












































































Jan 01, 1970
1,825 letture
Creazione di grafici di conoscenza per RAG: esplorazione di GraphRAG con Neo4j e LangChain
Troppo lungo; Leggere
Questo articolo esplora l'implementazione di una pipeline GraphRAG "From Local to Global" utilizzando Neo4j e LangChain. Copre il processo di costruzione di knowledge graph dal testo, riassumendo comunità di entità utilizzando Large Language Models (LLM) e migliorando l'accuratezza di Retrieval-Augmented Generation (RAG) combinando algoritmi di grafici con riepiloghi basati su LLM. L'approccio condensa informazioni da più fonti in grafici strutturati e genera riepiloghi in linguaggio naturale, offrendo un metodo efficiente per il recupero di informazioni complesse.
Sono sempre incuriosito dai nuovi approcci all'implementazione di Retrieval-Augmented Generation (RAG) su grafici, spesso chiamati GraphRAG. Tuttavia, sembra che tutti abbiano in mente un'implementazione diversa quando sentono il termine GraphRAG. In questo post del blog, approfondiremo l'articolo " From Local to Global GraphRAG " e l'implementazione da parte dei ricercatori Microsoft. Tratteremo la parte di costruzione e riepilogo del knowledge graph e lasceremo i retriever per il prossimo post del blog. I ricercatori sono stati così gentili da fornirci il repository del codice e hanno anche una pagina del progetto .
L'approccio adottato nell'articolo menzionato sopra è piuttosto interessante. Per quanto ne so, prevede l'uso di un knowledge graph come passaggio nella pipeline per condensare e combinare informazioni da più fonti. Estrarre entità e relazioni dal testo non è una novità. Tuttavia, gli autori introducono un'idea nuova (almeno per me) di riassumere la struttura condensata del grafico e le informazioni come testo in linguaggio naturale. La pipeline inizia con il testo di input dai documenti, che vengono elaborati per generare un grafico. Il grafico viene quindi riconvertito in testo in linguaggio naturale, dove il testo generato contiene informazioni condensate su entità specifiche o comunità di grafici precedentemente distribuite su più documenti.
A un livello molto alto, l'input per la pipeline GraphRAG sono documenti sorgente contenenti varie informazioni. I documenti vengono elaborati utilizzando un LLM per estrarre informazioni strutturate sulle entità che compaiono nei documenti insieme alle loro relazioni. Queste informazioni strutturate estratte vengono quindi utilizzate per costruire un knowledge graph.
Il vantaggio di usare una rappresentazione dati del knowledge graph è che può combinare in modo rapido e diretto informazioni da più documenti o fonti dati su entità specifiche. Come detto, il knowledge graph non è l'unica rappresentazione dati. Dopo che il knowledge graph è stato costruito, usano una combinazione di algoritmi grafici e prompt LLM per generare riepiloghi in linguaggio naturale di comunità di entità trovate nel knowledge graph.
Questi riepiloghi contengono quindi informazioni condensate distribuite su più fonti di dati e documenti per entità e comunità specifiche.
Per una comprensione più dettagliata della pipeline, possiamo fare riferimento alla descrizione dettagliata fornita nel documento originale.
Fasi della pipeline — Immagine dal documento GraphRAG , con licenza CC BY 4.0
Di seguito è riportato un riepilogo di alto livello della pipeline che utilizzeremo per riprodurre il loro approccio utilizzando Neo4j e LangChain.
Indicizzazione — Generazione di grafici
- Documenti sorgente in blocchi di testo : i documenti sorgente vengono suddivisi in blocchi di testo più piccoli per l'elaborazione.
- Da blocchi di testo a istanze di elementi : ogni blocco di testo viene analizzato per estrarre entità e relazioni, producendo un elenco di tuple che rappresentano questi elementi.
- Istanze di elementi in riepiloghi di elementi : le entità e le relazioni estratte vengono riepilogate dall'LLM in blocchi di testo descrittivi per ciascun elemento.
- Riepiloghi degli elementi per rappresentare graficamente le comunità : questi riepiloghi delle entità formano un grafico, che viene poi suddiviso in comunità utilizzando algoritmi come Leiden per la struttura gerarchica.
- Grafici delle comunità per riepiloghi delle comunità : i riepiloghi di ciascuna comunità vengono generati con LLM per comprendere la struttura tematica globale e la semantica del set di dati.
Recupero — Rispondere
- Riepiloghi della community per risposte globali : i riepiloghi della community vengono utilizzati per rispondere a una query dell'utente generando risposte intermedie, che vengono poi aggregate in una risposta globale finale.
Si noti che la mia implementazione è stata fatta prima che il loro codice fosse disponibile, quindi potrebbero esserci leggere differenze nell'approccio sottostante o nei prompt LLM utilizzati. Cercherò di spiegare queste differenze man mano che andiamo avanti.
Il codice è disponibile su GitHub .
Impostazione dell'ambiente Neo4j
Utilizzeremo Neo4j come archivio grafico sottostante. Il modo più semplice per iniziare è utilizzare un'istanza gratuita di Neo4j Sandbox , che offre istanze cloud del database Neo4j con il plugin Graph Data Science installato. In alternativa, puoi impostare un'istanza locale del database Neo4j scaricando l'applicazione Neo4j Desktop e creando un'istanza di database locale. Se stai utilizzando una versione locale, assicurati di installare entrambi i plugin APOC e GDS. Per le configurazioni di produzione, puoi utilizzare l'istanza AuraDS (Data Science) a pagamento e gestita, che fornisce il plugin GDS.
Iniziamo creando un'istanza di Neo4jGraph , che è il wrapper di convenienza che abbiamo aggiunto a LangChain:
from langchain_community.graphs import Neo4jGraph os.environ["NEO4J_URI"] = "bolt://44.202.208.177:7687" os.environ["NEO4J_USERNAME"] = "neo4j" os.environ["NEO4J_PASSWORD"] = "mast-codes-trails" graph = Neo4jGraph(refresh_schema=False)Insieme di dati
Utilizzeremo un dataset di articoli di notizie che ho creato qualche tempo fa usando l'API di Diffbot. L'ho caricato sul mio GitHub per un più facile riutilizzo:
news = pd.read_csv( "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/news_articles.csv" ) news["tokens"] = [ num_tokens_from_string(f"{row['title']} {row['text']}") for i, row in news.iterrows() ] news.head()
Esaminiamo le prime due righe del set di dati.
Abbiamo a disposizione il titolo e il testo degli articoli, insieme alla data di pubblicazione e al conteggio dei token utilizzando la libreria TikToken.
Frammentazione del testo
La fase di suddivisione in blocchi del testo è cruciale e ha un impatto significativo sui risultati a valle. Gli autori del documento hanno scoperto che l'utilizzo di blocchi di testo più piccoli comporta l'estrazione di più entità complessive.
Numero di entità di estrazione data la dimensione dei blocchi di testo — Immagine dal documento GraphRAG , con licenza CC BY 4.0
Come puoi vedere, usando blocchi di testo di 2.400 token si ottengono meno entità estratte rispetto a quando ne usavano 600. Inoltre, hanno identificato che gli LLM potrebbero non estrarre tutte le entità alla prima esecuzione. In tal caso, introducono un'euristica per eseguire l'estrazione più volte. Ne parleremo più in dettaglio nella prossima sezione.
Tuttavia, ci sono sempre dei compromessi. L'utilizzo di blocchi di testo più piccoli può comportare la perdita del contesto e delle coreferenze di entità specifiche distribuite nei documenti. Ad esempio, se un documento menziona "John" e "he" in frasi separate, suddividere il testo in blocchi più piccoli potrebbe rendere poco chiaro che "he" si riferisce a John. Alcuni dei problemi di coreferenza possono essere risolti utilizzando una strategia di suddivisione in blocchi di testo sovrapposti, ma non tutti.
Esaminiamo la dimensione dei testi dei nostri articoli:
sns.histplot(news["tokens"], kde=False) plt.title('Distribution of chunk sizes') plt.xlabel('Token count') plt.ylabel('Frequency') plt.show()
La distribuzione dei conteggi dei token dell'articolo è approssimativamente normale, con un picco di circa 400 token. La frequenza dei blocchi aumenta gradualmente fino a questo picco, quindi diminuisce simmetricamente, indicando che la maggior parte dei blocchi di testo è vicina al limite dei 400 token.
A causa di questa distribuzione, non eseguiremo alcun chunking di testo qui per evitare problemi di coreferenza. Per impostazione predefinita, il progetto GraphRAG utilizza dimensioni di chunk di 300 token con 100 token di sovrapposizione.
Estrazione di nodi e relazioni
Il passo successivo è costruire la conoscenza da blocchi di testo. Per questo caso d'uso, utilizziamo un LLM per estrarre informazioni strutturate sotto forma di nodi e relazioni dal testo. Puoi esaminare il prompt LLM utilizzato dagli autori nel documento. Hanno prompt LLM in cui possiamo predefinire etichette di nodi se necessario, ma di default è facoltativo. Inoltre, le relazioni estratte nella documentazione originale non hanno realmente un tipo, solo una descrizione. Immagino che il motivo dietro questa scelta sia quello di consentire al LLM di estrarre e conservare informazioni più ricche e sfumate come relazioni. Ma è difficile avere un knowledge graph pulito senza specifiche di tipo di relazione (le descrizioni potrebbero andare in una proprietà).
Nella nostra implementazione, utilizzeremo LLMGraphTransformer , disponibile nella libreria LangChain. Invece di utilizzare la pura ingegneria dei prompt, come fa l'implementazione nell'articolo, LLMGraphTransformer utilizza il supporto di chiamata di funzione incorporato per estrarre informazioni strutturate (LLM di output strutturati in LangChain). Puoi ispezionare il prompt di sistema :
from langchain_experimental.graph_transformers import LLMGraphTransformer from langchain_openai import ChatOpenAI llm = ChatOpenAI(temperature=0, model_name="gpt-4o") llm_transformer = LLMGraphTransformer( llm=llm, node_properties=["description"], relationship_properties=["description"] ) def process_text(text: str) -> List[GraphDocument]: doc = Document(page_content=text) return llm_transformer.convert_to_graph_documents([doc])
In questo esempio, utilizziamo GPT-4o per l'estrazione di grafici. Gli autori istruiscono specificamente l'LLM a estrarre entità e relazioni e le loro descrizioni . Con l'implementazione di LangChain, puoi utilizzare gli attributi node_properties e relationship_properties per specificare quali proprietà di nodo o relazione vuoi che l'LLM estragga.
La differenza con l'implementazione di LLMGraphTransformer è che tutte le proprietà di nodo o relazione sono facoltative, quindi non tutti i nodi avranno la proprietà description . Se volessimo, potremmo definire un'estrazione personalizzata per avere una proprietà description obbligatoria, ma lo salteremo in questa implementazione.
Parallelizzeremo le richieste per rendere più rapida l'estrazione del grafico e memorizzare i risultati su Neo4j:
MAX_WORKERS = 10 NUM_ARTICLES = 2000 graph_documents = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(process_text, f"{row['title']} {row['text']}") for i, row in news.head(NUM_ARTICLES).iterrows() ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): graph_document = future.result() graph_documents.extend(graph_document) graph.add_graph_documents( graph_documents, baseEntityLabel=True, include_source=True )
In questo esempio, estraiamo informazioni grafiche da 2.000 articoli e memorizziamo i risultati in Neo4j. Abbiamo estratto circa 13.000 entità e 16.000 relazioni. Ecco un esempio di un documento estratto nel grafico.
Ci vogliono circa 35 (+/- 5) minuti per completare l'estrazione e costa circa 30 $ con GPT-4o.
In questa fase, gli autori introducono euristiche per decidere se estrarre informazioni dal grafico in più di un passaggio. Per semplicità, faremo solo un passaggio. Tuttavia, se volessimo fare più passaggi, potremmo mettere i primi risultati di estrazione come cronologia conversazionale e semplicemente istruire l' LLM che mancano molte entità e che dovrebbe estrarne altre, come fanno gli autori di GraphRAG.
In precedenza, ho menzionato quanto sia importante la dimensione del blocco di testo e come influisce sul numero di entità estratte. Poiché non abbiamo eseguito alcun ulteriore chunking del testo, possiamo valutare la distribuzione delle entità estratte in base alla dimensione del blocco di testo:
entity_dist = graph.query( """ MATCH (d:Document) RETURN d.text AS text, count {(d)-[:MENTIONS]->()} AS entity_count """ ) entity_dist_df = pd.DataFrame.from_records(entity_dist) entity_dist_df["token_count"] = [ num_tokens_from_string(str(el)) for el in entity_dist_df["text"] ] # Scatter plot with regression line sns.lmplot( x="token_count", y="entity_count", data=entity_dist_df, line_kws={"color": "red"} ) plt.title("Entity Count vs Token Count Distribution") plt.xlabel("Token Count") plt.ylabel("Entity Count") plt.show()
Il diagramma di dispersione mostra che, sebbene vi sia un trend positivo, indicato dalla linea rossa, la relazione è sublineare. La maggior parte dei punti dati si raggruppa a conteggi di entità inferiori, anche quando i conteggi di token aumentano. Ciò indica che il numero di entità estratte non è proporzionale alla dimensione dei blocchi di testo. Sebbene esistano alcuni valori anomali, il modello generale mostra che conteggi di token più elevati non portano costantemente a conteggi di entità più elevati. Ciò convalida la scoperta degli autori secondo cui dimensioni di blocchi di testo inferiori estrarranno più informazioni.
Ho anche pensato che sarebbe stato interessante esaminare le distribuzioni del grado dei nodi del grafico costruito. Il seguente codice recupera e visualizza le distribuzioni del grado dei nodi:
degree_dist = graph.query( """ MATCH (e:__Entity__) RETURN count {(e)-[:!MENTIONS]-()} AS node_degree """ ) degree_dist_df = pd.DataFrame.from_records(degree_dist) # Calculate mean and median mean_degree = np.mean(degree_dist_df['node_degree']) percentiles = np.percentile(degree_dist_df['node_degree'], [25, 50, 75, 90]) # Create a histogram with a logarithmic scale plt.figure(figsize=(12, 6)) sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue') # Use a logarithmic scale for the x-axis plt.yscale('log') # Adding labels and title plt.xlabel('Node Degree') plt.ylabel('Count (log scale)') plt.title('Node Degree Distribution') # Add mean, median, and percentile lines plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'Mean: {mean_degree:.2f}') plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25th Percentile: {percentiles[0]:.2f}') plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50th Percentile: {percentiles[1]:.2f}') plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75th Percentile: {percentiles[2]:.2f}') plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90th Percentile: {percentiles[3]:.2f}') # Add legend plt.legend() # Show the plot plt.show()
La distribuzione del grado del nodo segue uno schema di legge di potenza, indicando che la maggior parte dei nodi ha pochissime connessioni mentre alcuni nodi sono altamente connessi. Il grado medio è 2,45 e la mediana è 1,00, il che dimostra che più della metà dei nodi ha una sola connessione. La maggior parte dei nodi (75 percento) ha due o meno connessioni e il 90 percento ne ha cinque o meno. Questa distribuzione è tipica di molte reti del mondo reale, dove un piccolo numero di hub ha molte connessioni e la maggior parte dei nodi ne ha poche.
Poiché sia le descrizioni dei nodi che quelle delle relazioni non sono proprietà obbligatorie, esamineremo anche quante ne sono state estratte:
graph.query(""" MATCH (n:`__Entity__`) RETURN "node" AS type, count(*) AS total_count, count(n.description) AS non_null_descriptions UNION ALL MATCH (n)-[r:!MENTIONS]->() RETURN "relationship" AS type, count(*) AS total_count, count(r.description) AS non_null_descriptions """)
I risultati mostrano che 5.926 nodi su 12.994 (45,6 percento) hanno la proprietà description. D'altro canto, solo 5.569 relazioni su 15.921 (35 percento) hanno tale proprietà.
Si noti che, a causa della natura probabilistica degli LLM, i numeri possono variare a seconda delle diverse esecuzioni e dei diversi dati sorgente, LLM e prompt.
Risoluzione dell'entità
La risoluzione delle entità (de-duplicazione) è fondamentale quando si costruiscono grafici della conoscenza perché assicura che ogni entità sia rappresentata in modo univoco e accurato, impedendo duplicati e unendo record che fanno riferimento alla stessa entità del mondo reale. Questo processo è essenziale per mantenere l'integrità e la coerenza dei dati all'interno del grafico. Senza la risoluzione delle entità, i grafici della conoscenza soffrirebbero di dati frammentati e incoerenti, portando a errori e informazioni inaffidabili.
Questa immagine mostra come una singola entità del mondo reale potrebbe apparire con nomi leggermente diversi in documenti diversi e, di conseguenza, nel nostro grafico.
Inoltre, i dati sparsi diventano un problema significativo senza la risoluzione delle entità. Dati incompleti o parziali provenienti da varie fonti possono dare origine a informazioni sparse e scollegate, rendendo difficile formare una comprensione coerente e completa delle entità. Una risoluzione accurata delle entità affronta questo problema consolidando i dati, colmando le lacune e creando una vista unificata di ciascuna entità.
Prima/dopo l'utilizzo della risoluzione dell'entità Senzing per collegare i dati delle fughe di notizie offshore del Consorzio internazionale dei giornalisti investigativi (ICIJ) — Immagine di Paco Nathan
La parte sinistra della visualizzazione presenta un grafico sparso e non connesso. Tuttavia, come mostrato sul lato destro, un grafico del genere può diventare ben connesso con una risoluzione efficiente delle entità.
Nel complesso, la risoluzione delle entità migliora l'efficienza del recupero e dell'integrazione dei dati, fornendo una visione coesa delle informazioni attraverso diverse fonti. In definitiva, consente risposte alle domande più efficaci basate su un knowledge graph affidabile e completo.
Sfortunatamente, gli autori del documento GraphRAG non hanno incluso alcun codice di risoluzione delle entità nel loro repository, sebbene lo menzionino nel loro documento. Un motivo per cui questo codice è stato escluso potrebbe essere che è difficile implementare una risoluzione delle entità robusta e performante per un dato dominio. È possibile implementare euristiche personalizzate per diversi nodi quando si ha a che fare con tipi di nodi predefiniti (quando non sono predefiniti, non sono abbastanza coerenti, come azienda, organizzazione, attività commerciale, ecc.). Tuttavia, se le etichette o i tipi di nodo non sono noti in anticipo, come nel nostro caso, questo diventa un problema ancora più difficile. Tuttavia, implementeremo una versione di risoluzione delle entità nel nostro progetto qui, combinando incorporamenti di testo e algoritmi di grafici con distanza di parola e LLM.
Il nostro processo di risoluzione delle entità prevede i seguenti passaggi:
- Entità nel grafico : inizia con tutte le entità presenti nel grafico.
- Grafico K-più prossimo : costruisci un grafico dei k-vicini più prossimi, collegando entità simili in base agli incorporamenti di testo.
- Componenti debolmente connesse — Identifica i componenti debolmente connessi nel grafico k-più vicino, raggruppando le entità che hanno probabilità di essere simili. Aggiungi un passaggio di filtraggio della distanza delle parole dopo che questi componenti sono stati identificati.
- Valutazione LLM : utilizzare un LLM per valutare questi componenti e decidere se le entità all'interno di ciascun componente debbano essere unite, ottenendo una decisione finale sulla risoluzione dell'entità (ad esempio, unendo 'Silicon Valley Bank' e 'Silicon_Valley_Bank' rifiutando l'unione per date diverse come '16 settembre 2023' e '2 settembre 2023').
Iniziamo calcolando gli embedding di testo per le proprietà name e description delle entità. Possiamo usare il metodo from_existing_graph nell'integrazione Neo4jVector in LangChain per ottenere questo risultato:
vector = Neo4jVector.from_existing_graph( OpenAIEmbeddings(), node_label='__Entity__', text_node_properties=['id', 'description'], embedding_node_property='embedding' )
Possiamo usare questi embedding per trovare potenziali candidati simili in base alla distanza del coseno di questi embedding. Utilizzeremo algoritmi grafici disponibili nella libreria Graph Data Science (GDS) ; pertanto, possiamo usare il client Python GDS per facilità d'uso in modo Pythonico:
from graphdatascience import GraphDataScience gds = GraphDataScience( os.environ["NEO4J_URI"], auth=(os.environ["NEO4J_USERNAME"], os.environ["NEO4J_PASSWORD"]) )
Se non si ha familiarità con la libreria GDS, prima di poter eseguire qualsiasi algoritmo grafico dobbiamo proiettare un grafico in memoria.
Innanzitutto, il grafico Neo4j memorizzato viene proiettato in un grafico in memoria per un'elaborazione e un'analisi più rapide. Quindi, un algoritmo grafico viene eseguito sul grafico in memoria. Facoltativamente, i risultati dell'algoritmo possono essere memorizzati nuovamente nel database Neo4j. Scopri di più nella documentazione .
Per creare il grafico dei k-vicini più prossimi, proietteremo tutte le entità insieme ai loro incorporamenti di testo:
G, result = gds.graph.project( "entities", # Graph name "__Entity__", # Node projection "*", # Relationship projection nodeProperties=["embedding"] # Configuration parameters )
Ora che il grafico è proiettato sotto il nome entities , possiamo eseguire algoritmi grafici. Inizieremo costruendo un grafico k-nearest . I due parametri più importanti che influenzano quanto sparso o denso sarà il grafico k-nearest sono similarityCutoff e topK . Il topK è il numero di vicini da trovare per ogni nodo, con un valore minimo di 1. Il similarityCutoff filtra le relazioni con similarità al di sotto di questa soglia. Qui, useremo un topK predefinito di 10 e un cutoff di similarità relativamente alto di 0,95. L'utilizzo di un cutoff di similarità elevato, come 0,95, garantisce che solo le coppie altamente simili siano considerate corrispondenze, riducendo al minimo i falsi positivi e migliorando l'accuratezza.
Poiché vogliamo memorizzare i risultati nel grafico in memoria proiettato anziché nel grafico della conoscenza, utilizzeremo la modalità mutate dell'algoritmo:
similarity_threshold = 0.95 gds.knn.mutate( G, nodeProperties=['embedding'], mutateRelationshipType= 'SIMILAR', mutateProperty= 'score', similarityCutoff=similarity_threshold )
Il passo successivo è identificare gruppi di entità che sono connesse con le relazioni di similarità appena dedotte. L'identificazione di gruppi di nodi connessi è un processo frequente nell'analisi di rete, spesso chiamato rilevamento della comunità o clustering , che implica la ricerca di sottogruppi di nodi densamente connessi. In questo esempio, utilizzeremo l' algoritmo Weakly Connected Components , che ci aiuta a trovare parti di un grafico in cui tutti i nodi sono connessi, anche se ignoriamo la direzione delle connessioni.
Utilizziamo la modalità write dell'algoritmo per memorizzare i risultati nel database (grafico memorizzato):
gds.wcc.write( G, writeProperty="wcc", relationshipTypes=["SIMILAR"] )
Il confronto dell'incorporamento del testo aiuta a trovare potenziali duplicati, ma è solo una parte del processo di risoluzione dell'entità. Ad esempio, Google e Apple sono molto vicine nello spazio dell'incorporamento (somiglianza del coseno 0,96 utilizzando il modello di incorporamento ada-002 ). Lo stesso vale per BMW e Mercedes Benz (somiglianza del coseno 0,97). Un'elevata somiglianza dell'incorporamento del testo è un buon inizio, ma possiamo migliorarla. Pertanto, aggiungeremo un filtro aggiuntivo che consente solo coppie di parole con una distanza di testo di tre o meno (il che significa che solo i caratteri possono essere modificati):
word_edit_distance = 3 potential_duplicate_candidates = graph.query( """MATCH (e:`__Entity__`) WHERE size(e.id) > 3 // longer than 3 characters WITH e.wcc AS community, collect(e) AS nodes, count(*) AS count WHERE count > 1 UNWIND nodes AS node // Add text distance WITH distinct [n IN nodes WHERE apoc.text.distance(toLower(node.id), toLower(n.id)) < $distance OR node.id CONTAINS n.id | n.id] AS intermediate_results WHERE size(intermediate_results) > 1 WITH collect(intermediate_results) AS results // combine groups together if they share elements UNWIND range(0, size(results)-1, 1) as index WITH results, index, results[index] as result WITH apoc.coll.sort(reduce(acc = result, index2 IN range(0, size(results)-1, 1) | CASE WHEN index <> index2 AND size(apoc.coll.intersection(acc, results[index2])) > 0 THEN apoc.coll.union(acc, results[index2]) ELSE acc END )) as combinedResult WITH distinct(combinedResult) as combinedResult // extra filtering WITH collect(combinedResult) as allCombinedResults UNWIND range(0, size(allCombinedResults)-1, 1) as combinedResultIndex WITH allCombinedResults[combinedResultIndex] as combinedResult, combinedResultIndex, allCombinedResults WHERE NOT any(x IN range(0,size(allCombinedResults)-1,1) WHERE x <> combinedResultIndex AND apoc.coll.containsAll(allCombinedResults[x], combinedResult) ) RETURN combinedResult """, params={'distance': word_edit_distance})
Questa affermazione di Cypher è leggermente più complessa e la sua interpretazione va oltre lo scopo di questo post del blog. Puoi sempre chiedere a un LLM di interpretarla.
Inoltre, il limite della distanza tra le parole potrebbe essere una funzione della lunghezza della parola anziché un singolo numero e l'implementazione potrebbe essere più scalabile.
Ciò che è importante è che genera gruppi di potenziali entità che potremmo voler unire. Ecco un elenco di potenziali nodi da unire:
{'combinedResult': ['Sinn Fein', 'Sinn Féin']}, {'combinedResult': ['Government', 'Governments']}, {'combinedResult': ['Unreal Engine', 'Unreal_Engine']}, {'combinedResult': ['March 2016', 'March 2020', 'March 2022', 'March_2023']}, {'combinedResult': ['Humana Inc', 'Humana Inc.']}, {'combinedResult': ['New York Jets', 'New York Mets']}, {'combinedResult': ['Asia Pacific', 'Asia-Pacific', 'Asia_Pacific']}, {'combinedResult': ['Bengaluru', 'Mangaluru']}, {'combinedResult': ['US Securities And Exchange Commission', 'Us Securities And Exchange Commission']}, {'combinedResult': ['Jp Morgan', 'Jpmorgan']}, {'combinedResult': ['Brighton', 'Brixton']},
Come puoi vedere, il nostro approccio di risoluzione funziona meglio per alcuni tipi di nodi rispetto ad altri. In base a un rapido esame, sembra funzionare meglio per persone e organizzazioni, mentre è piuttosto negativo per le date. Se usassimo tipi di nodi predefiniti, potremmo preparare diverse euristiche per vari tipi di nodi. In questo esempio, non abbiamo etichette di nodi predefinite, quindi ci rivolgeremo a un LLM per prendere la decisione finale se le entità debbano essere unite o meno.
Innanzitutto, dobbiamo formulare il prompt LLM per guidare e informare in modo efficace la decisione finale riguardante l'unione dei nodi:
system_prompt = """You are a data processing assistant. Your task is to identify duplicate entities in a list and decide which of them should be merged. The entities might be slightly different in format or content, but essentially refer to the same thing. Use your analytical skills to determine duplicates. Here are the rules for identifying duplicates: 1. Entities with minor typographical differences should be considered duplicates. 2. Entities with different formats but the same content should be considered duplicates. 3. Entities that refer to the same real-world object or concept, even if described differently, should be considered duplicates. 4. If it refers to different numbers, dates, or products, do not merge results """ user_template = """ Here is the list of entities to process: {entities} Please identify duplicates, merge them, and provide the merged list. """
Mi piace sempre utilizzare il metodo with_structured_output in LangChain quando mi aspetto un output di dati strutturati, per evitare di dover analizzare manualmente gli output.
Qui, definiremo l'output come un list of lists , dove ogni elenco interno contiene le entità che devono essere unite. Questa struttura viene utilizzata per gestire scenari in cui, ad esempio, l'input potrebbe essere [Sony, Sony Inc, Google, Google Inc] . In tali casi, si desidera unire "Sony" e "Sony Inc" separatamente da "Google" e "Google Inc."
class DuplicateEntities(BaseModel): entities: List[str] = Field( description="Entities that represent the same object or real-world entity and should be merged" ) class Disambiguate(BaseModel): merge_entities: Optional[List[DuplicateEntities]] = Field( description="Lists of entities that represent the same object or real-world entity and should be merged" ) extraction_llm = ChatOpenAI(model_name="gpt-4o").with_structured_output( Disambiguate )
Successivamente, integriamo il prompt LLM con l'output strutturato per creare una catena utilizzando la sintassi LangChain Expression Language (LCEL) e la incapsuliamo in una funzione disambiguate .
extraction_chain = extraction_prompt | extraction_llm def entity_resolution(entities: List[str]) -> Optional[List[List[str]]]: return [ el.entities for el in extraction_chain.invoke({"entities": entities}).merge_entities ]
Dobbiamo eseguire tutti i potenziali nodi candidati tramite la funzione entity_resolution per decidere se devono essere uniti. Per velocizzare il processo, parallelizzeremo di nuovo le chiamate LLM:
merged_entities = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(entity_resolution, el['combinedResult']) for el in potential_duplicate_candidates ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): to_merge = future.result() if to_merge: merged_entities.extend(to_merge)
Il passaggio finale della risoluzione dell'entità consiste nell'acquisire i risultati entity_resolution LLM e riscriverli nel database unendo i nodi specificati:
graph.query(""" UNWIND $data AS candidates CALL { WITH candidates MATCH (e:__Entity__) WHERE e.id IN candidates RETURN collect(e) AS nodes } CALL apoc.refactor.mergeNodes(nodes, {properties: { description:'combine', `.*`: 'discard' }}) YIELD node RETURN count(*) """, params={"data": merged_entities})
Questa risoluzione dell'entità non è perfetta, ma ci fornisce un punto di partenza su cui possiamo migliorare. Inoltre, possiamo migliorare la logica per determinare quali entità dovrebbero essere mantenute.
Riepilogo degli elementi
Nel passaggio successivo, gli autori eseguono un passaggio di riepilogo degli elementi. In sostanza, ogni nodo e relazione viene passato attraverso un prompt di riepilogo delle entità . Gli autori notano la novità e l'interesse del loro approccio:
"Nel complesso, il nostro utilizzo di testo descrittivo ricco per nodi omogenei in una struttura di grafico potenzialmente rumorosa è allineato sia con le capacità degli LLM sia con le esigenze di una sintesi globale incentrata sulle query. Queste qualità differenziano anche il nostro indice grafico dai tipici grafici della conoscenza, che si basano su triple di conoscenza concise e coerenti (soggetto, predicato, oggetto) per le attività di ragionamento a valle".
L'idea è entusiasmante. Estraiamo ancora ID o nomi di soggetti e oggetti dal testo, il che ci consente di collegare relazioni a entità corrette, anche quando le entità compaiono in più blocchi di testo. Tuttavia, le relazioni non sono ridotte a un singolo tipo. Invece, il tipo di relazione è in realtà un testo libero che ci consente di conservare informazioni più ricche e sfumate.
Inoltre, le informazioni sulle entità vengono riepilogate utilizzando un LLM, consentendoci di incorporare e indicizzare queste informazioni ed entità in modo più efficiente, per un recupero più accurato.
Si potrebbe sostenere che queste informazioni più ricche e sfumate potrebbero anche essere mantenute aggiungendo ulteriori proprietà di nodo e relazione, eventualmente arbitrarie. Un problema con le proprietà di nodo e relazione arbitrarie è che potrebbe essere difficile estrarre le informazioni in modo coerente perché l'LLM potrebbe usare nomi di proprietà diversi o concentrarsi su vari dettagli a ogni esecuzione.
Alcuni di questi problemi potrebbero essere risolti utilizzando nomi di proprietà predefiniti con informazioni aggiuntive su tipo e descrizione. In tal caso, avresti bisogno di un esperto in materia per aiutarti a definire tali proprietà, lasciando poco spazio a un LLM per estrarre informazioni vitali al di fuori delle descrizioni predefinite.
Si tratta di un approccio entusiasmante per rappresentare informazioni più dettagliate in un knowledge graph.
Un potenziale problema con la fase di riepilogo degli elementi è che non è ben scalabile poiché richiede una chiamata LLM per ogni entità e relazione nel grafico. Il nostro grafico è relativamente piccolo con 13.000 nodi e 16.000 relazioni. Anche per un grafico così piccolo, avremmo bisogno di 29.000 chiamate LLM e ogni chiamata utilizzerebbe un paio di centinaia di token, il che lo renderebbe piuttosto costoso e dispendioso in termini di tempo. Pertanto, eviteremo questa fase qui. Possiamo comunque utilizzare le proprietà di descrizione estratte durante l'elaborazione iniziale del testo.
Costruire e riassumere le comunità
L'ultimo passaggio nel processo di costruzione e indicizzazione del grafico comporta l'identificazione delle community all'interno del grafico. In questo contesto, una community è un gruppo di nodi che sono più densamente connessi tra loro rispetto al resto del grafico, indicando un livello più elevato di interazione o similarità. La seguente visualizzazione mostra un esempio di risultati di rilevamento della community.
Una volta identificate queste comunità di entità con un algoritmo di clustering, un LLM genera un riepilogo per ciascuna comunità, fornendo informazioni sulle singole caratteristiche e relazioni.
Di nuovo, utilizziamo la libreria Graph Data Science. Iniziamo proiettando un grafico in memoria. Per seguire esattamente l'articolo originale, proietteremo il grafico delle entità come una rete pesata non orientata, dove la rete rappresenta il numero di connessioni tra due entità:
G, result = gds.graph.project( "communities", # Graph name "__Entity__", # Node projection { "_ALL_": { "type": "*", "orientation": "UNDIRECTED", "properties": {"weight": {"property": "*", "aggregation": "COUNT"}}, } }, )
Gli autori hanno utilizzato l' algoritmo di Leiden , un metodo di clustering gerarchico, per identificare le comunità all'interno del grafico. Un vantaggio dell'utilizzo di un algoritmo di rilevamento delle comunità gerarchico è la capacità di esaminare le comunità a più livelli di granularità. Gli autori suggeriscono di riassumere tutte le comunità a ogni livello, fornendo una comprensione completa della struttura del grafico.
Per prima cosa, utilizzeremo l'algoritmo Weakly Connected Components (WCC) per valutare la connettività del nostro grafico. Questo algoritmo identifica sezioni isolate all'interno del grafico, ovvero rileva sottoinsiemi di nodi o componenti che sono connessi tra loro ma non al resto del grafico. Questi componenti ci aiutano a comprendere la frammentazione all'interno della rete e a identificare gruppi di nodi indipendenti dagli altri. WCC è fondamentale per analizzare la struttura complessiva e la connettività del grafico.
wcc = gds.wcc.stats(G) print(f"Component count: {wcc['componentCount']}") print(f"Component distribution: {wcc['componentDistribution']}") # Component count: 1119 # Component distribution: { # "min":1, # "p5":1, # "max":9109, # "p999":43, # "p99":19, # "p1":1, # "p10":1, # "p90":7, # "p50":2, # "p25":1, # "p75":4, # "p95":10, # "mean":11.3 }
I risultati dell'algoritmo WCC hanno identificato 1.119 componenti distinti. In particolare, il componente più grande comprende 9.109 nodi, cosa comune nelle reti del mondo reale in cui un singolo super componente coesiste con numerosi componenti isolati più piccoli. Il componente più piccolo ha un nodo e la dimensione media del componente è di circa 11,3 nodi.
Successivamente, eseguiremo l'algoritmo di Leiden, che è disponibile anche nella libreria GDS, e abiliteremo il parametro includeIntermediateCommunities per restituire e memorizzare le community a tutti i livelli. Abbiamo anche incluso un parametro relationshipWeightProperty per eseguire la variante ponderata dell'algoritmo di Leiden. Utilizzando la modalità write dell'algoritmo, i risultati vengono memorizzati come proprietà del nodo.
gds.leiden.write( G, writeProperty="communities", includeIntermediateCommunities=True, relationshipWeightProperty="weight", )
L'algoritmo ha identificato cinque livelli di comunità, con il più alto (livello meno granulare in cui le comunità sono più grandi) che ha 1.188 comunità (invece di 1.119 componenti). Ecco la visualizzazione delle comunità all'ultimo livello usando Gephi.
Visualizzare più di 1.000 comunità è difficile; persino scegliere i colori per ciascuna è praticamente impossibile. Tuttavia, sono delle belle rappresentazioni artistiche.
Partendo da questo, creeremo un nodo distinto per ogni comunità e rappresenteremo la loro struttura gerarchica come un grafico interconnesso. In seguito, memorizzeremo anche i riepiloghi della comunità e altri attributi come proprietà del nodo.
graph.query(""" MATCH (e:`__Entity__`) UNWIND range(0, size(e.communities) - 1 , 1) AS index CALL { WITH e, index WITH e, index WHERE index = 0 MERGE (c:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET c.level = index MERGE (e)-[:IN_COMMUNITY]->(c) RETURN count(*) AS count_0 } CALL { WITH e, index WITH e, index WHERE index > 0 MERGE (current:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET current.level = index MERGE (previous:`__Community__` {id: toString(index - 1) + '-' + toString(e.communities[index - 1])}) ON CREATE SET previous.level = index - 1 MERGE (previous)-[:IN_COMMUNITY]->(current) RETURN count(*) AS count_1 } RETURN count(*) """)
Gli autori introducono anche un community rank , che indica il numero di blocchi di testo distinti in cui compaiono le entità all'interno della comunità:
graph.query(""" MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(:__Entity__)<-[:MENTIONS]-(d:Document) WITH c, count(distinct d) AS rank SET c.community_rank = rank; """)
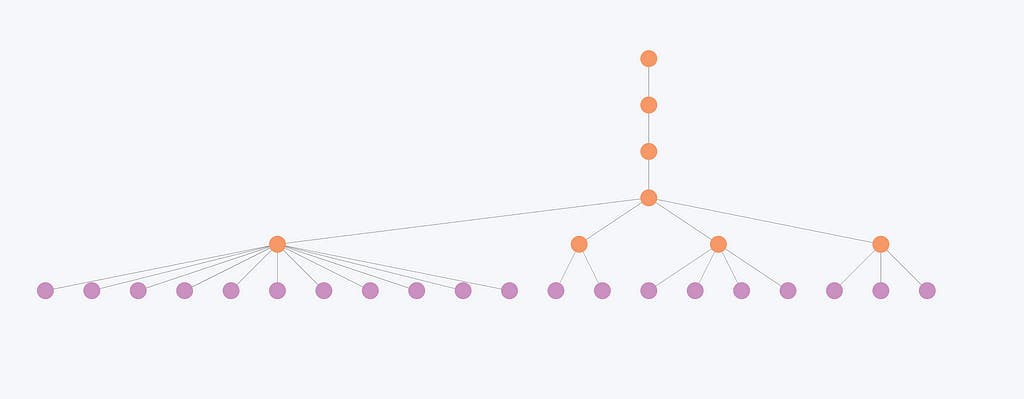
Ora esaminiamo un esempio di struttura gerarchica con molte comunità intermedie che si fondono a livelli superiori. Le comunità non si sovrappongono, il che significa che ogni entità appartiene esattamente a una singola comunità a ogni livello.
L'immagine rappresenta una struttura gerarchica risultante dall'algoritmo di rilevamento della comunità di Leiden. I nodi viola rappresentano entità individuali, mentre i nodi arancioni rappresentano comunità gerarchiche.
La gerarchia mostra l'organizzazione di queste entità in varie comunità, con le comunità più piccole che si fondono in quelle più grandi ai livelli superiori.
Esaminiamo ora come le comunità più piccole si fondono ai livelli più alti.
Questa immagine illustra che le entità meno connesse e di conseguenza le comunità più piccole subiscono cambiamenti minimi tra i livelli. Ad esempio, la struttura della comunità qui cambia solo nei primi due livelli ma rimane identica per gli ultimi tre livelli. Di conseguenza, i livelli gerarchici spesso appaiono ridondanti per queste entità, poiché l'organizzazione complessiva non cambia in modo significativo a diversi livelli.
Esaminiamo più in dettaglio il numero di comunità, le loro dimensioni e i diversi livelli:
community_size = graph.query( """ MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(e:__Entity__) WITH c, count(distinct e) AS entities RETURN split(c.id, '-')[0] AS level, entities """ ) community_size_df = pd.DataFrame.from_records(community_size) percentiles_data = [] for level in community_size_df["level"].unique(): subset = community_size_df[community_size_df["level"] == level]["entities"] num_communities = len(subset) percentiles = np.percentile(subset, [25, 50, 75, 90, 99]) percentiles_data.append( [ level, num_communities, percentiles[0], percentiles[1], percentiles[2], percentiles[3], percentiles[4], max(subset) ] ) # Create a DataFrame with the percentiles percentiles_df = pd.DataFrame( percentiles_data, columns=[ "Level", "Number of communities", "25th Percentile", "50th Percentile", "75th Percentile", "90th Percentile", "99th Percentile", "Max" ], ) percentiles_df
Nell'implementazione originale, le community a ogni livello erano riepilogate. Nel nostro caso, sarebbero 8.590 community e, di conseguenza, 8.590 chiamate LLM. Vorrei sostenere che, a seconda della struttura gerarchica della community, non tutti i livelli devono essere riepilogati. Ad esempio, la differenza tra l'ultimo e il penultimo livello è di sole quattro community (1.192 contro 1.188). Pertanto, creeremmo molti riepiloghi ridondanti. Una soluzione è creare un'implementazione che possa creare un singolo riepilogo per le community a diversi livelli che non cambiano; un'altra sarebbe quella di comprimere le gerarchie delle community che non cambiano.
Inoltre, non sono sicuro se vogliamo riassumere le comunità con un solo membro, poiché potrebbero non fornire molto valore o informazioni. Qui, riassumeremo le comunità sui livelli 0, 1 e 4. Per prima cosa, dobbiamo recuperare le loro informazioni dal database:
community_info = graph.query(""" MATCH (c:`__Community__`)<-[:IN_COMMUNITY*]-(e:__Entity__) WHERE c.level IN [0,1,4] WITH c, collect(e ) AS nodes WHERE size(nodes) > 1 CALL apoc.path.subgraphAll(nodes[0], { whitelistNodes:nodes }) YIELD relationships RETURN c.id AS communityId, [n in nodes | {id: n.id, description: n.description, type: [el in labels(n) WHERE el <> '__Entity__'][0]}] AS nodes, [r in relationships | {start: startNode(r).id, type: type(r), end: endNode(r).id, description: r.description}] AS rels """)
Al momento, le informazioni della comunità hanno la seguente struttura:
{'communityId': '0-6014', 'nodes': [{'id': 'Darrell Hughes', 'description': None, type:"Person"}, {'id': 'Chief Pilot', 'description': None, type: "Person"}, ... }], 'rels': [{'start': 'Ryanair Dac', 'description': 'Informed of the change in chief pilot', 'type': 'INFORMED', 'end': 'Irish Aviation Authority'}, {'start': 'Ryanair Dac', 'description': 'Dismissed after internal investigation found unacceptable behaviour', 'type': 'DISMISSED', 'end': 'Aidan Murray'}, ... ]}
Ora, dobbiamo preparare un prompt LLM che generi un riepilogo in linguaggio naturale basato sulle informazioni fornite dagli elementi della nostra comunità. Possiamo prendere spunto dal prompt utilizzato dai ricercatori .
Gli autori non solo hanno riassunto le comunità, ma hanno anche generato delle conclusioni per ciascuna di esse. Una conclusione può essere definita come un'informazione concisa riguardante un evento specifico o un pezzo di informazione. Un esempio del genere:
"summary": "Abila City Park as the central location", "explanation": "Abila City Park is the central entity in this community, serving as the location for the POK rally. This park is the common link between all other entities, suggesting its significance in the community. The park's association with the rally could potentially lead to issues such as public disorder or conflict, depending on the nature of the rally and the reactions it provokes. [records: Entities (5), Relationships (37, 38, 39, 40)]"
Il mio intuito mi suggerisce che estrarre i risultati con un'unica passata potrebbe non essere così completo come dovremmo, proprio come estrarre entità e relazioni.
Inoltre, non ho trovato alcun riferimento o esempio del loro utilizzo nel loro codice nei recuperatori di ricerca locali o globali. Di conseguenza, ci asterremo dall'estrarre i risultati in questo caso. O, come spesso affermano gli accademici: questo esercizio è lasciato al lettore. Inoltre, abbiamo anche saltato le affermazioni o l'estrazione delle informazioni sulle covariate , che a prima vista sembrano simili ai risultati.
Il prompt che utilizzeremo per produrre i riepiloghi della community è piuttosto semplice:
community_template = """Based on the provided nodes and relationships that belong to the same graph community, generate a natural language summary of the provided information: {community_info} Summary:""" # noqa: E501 community_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Given an input triples, generate the information summary. No pre-amble.", ), ("human", community_template), ] ) community_chain = community_prompt | llm | StrOutputParser()
L'unica cosa rimasta è trasformare le rappresentazioni della community in stringhe per ridurre il numero di token evitando il sovraccarico dei token JSON e racchiudere la catena come una funzione:
def prepare_string(data): nodes_str = "Nodes are:\n" for node in data['nodes']: node_id = node['id'] node_type = node['type'] if 'description' in node and node['description']: node_description = f", description: {node['description']}" else: node_description = "" nodes_str += f"id: {node_id}, type: {node_type}{node_description}\n" rels_str = "Relationships are:\n" for rel in data['rels']: start = rel['start'] end = rel['end'] rel_type = rel['type'] if 'description' in rel and rel['description']: description = f", description: {rel['description']}" else: description = "" rels_str += f"({start})-[:{rel_type}]->({end}){description}\n" return nodes_str + "\n" + rels_str def process_community(community): stringify_info = prepare_string(community) summary = community_chain.invoke({'community_info': stringify_info}) return {"community": community['communityId'], "summary": summary}
Ora possiamo generare riepiloghi della community per i livelli selezionati. Di nuovo, parallelizziamo le chiamate per un'esecuzione più rapida:
summaries = [] with ThreadPoolExecutor() as executor: futures = {executor.submit(process_community, community): community for community in community_info} for future in tqdm(as_completed(futures), total=len(futures), desc="Processing communities"): summaries.append(future.result())
Un aspetto che non ho menzionato è che gli autori affrontano anche il potenziale problema di superare la dimensione del contesto quando si inseriscono informazioni sulla comunità. Man mano che i grafici si espandono, anche le comunità possono crescere in modo significativo. Nel nostro caso, la comunità più grande era composta da 545 membri. Dato che GPT-4o ha una dimensione del contesto superiore a 100.000 token, abbiamo deciso di saltare questo passaggio.
Come passaggio finale, memorizzeremo i riepiloghi della community nel database:
graph.query(""" UNWIND $data AS row MERGE (c:__Community__ {id:row.community}) SET c.summary = row.summary """, params={"data": summaries})
La struttura del grafico finale:
Il grafico ora contiene i documenti originali, le entità e le relazioni estratte, nonché la struttura gerarchica della comunità e i riepiloghi.
Riepilogo
Gli autori del paper "From Local to Global" hanno fatto un ottimo lavoro nel dimostrare un nuovo approccio a GraphRAG. Mostrano come possiamo combinare e riassumere informazioni da vari documenti in una struttura gerarchica di knowledge graph.
Una cosa che non viene menzionata esplicitamente è che possiamo anche integrare fonti di dati strutturati in un grafico; l'input non deve essere limitato solo al testo non strutturato.
Ciò che apprezzo particolarmente del loro approccio di estrazione è che catturano descrizioni sia per i nodi che per le relazioni. Le descrizioni consentono al LLM di conservare più informazioni rispetto alla riduzione di tutto a soli ID dei nodi e tipi di relazione.
Inoltre, dimostrano che un singolo passaggio di estrazione sul testo potrebbe non catturare tutte le informazioni rilevanti e introdurre una logica per eseguire più passaggi, se necessario. Gli autori presentano anche un'idea interessante per eseguire riepiloghi su comunità di grafici, consentendoci di incorporare e indicizzare informazioni di argomento condensato su più fonti di dati.
Nel prossimo post del blog esamineremo le implementazioni del motore di ricerca locale e globale e parleremo di altri approcci che potremmo implementare in base alla struttura del grafico fornita.
Come sempre, il codice è disponibile su GitHub .
Questa volta ho caricato anche il dump del database in modo che possiate esplorare i risultati e sperimentare diverse opzioni di recupero.
È anche possibile importare questo dump in un'istanza Neo4j AuraDB gratuita per sempre , che possiamo utilizzare per le esplorazioni di recupero, poiché non abbiamo bisogno di algoritmi di Graph Data Science per questo scopo, ma solo di indici di pattern grafici, vettori e full-text.
Per saperne di più sulle integrazioni di Neo4j con tutti i framework GenAI e sugli algoritmi grafici pratici, leggi il mio libro "Graph Algorithms for Data Science".
Per saperne di più su questo argomento, unisciti a noi al NODES 2024 il 7 novembre, la nostra conferenza virtuale gratuita per sviluppatori su app intelligenti, knowledge graph e AI. Registrati ora !
L O A D I N G
. . . comments & more!
. . . comments & more!



