























Predviđanje veze ima za cilj da predvidi vjerovatnoću buduće ili nedostajuće veze između čvorova u mreži. Široko se koristi u raznim aplikacijama, kao što su društvene mreže, sistemi preporuka i biološke mreže. Fokusiraćemo se na predviđanje veza u društvenim mrežama, a za to ćemo koristiti isti skup podataka koji je korišten za predviđanje lokalnih veza s DGL-om u prethodnim podacima o društvenim mrežama nakon Twitcha . Ovaj skup podataka sadrži graf sa svojim čvorovima koji predstavljaju Twitch korisnike i ivicama koje predstavljaju međusobno prijateljstvo između korisnika. To ćemo koristiti da predvidimo nove veze ('praćenja') između korisnika, na osnovu postojećih veza i korisničkih karakteristika.
Kao što je prikazano na dijagramu, predviđanje veze uključuje više koraka uključujući uvoz, izvoz i prethodnu obradu podataka, obuku modela i optimizaciju njegovih hiperparametara, i konačno postavljanje i ispitivanje krajnje tačke zaključivanja koja generiše stvarna predviđanja.
U ovom postu ćemo se fokusirati na prvi korak procesa: pripremu podataka i njihovo učitavanje u klaster Neptuna.
KONVERZIRANJE PODATAKA U NEPTUNE LOADER FORMAT
Početne datoteke u skupu podataka izgledaju ovako:
Vrhovi (početni):
id,days,mature,views,partner,new_id 73045350,1459,False,9528,False,2299 61573865,1629,True,3615,False,153 ...
Ivice (početne):
from,to 6194,255 6194,980 ...Da bismo te podatke učitali u Neptun, prvo moramo konvertirati podatke u jedan od podržanih formata. Koristićemo Gremlin graf, tako da podaci moraju biti u CSV datotekama sa vrhovima i ivicama, a nazivi kolona u CSV datotekama moraju pratiti ovaj obrazac .
Evo kako izgledaju konvertirani podaci:
Vrhovi (pretvoreni):
~id,~label,days:Int(single),mature:Bool(single),partner:Bool(single),views:Int(single) 2299,"user",1459,false,false,9528 153,"user",1629,true,false,3615 ...
Ivice (pretvorene):
~from,~to,~label,~id 6194,255,"follows",0 255,6194,"follows",1 ...
A ovo je kod koji konvertuje datoteke isporučene sa skupom podataka u format koji Neptune Loader podržava:
import pandas as pd # === Vertices === # load vertices from the CSV file provided in the dataset vertices_df = pd.read_csv('./musae_ENGB_target.csv') # drop old ID column, we'll use the new IDs only vertices_df.drop('id', axis=1, inplace=True) # rename columns for Neptune Bulk Loader: # add ~ to the id column, # add data types and cardinality to vertex property columns vertices_df.rename( columns={ 'new_id': '~id', 'days': 'days:Int(single)', 'mature': 'mature:Bool(single)', 'views': 'views:Int(single)', 'partner': 'partner:Bool(single)', }, inplace=True, ) # add vertex label column vertices_df['~label'] = 'user' # save vertices to a file, ignore the index column vertices_df.to_csv('vertices.csv', index=False) # === Edges === # load edges from the CSV file provided in the dataset edges_df = pd.read_csv('./musae_ENGB_edges.csv') # add reverse edges (the original edges represent mutual follows) reverse_edges_df = edges_df[['to', 'from']] reverse_edges_df.rename(columns={'from': 'to', 'to': 'from'}, inplace=True) reverse_edges_df.head() edges_df = pd.concat([edges_df, reverse_edges_df], ignore_index=True) # rename columns according to Neptune Bulk Loader format: # add ~ to 'from' and 'to' column names edges_df.rename(columns={ 'from': '~from', 'to': '~to', }, inplace=True, ) edges_df.head() # add edge label column edges_df['~label'] = 'follows' # add edge IDs edges_df['~id'] = range(len(edges_df)) # save edges to a file, ignore the index column edges_df.to_csv('edges.csv', index=False)DOZVOLJAVANJE NEPTUNE DB PRISTUP PODACI U S3: IAM ULOGA I VPC KRAJNJA TOČKA
Nakon konvertovanja fajlova učitaćemo ih na S3. Da bismo to uradili, prvo moramo da kreiramo kantu koja će sadržati naše vertices.csv i edges.csv datoteke. Takođe moramo da kreiramo IAM ulogu koja dozvoljava pristup tom S3 segmentu (u priloženoj politici) i ima politiku poverenja koja dozvoljava Neptunu da to preuzme (pogledajte snimak ekrana).

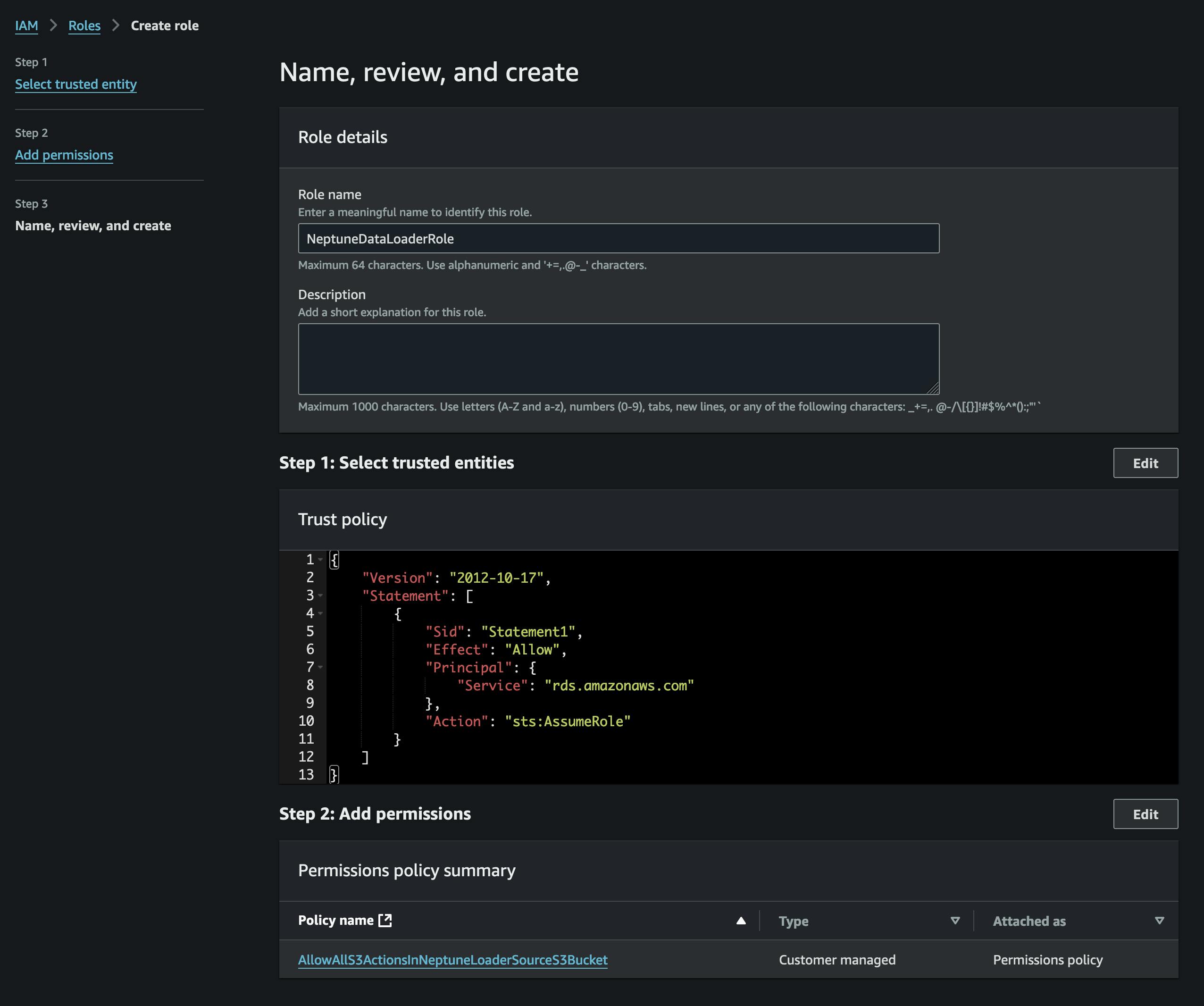
Ulogu ćemo dodati našem Neptune klasteru (pomoću Neptune konzole), a zatim ćemo pričekati da postane aktivna (ili ponovo pokrenuti klaster).




Takođe moramo dozvoliti mrežni saobraćaj od Neptuna do S3, a da bismo to uradili, potrebna nam je krajnja tačka Gateway VPC za S3 u našem VPC:


LOADING DATA
Sada smo spremni za početak učitavanja naših podataka. Da bismo to učinili, moramo pozvati API klastera iz VPC-a i kreirati 2 posla učitavanja: jedan za vertices.csv, a drugi za edges.csv. API pozivi su identični, samo se ključ S3 objekta razlikuje. VPC konfiguracija i sigurnosne grupe moraju dozvoliti promet od instance gdje pokrećete curl do Neptune klastera.
curl -XPOST \ -H 'Content-Type: application/json' \ https://your-neptune-endpoint:8182/loader -d ' { "source" : "s3://bucket-name/vertices.csv", "format" : "csv", "iamRoleArn" : "arn:aws:iam::account-id:role/role-name", "region" : "us-east-1", "failOnError" : "TRUE", "parallelism" : "HIGH", "updateSingleCardinalityProperties" : "FALSE" }'
API za učitavanje odgovara JSON-om koji sadrži ID posla (' loadId '):
{ "status" : "200 OK", "payload" : { "loadId" : "your-load-id" } }Možete provjeriti da li je učitavanje završeno koristeći ovaj API:
curl -XGET https://your-neptune-endpoint:8182/loader/your-load-idReaguje sa ovim:
{ "status" : "200 OK", "payload" : { "feedCount" : [ { "LOAD_COMPLETED" : 1 } ], "overallStatus" : { "fullUri" : "s3://bucket-name/vertices.csv", "runNumber" : 1, "retryNumber" : 1, "status" : "LOAD_COMPLETED", "totalTimeSpent" : 8, "startTime" : 1, "totalRecords" : 35630, "totalDuplicates" : 0, "parsingErrors" : 0, "datatypeMismatchErrors" : 0, "insertErrors" : 0 } } Kada se vrhovi učitaju iz vertices.csv , možemo učitati ivice koristeći isti API. Da bismo to uradili, samo zamenimo vertices.csv sa edges.csv i ponovo pokrenemo prvu naredbu curl .
PROVJERA UČITANIH PODATAKA
Kada su poslovi učitavanja završeni, možemo pristupiti učitanim podacima slanjem Gremlin upita Neptune klasteru. Da bismo pokrenuli ove upite, možemo se ili povezati na Neptune preko Gremlin konzole ili koristiti Neptune / Sagemaker Notebook. Koristićemo Sagemaker notebook koji se može kreirati zajedno sa klasterom Neptun ili dodati kasnije kada klaster već radi.
Ovo je upit koji dobiva broj vrhova koje smo kreirali:
%%gremlin gV().count()Također možete dobiti vrh po ID-u i provjeriti da li su njegova svojstva ispravno učitana sa:
%%gremlin gV('some-vertex-id').elementMap() 

Nakon učitavanja rubova, možete provjeriti jesu li uspješno učitane
%%gremlin gE().count()i
%%gremlin gE('0').elementMap()


Ovim se završava dio procesa učitavanja podataka. U sljedećem postu ćemo pogledati izvoz podataka iz Neptuna u formatu koji se može koristiti za obuku ML modela.




