























Auteur:
(1) Brandon T. Willard, informatique normale ;
(2) Rémi Louf, Informatique normale.
Tableau des liens
- Résumé et introduction
- Échantillonnage LLM et génération guidée
- Traitement et indexation itératifs FSM
- Extensions à l'analyse itérative
- Discussion, références et remerciements
2. Échantillonnage LLM et génération guidée
Soit St = (s1 . . . st) représente une séquence de t jetons avec st ∈ V, V un vocabulaire et |V| = N. Les vocabulaires, V, sont composés de chaînes d'un alphabet fixe [Sennrich et al., 2015] et N est souvent de l'ordre de 104 ou plus.
Nous définissons le prochain jeton st+1 comme la variable aléatoire suivante :

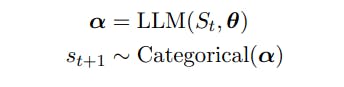


2.1 Séquences d'échantillonnage
Soit F ⊂ P (V), où P est l'opérateur d'ensemble de puissances, des sous-ensembles de chaînes multi-jetons qui se terminent par un jeton spécial EOS ∈ V. La tâche de génération de texte consiste à tirer des échantillons de F.
Plusieurs procédures ont été envisagées pour générer des éléments de F. Le décodage gourmand consiste à générer des jetons de manière récursive, en choisissant le jeton ayant la plus forte probabilité à chaque étape. La recherche par faisceau génère également des jetons de manière récursive, en utilisant une heuristique pour trouver le mode de distribution. Plus récemment, l'échantillonnage SMC a également été utilisé pour générer des séquences [Lew et al., 2023].


La procédure d'échantillonnage est décrite en général par l'algorithme 1. Souvent appelée échantillonnage multinomial, la procédure génère de manière récursive de nouveaux jetons en échantillonnant à partir de la distribution catégorielle définie ci-dessus jusqu'à ce que le jeton EOS soit trouvé.
2.2 Génération de guidage


• des échantillons de chiffres,
• des chaînes qui correspondent à l'expression régulière [a-zA-Z],
• et des chaînes qui analysent selon une grammaire spécifiée (par exemple Python, SQL, etc.)
La procédure d'échantillonnage avec masquage est une simple augmentation de l'algorithme 1 et est fournie dans l'algorithme 2.
Le calcul de m sur la ligne 2.5 est implicitement effectué sur tous les éléments de V. Mis à part le calcul de α, cette étape est de loin la plus coûteuse. Dans le cas d'un masquage guidé par des expressions régulières - et dans des cas plus sophistiqués que cela - le support et donc m dépendront nécessairement des jetons précédemment échantillonnés. La génération guidée de ce type est en fin de compte un problème de correspondance ou d'analyse itérative et ne se prête pas directement aux approches standard qui nécessitent l'accès initial à une chaîne complète. Dans certains cas, une correspondance ou une analyse partielle peut être effectuée dès le début de la séquence échantillonnée à chaque itération, mais cela a un coût qui augmente au moins linéairement parallèlement au coût O(N) de son application dans l'ensemble du vocabulaire.
Cela nous amène aux principales questions de ce travail : comment faire correspondre ou analyser efficacement des chaînes incomplètes selon une expression régulière ou CFG et déterminer les masques m à chaque itération de l'algorithme 2 ?


Cet article est disponible sur arxiv sous licence CC 4.0.








