























लेखक:
(1) ब्रैंडन टी. विलार्ड, नॉर्मल कंप्यूटिंग;
(2) रेमी लौफ, नॉर्मल कंप्यूटिंग।
लिंक की तालिका
- सार और परिचय
- एलएलएम नमूनाकरण और निर्देशित पीढ़ी
- पुनरावृत्तीय एफएसएम प्रसंस्करण और अनुक्रमण
- पुनरावृत्तीय पार्सिंग के लिए विस्तार
- चर्चा, संदर्भ और आभार
2. एलएलएम नमूनाकरण और निर्देशित पीढ़ी
मान लें कि St = (s1 . . . st) t टोकनों के अनुक्रम को दर्शाता है जिसमें st ∈ V है, V एक शब्दावली है, और |V| = N है। शब्दावली, V, एक निश्चित वर्णमाला [सेनरिच एट अल., 2015] से स्ट्रिंग्स से बनी होती है और N अक्सर 104 या उससे बड़ी होती है।
हम अगले टोकन st+1 को निम्नलिखित यादृच्छिक चर के रूप में परिभाषित करते हैं:

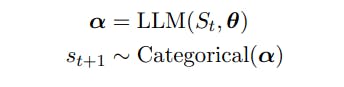


2.1 नमूनाकरण अनुक्रम
मान लें कि F ⊂ P (V), जहाँ P पावरसेट ऑपरेटर है, बहु-टोकन स्ट्रिंग के उपसमुच्चय हैं जो एक विशेष टोकन EOS ∈ V के साथ समाप्त होते हैं। पाठ निर्माण कार्य F से नमूने निकालना है।
F के तत्वों को उत्पन्न करने के लिए कई प्रक्रियाओं पर विचार किया गया है। लालची डिकोडिंग में टोकन को पुनरावर्ती रूप से उत्पन्न करना शामिल है, प्रत्येक चरण में सबसे अधिक संभावना वाले टोकन को चुनना। बीम सर्च भी वितरण के मोड को खोजने के लिए एक अनुमानी का उपयोग करके टोकन को पुनरावर्ती रूप से उत्पन्न करता है। हाल ही में, अनुक्रम उत्पन्न करने के लिए SMC सैंपलिंग का भी उपयोग किया गया है [लेव एट अल., 2023]।


नमूनाकरण प्रक्रिया को सामान्य रूप से एल्गोरिथ्म 1 द्वारा वर्णित किया गया है। इसे अक्सर बहुपद नमूनाकरण कहा जाता है, यह प्रक्रिया ऊपर परिभाषित श्रेणीबद्ध वितरण से नमूना लेकर पुनरावर्ती रूप से नए टोकन उत्पन्न करती है जब तक कि EOS टोकन नहीं मिल जाता।
2.2 मार्गदर्शक पीढ़ी


• अंक नमूने,
• स्ट्रिंग जो नियमित अभिव्यक्ति [a-zA-Z] से मेल खाती हैं,
• और स्ट्रिंग्स जो निर्दिष्ट व्याकरण (जैसे पायथन, एसक्यूएल, आदि) के अनुसार पार्स करते हैं
मास्किंग के साथ नमूनाकरण प्रक्रिया एल्गोरिथम 1 का एक सरल संवर्द्धन है और इसे एल्गोरिथम 2 में प्रदान किया गया है।
लाइन 2.5 पर m की गणना V के सभी तत्वों पर निहित रूप से की जाती है। α की गणना के अलावा, यह चरण आसानी से सबसे महंगा है। नियमित अभिव्यक्ति-निर्देशित मास्किंग के मामले में - और उससे अधिक परिष्कृत मामलों में - समर्थन और, इस प्रकार, m अनिवार्य रूप से पहले से सैंपल किए गए टोकन पर निर्भर करेगा। इस तरह की निर्देशित पीढ़ी अंततः एक पुनरावृत्त मिलान या पार्सिंग समस्या है और यह सीधे मानक दृष्टिकोणों के लिए उपयुक्त नहीं है, जिसके लिए पहले से ही एक पूर्ण स्ट्रिंग तक पहुंच की आवश्यकता होती है। कुछ मामलों में, प्रत्येक पुनरावृत्ति पर सैंपल किए गए अनुक्रम की शुरुआत से आंशिक मिलान या पार्सिंग की जा सकती है, लेकिन इसकी एक लागत है जो पूरे शब्दावली में इसके आवेदन की O(N) लागत के साथ कम से कम रैखिक रूप से बढ़ती है।
यह हमें इस कार्य के मुख्य प्रश्नों की ओर ले जाता है: हम नियमित अभिव्यक्ति या CFG के अनुसार अपूर्ण स्ट्रिंग्स का कुशलतापूर्वक मिलान या पार्स कैसे कर सकते हैं और एल्गोरिथम 2 के प्रत्येक पुनरावृत्ति पर मास्क m का निर्धारण कैसे कर सकते हैं?


यह पेपर CC 4.0 लाइसेंस के अंतर्गत arxiv पर उपलब्ध है।








