
























私は、グラフ上で Retrieval-Augmented Generation (RAG) を実装する新しいアプローチ (GraphRAG とも呼ばれる) に常に興味をそそられています。しかし、GraphRAG という言葉を聞くと、人それぞれに異なる実装を思い浮かべるようです。このブログ記事では、「 From Local to Global GraphRAG 」の記事と Microsoft の研究者による実装について詳しく説明します。ナレッジ グラフの構築と要約の部分を取り上げ、リトリーバーについては次のブログ記事に譲ります。研究者は、コード リポジトリを提供してくれたので、プロジェクト ページも用意されています。
上記の記事で採用されているアプローチは非常に興味深いものです。私が理解している限りでは、複数のソースからの情報を凝縮して組み合わせるためのパイプラインのステップとしてナレッジ グラフを使用するというものです。テキストからエンティティと関係性を抽出することは目新しいことではありません。しかし、著者らは凝縮されたグラフ構造と情報を自然言語テキストとして要約するという斬新なアイデア (少なくとも私にとっては) を紹介しています。パイプラインはドキュメントからの入力テキストから始まり、処理されてグラフが生成されます。その後、グラフは自然言語テキストに変換され、生成されたテキストには複数のドキュメントに分散されていた特定のエンティティまたはグラフ コミュニティに関する凝縮された情報が含まれます。


非常に大まかに言えば、GraphRAG パイプラインへの入力は、さまざまな情報を含むソース ドキュメントです。ドキュメントは LLM を使用して処理され、論文に登場するエンティティとその関係性に関する構造化情報が抽出されます。抽出されたこの構造化情報は、ナレッジ グラフの構築に使用されます。
ナレッジ グラフ データ表現を使用する利点は、特定のエンティティに関する複数のドキュメントまたはデータ ソースからの情報を迅速かつ簡単に組み合わせることができることです。ただし、前述のように、ナレッジ グラフは唯一のデータ表現ではありません。ナレッジ グラフが構築された後、グラフ アルゴリズムと LLM プロンプトの組み合わせを使用して、ナレッジ グラフで見つかったエンティティのコミュニティの自然言語による要約を生成します。
これらの要約には、特定のエンティティおよびコミュニティに関する複数のデータ ソースおよびドキュメントにまたがる要約された情報が含まれます。
パイプラインをより詳細に理解するには、元の論文に記載されているステップごとの説明を参照してください。


パイプラインのステップ — GraphRAG 論文からの画像、CC BY 4.0 ライセンス
以下は、Neo4j と LangChain を使用して彼らのアプローチを再現するために使用するパイプラインの概要です。
インデックス作成 - グラフ生成
- ソース ドキュメントをテキスト チャンクに分割: ソース ドキュメントは、処理のために小さなテキスト チャンクに分割されます。
- テキスト チャンクから要素インスタンスへ: 各テキスト チャンクが分析され、エンティティとリレーションシップが抽出され、これらの要素を表すタプルのリストが生成されます。
- 要素インスタンスから要素サマリーへ: 抽出されたエンティティとリレーションシップは、LLM によって各要素の説明テキスト ブロックに要約されます。
- 要素サマリーからグラフ コミュニティへ: これらのエンティティ サマリーはグラフを形成し、その後、階層構造用のLeidenなどのアルゴリズムを使用してコミュニティに分割されます。
- グラフ コミュニティからコミュニティ サマリーへ: 各コミュニティのサマリーは、データセットのグローバルなトピック構造とセマンティクスを理解するために LLM を使用して生成されます。
検索 — 回答
- コミュニティ サマリーからグローバル アンサーへ: コミュニティ サマリーは、中間回答を生成してユーザー クエリに回答するために使用され、その後、最終的なグローバル アンサーに集約されます。
私の実装は彼らのコードが利用可能になる前に行われたため、基礎となるアプローチや使用されている LLM プロンプトに若干の違いがある可能性があることに注意してください。これらの違いについては、後で説明したいと思います。
コードはGitHubで入手できます。
Neo4j 環境の設定
基盤となるグラフ ストアとして Neo4j を使用します。最も簡単に始めるには、Graph Data Science プラグインがインストールされた Neo4j データベースのクラウド インスタンスを提供するNeo4j Sandboxの無料インスタンスを使用します。または、 Neo4j Desktopアプリケーションをダウンロードしてローカル データベース インスタンスを作成することにより、Neo4j データベースのローカル インスタンスをセットアップすることもできます。ローカル バージョンを使用している場合は、APOC プラグインと GDS プラグインの両方を必ずインストールしてください。実稼働セットアップでは、GDS プラグインを提供する有料のマネージド AuraDS (データ サイエンス) インスタンスを使用できます。
まず、LangChain に追加した便利なラッパーであるNeo4jGraphインスタンスを作成します。
from langchain_community.graphs import Neo4jGraph os.environ["NEO4J_URI"] = "bolt://44.202.208.177:7687" os.environ["NEO4J_USERNAME"] = "neo4j" os.environ["NEO4J_PASSWORD"] = "mast-codes-trails" graph = Neo4jGraph(refresh_schema=False)データセット
以前 Diffbot の API を使用して作成したニュース記事データセットを使用します。再利用しやすいように GitHub にアップロードしておきました。
news = pd.read_csv( "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/news_articles.csv" ) news["tokens"] = [ num_tokens_from_string(f"{row['title']} {row['text']}") for i, row in news.iterrows() ] news.head()
データセットの最初の数行を調べてみましょう。


tiktoken ライブラリを使用すると、記事のタイトルと本文、公開日、トークン数を取得できます。
テキストチャンク
テキスト チャンク化の手順は非常に重要で、下流の結果に大きな影響を与えます。論文の著者は、テキスト チャンクを小さくすると、全体的により多くのエンティティが抽出されることを発見しました。


テキストチャンクのサイズを与えられた抽出エンティティの数 — GraphRAG 論文からの画像、CC BY 4.0 ライセンス
ご覧のとおり、2,400 トークンのテキスト チャンクを使用すると、600 トークンを使用した場合よりも抽出されるエンティティが少なくなります。さらに、LLM は最初の実行ですべてのエンティティを抽出しない可能性があることもわかりました。その場合、抽出を複数回実行するヒューリスティックを導入します。これについては、次のセクションで詳しく説明します。
ただし、トレードオフは常に存在します。テキスト チャンクを小さくすると、ドキュメント全体に広がる特定のエンティティのコンテキストと共参照が失われる可能性があります。たとえば、ドキュメントで「John」と「he」が別々の文で言及されている場合、テキストを小さなチャンクに分割すると、「he」が John を指していることが不明瞭になる可能性があります。共参照の問題の一部は、オーバーラップ テキスト チャンク化戦略を使用して解決できますが、すべてではありません。
記事のテキストのサイズを調べてみましょう。
sns.histplot(news["tokens"], kde=False) plt.title('Distribution of chunk sizes') plt.xlabel('Token count') plt.ylabel('Frequency') plt.show()


冠詞トークン数の分布はほぼ正規分布で、ピークは約 400 トークンです。チャンクの頻度はこのピークまで徐々に増加し、その後対称的に減少します。これは、ほとんどのテキスト チャンクが 400 トークン付近にあることを示しています。
この分布のため、共参照の問題を回避するために、ここではテキスト チャンク化は実行しません。デフォルトでは、GraphRAG プロジェクトは 300 トークンのチャンク サイズを使用し、100 トークンが重複します。
ノードと関係の抽出
次のステップは、テキスト チャンクから知識を構築することです。このユース ケースでは、LLM を使用して、テキストからノードと関係の形式で構造化された情報を抽出します。著者が論文で使用したLLM プロンプトを調べることができます。必要に応じてノード ラベルを事前定義できる LLM プロンプトがありますが、デフォルトではオプションです。さらに、元のドキュメントで抽出された関係には実際にはタイプがなく、説明のみがあります。この選択の背後にある理由は、LLM がより豊富で微妙な情報を関係として抽出して保持できるようにするためだと思います。ただし、関係タイプの仕様がないクリーンなナレッジ グラフを作成することは困難です (説明はプロパティに入れることができます)。
私たちの実装では、LangChain ライブラリで利用可能なLLMGraphTransformerを使用します。記事の実装のように純粋なプロンプト エンジニアリングを使用する代わりに、 LLMGraphTransformer は組み込み関数呼び出しサポートを使用して構造化情報 (LangChain の構造化出力 LLM) を抽出します。 システム プロンプトを検査できます。
from langchain_experimental.graph_transformers import LLMGraphTransformer from langchain_openai import ChatOpenAI llm = ChatOpenAI(temperature=0, model_name="gpt-4o") llm_transformer = LLMGraphTransformer( llm=llm, node_properties=["description"], relationship_properties=["description"] ) def process_text(text: str) -> List[GraphDocument]: doc = Document(page_content=text) return llm_transformer.convert_to_graph_documents([doc])
この例では、グラフ抽出に GPT-4o を使用します。著者は、LLM にエンティティとリレーションシップ、およびその説明を抽出するように具体的に指示しています。LangChain 実装では、 node_propertiesとrelationship_properties属性を使用して、LLM に抽出させるノードまたはリレーションシップのプロパティを指定できます。
LLMGraphTransformer 実装との違いは、すべてのノードまたはリレーションシップ プロパティがオプションであるため、すべてのノードにdescriptionプロパティがあるわけではないことです。必要に応じて、必須のdescriptionプロパティを持つカスタム抽出を定義することもできますが、この実装ではそれをスキップします。
グラフの抽出を高速化するためにリクエストを並列化し、結果を Neo4j に保存します。
MAX_WORKERS = 10 NUM_ARTICLES = 2000 graph_documents = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(process_text, f"{row['title']} {row['text']}") for i, row in news.head(NUM_ARTICLES).iterrows() ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): graph_document = future.result() graph_documents.extend(graph_document) graph.add_graph_documents( graph_documents, baseEntityLabel=True, include_source=True )
この例では、2,000 件の記事からグラフ情報を抽出し、結果を Neo4j に保存します。約 13,000 件のエンティティと 16,000 件の関係を抽出しました。グラフ内の抽出されたドキュメントの例を次に示します。


抽出が完了するまでに約 35 (+/- 5) 分かかり、GPT-4o を使用すると約 30 ドルかかります。
このステップでは、著者らは、グラフ情報を複数のパスで抽出するかどうかを決定するためのヒューリスティックを導入しています。簡単にするために、1 パスのみを実行します。ただし、複数のパスを実行したい場合は、最初の抽出結果を会話履歴として保存し、 LLM に多くのエンティティが欠落していることを指示するだけで、GraphRAG の著者らが行っているように、より多くのエンティティを抽出するように指示できます。
以前、テキスト チャンクのサイズがいかに重要で、抽出されるエンティティの数にどのように影響するかについて説明しました。追加のテキスト チャンク処理は実行しなかったため、テキスト チャンクのサイズに基づいて抽出されたエンティティの分布を評価できます。
entity_dist = graph.query( """ MATCH (d:Document) RETURN d.text AS text, count {(d)-[:MENTIONS]->()} AS entity_count """ ) entity_dist_df = pd.DataFrame.from_records(entity_dist) entity_dist_df["token_count"] = [ num_tokens_from_string(str(el)) for el in entity_dist_df["text"] ] # Scatter plot with regression line sns.lmplot( x="token_count", y="entity_count", data=entity_dist_df, line_kws={"color": "red"} ) plt.title("Entity Count vs Token Count Distribution") plt.xlabel("Token Count") plt.ylabel("Entity Count") plt.show()


散布図では、赤い線で示されるように、プラスの傾向はあるものの、関係は準線形であることがわかります。トークン数が増加しても、ほとんどのデータ ポイントはエンティティ数の少ないところに集まっています。これは、抽出されるエンティティの数がテキスト チャンクのサイズに比例して増加しないことを示しています。外れ値もいくつか存在しますが、一般的なパターンは、トークン数が多くなってもエンティティ数が常に増加するわけではないことを示しています。これは、テキスト チャンクのサイズが小さいほど、より多くの情報が抽出されるという著者の発見を裏付けています。
また、構築されたグラフのノード次数分布を調べるのも興味深いと思いました。次のコードは、ノード次数分布を取得して視覚化します。
degree_dist = graph.query( """ MATCH (e:__Entity__) RETURN count {(e)-[:!MENTIONS]-()} AS node_degree """ ) degree_dist_df = pd.DataFrame.from_records(degree_dist) # Calculate mean and median mean_degree = np.mean(degree_dist_df['node_degree']) percentiles = np.percentile(degree_dist_df['node_degree'], [25, 50, 75, 90]) # Create a histogram with a logarithmic scale plt.figure(figsize=(12, 6)) sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue') # Use a logarithmic scale for the x-axis plt.yscale('log') # Adding labels and title plt.xlabel('Node Degree') plt.ylabel('Count (log scale)') plt.title('Node Degree Distribution') # Add mean, median, and percentile lines plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'Mean: {mean_degree:.2f}') plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25th Percentile: {percentiles[0]:.2f}') plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50th Percentile: {percentiles[1]:.2f}') plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75th Percentile: {percentiles[2]:.2f}') plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90th Percentile: {percentiles[3]:.2f}') # Add legend plt.legend() # Show the plot plt.show()


ノード次数分布はべき乗法則パターンに従っており、ほとんどのノードの接続数は非常に少ないのに対し、少数のノードは高度に接続されています。平均次数は 2.45、中央値は 1.00 で、半数以上のノードが 1 つの接続しか持たないことを示しています。ほとんどのノード (75%) は 2 つ以下の接続を持ち、90% は 5 つ以下の接続を持っています。この分布は、少数のハブが多数の接続を持ち、ほとんどのノードが少数の接続を持つ、多くの現実世界のネットワークに典型的です。
ノードと関係の説明はどちらも必須のプロパティではないため、抽出された数も調べます。
graph.query(""" MATCH (n:`__Entity__`) RETURN "node" AS type, count(*) AS total_count, count(n.description) AS non_null_descriptions UNION ALL MATCH (n)-[r:!MENTIONS]->() RETURN "relationship" AS type, count(*) AS total_count, count(r.description) AS non_null_descriptions """)
結果によると、12,994 個のノードのうち 5,926 個 (45.6%) に説明プロパティがあります。一方、15,921 個の関係のうち 5,569 個 (35%) のみにこのようなプロパティがあります。
LLM の確率的な性質により、実行やソース データ、LLM、プロンプトによって数値が異なる場合があることに注意してください。
エンティティ解決
エンティティ解決 (重複排除) は、ナレッジ グラフを構築するときに非常に重要です。エンティティ解決によって、各エンティティが一意かつ正確に表現され、重複が防止され、同じ実世界のエンティティを参照するレコードがマージされるためです。このプロセスは、グラフ内のデータの整合性と一貫性を維持するために不可欠です。エンティティ解決がないと、ナレッジ グラフのデータが断片化され、一貫性が失われ、エラーや信頼性の低い洞察につながります。


この画像は、現実世界の単一のエンティティが、異なるドキュメントではわずかに異なる名前で表示され、その結果としてグラフにもどのように表示されるかを示しています。
さらに、エンティティ解決を行わないと、まばらなデータが重大な問題になります。さまざまなソースからの不完全または不完全なデータにより、情報が散在して断片化され、エンティティの一貫性のある包括的な理解を形成することが困難になります。正確なエンティティ解決は、データを統合し、ギャップを埋め、各エンティティの統一されたビューを作成することで、この問題に対処します。


Senzingエンティティ解決を使用して 国際調査報道ジャーナリスト連合 (ICIJ) のオフショア漏洩データを接続した前後の画像 — Paco Nathan提供
視覚化の左側の部分は、まばらで接続されていないグラフを示しています。ただし、右側に示すように、このようなグラフは、効率的なエンティティ解決によって適切に接続できるようになります。
全体として、エンティティ解決により、データの取得と統合の効率が向上し、さまざまなソースにわたる情報の統合ビューが提供されます。最終的には、信頼性が高く完全なナレッジ グラフに基づいて、より効果的な質問回答が可能になります。
残念ながら、GraphRAG 論文の著者は、論文ではエンティティ解決について言及していますが、リポジトリにはエンティティ解決コードを含めていません。このコードを省いた理由の 1 つは、特定のドメインに対して堅牢でパフォーマンスの高いエンティティ解決を実装するのが難しいためだと考えられます。定義済みのノード タイプを扱う場合は、さまざまなノードにカスタム ヒューリスティックを実装できます (定義されていない場合は、会社、組織、ビジネスなどのように一貫性が十分ではありません)。ただし、今回の場合のように、ノードのラベルやタイプが事前にわからない場合は、さらに難しい問題になります。それでも、ここでは、テキスト埋め込みとグラフ アルゴリズムを単語距離と LLM と組み合わせて、プロジェクトにエンティティ解決のバージョンを実装します。


エンティティ解決のプロセスには、次の手順が含まれます。
- グラフ内のエンティティ- グラフ内のすべてのエンティティから開始します。
- K 近傍グラフ— テキスト埋め込みに基づいて類似のエンティティを接続する k 近傍グラフを構築します。
- 弱く接続されたコンポーネント— k 近傍グラフ内の弱く接続されたコンポーネントを識別し、類似する可能性のあるエンティティをグループ化します。これらのコンポーネントが識別された後、単語距離フィルタリング手順を追加します。
- LLM 評価— LLM を使用してこれらのコンポーネントを評価し、各コンポーネント内のエンティティをマージする必要があるかどうかを決定し、エンティティ解決に関する最終決定を下します (たとえば、「Silicon Valley Bank」と「Silicon_Valley_Bank」をマージし、「2023 年 9 月 16 日」と「2023 年 9 月 2 日」などの異なる日付のマージを拒否するなど)。
まず、エンティティの名前と説明のプロパティのテキスト埋め込みを計算します。これを実現するには、LangChain のNeo4jVector統合のfrom_existing_graphメソッドを使用できます。
vector = Neo4jVector.from_existing_graph( OpenAIEmbeddings(), node_label='__Entity__', text_node_properties=['id', 'description'], embedding_node_property='embedding' )
これらの埋め込みを使用して、これらの埋め込みのコサイン距離に基づいて類似する潜在的な候補を見つけることができます。Graph Data Science (GDS) ライブラリで利用可能なグラフ アルゴリズムを使用します。そのため、Python の方法で簡単に使用できるように、 GDS Python クライアントを使用できます。
from graphdatascience import GraphDataScience gds = GraphDataScience( os.environ["NEO4J_URI"], auth=(os.environ["NEO4J_USERNAME"], os.environ["NEO4J_PASSWORD"]) )
GDS ライブラリに慣れていない場合は、グラフ アルゴリズムを実行する前に、まずメモリ内グラフを投影する必要があります。


まず、Neo4j に保存されたグラフがメモリ内グラフに投影され、処理と分析が高速化されます。次に、グラフ アルゴリズムがメモリ内グラフで実行されます。オプションで、アルゴリズムの結果を Neo4j データベースに保存し直すこともできます。詳細については、ドキュメントを参照してください。
k 最近傍グラフを作成するには、すべてのエンティティをテキスト埋め込みとともに投影します。
G, result = gds.graph.project( "entities", # Graph name "__Entity__", # Node projection "*", # Relationship projection nodeProperties=["embedding"] # Configuration parameters )
グラフがentities名の下に投影されたので、グラフ アルゴリズムを実行できます。まず、 k 近傍グラフを構築します。k 近傍グラフの疎密に影響を与える最も重要な 2 つのパラメーターは、 similarityCutoffとtopKですtopKは、各ノードに対して検索する近傍の数で、最小値は 1 です。 similarityCutoff類似度がこのしきい値を下回る関係を除外します。ここでは、デフォルトのtopK 10 と、比較的高い類似度カットオフ 0.95 を使用します。0.95 などの高い類似度カットオフを使用すると、非常に類似したペアのみが一致と見なされ、誤検知が最小限に抑えられ、精度が向上します。


結果をナレッジ グラフではなく、投影されたメモリ内グラフに保存したいので、アルゴリズムのmutateモードを使用します。
similarity_threshold = 0.95 gds.knn.mutate( G, nodeProperties=['embedding'], mutateRelationshipType= 'SIMILAR', mutateProperty= 'score', similarityCutoff=similarity_threshold )
次のステップは、新たに推定された類似関係で接続されたエンティティのグループを識別することです。接続されたノードのグループを識別することは、ネットワーク分析で頻繁に行われるプロセスで、コミュニティ検出またはクラスタリングと呼ばれることが多く、密に接続されたノードのサブグループを見つけることが含まれます。この例では、接続の方向を無視しても、すべてのノードが接続されているグラフの部分を見つけるのに役立つ、弱接続コンポーネント アルゴリズムを使用します。


アルゴリズムのwriteモードを使用して、結果をデータベースに保存します (保存されたグラフ)。
gds.wcc.write( G, writeProperty="wcc", relationshipTypes=["SIMILAR"] )
テキスト埋め込みの比較は、重複の可能性があるものを見つけるのに役立ちますが、エンティティ解決プロセスの一部にすぎません。たとえば、Google と Apple は埋め込みスペースで非常に近いです ( ada-002埋め込みモデルを使用した場合のコサイン類似度は 0.96)。BMW と Mercedes Benz も同様です (コサイン類似度は 0.97)。テキスト埋め込みの類似度が高いのは良いスタートですが、さらに改善することができます。そのため、テキスト距離が 3 以下の単語のペアのみを許可する (つまり、文字のみを変更できる) 追加のフィルターを追加します。
word_edit_distance = 3 potential_duplicate_candidates = graph.query( """MATCH (e:`__Entity__`) WHERE size(e.id) > 3 // longer than 3 characters WITH e.wcc AS community, collect(e) AS nodes, count(*) AS count WHERE count > 1 UNWIND nodes AS node // Add text distance WITH distinct [n IN nodes WHERE apoc.text.distance(toLower(node.id), toLower(n.id)) < $distance OR node.id CONTAINS n.id | n.id] AS intermediate_results WHERE size(intermediate_results) > 1 WITH collect(intermediate_results) AS results // combine groups together if they share elements UNWIND range(0, size(results)-1, 1) as index WITH results, index, results[index] as result WITH apoc.coll.sort(reduce(acc = result, index2 IN range(0, size(results)-1, 1) | CASE WHEN index <> index2 AND size(apoc.coll.intersection(acc, results[index2])) > 0 THEN apoc.coll.union(acc, results[index2]) ELSE acc END )) as combinedResult WITH distinct(combinedResult) as combinedResult // extra filtering WITH collect(combinedResult) as allCombinedResults UNWIND range(0, size(allCombinedResults)-1, 1) as combinedResultIndex WITH allCombinedResults[combinedResultIndex] as combinedResult, combinedResultIndex, allCombinedResults WHERE NOT any(x IN range(0,size(allCombinedResults)-1,1) WHERE x <> combinedResultIndex AND apoc.coll.containsAll(allCombinedResults[x], combinedResult) ) RETURN combinedResult """, params={'distance': word_edit_distance})
この Cypher ステートメントは少し複雑で、その解釈はこのブログ記事の範囲を超えています。いつでも LLM に解釈を依頼できます。


さらに、単語距離のカットオフは、単一の数値ではなく単語の長さの関数にすることができ、実装はよりスケーラブルになる可能性があります。
重要なのは、マージする可能性のあるエンティティのグループを出力することです。マージする可能性のあるノードのリストは次のとおりです。
{'combinedResult': ['Sinn Fein', 'Sinn Féin']}, {'combinedResult': ['Government', 'Governments']}, {'combinedResult': ['Unreal Engine', 'Unreal_Engine']}, {'combinedResult': ['March 2016', 'March 2020', 'March 2022', 'March_2023']}, {'combinedResult': ['Humana Inc', 'Humana Inc.']}, {'combinedResult': ['New York Jets', 'New York Mets']}, {'combinedResult': ['Asia Pacific', 'Asia-Pacific', 'Asia_Pacific']}, {'combinedResult': ['Bengaluru', 'Mangaluru']}, {'combinedResult': ['US Securities And Exchange Commission', 'Us Securities And Exchange Commission']}, {'combinedResult': ['Jp Morgan', 'Jpmorgan']}, {'combinedResult': ['Brighton', 'Brixton']},
ご覧のとおり、私たちの解決方法は、一部のノード タイプでは他の方法よりもうまく機能します。簡単に調べたところ、人や組織ではうまく機能するようです。日付ではあまりうまく機能しません。定義済みのノード タイプを使用すれば、さまざまなノード タイプに対して異なるヒューリスティックを準備できます。この例では、定義済みのノード ラベルがないため、エンティティをマージするかどうかの最終決定を LLM に任せます。
まず、ノードのマージに関する最終決定を効果的にガイドし、通知するための LLM プロンプトを作成する必要があります。
system_prompt = """You are a data processing assistant. Your task is to identify duplicate entities in a list and decide which of them should be merged. The entities might be slightly different in format or content, but essentially refer to the same thing. Use your analytical skills to determine duplicates. Here are the rules for identifying duplicates: 1. Entities with minor typographical differences should be considered duplicates. 2. Entities with different formats but the same content should be considered duplicates. 3. Entities that refer to the same real-world object or concept, even if described differently, should be considered duplicates. 4. If it refers to different numbers, dates, or products, do not merge results """ user_template = """ Here is the list of entities to process: {entities} Please identify duplicates, merge them, and provide the merged list. """
構造化データ出力が予想される場合は、出力を手動で解析する必要がないように、常に LangChain のwith_structured_outputメソッドを使用します。
ここでは、出力をlist of listsとして定義します。各内部リストには、結合するエンティティが含まれます。この構造は、たとえば入力が[Sony, Sony Inc, Google, Google Inc]となるシナリオを処理するために使用されます。このような場合、「Sony」と「Sony Inc」を「Google」と「Google Inc」とは別々に結合します。
class DuplicateEntities(BaseModel): entities: List[str] = Field( description="Entities that represent the same object or real-world entity and should be merged" ) class Disambiguate(BaseModel): merge_entities: Optional[List[DuplicateEntities]] = Field( description="Lists of entities that represent the same object or real-world entity and should be merged" ) extraction_llm = ChatOpenAI(model_name="gpt-4o").with_structured_output( Disambiguate )
次に、LLM プロンプトを構造化出力と統合し、LangChain Expression Language (LCEL) 構文を使用してチェーンを作成し、それをdisambiguate関数内にカプセル化します。
extraction_chain = extraction_prompt | extraction_llm def entity_resolution(entities: List[str]) -> Optional[List[List[str]]]: return [ el.entities for el in extraction_chain.invoke({"entities": entities}).merge_entities ]
すべての潜在的な候補ノードをentity_resolution関数で実行し、それらをマージするかどうかを決定する必要があります。プロセスを高速化するために、LLM 呼び出しを再び並列化します。
merged_entities = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(entity_resolution, el['combinedResult']) for el in potential_duplicate_candidates ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): to_merge = future.result() if to_merge: merged_entities.extend(to_merge)
エンティティ解決の最終ステップでは、 entity_resolution LLM から結果を取得し、指定されたノードをマージしてデータベースに書き戻します。
graph.query(""" UNWIND $data AS candidates CALL { WITH candidates MATCH (e:__Entity__) WHERE e.id IN candidates RETURN collect(e) AS nodes } CALL apoc.refactor.mergeNodes(nodes, {properties: { description:'combine', `.*`: 'discard' }}) YIELD node RETURN count(*) """, params={"data": merged_entities})
このエンティティ解決は完璧ではありませんが、改善するための出発点となります。さらに、保持するエンティティを決定するロジックを改善することもできます。
要素の要約
次のステップでは、著者らは要素要約ステップを実行します。基本的に、すべてのノードと関係は、 エンティティ要約プロンプトを通過します。著者らは、このアプローチの斬新さと興味深さについて次のように述べています。
「全体的に、潜在的にノイズの多いグラフ構造内の均質なノードに豊富な説明テキストを使用することは、LLM の機能と、グローバルでクエリに重点を置いた要約のニーズの両方と一致しています。これらの特性は、下流の推論タスクに簡潔で一貫性のある知識トリプル (主語、述語、目的語) に依存する一般的な知識グラフと当社のグラフ インデックスを区別するものです。」
このアイデアは興味深いものです。テキストから主題とオブジェクトの ID または名前を抽出し、エンティティが複数のテキスト チャンクにまたがって出現する場合でも、関係を正しいエンティティにリンクできます。ただし、関係は 1 つのタイプに限定されません。代わりに、関係タイプは実際には自由形式のテキストであり、より豊富で微妙な情報を保持できます。
さらに、エンティティ情報は LLM を使用して要約されるため、この情報とエンティティをより効率的に埋め込み、インデックス付けして、より正確な検索が可能になります。
このより豊富で微妙な情報は、追加の、おそらく任意のノードおよびリレーションシップ プロパティを追加することでも保持できると主張する人もいるかもしれません。任意のノードおよびリレーションシップ プロパティに関する 1 つの問題は、LLM が異なるプロパティ名を使用したり、実行ごとにさまざまな詳細に焦点を当てたりする可能性があるため、情報を一貫して抽出することが難しい可能性があることです。
これらの問題の一部は、追加のタイプと説明情報を含む定義済みのプロパティ名を使用することで解決できます。その場合、それらのプロパティを定義するには分野の専門家が必要になり、LLM が定義済みの説明以外の重要な情報を抽出できる余地はほとんどありません。
より豊富な情報をナレッジグラフで表現する興味深いアプローチです。
要素要約ステップの潜在的な問題の 1 つは、グラフ内のすべてのエンティティと関係に対して LLM 呼び出しが必要になるため、拡張性が低いことです。グラフは比較的小さく、13,000 個のノードと 16,000 個の関係があります。このような小さなグラフでも、29,000 個の LLM 呼び出しが必要になり、各呼び出しで数百個のトークンが使用されるため、コストと時間がかかります。したがって、ここではこのステップを回避します。初期のテキスト処理中に抽出された説明プロパティは引き続き使用できます。
コミュニティの構築と要約
グラフ構築とインデックス作成プロセスの最終ステップでは、グラフ内のコミュニティを特定します。この文脈では、コミュニティとは、グラフの残りの部分よりも互いに密に接続されたノードのグループであり、相互作用または類似性のレベルが高いことを示します。次の視覚化は、コミュニティ検出結果の例を示しています。


これらのエンティティ コミュニティがクラスタリング アルゴリズムによって識別されると、LLM は各コミュニティの概要を生成し、個々の特性と関係についての洞察を提供します。
ここでも、Graph Data Science ライブラリを使用します。まず、メモリ内グラフを投影します。元の記事に正確に従うために、エンティティのグラフを無向重み付けネットワークとして投影します。このネットワークは、2 つのエンティティ間の接続の数を表します。
G, result = gds.graph.project( "communities", # Graph name "__Entity__", # Node projection { "_ALL_": { "type": "*", "orientation": "UNDIRECTED", "properties": {"weight": {"property": "*", "aggregation": "COUNT"}}, } }, )
著者らは、グラフ内のコミュニティを識別するために、階層的クラスタリング法であるライデンアルゴリズムを採用しました。階層的コミュニティ検出アルゴリズムを使用する利点の 1 つは、複数の粒度レベルでコミュニティを調査できることです。著者らは、各レベルですべてのコミュニティを要約し、グラフの構造を包括的に理解することを提案しています。
まず、弱連結コンポーネント (WCC) アルゴリズムを使用してグラフの接続性を評価します。このアルゴリズムはグラフ内の孤立したセクションを識別します。つまり、互いに接続されているがグラフの残りの部分とは接続されていないノードまたはコンポーネントのサブセットを検出します。これらのコンポーネントは、ネットワーク内の断片化を理解し、他のノードから独立したノードのグループを識別するのに役立ちます。WCC は、グラフの全体的な構造と接続性を分析するために不可欠です。
wcc = gds.wcc.stats(G) print(f"Component count: {wcc['componentCount']}") print(f"Component distribution: {wcc['componentDistribution']}") # Component count: 1119 # Component distribution: { # "min":1, # "p5":1, # "max":9109, # "p999":43, # "p99":19, # "p1":1, # "p10":1, # "p90":7, # "p50":2, # "p25":1, # "p75":4, # "p95":10, # "mean":11.3 }
WCC アルゴリズムの結果、1,119 個の異なるコンポーネントが特定されました。特に、最大のコンポーネントは 9,109 個のノードで構成されており、これは単一のスーパー コンポーネントが多数の小さな独立したコンポーネントと共存する実際のネットワークでは一般的です。最小のコンポーネントには 1 つのノードがあり、平均コンポーネント サイズは約 11.3 ノードです。
次に、GDS ライブラリでも利用可能な Leiden アルゴリズムを実行し、 includeIntermediateCommunitiesパラメータを有効にして、すべてのレベルのコミュニティを返して保存します。また、Leiden アルゴリズムの加重バリアントを実行するために、 relationshipWeightPropertyパラメータも追加しました。アルゴリズムのwriteモードを使用すると、結果がノード プロパティとして保存されます。
gds.leiden.write( G, writeProperty="communities", includeIntermediateCommunities=True, relationshipWeightProperty="weight", )
アルゴリズムは 5 つのレベルのコミュニティを識別し、最高レベル (コミュニティが最も大きい最小粒度レベル) には 1,188 のコミュニティ (1,119 個のコンポーネントとは対照的) があります。以下は、Gephi を使用して最後のレベルのコミュニティを視覚化したものです。


1,000 を超えるコミュニティを視覚化するのは困難です。それぞれのコミュニティに色を選択することさえ、事実上不可能です。しかし、それらは芸術的な表現として素晴らしいものになります。
これを基に、各コミュニティごとに個別のノードを作成し、その階層構造を相互接続されたグラフとして表します。後で、コミュニティの概要やその他の属性もノードのプロパティとして保存します。
graph.query(""" MATCH (e:`__Entity__`) UNWIND range(0, size(e.communities) - 1 , 1) AS index CALL { WITH e, index WITH e, index WHERE index = 0 MERGE (c:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET c.level = index MERGE (e)-[:IN_COMMUNITY]->(c) RETURN count(*) AS count_0 } CALL { WITH e, index WITH e, index WHERE index > 0 MERGE (current:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET current.level = index MERGE (previous:`__Community__` {id: toString(index - 1) + '-' + toString(e.communities[index - 1])}) ON CREATE SET previous.level = index - 1 MERGE (previous)-[:IN_COMMUNITY]->(current) RETURN count(*) AS count_1 } RETURN count(*) """)
著者らは、コミュニティ内のエンティティが出現する個別のテキストチャンクの数を示すcommunity rankも導入しています。
graph.query(""" MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(:__Entity__)<-[:MENTIONS]-(d:Document) WITH c, count(distinct d) AS rank SET c.community_rank = rank; """)
ここで、多くの中間コミュニティが上位レベルで統合されるサンプルの階層構造を調べてみましょう。コミュニティは重複していません。つまり、各エンティティは各レベルで正確に 1 つのコミュニティに属します。


この画像は、ライデン コミュニティ検出アルゴリズムによって生成された階層構造を表しています。紫色のノードは個々のエンティティを表し、オレンジ色のノードは階層コミュニティを表しています。
階層は、これらのエンティティがさまざまなコミュニティに編成され、より小さなコミュニティがより高いレベルでより大きなコミュニティに統合されることを示しています。
次に、より小さなコミュニティがより高いレベルでどのように統合されるかを見てみましょう。

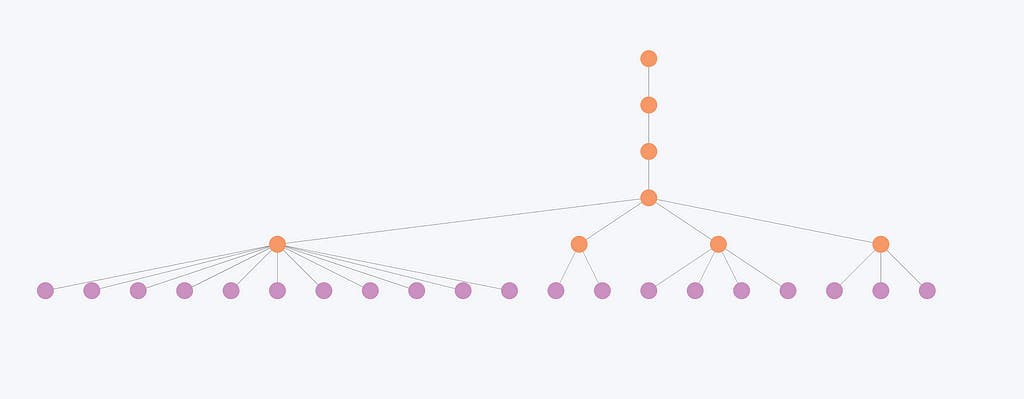
この図は、つながりの少ないエンティティと、その結果として小さなコミュニティでは、レベル間での変化が最小限であることを示しています。たとえば、ここでのコミュニティ構造は最初の 2 つのレベルでのみ変化し、最後の 3 つのレベルでは同一のままです。その結果、全体的な組織は異なる層で大幅に変化しないため、これらのエンティティでは階層レベルが冗長であるように見えることがよくあります。
コミュニティの数、規模、レベルの違いを詳しく見てみましょう。
community_size = graph.query( """ MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(e:__Entity__) WITH c, count(distinct e) AS entities RETURN split(c.id, '-')[0] AS level, entities """ ) community_size_df = pd.DataFrame.from_records(community_size) percentiles_data = [] for level in community_size_df["level"].unique(): subset = community_size_df[community_size_df["level"] == level]["entities"] num_communities = len(subset) percentiles = np.percentile(subset, [25, 50, 75, 90, 99]) percentiles_data.append( [ level, num_communities, percentiles[0], percentiles[1], percentiles[2], percentiles[3], percentiles[4], max(subset) ] ) # Create a DataFrame with the percentiles percentiles_df = pd.DataFrame( percentiles_data, columns=[ "Level", "Number of communities", "25th Percentile", "50th Percentile", "75th Percentile", "90th Percentile", "99th Percentile", "Max" ], ) percentiles_df


元の実装では、すべてのレベルのコミュニティが要約されていました。私たちの場合、コミュニティは 8,590 個になり、結果として LLM 呼び出しも 8,590 個になります。階層的なコミュニティ構造によっては、すべてのレベルを要約する必要はないと私は主張します。たとえば、最後のレベルと最後から 2 番目のレベルの違いは、わずか 4 つのコミュニティ (1,192 と 1,188) です。したがって、冗長な要約が多数作成されることになります。1 つの解決策は、変更されないさまざまなレベルのコミュニティに対して単一の要約を作成できる実装を作成することです。もう 1 つの解決策は、変更されないコミュニティ階層を折りたたむことです。
また、メンバーが 1 人だけのコミュニティを要約するかどうかはわかりません。あまり価値や情報を提供しない可能性があるからです。ここでは、レベル 0、1、4 のコミュニティを要約します。まず、データベースからそれらの情報を取得する必要があります。
community_info = graph.query(""" MATCH (c:`__Community__`)<-[:IN_COMMUNITY*]-(e:__Entity__) WHERE c.level IN [0,1,4] WITH c, collect(e ) AS nodes WHERE size(nodes) > 1 CALL apoc.path.subgraphAll(nodes[0], { whitelistNodes:nodes }) YIELD relationships RETURN c.id AS communityId, [n in nodes | {id: n.id, description: n.description, type: [el in labels(n) WHERE el <> '__Entity__'][0]}] AS nodes, [r in relationships | {start: startNode(r).id, type: type(r), end: endNode(r).id, description: r.description}] AS rels """)
現在、コミュニティ情報の構造は次のとおりです。
{'communityId': '0-6014', 'nodes': [{'id': 'Darrell Hughes', 'description': None, type:"Person"}, {'id': 'Chief Pilot', 'description': None, type: "Person"}, ... }], 'rels': [{'start': 'Ryanair Dac', 'description': 'Informed of the change in chief pilot', 'type': 'INFORMED', 'end': 'Irish Aviation Authority'}, {'start': 'Ryanair Dac', 'description': 'Dismissed after internal investigation found unacceptable behaviour', 'type': 'DISMISSED', 'end': 'Aidan Murray'}, ... ]}
次に、コミュニティの要素によって提供される情報に基づいて自然言語の要約を生成する LLM プロンプトを準備する必要があります。 研究者が使用したプロンプトからインスピレーションを得ることができます。
著者らはコミュニティを要約しただけでなく、それぞれのコミュニティに関する調査結果も生成しました。調査結果とは、特定のイベントや情報に関する簡潔な情報と定義できます。その一例を次に示します。
"summary": "Abila City Park as the central location", "explanation": "Abila City Park is the central entity in this community, serving as the location for the POK rally. This park is the common link between all other entities, suggesting its significance in the community. The park's association with the rally could potentially lead to issues such as public disorder or conflict, depending on the nature of the rally and the reactions it provokes. [records: Entities (5), Relationships (37, 38, 39, 40)]"
私の直感では、エンティティと関係性を抽出する場合と同様に、1 回のパスだけで検出結果を抽出しても、必要なほど包括的ではない可能性があります。
さらに、ローカルまたはグローバル検索リトリーバーのコード内でのそれらの使用に関する参照や例は見つかりませんでした。そのため、この例では調査結果の抽出を控えます。または、学者がよく言うように、「この演習は読者に委ねられています」。さらに、一見すると調査結果に似ている主張または共変量情報の抽出もスキップしました。
コミュニティの概要を作成するために使用するプロンプトは非常に簡単です。
community_template = """Based on the provided nodes and relationships that belong to the same graph community, generate a natural language summary of the provided information: {community_info} Summary:""" # noqa: E501 community_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Given an input triples, generate the information summary. No pre-amble.", ), ("human", community_template), ] ) community_chain = community_prompt | llm | StrOutputParser()
残っているのは、コミュニティ表現を文字列に変換して、JSON トークンのオーバーヘッドを回避し、チェーンを関数としてラップすることでトークンの数を減らすことだけです。
def prepare_string(data): nodes_str = "Nodes are:\n" for node in data['nodes']: node_id = node['id'] node_type = node['type'] if 'description' in node and node['description']: node_description = f", description: {node['description']}" else: node_description = "" nodes_str += f"id: {node_id}, type: {node_type}{node_description}\n" rels_str = "Relationships are:\n" for rel in data['rels']: start = rel['start'] end = rel['end'] rel_type = rel['type'] if 'description' in rel and rel['description']: description = f", description: {rel['description']}" else: description = "" rels_str += f"({start})-[:{rel_type}]->({end}){description}\n" return nodes_str + "\n" + rels_str def process_community(community): stringify_info = prepare_string(community) summary = community_chain.invoke({'community_info': stringify_info}) return {"community": community['communityId'], "summary": summary}
これで、選択したレベルのコミュニティ サマリーを生成できます。ここでも、実行を高速化するために呼び出しを並列化します。
summaries = [] with ThreadPoolExecutor() as executor: futures = {executor.submit(process_community, community): community for community in community_info} for future in tqdm(as_completed(futures), total=len(futures), desc="Processing communities"): summaries.append(future.result())
私が言及しなかった点の 1 つは、著者らがコミュニティ情報を入力する際にコンテキスト サイズを超える潜在的な問題にも対処していることです。グラフが拡大するにつれて、コミュニティも大幅に拡大する可能性があります。私たちの場合、最大のコミュニティは 545 人のメンバーで構成されていました。GPT-4o のコンテキスト サイズは 100,000 トークンを超えるため、この手順をスキップすることにしました。
最後のステップとして、コミュニティの概要をデータベースに保存します。
graph.query(""" UNWIND $data AS row MERGE (c:__Community__ {id:row.community}) SET c.summary = row.summary """, params={"data": summaries})
最終的なグラフ構造:


グラフには、元のドキュメント、抽出されたエンティティと関係、階層的なコミュニティ構造と概要が含まれるようになりました。
まとめ
「From Local to Global」論文の著者は、GraphRAG への新しいアプローチを実証する素晴らしい仕事をしました。さまざまなドキュメントからの情報を組み合わせて、階層的な知識グラフ構造に要約する方法を示しています。
明示的に言及されていないことの 1 つは、構造化データ ソースをグラフに統合することもできるということです。入力は、非構造化テキストのみに限定される必要はありません。
彼らの抽出アプローチで特に評価したいのは、ノードと関係の両方の説明をキャプチャすることです。説明により、LLM は、すべてをノード ID と関係タイプだけに減らすよりも多くの情報を保持できます。
さらに、著者らは、テキストを 1 回抽出するだけではすべての関連情報が取得されない可能性があることを示し、必要に応じて複数の抽出を実行するロジックを導入しています。著者らはまた、グラフ コミュニティに対して要約を実行するための興味深いアイデアを提示し、複数のデータ ソースにわたって凝縮されたトピック情報を埋め込み、インデックスを作成できるようにしています。
次のブログ投稿では、ローカルおよびグローバル検索リトリーバーの実装について説明し、指定されたグラフ構造に基づいて実装できる他のアプローチについて説明します。
いつものように、コードはGitHubで入手できます。
今回は、データベース ダンプもアップロードしたので、結果を調べて、さまざまなリトリーバー オプションを試すことができます。
また、このダンプを永久に無料の Neo4j AuraDB インスタンスにインポートすることもできます。検索探索にはグラフ データ サイエンス アルゴリズムは必要なく、グラフ パターン マッチング、ベクター、および全文インデックスだけが必要なので、これを使用できます。
すべての GenAI フレームワークおよび実用的なグラフ アルゴリズムとの Neo4j 統合の詳細については、私の著書「データ サイエンスのためのグラフ アルゴリズム」をご覧ください。
このトピックについて詳しく知るには、11 月 7 日に開催されるインテリジェント アプリ、ナレッジ グラフ、AI に関する無料の仮想開発者会議 NODES 2024 にご参加ください。今すぐ登録してください。








