























Autor:
(1) Brandon T. Willard, Computação Normal;
(2) R´emi Louf, Computação Normal.
Tabela de links
- Resumo e introdução
- Amostragem LLM e Geração Guiada
- Processamento e indexação iterativo de FSM
- Extensões para análise iterativa
- Discussão, Referências e Agradecimentos
2. Amostragem LLM e Geração Guiada
Seja St = (s1 . . . st) represente uma sequência de t tokens com st ∈ V, V um vocabulário e |V| = N. Os vocabulários, V, são compostos de strings de um alfabeto fixo [Sennrich et al., 2015] e N é frequentemente da ordem de 104 ou maior.
Definimos o próximo token st+1 como a seguinte variável aleatória:

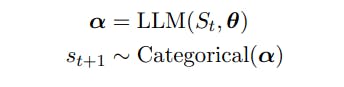


2.1 Sequências de amostragem
Sejam F ⊂ P (V), onde P é o operador powerset, subconjuntos de strings multi-token que terminam com um token especial EOS ∈ V. A tarefa de geração de texto é extrair amostras de F.
Vários procedimentos foram considerados para gerar elementos de F. A decodificação gananciosa consiste em gerar tokens recursivamente, escolhendo o token com maior probabilidade em cada etapa. A pesquisa em feixe também gera tokens recursivamente, usando uma heurística para encontrar o modo de distribuição. Mais recentemente, a amostragem SMC também tem sido usada para gerar sequências [Lew et al., 2023].


O procedimento de amostragem é descrito em geral pelo Algoritmo 1. Freqüentemente chamado de amostragem multinomial, o procedimento gera recursivamente novos tokens por amostragem da distribuição categórica definida acima até que o token EOS seja encontrado.
2.2 Geração orientadora


• amostras de dígitos,
• strings que correspondem à expressão regular [a-zA-Z],
• e strings que analisam de acordo com uma gramática especificada (por exemplo, Python, SQL, etc.)
O procedimento de amostragem com mascaramento é um simples aumento do Algoritmo 1 e é fornecido no Algoritmo 2.
O cálculo de m na linha 2.5 é realizado implicitamente sobre todos os elementos de V. Além do cálculo de α, esta etapa é facilmente a mais cara. No caso de mascaramento guiado por expressões regulares – e casos mais sofisticados que esse – o suporte e, portanto, m dependerão necessariamente dos tokens amostrados anteriormente. A geração guiada desse tipo é, em última análise, um problema iterativo de correspondência ou análise e não é diretamente passível de abordagens padrão que exigem acesso antecipado a uma string completa. Em alguns casos, a correspondência ou análise parcial pode ser realizada desde o início da sequência amostrada em cada iteração, mas isto tem um custo que cresce pelo menos linearmente junto com o custo O(N) de sua aplicação em todo o vocabulário.
Isso nos leva às principais questões deste trabalho: como podemos combinar ou analisar strings incompletas de forma eficiente de acordo com uma expressão regular ou CFG e determinar as máscaras m em cada iteração do Algoritmo 2?


Este artigo está disponível no arxiv sob licença CC 4.0.








