























Autor:
(1) Brandon T. Willard, Normal Computing;
(2) R´emi Louf, Normal Computing.
Linktabelle
- Zusammenfassung und Einleitung
- LLM-Sampling und geführte Generierung
- Iterative FSM-Verarbeitung und Indizierung
- Erweiterungen zum iterativen Parsing
- Diskussion, Referenzen und Danksagungen
2. LLM-Sampling und geführte Generierung
Es sei St = (s1 . . . st) eine Folge von t Token mit st ∈ V, V ein Vokabular und |V| = N. Die Vokabulare V bestehen aus Zeichenfolgen eines festen Alphabets [Sennrich et al., 2015] und N liegt oft in der Größenordnung von 104 oder größer.
Wir definieren das nächste Token st+1 als folgende Zufallsvariable:

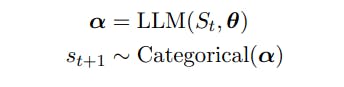


2.1 Abtastsequenzen
Seien F ⊂ P (V), wobei P der Potenzmengenoperator ist, Teilmengen von Zeichenfolgen mit mehreren Token, die mit einem speziellen Token EOS ∈ V enden. Die Aufgabe der Textgenerierung besteht darin, Beispiele aus F zu ziehen.
Es wurden mehrere Verfahren zur Generierung von Elementen von F in Betracht gezogen. Bei der Greedy-Decodierung werden Token rekursiv generiert, wobei bei jedem Schritt das Token mit der höchsten Wahrscheinlichkeit ausgewählt wird. Auch die Beam-Suche generiert Token rekursiv und verwendet eine Heuristik, um den Modus der Verteilung zu finden. In jüngerer Zeit wurde auch SMC-Sampling zur Generierung von Sequenzen verwendet [Lew et al., 2023].


Das Sampling-Verfahren wird allgemein durch Algorithmus 1 beschrieben. Das Verfahren wird oft als multinomiales Sampling bezeichnet und generiert rekursiv neue Token, indem es aus der oben definierten kategorischen Verteilung Sampling durchführt, bis das EOS-Token gefunden wird.
2.2 Generation führen


• Ziffernproben,
• Zeichenfolgen, die dem regulären Ausdruck [a-zA-Z] entsprechen,
• und Zeichenfolgen, die gemäß einer angegebenen Grammatik analysiert werden (z. B. Python, SQL usw.)
Das Sampling-Verfahren mit Maskierung ist eine einfache Erweiterung von Algorithmus 1 und wird in Algorithmus 2 bereitgestellt.
Die Berechnung von m in Zeile 2.5 wird implizit über alle Elemente von V durchgeführt. Abgesehen von der Berechnung von α ist dieser Schritt bei weitem der teuerste. Im Fall einer durch reguläre Ausdrücke gesteuerten Maskierung – und in komplexeren Fällen – hängt die Unterstützung und damit m zwangsläufig von den zuvor abgetasteten Token ab. Eine derartige gesteuerte Generierung ist letztendlich ein iteratives Matching- oder Parsing-Problem und lässt sich nicht direkt mit Standardansätzen lösen, die im Voraus Zugriff auf eine vollständige Zeichenfolge erfordern. In einigen Fällen kann bei jeder Iteration ein teilweises Matching oder Parsing vom Beginn der abgetasteten Sequenz an durchgeführt werden, aber dies hat Kosten, die mindestens linear mit den O(N)-Kosten seiner Anwendung über das gesamte Vokabular hinweg wachsen.
Dies führt uns zu den Hauptfragen dieser Arbeit: Wie können wir unvollständige Zeichenfolgen effizient gemäß einem regulären Ausdruck oder CFG abgleichen oder analysieren und die Masken m bei jeder Iteration von Algorithmus 2 bestimmen?


Dieses Dokument ist auf Arxiv unter der CC 4.0-Lizenz verfügbar .








