























Автор:
(1) Брэндон Т. Уиллард, Нормальные вычисления;
(2) Реми Луф, Нормальные вычисления.
Таблица ссылок
- Аннотация и введение
- Выборка LLM и управляемая генерация
- Итеративная обработка и индексирование конечного автомата
- Расширения итеративного анализа
- Обсуждение, ссылки и благодарности
2. Выборка LLM и управляемая генерация
Пусть St = (s1...st) представляет собой последовательность t токенов со st ∈ V, V — словарь и |V| = N. Словари V состоят из строк фиксированного алфавита [Sennrich et al., 2015], а N часто имеет порядок 104 или больше.
Мы определяем следующий токен st+1 как следующую случайную величину:

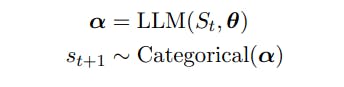


2.1 Последовательность отбора проб
Пусть F ⊂ P (V), где P — оператор степенного множества, — это подмножества многосимвольных строк, которые заканчиваются специальным токеном EOS ∈ V. Задача генерации текста состоит в том, чтобы извлечь образцы из F.
Было рассмотрено несколько процедур для генерации элементов F. Жадное декодирование заключается в рекурсивной генерации токенов, выбирая на каждом этапе токен с наибольшей вероятностью. Лучевой поиск также генерирует токены рекурсивно, используя эвристику для определения режима распределения. Совсем недавно для генерации последовательностей стали также использовать отбор проб SMC [Lew et al., 2023].


Процедура выборки в общих чертах описывается алгоритмом 1. Часто называемая полиномиальной выборкой, эта процедура рекурсивно генерирует новые токены путем выборки из категориального распределения, определенного выше, до тех пор, пока не будет найден токен EOS.
2.2 Руководство поколением


• образцы цифр,
• строки, соответствующие регулярному выражению [a-zA-Z],
• и строки, которые анализируются в соответствии с заданной грамматикой (например, Python, SQL и т. д.).
Процедура выборки с маскированием является простым дополнением алгоритма 1 и представлена в алгоритме 2.
Вычисление m в строке 2.5 неявно выполняется над всеми элементами V. Если не считать вычисления α, этот шаг, пожалуй, самый затратный. В случае маскировки на основе регулярных выражений (и в более сложных случаях) поддержка и, следовательно, m обязательно будут зависеть от ранее выбранных токенов. Управляемая генерация такого типа в конечном итоге представляет собой задачу итеративного сопоставления или синтаксического анализа и не поддается напрямую стандартным подходам, требующим предварительного доступа к полной строке. В некоторых случаях частичное сопоставление или синтаксический анализ могут выполняться с начала выборочной последовательности на каждой итерации, но это требует затрат, которые растут, по крайней мере, линейно вместе со стоимостью O(N) его применения по всему словарю.
Это подводит нас к основным вопросам данной работы: как мы можем эффективно сопоставлять или анализировать неполные строки в соответствии с регулярным выражением или CFG и определять маски m на каждой итерации алгоритма 2?


Этот документ доступен на arxiv под лицензией CC 4.0.








