























La previsione dei link mira a prevedere la probabilità di una connessione futura o mancante tra i nodi di una rete. È ampiamente utilizzata in varie applicazioni, come social network, sistemi di raccomandazione e reti biologiche. Ci concentreremo sulla previsione dei link nei social network e per questo useremo lo stesso set di dati che è stato utilizzato per la previsione dei link locali con DGL nel post precedente: dati del social network di Twitch . Questo set di dati contiene un grafico con i suoi nodi che rappresentano gli utenti di Twitch e gli edge che rappresentano l'amicizia reciproca tra gli utenti. Lo useremo per prevedere nuovi link ("follow") tra gli utenti, in base ai link esistenti e alle caratteristiche degli utenti.
Come mostrato nel diagramma, la previsione dei collegamenti comporta più fasi, tra cui l'importazione, l'esportazione e la preelaborazione dei dati, l'addestramento di un modello e l'ottimizzazione dei suoi iperparametri e, infine, l'impostazione e l'interrogazione di un endpoint di inferenza che genera previsioni effettive.
In questo post ci concentreremo sul primo passaggio del processo: la preparazione dei dati e il loro caricamento in un ammasso di Nettuno.
CONVERSIONE DEI DATI NEL FORMATO NEPTUNE LOADER
I file iniziali nel set di dati si presentano in questo modo:
Vertici (iniziali):
id,days,mature,views,partner,new_id 73045350,1459,False,9528,False,2299 61573865,1629,True,3615,False,153 ...
Bordi (iniziali):
from,to 6194,255 6194,980 ...Per caricare quei dati in Neptune, dobbiamo prima convertirli in uno dei formati supportati. Useremo un grafico Gremlin, quindi i dati devono essere in file CSV con vertici e spigoli, e i nomi delle colonne nei file CSV devono seguire questo schema .
Ecco come appaiono i dati convertiti:
Vertici (convertiti):
~id,~label,days:Int(single),mature:Bool(single),partner:Bool(single),views:Int(single) 2299,"user",1459,false,false,9528 153,"user",1629,true,false,3615 ...
Bordi (convertiti):
~from,~to,~label,~id 6194,255,"follows",0 255,6194,"follows",1 ...
Questo è il codice che converte i file forniti con il set di dati nel formato supportato da Neptune Loader:
import pandas as pd # === Vertices === # load vertices from the CSV file provided in the dataset vertices_df = pd.read_csv('./musae_ENGB_target.csv') # drop old ID column, we'll use the new IDs only vertices_df.drop('id', axis=1, inplace=True) # rename columns for Neptune Bulk Loader: # add ~ to the id column, # add data types and cardinality to vertex property columns vertices_df.rename( columns={ 'new_id': '~id', 'days': 'days:Int(single)', 'mature': 'mature:Bool(single)', 'views': 'views:Int(single)', 'partner': 'partner:Bool(single)', }, inplace=True, ) # add vertex label column vertices_df['~label'] = 'user' # save vertices to a file, ignore the index column vertices_df.to_csv('vertices.csv', index=False) # === Edges === # load edges from the CSV file provided in the dataset edges_df = pd.read_csv('./musae_ENGB_edges.csv') # add reverse edges (the original edges represent mutual follows) reverse_edges_df = edges_df[['to', 'from']] reverse_edges_df.rename(columns={'from': 'to', 'to': 'from'}, inplace=True) reverse_edges_df.head() edges_df = pd.concat([edges_df, reverse_edges_df], ignore_index=True) # rename columns according to Neptune Bulk Loader format: # add ~ to 'from' and 'to' column names edges_df.rename(columns={ 'from': '~from', 'to': '~to', }, inplace=True, ) edges_df.head() # add edge label column edges_df['~label'] = 'follows' # add edge IDs edges_df['~id'] = range(len(edges_df)) # save edges to a file, ignore the index column edges_df.to_csv('edges.csv', index=False)CONSENTIRE AL DB NEPTUNE DI ACCEDERE AI DATI IN S3: RUOLO IAM ED ENDPOINT VPC
Dopo aver convertito i file, li caricheremo su S3. Per farlo, dobbiamo prima creare un bucket che conterrà i nostri file vertices.csv e edges.csv. Dobbiamo anche creare un ruolo IAM che consenta l'accesso a quel bucket S3 (nella policy allegata) e che abbia una policy di attendibilità che consenta a Neptune di assumerlo (fare riferimento allo screenshot).

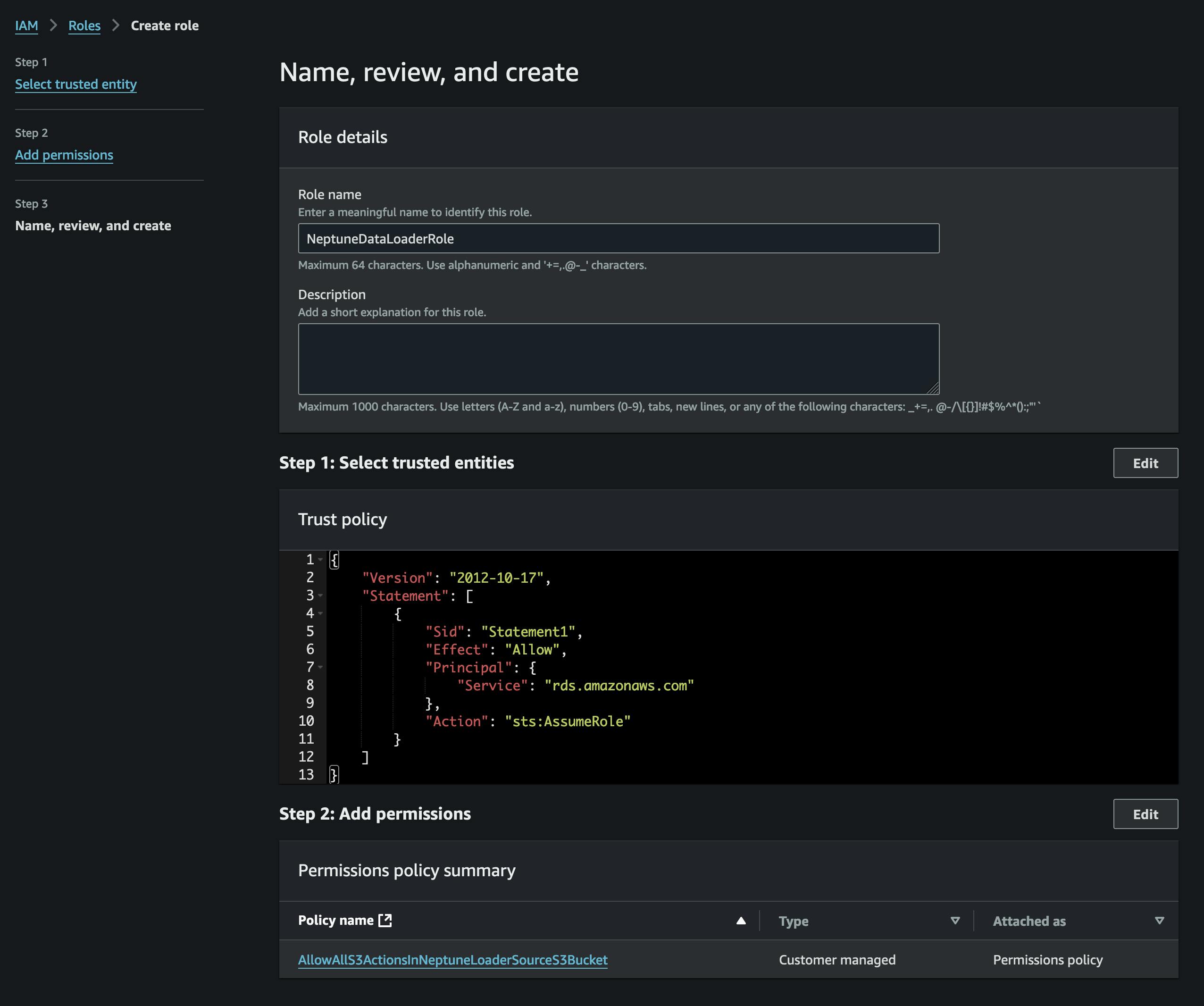
Aggiungeremo il ruolo al nostro cluster Neptune (utilizzando la console Neptune) e poi attenderemo che diventi attivo (o riavvieremo il cluster).




Dobbiamo anche consentire il traffico di rete da Nettuno a S3 e per farlo abbiamo bisogno di un endpoint Gateway VPC per S3 nella nostra VPC:


CARICAMENTO DATI
Ora siamo pronti per iniziare a caricare i nostri dati. Per farlo, dobbiamo chiamare l'API del cluster dall'interno della VPC e creare 2 job di caricamento: uno per vertices.csv e un altro per edges.csv. Le chiamate API sono identiche, solo la chiave dell'oggetto S3 varia. La configurazione della VPC e i gruppi di sicurezza devono consentire il traffico dall'istanza in cui esegui curl al cluster Neptune.
curl -XPOST \ -H 'Content-Type: application/json' \ https://your-neptune-endpoint:8182/loader -d ' { "source" : "s3://bucket-name/vertices.csv", "format" : "csv", "iamRoleArn" : "arn:aws:iam::account-id:role/role-name", "region" : "us-east-1", "failOnError" : "TRUE", "parallelism" : "HIGH", "updateSingleCardinalityProperties" : "FALSE" }'
L'API del caricatore risponde con un JSON che contiene l'ID del lavoro (' loadId '):
{ "status" : "200 OK", "payload" : { "loadId" : "your-load-id" } }Puoi verificare se il caricamento è completato utilizzando questa API:
curl -XGET https://your-neptune-endpoint:8182/loader/your-load-idRisponde così:
{ "status" : "200 OK", "payload" : { "feedCount" : [ { "LOAD_COMPLETED" : 1 } ], "overallStatus" : { "fullUri" : "s3://bucket-name/vertices.csv", "runNumber" : 1, "retryNumber" : 1, "status" : "LOAD_COMPLETED", "totalTimeSpent" : 8, "startTime" : 1, "totalRecords" : 35630, "totalDuplicates" : 0, "parsingErrors" : 0, "datatypeMismatchErrors" : 0, "insertErrors" : 0 } } Una volta caricati i vertici da vertices.csv , possiamo caricare gli spigoli usando la stessa API. Per farlo, sostituiamo semplicemente vertices.csv con edges.csv ed eseguiamo di nuovo il primo comando curl .
VERIFICA DEI DATI CARICATI
Una volta completati i lavori di caricamento, possiamo accedere ai dati caricati inviando query Gremlin al cluster Neptune. Per eseguire queste query, possiamo connetterci a Neptune con una console Gremlin o utilizzare un notebook Neptune/Sagemaker. Utilizzeremo un notebook Sagemaker che può essere creato insieme al cluster Neptune o aggiunto in seguito quando il cluster è già in esecuzione.
Questa è la query che ottiene il numero di vertici che abbiamo creato:
%%gremlin gV().count()È anche possibile ottenere un vertice tramite ID e verificare che le sue proprietà siano state caricate correttamente con:
%%gremlin gV('some-vertex-id').elementMap() 

Dopo aver caricato i bordi, puoi verificare che siano stati caricati correttamente con
%%gremlin gE().count()E
%%gremlin gE('0').elementMap()


Questo conclude la parte di caricamento dei dati del processo. Nel prossimo post esamineremo l'esportazione dei dati da Neptune in un formato che può essere utilizzato per l'addestramento del modello ML.








