=True) # rename columns for Neptune Bulk Loader: # add ~ to the id column, # add data types and cardinality to vertex property columns vertices_df.rename( columns={ 'new_id': '~id', 'days': 'days:Int(single)', 'mature': 'mature:Bool(single)', 'views': 'views:Int(single)', 'partner': 'partner:Bool(single)', }, inplace=True, ) # add vertex label column vertices_df['~label'] = 'user' # save vertices to a file, ignore the index column vertices_df.to_csv('vertices.csv', index=False) # === Edges === # load edges from the CSV file provided in the dataset edges_df = pd.read_csv('./musae_ENGB_edges.csv') # add reverse edges (the original edges represent mutual follows) reverse_edges_df = edges_df[['to', 'from']] reverse_edges_df.rename(columns={'from': 'to', 'to': 'from'}, inplace=True) reverse_edges_df.head() edges_df = pd.concat([edges_df, reverse_edges_df], ignore_index=True) # rename columns according to Neptune Bulk Loader format: # add ~ to 'from' and 'to' column names edges_df.rename(columns={ 'from': '~from', 'to': '~to', }, inplace=True, ) edges_df.head() # add edge label column edges_df['~label'] = 'follows' # add edge IDs edges_df['~id'] = range(len(edges_df)) # save edges to a file, ignore the index column edges_df.to_csv('edges.csv', index=False)NEPTUNE DB -KÄYTTÖTIETOJEN SALLISTAMINEN S3:ssa: IAM-ROLI JA VPC-PÄÄTEPISTE
Kun tiedostot on muunnettu, lataamme ne S3:een. Tätä varten meidän on ensin luotava ämpäri, joka sisältää vertices.csv- ja edges.csv-tiedostomme. Meidän on myös luotava IAM-rooli, joka sallii pääsyn kyseiseen S3-säilöyn (liitteenä olevassa käytännössä) ja jolla on luottamuskäytäntö, joka sallii Neptunen olettaa sen (katso kuvakaappaus).

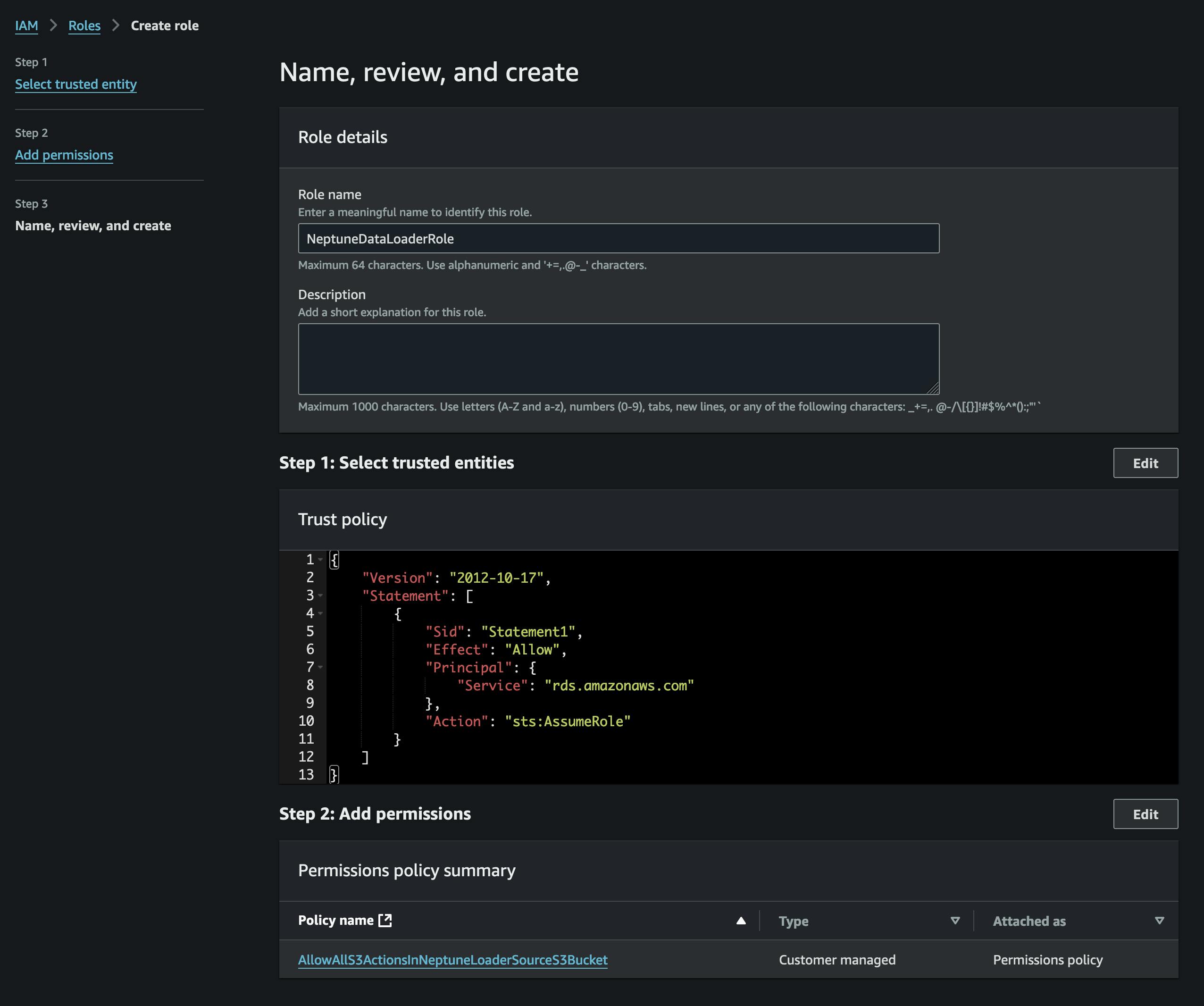
Lisäämme roolin Neptune-klusteriimme (käyttäen Neptune-konsolia) ja sitten odotamme sen aktivoitumista (tai käynnistämme klusterin uudelleen).




Meidän on myös sallittava verkkoliikenne Neptunuksesta S3:een, ja tätä varten tarvitsemme VPC:ssämme Gateway VPC -päätepisteen S3:lle:


TIETOJEN LATAUS
Olemme nyt valmiita aloittamaan tietojemme lataamisen. Tätä varten meidän on kutsuttava klusterin API VPC:n sisältä ja luotava 2 lataustyötä: yksi vertices.csv:lle ja toinen edges.csv:lle. API-kutsut ovat identtisiä, vain S3-objektiavain vaihtelee. VPC-kokoonpanon ja suojausryhmien on sallittava liikenne instanssista, jossa suoritat curl Neptune-klusteriin.
curl -XPOST \ -H 'Content-Type: application/json' \ https://your-neptune-endpoint:8182/loader -d ' { "source" : "s3://bucket-name/vertices.csv", "format" : "csv", "iamRoleArn" : "arn:aws:iam::account-id:role/role-name", "region" : "us-east-1", "failOnError" : "TRUE", "parallelism" : "HIGH", "updateSingleCardinalityProperties" : "FALSE" }'
Lataussovellusliittymä vastaa JSON:lla, joka sisältää työtunnuksen (' loadId '):
{ "status" : "200 OK", "payload" : { "loadId" : "your-load-id" } }Voit tarkistaa, onko lataus valmis käyttämällä tätä API:
curl -XGET https://your-neptune-endpoint:8182/loader/your-load-idSe vastaa tällä:
{ "status" : "200 OK", "payload" : { "feedCount" : [ { "LOAD_COMPLETED" : 1 } ], "overallStatus" : { "fullUri" : "s3://bucket-name/vertices.csv", "runNumber" : 1, "retryNumber" : 1, "status" : "LOAD_COMPLETED", "totalTimeSpent" : 8, "startTime" : 1, "totalRecords" : 35630, "totalDuplicates" : 0, "parsingErrors" : 0, "datatypeMismatchErrors" : 0, "insertErrors" : 0 } } Kun kärjet on ladattu osoitteesta vertices.csv , voimme ladata reunat käyttämällä samaa API:ta. Voit tehdä tämän korvaamalla vertices.csv:n osoitteella edges.csv ja suorittamalla ensimmäisen curl -komennon uudelleen.
LADATTUJEN TIETOJEN TARKISTAMINEN
Kun lataustyöt on suoritettu, voimme käyttää ladattuja tietoja lähettämällä Gremlin-kyselyitä Neptune-klusteriin. Näiden kyselyjen suorittamiseksi voimme joko muodostaa yhteyden Neptuneen Gremlin-konsolilla tai käyttää Neptune/Sagemaker-muistikirjaa. Käytämme Sagemaker-muistikirjaa, joka voidaan joko luoda yhdessä Neptune-klusterin kanssa tai lisätä myöhemmin, kun klusteri on jo käynnissä.
Tämä on kysely, joka saa luomiemme pisteiden lukumäärän:
%%gremlin gV().count()Voit myös saada kärkipisteen tunnuksella ja varmistaa, että sen ominaisuudet on ladattu oikein:
%%gremlin gV('some-vertex-id').elementMap() 

Reunojen lataamisen jälkeen voit varmistaa, että ne on ladattu onnistuneesti
%%gremlin gE().count()ja
%%gremlin gE('0').elementMap()


Tämä päättää prosessin tietojen latausosan. Seuraavassa postauksessa tarkastellaan tietojen vientiä Neptunuksesta muodossa, jota voidaan käyttää ML-mallin harjoittamiseen.








