























Yazar:
(1) Brandon T. Willard, Normal Hesaplama;
(2) R'emi Louf, Normal Hesaplama.
Bağlantı Tablosu
- Özet ve Giriş
- LLM Örnekleme ve Kılavuzlu Üretim
- Yinelemeli FSM İşleme ve İndeksleme
- Yinelemeli Ayrıştırma Uzantıları
- Tartışma, Referanslar ve Teşekkür
2. LLM Örnekleme ve Kılavuzlu Üretim
St = (s1 . . . st), st ∈ V, V'nin sözcük dağarcığı ve |V| ile bir t jeton dizisini temsil etmesine izin verin. = N. Kelime dağarcığı, V, sabit bir alfabeden gelen dizilerden oluşur [Sennrich ve diğerleri, 2015] ve N genellikle 104 veya daha büyük mertebesindedir.
Bir sonraki st+1 jetonunu aşağıdaki rastgele değişken olarak tanımlarız:

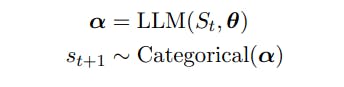


2.1 Örnekleme dizileri
P'nin güç kümesi operatörü olduğu F ⊂ P (V), özel bir belirteç EOS ∈ V ile biten çoklu belirteçli dizelerin alt kümeleri olsun. Metin oluşturma görevi, F'den örnekler çekmektir.
F. Açgözlü kod çözme öğelerini oluşturmak için çeşitli prosedürler dikkate alınmıştır, her adımda en yüksek olasılığa sahip belirteci seçerek yinelemeli olarak belirteçler oluşturmayı içerir. Işın araması aynı zamanda dağıtım modunu bulmak için bir buluşsal yöntem kullanarak yinelemeli olarak belirteçler üretir. Daha yakın zamanlarda, diziler oluşturmak için SMC örneklemesi de kullanılmıştır [Lew ve diğerleri, 2023].


Örnekleme prosedürü genel olarak Algoritma 1 ile açıklanmaktadır. Çoğunlukla çok terimli örnekleme olarak adlandırılan prosedür, EOS belirteci bulunana kadar yukarıda tanımlanan kategorik dağılımdan örnekleme yaparak yinelemeli olarak yeni belirteçler üretir.
2.2 Rehber oluşturma


• rakam örnekleri,
• [a-zA-Z] normal ifadesiyle eşleşen dizeler,
• ve belirli bir dilbilgisine göre ayrıştırılan dizeler (örn. Python, SQL, vb.)
Maskelemeli örnekleme prosedürü, Algoritma 1'in basit bir uzantısıdır ve Algoritma 2'de sağlanmaktadır.
m'nin 2.5 satırında hesaplanması örtülü olarak V'nin tüm elemanları üzerinde gerçekleştirilir. α'nın hesaplanması dışında, bu adım kolaylıkla en pahalı adımdır. Düzenli ifade kılavuzlu maskeleme durumunda ve bundan daha karmaşık durumlarda destek ve dolayısıyla m, zorunlu olarak önceden örneklenmiş belirteçlere bağlı olacaktır. Bu türden yönlendirmeli oluşturma, sonuçta yinelemeli bir eşleştirme veya ayrıştırma sorunudur ve önceden tam bir dizeye erişim gerektiren standart yaklaşımlara doğrudan uygun değildir. Bazı durumlarda, her yinelemede örneklenen dizinin başlangıcından itibaren kısmi eşleştirme veya ayrıştırma gerçekleştirilebilir, ancak bunun, tüm sözcük dağarcığı genelinde uygulanmasının O(N) maliyetiyle birlikte en azından doğrusal olarak büyüyen bir maliyeti vardır.
Bu bizi bu çalışmanın ana sorularına yönlendirir: Eksik dizeleri düzenli bir ifadeye veya CFG'ye göre verimli bir şekilde nasıl eşleştirebilir veya ayrıştırabiliriz ve Algoritma 2'nin her yinelemesinde m maskelerini nasıl belirleyebiliriz?


Bu makale arxiv'de CC 4.0 lisansı altında mevcuttur .








