























Tác giả:
(1) Brandon T. Willard, Máy tính thông thường;
(2) R'emi Louf, Máy tính thông thường.
Bảng liên kết
- Tóm tắt và giới thiệu
- Lấy mẫu LLM và tạo hướng dẫn
- Xử lý và lập chỉ mục FSM lặp
- Phần mở rộng cho phân tích lặp
- Thảo luận, Tài liệu tham khảo và Lời cảm ơn
2. Lấy mẫu LLM và tạo hướng dẫn
Đặt St = (s1 . . . st) biểu thị một chuỗi t token với st ∈ V, V a từ vựng và |V| = N. Các từ vựng, V, bao gồm các chuỗi từ một bảng chữ cái cố định [Sennrich và cộng sự, 2015] và N thường ở thứ tự 104 hoặc lớn hơn.
Chúng tôi xác định mã thông báo tiếp theo st+1 là biến ngẫu nhiên sau:

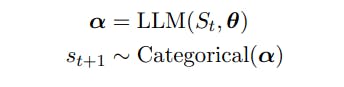


2.1 Trình tự lấy mẫu
Đặt F ⊂ P (V), trong đó P là toán tử lũy thừa, là tập hợp con của chuỗi nhiều mã thông báo kết thúc bằng mã thông báo đặc biệt EOS ∈ V. Nhiệm vụ tạo văn bản là lấy mẫu từ F.
Một số quy trình đã được xem xét để tạo ra các phần tử của F. Giải mã tham lam bao gồm việc tạo mã thông báo theo cách đệ quy, chọn mã thông báo có xác suất cao nhất ở mỗi bước. Tìm kiếm chùm cũng tạo ra các mã thông báo theo cách đệ quy, sử dụng phương pháp phỏng đoán để tìm chế độ phân phối. Gần đây hơn, việc lấy mẫu SMC cũng đã được sử dụng để tạo ra các chuỗi [Lew và cộng sự, 2023].


Quy trình lấy mẫu được mô tả tổng quát bằng Thuật toán 1. Thường được gọi là lấy mẫu đa thức, quy trình này tạo đệ quy các mã thông báo mới bằng cách lấy mẫu từ phân phối phân loại được xác định ở trên cho đến khi tìm thấy mã thông báo EOS.
2.2 Hướng dẫn tạo


• mẫu chữ số,
• các chuỗi khớp với biểu thức chính quy [a-zA-Z],
• và các chuỗi phân tích cú pháp theo một ngữ pháp cụ thể (ví dụ: Python, SQL, v.v.)
Quy trình lấy mẫu có che là phần mở rộng đơn giản của Thuật toán 1 và được cung cấp trong Thuật toán 2.
Việc tính toán m trên dòng 2.5 được thực hiện ngầm trên tất cả các phần tử của V. Ngoài việc tính α, bước này dễ dàng là bước tốn kém nhất. Trong trường hợp mặt nạ hướng dẫn biểu thức chính quy—và các trường hợp phức tạp hơn thế—sự hỗ trợ và do đó, m sẽ nhất thiết phụ thuộc vào các mã thông báo được lấy mẫu trước đó. Việc tạo có hướng dẫn thuộc loại này cuối cùng là một vấn đề phân tích hoặc so khớp lặp đi lặp lại và không thể tuân thủ trực tiếp các phương pháp tiếp cận tiêu chuẩn yêu cầu quyền truy cập vào một chuỗi hoàn chỉnh trả trước. Trong một số trường hợp, việc so khớp hoặc phân tích cú pháp một phần có thể được thực hiện từ đầu chuỗi được lấy mẫu trên mỗi lần lặp, nhưng việc này có chi phí tăng ít nhất tuyến tính cùng với chi phí O(N) của ứng dụng của nó trên toàn bộ từ vựng.
Điều này dẫn chúng ta đến các câu hỏi chính của công việc này: làm cách nào chúng ta có thể khớp hoặc phân tích các chuỗi không đầy đủ một cách hiệu quả theo biểu thức chính quy hoặc CFG và xác định mặt nạ m tại mỗi lần lặp của Thuật toán 2?


Bài viết này có sẵn trên arxiv theo giấy phép CC 4.0.








