





























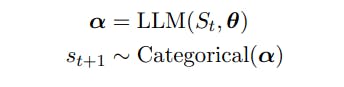














Jan 01, 1970
496 판독값
대규모 언어 모델을 위한 효율적인 안내 생성: LLM 샘플링 및 안내 생성
너무 오래; 읽다
연구원들은 정확한 제어와 향상된 성능을 제공하는 텍스트 생성을 위한 유한 상태 기계 프레임워크를 제안합니다.작가:
(1) Brandon T. Willard, 일반 컴퓨팅;
(2) R'emi Louf, 일반 컴퓨팅.
링크 표
2. LLM 샘플링 및 유도 생성
St = (s1 . . . . st)는 st ∈ V, V는 어휘 및 |V|를 갖는 t 토큰의 시퀀스를 나타냅니다. = N. 어휘 V는 고정된 알파벳의 문자열로 구성되며[Sennrich et al., 2015] N은 종종 104 이상입니다.
다음 토큰 st+1을 다음 무작위 변수로 정의합니다.
2.1 샘플링 순서
P가 거듭제곱 연산자인 F ⊂ P (V)를 특수 토큰 EOS ∈ V로 끝나는 멀티 토큰 문자열의 하위 집합이라고 가정합니다. 텍스트 생성 작업은 F에서 샘플을 그리는 것입니다.
F의 요소를 생성하기 위해 여러 절차가 고려되었습니다. Greedy 디코딩은 각 단계에서 가장 높은 확률로 토큰을 선택하여 재귀적으로 토큰을 생성하는 것으로 구성됩니다. 빔 검색은 또한 분포 모드를 찾기 위해 휴리스틱을 사용하여 재귀적으로 토큰을 생성합니다. 최근에는 SMC 샘플링도 시퀀스를 생성하는 데 사용되었습니다[Lew et al., 2023].
샘플링 절차는 일반적으로 알고리즘 1에 의해 설명됩니다. 흔히 다항 샘플링이라고 불리는 이 절차는 EOS 토큰을 찾을 때까지 위에 정의된 범주형 분포에서 샘플링하여 새로운 토큰을 반복적으로 생성합니다.
2.2 세대 안내
• 숫자 샘플,
• 정규식 [a-zA-Z]와 일치하는 문자열,
• 지정된 문법(예: Python, SQL 등)에 따라 구문 분석하는 문자열
마스킹을 사용한 샘플링 절차는 알고리즘 1을 간단하게 확장한 것이며 알고리즘 2에서 제공됩니다.
2.5행에서 m의 계산은 V의 모든 요소에 대해 암묵적으로 수행됩니다. α를 계산하는 것 외에도 이 단계는 가장 비용이 많이 듭니다. 정규식 기반 마스킹의 경우(및 그보다 더 정교한 경우) 지원 및 m은 필연적으로 이전에 샘플링된 토큰에 따라 달라집니다. 이러한 종류의 유도 생성은 궁극적으로 반복적인 일치 또는 구문 분석 문제이며 완전한 문자열에 대한 사전 액세스가 필요한 표준 접근 방식을 직접적으로 적용할 수 없습니다. 어떤 경우에는 각 반복에서 샘플링된 시퀀스의 시작부터 부분 일치 또는 구문 분석을 수행할 수 있지만 이는 전체 어휘에 걸쳐 적용하는 O(N) 비용과 함께 최소한 선형적으로 증가하는 비용을 갖습니다.
이는 이 작업의 주요 질문으로 이어집니다. 어떻게 정규 표현식이나 CFG에 따라 불완전한 문자열을 효율적으로 일치시키거나 구문 분석하고 알고리즘 2의 각 반복에서 마스크 m을 결정할 수 있습니까?
이 문서는 CC 4.0 라이선스에 따라 arxiv에서 볼 수 있습니다.
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
태그 걸기
관련 기사

Floki의 Valhalla가 인도 스리랑카 투어의 보조 후원자로 합류 #web3
Jan 01, 1970


