























著者:
(1)ブランドン・T・ウィラード『ノーマルコンピューティング』
(2)レミ・ルーフ、「Normal Computing」
リンク一覧
2. LLMサンプリングとガイド付き生成
St = (s1 . . . st) が t 個のトークンのシーケンスを表し、st ∈ V、V が語彙、|V| = N であるとします。語彙 V は固定アルファベットの文字列で構成されており [Sennrich et al., 2015]、N は 104 以上のオーダーになることがよくあります。
次のトークン st+1 を次のランダム変数として定義します。

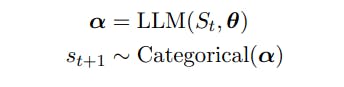


2.1 サンプリングシーケンス
F ⊂ P (V)(P はべき集合演算子)を、特別なトークン EOS ∈ V で終わる複数トークン文字列のサブセットとします。テキスト生成タスクは、F からサンプルを抽出することです。
F の要素を生成するために、いくつかの手順が検討されてきました。貪欲復号法は、各ステップで最も高い確率のトークンを選択し、トークンを再帰的に生成します。ビーム探索法も、分布のモードを見つけるためにヒューリスティックを使用して、トークンを再帰的に生成します。最近では、SMC サンプリングもシーケンスを生成するために使用されています [Lew et al., 2023]。


サンプリング手順は、一般的にアルゴリズム 1 で説明されます。多項式サンプリングと呼ばれることが多いこの手順では、EOS トークンが見つかるまで、上記で定義されたカテゴリ分布からサンプリングして、新しいトークンを再帰的に生成します。
2.2 ガイド世代


• 数字サンプル、
• 正規表現[a-zA-Z]に一致する文字列、
• 指定された文法に従って解析される文字列(Python、SQL など)
マスキングを使用したサンプリング手順は、アルゴリズム 1 の単純な拡張であり、アルゴリズム 2 で提供されます。
2.5 行目の m の計算は、V のすべての要素に対して暗黙的に実行されます。α の計算を除けば、このステップは最もコストがかかります。正規表現ガイド付きマスキングの場合 (およびそれよりも複雑な場合)、サポート、つまり m は、以前にサンプリングされたトークンに必然的に依存します。この種のガイド付き生成は、最終的には反復的なマッチングまたは解析の問題であり、事前に完全な文字列にアクセスする必要がある標準的なアプローチには直接対応できません。場合によっては、各反復でサンプリングされたシーケンスの先頭から部分的なマッチングまたは解析を実行できますが、これには、語彙全体にわたる適用の O(N) コストと並行して少なくとも線形に増加するコストがあります。
これにより、この研究の主な疑問が浮かび上がります。つまり、正規表現または CFG に従って不完全な文字列を効率的に一致または解析し、アルゴリズム 2 の各反復でマスク m を決定するにはどうすればよいのでしょうか。


この論文はCC 4.0ライセンスの下でarxivで公開されています。








