
























Мене завжди цікавлять нові підходи до впровадження генерації з доповненим пошуком (RAG) над графіками, яку часто називають GraphRAG. Однак, здається, кожен має на увазі іншу реалізацію, коли чує термін GraphRAG. У цій публікації блогу ми детально зануримося в статтю « Від локального до глобального GraphRAG » і впровадження дослідників Microsoft. Ми розглянемо побудову графа знань і частину узагальнення, а ретривери залишимо для наступної публікації в блозі. Дослідники були такі люб’язні, що надали нам сховище коду, а також у них є сторінка проекту .
Підхід, використаний у згаданій вище статті, досить цікавий. Наскільки я розумію, це передбачає використання графа знань як крок у конвеєрі для конденсації та об’єднання інформації з кількох джерел. Вилучення сутностей і зв’язків із тексту не є чимось новим. Однак автори представляють нову (принаймні для мене) ідею підсумовування конденсованої графової структури та інформації як тексту природною мовою. Конвеєр починається з введення тексту з документів, які обробляються для створення графіка. Потім графік перетворюється назад у текст природною мовою, де згенерований текст містить стислу інформацію про конкретні сутності або спільноти графів, які раніше були розповсюджені в кількох документах.


На дуже високому рівні входом до конвеєра GraphRAG є вихідні документи, що містять різноманітну інформацію. Документи обробляються за допомогою LLM для отримання структурованої інформації про сутності, які з’являються в документах, разом із їхніми зв’язками. Ця витягнута структурована інформація потім використовується для побудови графіка знань.
Перевага використання представлення даних у графі знань полягає в тому, що він може швидко й просто поєднувати інформацію з кількох документів або джерел даних про певні сутності. Як згадувалося, граф знань — це не єдине представлення даних. Після того, як граф знань було побудовано, вони використовують комбінацію алгоритмів графів і підказок LLM для створення зведень природною мовою спільнот сутностей, знайдених у графі знань.
Потім ці зведення містять згорнуту інформацію, яка поширюється на численні джерела даних і документи для окремих організацій і спільнот.
Для більш детального розуміння конвеєра ми можемо звернутися до покрокового опису, наданого в оригінальній статті.


Етапи в конвеєрі — зображення з паперу GraphRAG , ліцензовано за CC BY 4.0
Нижче наведено короткий опис конвеєра, який ми будемо використовувати для відтворення їхнього підходу за допомогою Neo4j і LangChain.
Індексування — Створення графіків
- Вихідні документи до текстових фрагментів : вихідні документи розбиваються на менші текстові фрагменти для обробки.
- Фрагменти тексту до екземплярів елементів : кожен фрагмент тексту аналізується для виділення сутностей і зв’язків, створюючи список кортежів, що представляють ці елементи.
- Екземпляри елементів до резюме елементів : LLM підсумовує витягнуті сутності та зв’язки в описові текстові блоки для кожного елемента.
- Підсумки елементів для спільнот графів : ці підсумки об’єктів утворюють граф, який потім розбивається на спільноти за допомогою алгоритмів, таких як Leiden, для ієрархічної структури.
- Створення графіка між спільнотами та підсумками спільнот : резюме кожної спільноти генеруються за допомогою LLM, щоб зрозуміти глобальну тематичну структуру та семантику набору даних.
Пошук — Відповідь
- Резюме спільноти до глобальних відповідей : Резюме спільноти використовується для відповіді на запит користувача шляхом створення проміжних відповідей, які потім об’єднуються в остаточну глобальну відповідь.
Зауважте, що моя реалізація була виконана до того, як їх код був доступний, тому можуть бути невеликі відмінності в базовому підході або підказках LLM, які використовуються. Я спробую пояснити ці відмінності по ходу.
Код доступний на GitHub .
Налаштування середовища Neo4j
Ми будемо використовувати Neo4j як базове сховище графів. Найпростіший спосіб розпочати — скористатися безкоштовним екземпляром Neo4j Sandbox , який пропонує хмарні екземпляри бази даних Neo4j із встановленим плагіном Graph Data Science. Крім того, ви можете налаштувати локальний екземпляр бази даних Neo4j, завантаживши програму Neo4j Desktop і створивши локальний екземпляр бази даних. Якщо ви використовуєте локальну версію, обов’язково встановіть плагіни APOC і GDS. Для налаштувань виробництва ви можете використовувати платний керований екземпляр AuraDS (Data Science), який надає плагін GDS.
Ми починаємо зі створення екземпляра Neo4jGraph , який є зручною оболонкою, яку ми додали до LangChain:
from langchain_community.graphs import Neo4jGraph os.environ["NEO4J_URI"] = "bolt://44.202.208.177:7687" os.environ["NEO4J_USERNAME"] = "neo4j" os.environ["NEO4J_PASSWORD"] = "mast-codes-trails" graph = Neo4jGraph(refresh_schema=False)Набір даних
Ми будемо використовувати набір даних статей новин, який я створив деякий час тому за допомогою API Diffbot. Я завантажив його на свій GitHub для легшого повторного використання:
news = pd.read_csv( "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/news_articles.csv" ) news["tokens"] = [ num_tokens_from_string(f"{row['title']} {row['text']}") for i, row in news.iterrows() ] news.head()
Давайте розглянемо перші пару рядків із набору даних.


У нас доступні заголовок і текст статей, а також дата їх публікації та кількість токенів за допомогою бібліотеки tiktoken.
Розбиття тексту
Крок фрагментації тексту є вирішальним і суттєво впливає на подальші результати. Автори статті виявили, що використання менших фрагментів тексту призводить до загального вилучення більшої кількості об’єктів.


Кількість об’єктів вилучення з урахуванням розміру фрагментів тексту — Зображення з паперу GraphRAG , ліцензоване згідно з CC BY 4.0
Як бачите, використання фрагментів тексту з 2400 токенів призводить до меншої кількості вилучених об’єктів, ніж у випадку використання 600 токенів. Крім того, вони виявили, що LLM можуть не витягувати всі сутності під час першого запуску. У цьому випадку вони вводять евристику для виконання вилучення кілька разів. Про це ми поговоримо докладніше в наступному розділі.
Однак завжди є компроміси. Використання менших фрагментів тексту може призвести до втрати контексту та кореференцій конкретних сутностей, розподілених по документах. Наприклад, якщо в документі згадуються «Іван» і «він» в окремих реченнях, розбиття тексту на менші фрагменти може зробити незрозумілим, що «він» стосується Івана. Деякі проблеми кореференції можна вирішити за допомогою стратегії фрагментації тексту, що перекривається, але не всі.
Розглянемо розмір текстів нашої статті:
sns.histplot(news["tokens"], kde=False) plt.title('Distribution of chunk sizes') plt.xlabel('Token count') plt.ylabel('Frequency') plt.show()


Розподіл кількості токенів статті є приблизно нормальним, з піком близько 400 токенів. Частота фрагментів поступово зростає до цього піку, а потім симетрично зменшується, вказуючи на те, що більшість фрагментів тексту знаходяться поблизу позначки 400 токенів.
У зв’язку з цим розповсюдженням ми не виконуватимемо жодного фрагментування тексту, щоб уникнути проблем з кореференцією. За замовчуванням проект GraphRAG використовує розмір фрагментів у 300 токенів із 100 токенами перекриття.
Вилучення вузлів і зв’язків
Наступним кроком є конструювання знань із фрагментів тексту. У цьому випадку використання ми використовуємо LLM для отримання структурованої інформації у формі вузлів і зв’язків із тексту. Ви можете переглянути підказку LLM, яку автори використали в статті. У них є підказки LLM, де ми можемо попередньо визначити мітки вузлів, якщо це необхідно, але за замовчуванням це необов’язково. Крім того, витягнуті зв’язки в оригінальній документації насправді не мають типу, лише опис. Я думаю, причина цього вибору полягає в тому, щоб дозволити LLM витягувати та зберігати багатшу та детальнішу інформацію у вигляді зв’язків. Але важко мати чистий граф знань без специфікацій типу зв’язку (опис може входити до властивості).
У нашій реалізації ми будемо використовувати LLMGraphTransformer , який доступний у бібліотеці LangChain. Замість використання чистої оперативної інженерії, як це робиться у статті статті, LLMGraphTransformer використовує вбудовану підтримку виклику функції для вилучення структурованої інформації (структурований вихід LLM у LangChain). Ви можете перевірити системне повідомлення :
from langchain_experimental.graph_transformers import LLMGraphTransformer from langchain_openai import ChatOpenAI llm = ChatOpenAI(temperature=0, model_name="gpt-4o") llm_transformer = LLMGraphTransformer( llm=llm, node_properties=["description"], relationship_properties=["description"] ) def process_text(text: str) -> List[GraphDocument]: doc = Document(page_content=text) return llm_transformer.convert_to_graph_documents([doc])
У цьому прикладі ми використовуємо GPT-4o для вилучення графіка. Автори конкретно доручають LLM витягувати сутності та зв'язки та їхні описи . За допомогою реалізації LangChain ви можете використовувати атрибути node_properties і relationship_properties , щоб указати, які властивості вузла або зв’язку ви хочете витягти з LLM.
Різниця з реалізацією LLMGraphTransformer полягає в тому, що всі властивості вузла або зв’язку є необов’язковими, тому не всі вузли матимуть властивість description . Якби ми хотіли, ми могли б визначити спеціальне вилучення, яке має обов’язкову властивість description , але ми пропустимо це в цій реалізації.
Ми розпаралелюємо запити, щоб зробити вилучення графіка швидшим і зберегти результати в Neo4j:
MAX_WORKERS = 10 NUM_ARTICLES = 2000 graph_documents = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(process_text, f"{row['title']} {row['text']}") for i, row in news.head(NUM_ARTICLES).iterrows() ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): graph_document = future.result() graph_documents.extend(graph_document) graph.add_graph_documents( graph_documents, baseEntityLabel=True, include_source=True )
У цьому прикладі ми витягуємо інформацію графіка з 2000 статей і зберігаємо результати в Neo4j. Ми вилучили близько 13 000 сутностей і 16 000 відносин. Ось приклад витягнутого документа на графіку.


Це займає близько 35 (+/- 5) хвилин, щоб завершити вилучення, і коштує близько 30 доларів США з GPT-4o.
На цьому кроці автори вводять евристику, щоб вирішити, чи потрібно витягувати інформацію графа більш ніж за один прохід. Для простоти ми зробимо лише один прохід. Однак, якщо ми хочемо зробити кілька проходів, ми могли б помістити перші результати вилучення як історію розмов і просто вказати LLM, що багато об’єктів бракує , і він повинен витягти більше, як це роблять автори GraphRAG.
Раніше я згадував, наскільки важливий розмір фрагмента тексту та як він впливає на кількість вилучених об’єктів. Оскільки ми не виконували додаткового фрагментування тексту, ми можемо оцінити розподіл витягнутих об’єктів на основі розміру фрагмента тексту:
entity_dist = graph.query( """ MATCH (d:Document) RETURN d.text AS text, count {(d)-[:MENTIONS]->()} AS entity_count """ ) entity_dist_df = pd.DataFrame.from_records(entity_dist) entity_dist_df["token_count"] = [ num_tokens_from_string(str(el)) for el in entity_dist_df["text"] ] # Scatter plot with regression line sns.lmplot( x="token_count", y="entity_count", data=entity_dist_df, line_kws={"color": "red"} ) plt.title("Entity Count vs Token Count Distribution") plt.xlabel("Token Count") plt.ylabel("Entity Count") plt.show()


Діаграма розсіювання показує, що, незважаючи на наявність позитивної тенденції, позначеної червоною лінією, зв’язок сублінійний. Більшість точок даних кластеризуються при меншій кількості об’єктів, навіть якщо кількість токенів збільшується. Це вказує на те, що кількість вилучених об’єктів не масштабується пропорційно розміру фрагментів тексту. Хоча деякі викиди існують, загальна закономірність показує, що більша кількість токенів не завжди призводить до більшої кількості об’єктів. Це підтверджує висновок авторів про те, що менші розміри фрагментів тексту дозволять отримати більше інформації.
Я також подумав, що було б цікаво перевірити розподіл вузлових ступенів побудованого графіка. Наведений нижче код отримує та візуалізує розподіли ступенів вузлів:
degree_dist = graph.query( """ MATCH (e:__Entity__) RETURN count {(e)-[:!MENTIONS]-()} AS node_degree """ ) degree_dist_df = pd.DataFrame.from_records(degree_dist) # Calculate mean and median mean_degree = np.mean(degree_dist_df['node_degree']) percentiles = np.percentile(degree_dist_df['node_degree'], [25, 50, 75, 90]) # Create a histogram with a logarithmic scale plt.figure(figsize=(12, 6)) sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue') # Use a logarithmic scale for the x-axis plt.yscale('log') # Adding labels and title plt.xlabel('Node Degree') plt.ylabel('Count (log scale)') plt.title('Node Degree Distribution') # Add mean, median, and percentile lines plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'Mean: {mean_degree:.2f}') plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25th Percentile: {percentiles[0]:.2f}') plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50th Percentile: {percentiles[1]:.2f}') plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75th Percentile: {percentiles[2]:.2f}') plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90th Percentile: {percentiles[3]:.2f}') # Add legend plt.legend() # Show the plot plt.show()


Розподіл ступенів вузлів відповідає степеневому закону, що вказує на те, що більшість вузлів мають дуже мало зв’язків, тоді як кілька вузлів мають високий рівень зв’язку. Середній ступінь становить 2,45, а медіана — 1,00, що показує, що більше половини вузлів мають лише одне з’єднання. Більшість вузлів (75 відсотків) мають два або менше з’єднань, а 90 відсотків — п’ять або менше. Такий розподіл є типовим для багатьох мереж реального світу, де невелика кількість концентраторів має багато з’єднань, а більшість вузлів – небагато.
Оскільки описи вузлів і зв’язків не є обов’язковими властивостями, ми також перевіримо, скільки було вилучено:
graph.query(""" MATCH (n:`__Entity__`) RETURN "node" AS type, count(*) AS total_count, count(n.description) AS non_null_descriptions UNION ALL MATCH (n)-[r:!MENTIONS]->() RETURN "relationship" AS type, count(*) AS total_count, count(r.description) AS non_null_descriptions """)
Результати показують, що 5926 вузлів із 12994 (45,6 відсотка) мають властивість опису. З іншого боку, тільки 5569 відносин з 15921 (35 відсотків) мають таку властивість.
Зауважте, що через ймовірнісний характер LLM, числа можуть відрізнятися для різних прогонів і різних вихідних даних, LLM і підказок.
Розв’язання суб’єкта
Розділення сутностей (усунення дублікатів) має вирішальне значення під час побудови графів знань, оскільки воно гарантує унікальне й точне представлення кожної сутності, запобігаючи повторюванню та об’єднанню записів, які посилаються на ту саму сутність реального світу. Цей процес необхідний для підтримки цілісності та узгодженості даних у межах графіка. Без вирішення сутностей графи знань страждатимуть від фрагментованих і суперечливих даних, що призведе до помилок і ненадійної інформації.


Це зображення демонструє, як одна реальна сутність може відображатися під дещо різними назвами в різних документах і, відповідно, на нашому графіку.
Крім того, розріджені дані стають серйозною проблемою без вирішення сутності. Неповні або часткові дані з різних джерел можуть призвести до розрізнених і непов’язаних частин інформації, що ускладнює формування узгодженого та всебічного розуміння сутностей. Точне розпізнавання сутностей вирішує це шляхом консолідації даних, заповнення прогалин і створення уніфікованого подання кожної сутності.


До/після використання Senzing Enity Resolution для підключення офшорних витоків даних Міжнародного консорціуму журналістів-розслідувачів (ICIJ) — зображення від Paco Nathan
Ліва частина візуалізації представляє розріджений і незв’язаний графік. Однак, як показано на правій стороні, такий графік може стати добре пов’язаним із ефективним розпізнаванням об’єктів.
Загалом, розпізнавання сутностей підвищує ефективність пошуку та інтеграції даних, забезпечуючи цілісне уявлення про інформацію з різних джерел. Зрештою, це дає змогу ефективніше відповідати на запитання на основі надійного та повного графіка знань.
На жаль, автори статті GraphRAG не включили жодного коду вирішення сутностей у своє репо, хоча вони згадують про це у своїй статті. Однією з причин виключення цього коду може бути те, що важко реалізувати надійне та добре продуктивне вирішення сутностей для будь-якого заданого домену. Ви можете застосувати власну евристику для різних вузлів, коли маєте справу з попередньо визначеними типами вузлів (якщо вони не визначені заздалегідь, вони недостатньо узгоджені, як-от компанія, організація, бізнес тощо). Однак, якщо мітки або типи вузлів невідомі заздалегідь, як у нашому випадку, це стає ще більш складною проблемою. Тим не менш, ми реалізуємо версію розділення сутностей у нашому проекті тут, поєднуючи вбудовування тексту та алгоритми графів із відстанню між словами та LLM.


Наш процес усунення юридичних осіб включає такі кроки:
- Сутності на графіку — починайте з усіх сутностей на графіку.
- K-найближчий граф — побудуйте k-граф найближчих сусідів, з’єднуючи подібні сутності на основі вставлення тексту.
- Компоненти зі слабким зв’язком — визначте компоненти зі слабким зв’язком у k-найближчому графі, групуючи сутності, які ймовірно будуть подібними. Додайте крок фільтрації відстані слова після визначення цих компонентів.
- Оцінка LLM — використовуйте LLM, щоб оцінити ці компоненти та вирішити, чи слід об’єднати організації в межах кожного компонента, що призведе до остаточного рішення щодо розв’язання організації (наприклад, об’єднання «Silicon Valley Bank» і «Silicon_Valley_Bank» і відхилення злиття для різних такі дати, як «16 вересня 2023» і «2 вересня 2023»).
Ми починаємо з обчислення вбудованих текстів для властивостей імені та опису сутностей. Щоб досягти цього, ми можемо використати метод from_existing_graph в інтеграції Neo4jVector у LangChain:
vector = Neo4jVector.from_existing_graph( OpenAIEmbeddings(), node_label='__Entity__', text_node_properties=['id', 'description'], embedding_node_property='embedding' )
Ми можемо використовувати ці вкладення, щоб знайти потенційних кандидатів, подібних на основі косинусної відстані цих вкладень. Ми будемо використовувати алгоритми графів, доступні в бібліотеці Graph Data Science (GDS) ; тому ми можемо використовувати клієнт GDS Python для зручності використання Python:
from graphdatascience import GraphDataScience gds = GraphDataScience( os.environ["NEO4J_URI"], auth=(os.environ["NEO4J_USERNAME"], os.environ["NEO4J_PASSWORD"]) )
Якщо ви не знайомі з бібліотекою GDS, нам спочатку потрібно спроектувати граф у пам’яті, перш ніж ми зможемо виконувати будь-які алгоритми графів.


По-перше, збережений графік Neo4j проектується в граф у пам’яті для швидшої обробки та аналізу. Далі алгоритм графа виконується на графі в пам’яті. За бажанням результати алгоритму можна зберігати назад у базі даних Neo4j. Дізнайтеся більше про це в документації .
Щоб створити k-граф найближчих сусідів, ми спроектуємо всі сутності разом із їхніми вбудованими текстами:
G, result = gds.graph.project( "entities", # Graph name "__Entity__", # Node projection "*", # Relationship projection nodeProperties=["embedding"] # Configuration parameters )
Тепер, коли графік проектується під іменем entities , ми можемо виконувати алгоритми для графа. Ми почнемо з побудови k-найближчого графіка . Двома найважливішими параметрами, що впливають на те, наскільки розрідженим чи щільним буде k-найближчий графік, є similarityCutoff і topK . topK — це кількість сусідів, які потрібно знайти для кожного вузла, з мінімальним значенням 1. similarityCutoff відфільтровує зв’язки зі схожістю нижче цього порогу. Тут ми будемо використовувати стандартний topK 10 і відносно високу межу подібності 0,95. Використання високої межі схожості, наприклад 0,95, гарантує, що тільки дуже подібні пари вважаються збігами, мінімізуючи помилкові спрацьовування та покращуючи точність.


Оскільки ми хочемо зберегти результати в спроектованому графі в пам’яті замість графа знань, ми використаємо режим mutate алгоритму:
similarity_threshold = 0.95 gds.knn.mutate( G, nodeProperties=['embedding'], mutateRelationshipType= 'SIMILAR', mutateProperty= 'score', similarityCutoff=similarity_threshold )
Наступним кроком є ідентифікація груп об’єктів, які пов’язані з нововиявленими зв’язками подібності. Ідентифікація груп підключених вузлів є частим процесом у мережевому аналізі, який часто називають виявленням спільноти або кластеризацією , який передбачає пошук підгруп щільно підключених вузлів. У цьому прикладі ми використаємо алгоритм слабко зв’язаних компонентів , який допомагає знайти частини графа, де всі вузли з’єднані, навіть якщо ми ігноруємо напрямок з’єднань.


Ми використовуємо режим write алгоритму для збереження результатів у базі даних (збережений графік):
gds.wcc.write( G, writeProperty="wcc", relationshipTypes=["SIMILAR"] )
Порівняння вставлення тексту допомагає знайти потенційні дублікати, але це лише частина процесу вирішення сутності. Наприклад, Google і Apple дуже близькі в просторі вбудовування (подібність косинуса 0,96 за допомогою моделі вбудовування ada-002 ). Те ж саме стосується BMW і Mercedes Benz (косинус подібності 0,97). Висока схожість вставлення тексту — хороший початок, але ми можемо його покращити. Тому ми додамо додатковий фільтр, який дозволяє лише пари слів із текстовою відстанню до трьох або менше (це означає, що можна змінювати лише символи):
word_edit_distance = 3 potential_duplicate_candidates = graph.query( """MATCH (e:`__Entity__`) WHERE size(e.id) > 3 // longer than 3 characters WITH e.wcc AS community, collect(e) AS nodes, count(*) AS count WHERE count > 1 UNWIND nodes AS node // Add text distance WITH distinct [n IN nodes WHERE apoc.text.distance(toLower(node.id), toLower(n.id)) < $distance OR node.id CONTAINS n.id | n.id] AS intermediate_results WHERE size(intermediate_results) > 1 WITH collect(intermediate_results) AS results // combine groups together if they share elements UNWIND range(0, size(results)-1, 1) as index WITH results, index, results[index] as result WITH apoc.coll.sort(reduce(acc = result, index2 IN range(0, size(results)-1, 1) | CASE WHEN index <> index2 AND size(apoc.coll.intersection(acc, results[index2])) > 0 THEN apoc.coll.union(acc, results[index2]) ELSE acc END )) as combinedResult WITH distinct(combinedResult) as combinedResult // extra filtering WITH collect(combinedResult) as allCombinedResults UNWIND range(0, size(allCombinedResults)-1, 1) as combinedResultIndex WITH allCombinedResults[combinedResultIndex] as combinedResult, combinedResultIndex, allCombinedResults WHERE NOT any(x IN range(0,size(allCombinedResults)-1,1) WHERE x <> combinedResultIndex AND apoc.coll.containsAll(allCombinedResults[x], combinedResult) ) RETURN combinedResult """, params={'distance': word_edit_distance})
Це твердження Cypher є трохи складнішим, і його тлумачення виходить за рамки цієї публікації в блозі. Ви завжди можете попросити LLM інтерпретувати його.


Крім того, відсікання відстані слова може бути функцією довжини слова замість одного числа, і реалізація може бути більш масштабованою.
Важливо те, що він виводить групи потенційних об’єктів, які ми можемо захотіти об’єднати. Ось список потенційних вузлів для злиття:
{'combinedResult': ['Sinn Fein', 'Sinn Féin']}, {'combinedResult': ['Government', 'Governments']}, {'combinedResult': ['Unreal Engine', 'Unreal_Engine']}, {'combinedResult': ['March 2016', 'March 2020', 'March 2022', 'March_2023']}, {'combinedResult': ['Humana Inc', 'Humana Inc.']}, {'combinedResult': ['New York Jets', 'New York Mets']}, {'combinedResult': ['Asia Pacific', 'Asia-Pacific', 'Asia_Pacific']}, {'combinedResult': ['Bengaluru', 'Mangaluru']}, {'combinedResult': ['US Securities And Exchange Commission', 'Us Securities And Exchange Commission']}, {'combinedResult': ['Jp Morgan', 'Jpmorgan']}, {'combinedResult': ['Brighton', 'Brixton']},
Як бачите, наш підхід до вирішення працює краще для деяких типів вузлів, ніж для інших. Виходячи з швидкого огляду, здається, що це краще працює для людей та організацій, тоді як це досить погано для побачень. Якби ми використовували попередньо визначені типи вузлів, ми могли б підготувати різні евристики для різних типів вузлів. У цьому прикладі ми не маємо попередньо визначених міток вузлів, тому ми звернемося до LLM, щоб прийняти остаточне рішення про те, чи слід об’єднувати сутності чи ні.
По-перше, нам потрібно сформулювати підказку LLM, щоб ефективно керувати та інформувати про остаточне рішення щодо об’єднання вузлів:
system_prompt = """You are a data processing assistant. Your task is to identify duplicate entities in a list and decide which of them should be merged. The entities might be slightly different in format or content, but essentially refer to the same thing. Use your analytical skills to determine duplicates. Here are the rules for identifying duplicates: 1. Entities with minor typographical differences should be considered duplicates. 2. Entities with different formats but the same content should be considered duplicates. 3. Entities that refer to the same real-world object or concept, even if described differently, should be considered duplicates. 4. If it refers to different numbers, dates, or products, do not merge results """ user_template = """ Here is the list of entities to process: {entities} Please identify duplicates, merge them, and provide the merged list. """
Мені завжди подобається використовувати метод with_structured_output у LangChain, коли очікується вихід структурованих даних, щоб уникнути необхідності аналізувати виходи вручну.
Тут ми визначимо результат як list of lists , де кожен внутрішній список містить сутності, які слід об’єднати. Ця структура використовується для обробки сценаріїв, де, наприклад, введенням може бути [Sony, Sony Inc, Google, Google Inc] . У таких випадках ви хочете об’єднати «Sony» і «Sony Inc» окремо від «Google» і «Google Inc».
class DuplicateEntities(BaseModel): entities: List[str] = Field( description="Entities that represent the same object or real-world entity and should be merged" ) class Disambiguate(BaseModel): merge_entities: Optional[List[DuplicateEntities]] = Field( description="Lists of entities that represent the same object or real-world entity and should be merged" ) extraction_llm = ChatOpenAI(model_name="gpt-4o").with_structured_output( Disambiguate )
Далі ми інтегруємо підказку LLM із структурованим виводом, щоб створити ланцюжок за допомогою синтаксису мови виразів LangChain (LCEL) та інкапсулювати його у функцію disambiguate .
extraction_chain = extraction_prompt | extraction_llm def entity_resolution(entities: List[str]) -> Optional[List[List[str]]]: return [ el.entities for el in extraction_chain.invoke({"entities": entities}).merge_entities ]
Нам потрібно запустити всі потенційні вузли-кандидати через функцію entity_resolution , щоб вирішити, чи слід їх об’єднувати. Щоб пришвидшити процес, ми знову розпаралелюємо виклики LLM:
merged_entities = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(entity_resolution, el['combinedResult']) for el in potential_duplicate_candidates ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): to_merge = future.result() if to_merge: merged_entities.extend(to_merge)
Останнім етапом розпізнавання об’єктів є отримання результатів із LLM entity_resolution і запис їх назад до бази даних шляхом об’єднання вказаних вузлів:
graph.query(""" UNWIND $data AS candidates CALL { WITH candidates MATCH (e:__Entity__) WHERE e.id IN candidates RETURN collect(e) AS nodes } CALL apoc.refactor.mergeNodes(nodes, {properties: { description:'combine', `.*`: 'discard' }}) YIELD node RETURN count(*) """, params={"data": merged_entities})
Ця роздільна здатність сутності не ідеальна, але вона дає нам відправну точку, яку ми можемо покращити. Крім того, ми можемо покращити логіку для визначення того, які сутності слід зберегти.
Елемент Підведення підсумків
На наступному кроці автори виконують крок узагальнення елементів. По суті, кожен вузол і взаємозв’язок передаються через підказку для підсумовування сутності . Автори відзначають новизну та цікавість свого підходу:
«Загалом, наше використання насиченого описового тексту для однорідних вузлів у потенційно зашумленій графовій структурі узгоджується як з можливостями LLM, так і з потребами глобального підсумовування, орієнтованого на запити. Ці якості також відрізняють наш графовий індекс від типових графів знань, які спираються на стислі та послідовні трійки знань (суб’єкт, предикат, об’єкт) для подальших завдань міркування».
Ідея захоплююча. Ми все ще витягуємо ідентифікатори суб’єктів і об’єктів або імена з тексту, що дозволяє нам зв’язувати зв’язки з правильними сутностями, навіть якщо сутності з’являються в кількох фрагментах тексту. Однак відносини не зводяться до одного типу. Натомість тип зв’язку – це фактично текст довільної форми, який дозволяє нам зберігати багатшу та детальнішу інформацію.
Крім того, інформація про сутність узагальнюється за допомогою LLM, що дозволяє нам ефективніше вставляти та індексувати цю інформацію та сутності для більш точного пошуку.
Можна стверджувати, що ця більш багата та детальна інформація також може бути збережена шляхом додавання додаткових, можливо довільних, властивостей вузла та зв’язку. Одна проблема з довільними властивостями вузла та зв’язку полягає в тому, що може бути важко витягти інформацію послідовно, оскільки LLM може використовувати різні назви властивостей або зосереджуватися на різних деталях під час кожного виконання.
Деякі з цих проблем можна вирішити за допомогою попередньо визначених імен властивостей із додатковою інформацією про тип і опис. У такому випадку вам знадобиться фахівець із предметної теми, щоб допомогти визначити ці властивості, залишаючи мало місця для LLM, щоб отримати будь-яку важливу інформацію за межами попередньо визначених описів.
Це захоплюючий підхід до представлення багатшої інформації в графі знань.
Однією з потенційних проблем із кроком підсумовування елементів є те, що він погано масштабується, оскільки вимагає виклику LLM для кожної сутності та зв’язку в графі. Наш графік відносно крихітний із 13 000 вузлами та 16 000 зв’язків. Навіть для такого маленького графіка нам знадобиться 29 000 викликів LLM, і кожен виклик буде використовувати пару сотень токенів, що робить його досить дорогим і трудомістким. Тому ми уникатимемо цього кроку. Ми все ще можемо використовувати властивості опису, отримані під час початкової обробки тексту.
Побудова та узагальнення спільнот
Останнім кроком у процесі побудови та індексації графа є ідентифікація спільнот у графі. У цьому контексті спільнота — це група вузлів, які тісніше пов’язані один з одним, ніж з рештою графа, що вказує на вищий рівень взаємодії чи подібності. Наступна візуалізація показує приклад результатів виявлення спільноти.


Після того, як ці спільноти сутностей ідентифіковано за допомогою алгоритму кластеризації, LLM генерує підсумок для кожної спільноти, надаючи розуміння їхніх індивідуальних характеристик і зв’язків.
Знову ж таки, ми використовуємо бібліотеку Graph Data Science. Ми починаємо з проектування графа в пам’яті. Щоб точно слідувати оригінальній статті, ми спроектуємо граф сутностей як неорієнтовану зважену мережу, де мережа представляє кількість зв’язків між двома сутностями:
G, result = gds.graph.project( "communities", # Graph name "__Entity__", # Node projection { "_ALL_": { "type": "*", "orientation": "UNDIRECTED", "properties": {"weight": {"property": "*", "aggregation": "COUNT"}}, } }, )
Автори використали алгоритм Лейдена , метод ієрархічної кластеризації, щоб ідентифікувати спільноти на графі. Однією з переваг використання ієрархічного алгоритму виявлення спільнот є можливість досліджувати спільноти на кількох рівнях деталізації. Автори пропонують узагальнити всі спільноти на кожному рівні, забезпечуючи повне розуміння структури графа.
Спочатку ми використаємо алгоритм слабозв’язаних компонентів (WCC), щоб оцінити зв’язність нашого графіка. Цей алгоритм визначає ізольовані секції в межах графа, тобто він виявляє підмножини вузлів або компонентів, які з’єднані один з одним, але не з рештою графа. Ці компоненти допомагають нам зрозуміти фрагментацію всередині мережі та ідентифікувати групи вузлів, незалежних від інших. WCC життєво важливий для аналізу загальної структури та зв’язності графа.
wcc = gds.wcc.stats(G) print(f"Component count: {wcc['componentCount']}") print(f"Component distribution: {wcc['componentDistribution']}") # Component count: 1119 # Component distribution: { # "min":1, # "p5":1, # "max":9109, # "p999":43, # "p99":19, # "p1":1, # "p10":1, # "p90":7, # "p50":2, # "p25":1, # "p75":4, # "p95":10, # "mean":11.3 }
Результати алгоритму WCC ідентифікували 1119 окремих компонентів. Примітно, що найбільший компонент складається з 9109 вузлів, що часто зустрічається в мережах реального світу, де один суперкомпонент співіснує з численними меншими ізольованими компонентами. Найменший компонент має один вузол, а середній розмір компонента становить приблизно 11,3 вузла.
Далі ми запустимо алгоритм Leiden, який також доступний у бібліотеці GDS, і ввімкнемо параметр includeIntermediateCommunities для повернення та зберігання спільнот на всіх рівнях. Ми також включили параметр relationshipWeightProperty для запуску зваженого варіанту алгоритму Лейдена. Використання режиму write алгоритму зберігає результати як властивість вузла.
gds.leiden.write( G, writeProperty="communities", includeIntermediateCommunities=True, relationshipWeightProperty="weight", )
Алгоритм визначив п’ять рівнів спільнот, причому найвищий (найменш детальний рівень, де спільноти найбільші) містить 1188 спільнот (на відміну від 1119 компонентів). Ось візуалізація спільнот на останньому рівні за допомогою Gephi.


Важко візуалізувати понад 1000 спільнот; навіть підібрати кольори для кожного практично неможливо. Однак вони створюють гарні художні перетворення.
Спираючись на це, ми створимо окремий вузол для кожної спільноти та представимо їхню ієрархічну структуру як взаємопов’язаний граф. Пізніше ми також зберігатимемо підсумки спільноти та інші атрибути як властивості вузла.
graph.query(""" MATCH (e:`__Entity__`) UNWIND range(0, size(e.communities) - 1 , 1) AS index CALL { WITH e, index WITH e, index WHERE index = 0 MERGE (c:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET c.level = index MERGE (e)-[:IN_COMMUNITY]->(c) RETURN count(*) AS count_0 } CALL { WITH e, index WITH e, index WHERE index > 0 MERGE (current:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET current.level = index MERGE (previous:`__Community__` {id: toString(index - 1) + '-' + toString(e.communities[index - 1])}) ON CREATE SET previous.level = index - 1 MERGE (previous)-[:IN_COMMUNITY]->(current) RETURN count(*) AS count_1 } RETURN count(*) """)
Автори також вводять community rank , що вказує на кількість окремих фрагментів тексту, в яких з’являються сутності в межах спільноти:
graph.query(""" MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(:__Entity__)<-[:MENTIONS]-(d:Document) WITH c, count(distinct d) AS rank SET c.community_rank = rank; """)
Тепер давайте розглянемо зразок ієрархічної структури з багатьма проміжними спільнотами, які зливаються на вищих рівнях. Спільноти не збігаються, тобто кожна сутність належить до однієї спільноти на кожному рівні.


Зображення представляє ієрархічну структуру, отриману в результаті алгоритму виявлення спільноти Leiden. Фіолетові вузли представляють окремі сутності, тоді як помаранчеві вузли представляють ієрархічні спільноти.
Ієрархія показує організацію цих об’єктів у різні спільноти, де менші спільноти зливаються у більші на вищих рівнях.
Давайте тепер розглянемо, як менші спільноти зливаються на вищих рівнях.

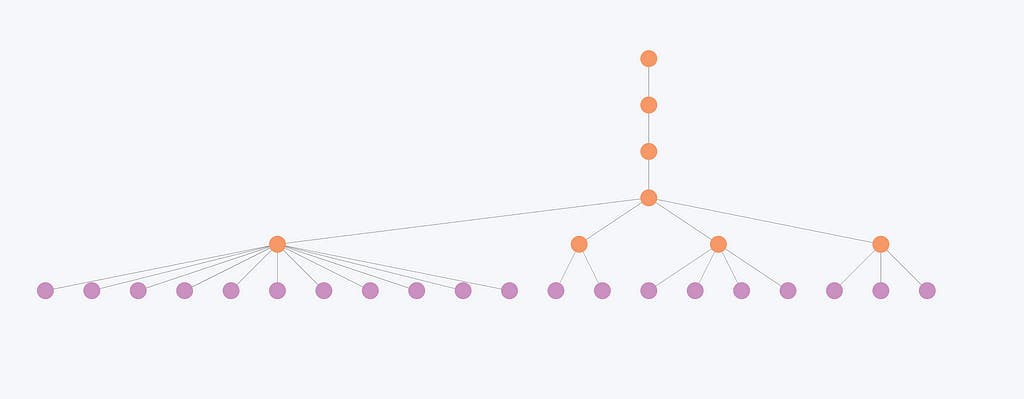
Це зображення ілюструє, що менш пов’язані організації та, отже, менші спільноти зазнають мінімальних змін на різних рівнях. Наприклад, структура спільноти тут змінюється лише на перших двох рівнях, але залишається ідентичною на останніх трьох рівнях. Отже, ієрархічні рівні часто здаються зайвими для цих об’єктів, оскільки загальна організація не зазнає істотних змін на різних рівнях.
Розглянемо кількість спільнот, їх розміри та різні рівні більш детально:
community_size = graph.query( """ MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(e:__Entity__) WITH c, count(distinct e) AS entities RETURN split(c.id, '-')[0] AS level, entities """ ) community_size_df = pd.DataFrame.from_records(community_size) percentiles_data = [] for level in community_size_df["level"].unique(): subset = community_size_df[community_size_df["level"] == level]["entities"] num_communities = len(subset) percentiles = np.percentile(subset, [25, 50, 75, 90, 99]) percentiles_data.append( [ level, num_communities, percentiles[0], percentiles[1], percentiles[2], percentiles[3], percentiles[4], max(subset) ] ) # Create a DataFrame with the percentiles percentiles_df = pd.DataFrame( percentiles_data, columns=[ "Level", "Number of communities", "25th Percentile", "50th Percentile", "75th Percentile", "90th Percentile", "99th Percentile", "Max" ], ) percentiles_df


У початковій реалізації спільноти на кожному рівні були підсумовані. У нашому випадку це буде 8 590 спільнот і, відповідно, 8 590 дзвінків LLM. Я б стверджував, що залежно від ієрархічної структури спільноти, не кожен рівень потрібно підсумовувати. Наприклад, різниця між останнім і передостаннім рівнем становить лише чотири спільноти (1192 проти 1188). Тому ми створили б багато зайвих резюме. Одним із рішень є створення реалізації, яка може створювати єдиний підсумок для спільнот на різних рівнях, які не змінюються; інший — зруйнувати ієрархії спільноти, які не змінюються.
Крім того, я не впевнений, чи хочемо ми підсумувати спільноти лише з одним учасником, оскільки вони можуть не надати великої цінності чи інформації. Тут ми підсумуємо спільноти на рівнях 0, 1 і 4. Спочатку нам потрібно отримати інформацію про них із бази даних:
community_info = graph.query(""" MATCH (c:`__Community__`)<-[:IN_COMMUNITY*]-(e:__Entity__) WHERE c.level IN [0,1,4] WITH c, collect(e ) AS nodes WHERE size(nodes) > 1 CALL apoc.path.subgraphAll(nodes[0], { whitelistNodes:nodes }) YIELD relationships RETURN c.id AS communityId, [n in nodes | {id: n.id, description: n.description, type: [el in labels(n) WHERE el <> '__Entity__'][0]}] AS nodes, [r in relationships | {start: startNode(r).id, type: type(r), end: endNode(r).id, description: r.description}] AS rels """)
На даний момент інформація спільноти має таку структуру:
{'communityId': '0-6014', 'nodes': [{'id': 'Darrell Hughes', 'description': None, type:"Person"}, {'id': 'Chief Pilot', 'description': None, type: "Person"}, ... }], 'rels': [{'start': 'Ryanair Dac', 'description': 'Informed of the change in chief pilot', 'type': 'INFORMED', 'end': 'Irish Aviation Authority'}, {'start': 'Ryanair Dac', 'description': 'Dismissed after internal investigation found unacceptable behaviour', 'type': 'DISMISSED', 'end': 'Aidan Murray'}, ... ]}
Тепер нам потрібно підготувати підказку LLM, яка генерує підсумок природною мовою на основі інформації, наданої елементами нашої спільноти. Ми можемо черпати натхнення з підказки, яку використали дослідники .
Автори не лише узагальнили спільноти, але й зробили висновки для кожної з них. Знахідку можна визначити як стислу інформацію про конкретну подію чи частину інформації. Один із таких прикладів:
"summary": "Abila City Park as the central location", "explanation": "Abila City Park is the central entity in this community, serving as the location for the POK rally. This park is the common link between all other entities, suggesting its significance in the community. The park's association with the rally could potentially lead to issues such as public disorder or conflict, depending on the nature of the rally and the reactions it provokes. [records: Entities (5), Relationships (37, 38, 39, 40)]"
Моя інтуїція підказує, що отримання знахідок лише за один прохід може бути не таким повним, як нам потрібно, подібно до вилучення сутностей і зв’язків.
Крім того, я не знайшов жодних посилань чи прикладів їх використання в їх коді ні в локальних, ні в глобальних пошукових системах. У зв’язку з цим ми утримаємося від вилучення висновків у цьому випадку. Або, як часто кажуть вчені: цю вправу залишаємо читачеві. Крім того, ми також пропустили твердження або витяг інформації про коваріативну інформацію , яка на перший погляд виглядає схожою на результати.
Підказка, яку ми використовуватимемо для створення підсумків спільноти, досить проста:
community_template = """Based on the provided nodes and relationships that belong to the same graph community, generate a natural language summary of the provided information: {community_info} Summary:""" # noqa: E501 community_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Given an input triples, generate the information summary. No pre-amble.", ), ("human", community_template), ] ) community_chain = community_prompt | llm | StrOutputParser()
Єдине, що залишилося, — це перетворити представлення спільноти на рядки, щоб зменшити кількість токенів, уникаючи накладних витрат на токени JSON, і обернути ланцюжок як функцію:
def prepare_string(data): nodes_str = "Nodes are:\n" for node in data['nodes']: node_id = node['id'] node_type = node['type'] if 'description' in node and node['description']: node_description = f", description: {node['description']}" else: node_description = "" nodes_str += f"id: {node_id}, type: {node_type}{node_description}\n" rels_str = "Relationships are:\n" for rel in data['rels']: start = rel['start'] end = rel['end'] rel_type = rel['type'] if 'description' in rel and rel['description']: description = f", description: {rel['description']}" else: description = "" rels_str += f"({start})-[:{rel_type}]->({end}){description}\n" return nodes_str + "\n" + rels_str def process_community(community): stringify_info = prepare_string(community) summary = community_chain.invoke({'community_info': stringify_info}) return {"community": community['communityId'], "summary": summary}
Тепер ми можемо генерувати підсумки спільноти для вибраних рівнів. Знову ж таки, ми розпаралелюємо виклики для швидшого виконання:
summaries = [] with ThreadPoolExecutor() as executor: futures = {executor.submit(process_community, community): community for community in community_info} for future in tqdm(as_completed(futures), total=len(futures), desc="Processing communities"): summaries.append(future.result())
Один аспект, про який я не згадав, полягає в тому, що автори також розглядають потенційну проблему перевищення розміру контексту під час введення інформації спільноти. Оскільки графіки розширюються, спільноти також можуть значно збільшуватися. У нашому випадку найбільша громада налічувала 545 осіб. Оскільки розмір контексту GPT-4o перевищує 100 000 токенів, ми вирішили пропустити цей крок.
На останньому етапі ми збережемо резюме спільноти в базі даних:
graph.query(""" UNWIND $data AS row MERGE (c:__Community__ {id:row.community}) SET c.summary = row.summary """, params={"data": summaries})
Остаточна структура графа:


Тепер графік містить оригінальні документи, витягнуті сутності та зв’язки, а також ієрархічну структуру спільноти та підсумки.
Резюме
Автори статті «Від локального до глобального» виконали велику роботу, продемонструвавши новий підхід до GraphRAG. Вони показують, як ми можемо об’єднати та узагальнити інформацію з різних документів в ієрархічну структуру графа знань.
Одна річ, яка явно не згадується, це те, що ми також можемо інтегрувати джерела структурованих даних у графік; введення не повинно обмежуватися лише неструктурованим текстом.
Що я особливо ціную в їхньому підході до вилучення, так це те, що вони фіксують описи як для вузлів, так і для зв’язків. Описи дозволяють LLM зберігати більше інформації, ніж зводити все до лише ідентифікаторів вузлів і типів зв’язків.
Крім того, вони демонструють, що один прохід вилучення над текстом може не охопити всю релевантну інформацію та вводять логіку для виконання кількох проходів, якщо це необхідно. Автори також представляють цікаву ідею для виконання підсумків над спільнотами графів, що дозволяє нам вставляти та індексувати стислу тематичну інформацію з кількох джерел даних.
У наступному дописі в блозі ми розглянемо реалізацію локального та глобального пошукового ретривера та поговоримо про інші підходи, які ми можемо застосувати на основі заданої структури графа.
Як завжди, код доступний на GitHub .
Цього разу я також завантажив дамп бази даних , щоб ви могли досліджувати результати та експериментувати з різними варіантами відновлення.
Ви також можете імпортувати цей дамп у назавжди вільний екземпляр Neo4j AuraDB , який ми можемо використовувати для досліджень пошуку, оскільки для цього нам не потрібні алгоритми Graph Data Science — лише зіставлення шаблонів графіків, векторні та повнотекстові індекси.
Дізнайтеся більше про інтеграцію Neo4j з усіма фреймворками GenAI і практичними алгоритмами графів у моїй книзі «Алгоритми графів для науки про дані».
Щоб дізнатися більше про цю тему, приєднуйтесь до нас на NODES 2024 7 листопада, нашій безкоштовній віртуальній конференції для розробників, присвяченій інтелектуальним програмам, графам знань і ШІ. Зареєструватися зараз !




