
























Introduction
Dans le blog précédent , je vous ai montré comment créer un pipeline CI à l'aide des extensions CLI Databricks et de GitLab. Dans cet article, je vais vous montrer comment atteindre le même objectif avec le dernier framework de déploiement Databricks recommandé, Databricks Asset Bundles . DAB est activement soutenu et développé par l'équipe Databricks en tant que nouvel outil permettant de rationaliser le développement de projets complexes de données, d'analyse et de ML pour la plateforme Databricks.
Je vais ignorer l'introduction générale du DAB et de ses fonctionnalités et vous renvoyer à la documentation Databricks. Ici, je vais me concentrer sur la façon de migrer notre projet dbx du blog précédent vers DAB. En cours de route, j'expliquerai certains concepts et fonctionnalités qui peuvent vous aider à mieux comprendre chaque étape.
Modèle de développement utilisant l'interface graphique Databricks
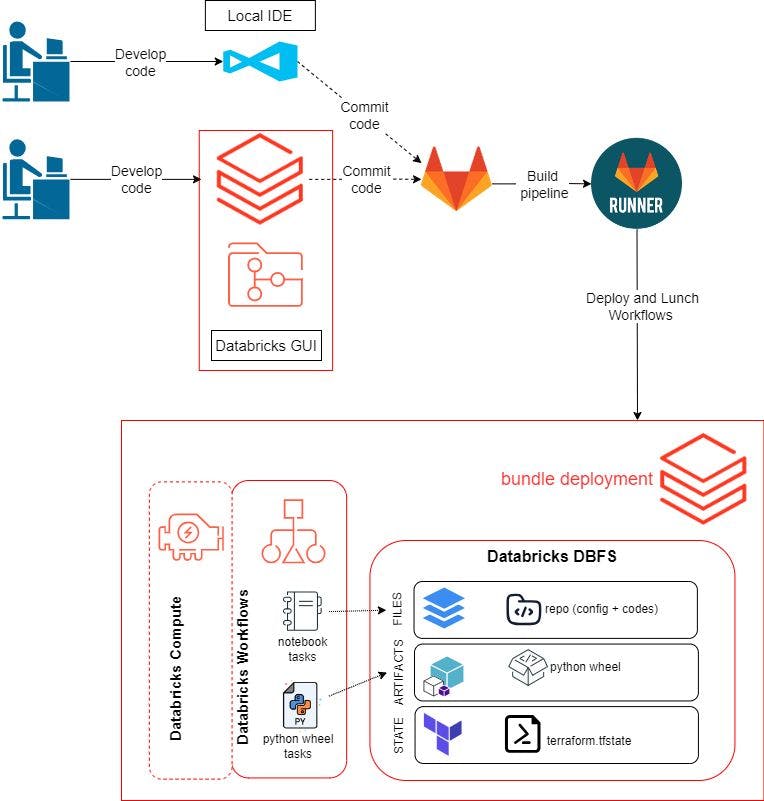
Dans l'article précédent, nous avons utilisé l'interface graphique Databricks pour développer et tester notre code et nos flux de travail. Pour cet article de blog, nous souhaitons également pouvoir utiliser notre environnement local pour développer notre code. Le flux de travail sera le suivant :
Créez un référentiel distant et clonez-le dans notre environnement local et notre espace de travail Databricks. Nous utilisons GitLab ici.
Développez la logique du programme et testez-la dans l'interface graphique Databricks ou sur notre IDE local. Cela inclut des scripts Python pour créer un package Python Wheel, des scripts pour tester la qualité des données à l'aide de pytest et un bloc-notes pour exécuter le pytest.
Poussez le code vers GitLab. Le
git pushdéclenchera un GitLab Runner pour créer, déployer et lancer des ressources sur Databricks à l'aide de Databricks Asset Bundles.Mise en place de vos environnements de développement
CLI Databricks
Tout d’abord, nous devons installer Databricks CLI version 0.205 ou supérieure sur votre ordinateur local. Pour vérifier votre version installée de la CLI Databricks, exécutez la commande
databricks -v. Pour installer Databricks CLI version 0,205 ou supérieure, consultez Installer ou mettre à jour Databricks CLI .Authentification
Databricks prend en charge diverses méthodes d'authentification entre la CLI Databricks sur notre machine de développement et votre espace de travail Databricks. Pour ce didacticiel, nous utilisons l'authentification par jeton d'accès personnel Databricks. Il se compose de deux étapes :
- Créez un jeton d'accès personnel sur notre espace de travail Databricks.
- Créez un profil de configuration Databricks sur notre machine locale.
Pour générer un jeton Databricks dans votre espace de travail Databricks, accédez à Paramètres utilisateur → Développeur → Jetons d'accès → Gérer → Générer un nouveau jeton.
Pour créer un profil de configuration, créez le fichier
~/.databrickscfgdans votre dossier racine avec le contenu suivant :

[asset-bundle-tutorial] host = https://xxxxxxxxxxx.cloud.databricks.com token = xxxxxxx Ici, le asset-bundle-tutorial est notre nom de profil, l'hôte est l'adresse de notre espace de travail et le jeton est le jeton d'accès personnel que nous venons de créer.
Vous pouvez créer ce fichier à l'aide de la CLI Databricks en exécutant databricks configure --profile asset-bundle-tutorial dans votre terminal. La commande vous demandera l' hôte Databricks et le jeton d'accès personnel . Si vous ne spécifiez pas l'indicateur --profile , le nom du profil sera défini sur DEFAULT .
Intégration Git (Databricks)
Dans un premier temps, nous configurons les informations d'identification Git et connectons un dépôt distant à Databricks . Ensuite, nous créons un référentiel distant et le clonons sur notre référentiel Databricks , ainsi que sur notre machine locale. Enfin, nous devons configurer l'authentification entre la CLI Databricks sur le coureur Gitlab et notre espace de travail Databricks. Pour ce faire, nous devons ajouter deux variables d'environnement, DATABRICKS_HOST et DATABRICKS_TOKEN à nos configurations de pipeline Gitlab CI/CD. Pour cela, ouvrez votre dépôt dans Gitlab, allez dans Paramètres → CI/CD → Variables → Ajouter des variables


Dbx et DAB sont tous deux construits autour des API REST Databricks , donc fondamentalement, ils sont très similaires. Je vais passer en revue les étapes pour créer manuellement un bundle à partir de notre projet dbx existant.
La première chose que nous devons mettre en place pour notre projet DAB est la configuration du déploiement. Dans dbx, nous utilisons deux fichiers pour définir et configurer nos environnements et workflows (tâches et pipelines). Pour configurer l'environnement, nous avons utilisé .dbx/project.json , et pour définir les workflows, nous avons utilisé deployment.yml .
Dans DAB, tout va dans databricks.yml , qui se trouve dans le dossier racine de votre projet. Voici à quoi cela ressemble :
bundle: name: DAB_tutorial #our bundle name # These are for any custom variables for use throughout the bundle. variables: my_cluster_id: description: The ID of an existing cluster. default: xxxx-xxxxx-xxxxxxxx #The remote workspace URL and workspace authentication credentials are read from the caller's local configuration profile named <asset-bundle-tutorial> workspace: profile: asset-bundle-tutorial # These are the default job and pipeline settings if not otherwise overridden in # the following "targets" top-level mapping. resources: jobs: etl_job: tasks: - task_key: "main" existing_cluster_id: ${var.my_cluster_id} python_wheel_task: package_name: "my_package" entry_point: "etl_job" # take a look at the setup.py entry_points section for details on how to define an entrypoint libraries: - whl: ../dist/*.whl - task_key: "eda" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/explorative_analysis.py source: WORKSPACE depends_on: - task_key: "main" test_job: tasks: - task_key: "main_notebook" existing_cluster_id: ${var.my_cluster_id} notebook_task: notebook_path: ../notebooks/run_unit_test.py source: WORKSPACE libraries: - pypi: package: pytest # These are the targets to use for deployments and workflow runs. One and only one of these # targets can be set to "default: true". targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: true workspace: profile: asset-bundle-tutorial root_path: /Users/${workspace.current_user.userName}/.bundle/${bundle.name}/my-envs/${bundle.target} host: <path to your databricks dev workspace>
Le fichier de configuration du bundle databricks.yml se compose de sections appelées mappages. Ces mappages nous permettent de modulariser le fichier de configuration en blocs logiques distincts. Il existe 8 mappages de niveau supérieur :
paquet
variables
espace de travail
artefacts
inclure
ressources
synchroniser
cibles
Ici, nous utilisons cinq de ces mappages pour organiser notre projet.
paquet :
Dans le mappage bundle , nous définissons le nom du bundle. Ici, nous pouvons également définir un ID de cluster par défaut qui doit être utilisé pour nos environnements de développement, ainsi que des informations sur l'URL et la branche Git.
variable :
Nous pouvons utiliser le mappage variables pour définir des variables personnalisées et rendre notre fichier de configuration plus réutilisable. Par exemple, nous déclarons une variable pour l'ID d'un cluster existant et l'utilisons dans différents workflows. Désormais, si vous souhaitez utiliser un autre cluster, il vous suffit de modifier la valeur de la variable.
ressources :
La cartographie resources est l'endroit où nous définissons nos flux de travail. Il comprend zéro ou un de chacun des mappages suivants : experiments , jobs , models et pipelines . Il s'agit essentiellement de notre fichier deployment.yml dans le projet dbx. Il existe cependant quelques différences mineures :
- Pour le
python_wheel_task, nous devons inclure le chemin d'accès à notre package wheel ; sinon, Databricks ne trouve pas la bibliothèque. Vous pouvez trouver plus d'informations sur la création de packages de roues à l'aide de DAB ici . - Nous pouvons utiliser des chemins relatifs au lieu de chemins complets pour exécuter les tâches du notebook. Le chemin du notebook à déployer est relatif au fichier
databricks.ymldans lequel cette tâche est déclarée.
cibles :
La cartographie targets est l'endroit où nous définissons les configurations et les ressources des différentes étapes/environnements de nos projets. Par exemple, pour un pipeline CI/CD typique, nous aurions trois cibles : le développement, la préparation et la production. Chaque cible peut être constituée de tous les mappages de niveau supérieur (à l'exception targets ) en tant que mappages enfants. Voici le schéma du mappage cible ( databricks.yml ).
targets: <some-unique-programmatic-identifier-for-this-target>: artifacts: ... bundle: ... compute_id: string default: true | false mode: development resources: ... sync: ... variables: <preceding-unique-variable-name>: <non-default-value> workspace: ...
Le mappage enfant nous permet de remplacer les configurations par défaut que nous avons définies précédemment dans les mappages de niveau supérieur. Par exemple, si nous souhaitons disposer d'un espace de travail Databricks isolé pour chaque étape de notre pipeline CI/CD, nous devons définir le mappage enfant de l'espace de travail pour chaque cible.
workspace: profile: my-default-profile targets: dev: default: true test: workspace: host: https://<staging-workspace-url> prod: workspace: host: https://<production-workspace-url>
inclure:
Le mappage include nous permet de diviser notre fichier de configuration en différents modules. Par exemple, nous pouvons enregistrer nos ressources et variables dans le fichier resources/dev_job.yml et l'importer dans notre fichier databricks.yml .
# yaml-language-server: $schema=bundle_config_schema.json bundle: name: DAB_tutorial #our bundle name workspace: profile: asset-bundle-tutorial include: - ./resources/*.yml targets: # The 'dev' target, used for development purposes. # Whenever a developer deploys using 'dev', they get their own copy. dev: # We use 'mode: development' to make sure everything deployed to this target gets a prefix # like '[dev my_user_name]'. Setting this mode also disables any schedules and # automatic triggers for jobs and enables the 'development' mode for Delta Live Tables pipelines. mode: development default: truePour une explication plus détaillée des configurations DAB, consultez les configurations Databricks Asset Bundle
Flux de travail
Les flux de travail sont exactement ceux que j'ai décrits dans le blog précédent. La seule différence réside dans l'emplacement des artefacts et des fichiers.


Le squelette du projet
voici à quoi ressemble le projet final
ASSET-BUNDLE-TUTORAL/ ├─ my_package/ │ ├─ tasks/ │ │ ├─ __init__.py │ │ ├─ sample_etl_job.py │ ├─ __init__.py │ ├─ common.py ├─ test/ │ ├─ conftest.py │ ├─ test_sample.py ├─ notebooks/ │ ├─ explorative_analysis.py │ ├─ run_unit_test.py ├─ resources/ │ ├─ dev_jobs.yml ├─ .gitignore ├─ .gitlab-ci.yml ├─ databricks.yml ├─ README.md ├─ setup.py
Valider, déployer et exécuter
Maintenant, ouvrez votre terminal et exécutez les commandes suivantes à partir du répertoire racine :
validate : Tout d’abord, nous devons vérifier si notre fichier de configuration a le bon format et la bonne syntaxe. Si la validation réussit, vous obtiendrez une représentation JSON de la configuration du bundle. En cas d'erreur, corrigez-la et exécutez à nouveau la commande jusqu'à ce que vous receviez le fichier JSON.
databricks bundle validate
déployer : le déploiement comprend la création du package de roue Python et son déploiement sur notre espace de travail Databricks, le déploiement des blocs-notes et autres fichiers sur notre espace de travail Databricks et la création des tâches dans nos flux de travail Databricks.
databricks bundle deploySi aucune option de commande n’est spécifiée, la CLI Databricks utilise la cible par défaut telle que déclarée dans les fichiers de configuration du bundle. Ici, nous n'avons qu'une seule cible donc cela n'a pas d'importance, mais pour le démontrer, nous pouvons également déployer une cible spécifique en utilisant l'option
-t dev.
run : exécutez les tâches déployées. Ici, nous pouvons spécifier quel travail nous voulons exécuter. Par exemple, dans la commande suivante, nous exécutons le travail
test_jobdans la cible de développement.databricks bundle run -t dev test_job
dans la sortie, vous obtenez une URL qui pointe vers le travail exécuté dans votre espace de travail.


vous pouvez également trouver vos tâches dans la section Workflow de votre espace de travail Databricks.
Configuration du pipeline CI
La configuration générale de notre pipeline CI reste la même que celle du projet précédent. Il se compose de deux étapes principales : tester et déployer . Au cours de la phase de test , le unit-test-job exécute les tests unitaires et déploie un flux de travail distinct pour les tests. L'étape de déploiement , activée une fois l'étape de test terminée avec succès, gère le déploiement de votre workflow ETL principal.
Ici, nous devons ajouter des étapes supplémentaires avant chaque étape d'installation de Databricks CLI et de configuration du profil d'authentification. Nous faisons cela dans la section before_script de notre pipeline CI. Le mot-clé before_script est utilisé pour définir un tableau de commandes qui doivent s'exécuter avant les commandes script de chaque tâche. Pour en savoir plus, cliquez ici .
Facultativement, vous pouvez utiliser le mot-clé after_project pour définir un tableau de commandes qui doivent s'exécuter APRÈS chaque tâche. Ici, nous pouvons utiliser databricks bundle destroy --auto-approve pour nettoyer une fois chaque tâche terminée. En général, notre pipeline passe par ces étapes :
- Installez la CLI Databricks et créez un profil de configuration.
- Construisez le projet.
- Poussez les artefacts de build vers l’espace de travail Databricks.
- Installez le package de roues sur votre cluster.
- Créez les tâches sur les workflows Databricks.
- Exécutez les travaux.
voici à quoi ressemble notre .gitlab-ci.yml :
image: python:3.9 stages: # List of stages for jobs, and their order of execution - test - deploy default: before_script: - echo "install databricks cli" - curl -V - curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh - echo "databricks CLI installation finished" - echo "create the configuration profile for token authentication" - echo "[asset-bundle-tutorial]" > ~/.databrickscfg - echo "token = $DATABRICKS_TOKEN" >> ~/.databrickscfg - echo "host = $DATABRICKS_HOST" >> ~/.databrickscfg - echo "validate the bundle" - databricks bundle validate after_script: - echo "remove all workflows" #- databricks bundle destroy --auto-approve unit-test-job: # This job runs in the test stage. stage: test script: - echo "Running unit tests." - pip3 install --upgrade wheel setuptools - pip install -e ".[local]" - databricks bundle deploy -t dev - databricks bundle run -t dev test_job deploy-job: # This job runs in the deploy stage. stage: deploy # It only runs when *both* jobs in the test stage complete successfully. script: - echo "Deploying application..." - echo "Install dependencies" - pip install -e ".[local]" - echo "Deploying Job" - databricks bundle deploy -t dev - databricks bundle run -t dev etl_job
Remarques
Voici quelques notes qui pourraient vous aider à configurer votre projet de bundle :
- Dans ce blog, nous avons créé notre bundle manuellement. D'après mon expérience, cela aide à mieux comprendre les concepts et les fonctionnalités sous-jacents. Mais si vous souhaitez démarrer rapidement votre projet, vous pouvez utiliser des modèles de bundles par défaut et non par défaut fournis par Databricks ou d'autres parties. Consultez cet article Databricks pour savoir comment lancer un projet avec le modèle Python par défaut.
- Lorsque vous déployez votre code à l'aide
databricks bundle deploy, Databricks CLI exécute la commandepython3 setup.py bdist_wheelpour créer votre package à l'aide du fichier setup.py . Si python3 est déjà installé mais que votre machine utilise l'alias python au lieu de python3 , vous rencontrerez des problèmes. Cependant, cela est facile à résoudre. Par exemple, voici et ici deux threads Stack Overflow avec quelques solutions.
Et après
Dans le prochain article de blog, je commencerai par mon premier article de blog sur la façon de démarrer un projet d'apprentissage automatique sur Databricks. Ce sera le premier article de mon prochain pipeline d'apprentissage automatique de bout en bout, couvrant tout, du développement à la production. Restez à l'écoute!
Ressources
Assurez-vous de mettre à jour le cluster_id dans resources/dev_jobs.yml
- Migrer de dbx vers des bundles | Databricks sur AWS
- Tâches de travail de développement de Databricks Asset Bundles | Databricks sur AWS
- Modes de déploiement du Databricks Asset Bundle | Databricks sur AWS
- Développer une roue Python à l'aide de Databricks Asset Bundles | Databricks sur AWS
- Bundles d'actifs Databricks : une approche standard et unifiée pour le déploiement de produits de données sur Databricks (youtube.com)
- dépôt et diapositives https://github.com/databricks/databricks-asset-bundles-dais2023








