





























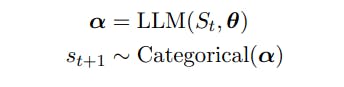














Jan 01, 1970
Generación guiada eficiente para modelos de lenguaje grandes: muestreo de LLM y generación guiada por@textmodels
514 lecturas
Generación guiada eficiente para modelos de lenguaje grandes: muestreo de LLM y generación guiada
Demasiado Largo; Para Leer
Los investigadores proponen un marco de máquina de estados finitos para la generación de texto, que ofrece un control preciso y un rendimiento mejorado.Autor:
(1) Brandon T. Willard, Computación normal;
(2) R´emi Louf, Computación Normal.
Tabla de enlaces
- Resumen e introducción
- Muestreo LLM y generación guiada
- Procesamiento e indexación iterativos de FSM
- Extensiones al análisis iterativo
- Discusión, referencias y agradecimientos
2. Muestreo LLM y generación guiada
Sea St = (s1 . . . st) representar una secuencia de t tokens con st ∈ V, V un vocabulario y |V| = N. Los vocabularios, V, se componen de cadenas de un alfabeto fijo [Sennrich et al., 2015] y N suele ser del orden de 104 o más.
Definimos el siguiente token st+1 como la siguiente variable aleatoria:
2.1 Secuencias de muestreo
Sean F ⊂ P (V), donde P es el operador de conjunto de potencias, subconjuntos de cadenas de múltiples tokens que terminan con un token especial EOS ∈ V. La tarea de generación de texto es extraer muestras de F.
Se han considerado varios procedimientos para generar elementos de F. La decodificación codiciosa consiste en generar tokens de forma recursiva, eligiendo el token con mayor probabilidad en cada paso. La búsqueda por haz también genera tokens de forma recursiva, utilizando una heurística para encontrar el modo de distribución. Más recientemente, el muestreo de SMC también se ha utilizado para generar secuencias [Lew et al., 2023].
El procedimiento de muestreo se describe en general mediante el Algoritmo 1. A menudo llamado muestreo multinomial, el procedimiento genera recursivamente nuevos tokens mediante el muestreo de la distribución categórica definida anteriormente hasta que se encuentra el token EOS.
2.2 Generación de guía
• muestras de dígitos,
• cadenas que coinciden con la expresión regular [a-zA-Z],
• y cadenas que se analizan según una gramática específica (por ejemplo, Python, SQL, etc.)
El procedimiento de muestreo con enmascaramiento es un simple aumento del Algoritmo 1 y se proporciona en el Algoritmo 2.
El cálculo de m en la línea 2.5 se realiza implícitamente sobre todos los elementos de V. Aparte de calcular α, este paso es fácilmente el más costoso. En el caso del enmascaramiento guiado por expresiones regulares (y casos más sofisticados que ese), el soporte y, por lo tanto, m dependerán necesariamente de los tokens muestreados previamente. La generación guiada de este tipo es, en última instancia, un problema de análisis o coincidencia iterativa y no se presta directamente a enfoques estándar que requieren acceso a una cadena completa por adelantado. En algunos casos, se puede realizar una comparación o análisis parcial desde el inicio de la secuencia muestreada en cada iteración, pero esto tiene un costo que crece al menos linealmente junto con el costo O(N) de su aplicación en todo el vocabulario.
Esto nos lleva a las preguntas principales de este trabajo: ¿cómo podemos hacer coincidir o analizar de manera eficiente cadenas incompletas de acuerdo con una expresión regular o CFG y determinar las máscaras m en cada iteración del Algoritmo 2?
Este documento está disponible en arxiv bajo licencia CC 4.0.
L O A D I N G
. . . comments & more!
. . . comments & more!



