
























Sunt întotdeauna intrigat de noile abordări de implementare a generației de recuperare mărită (RAG) peste grafice, adesea numite GraphRAG. Cu toate acestea, se pare că fiecare are o implementare diferită în minte atunci când aud termenul GraphRAG. În această postare de blog, ne vom aprofunda în articolul „ De la local la global GraphRAG ” și în implementarea de către cercetătorii Microsoft. Vom acoperi partea de construcție și rezumare a graficului de cunoștințe și vom lăsa retrieverii pentru următoarea postare pe blog. Cercetătorii au fost atât de amabili încât ne-au oferit depozitul de cod și au și o pagină de proiect .
Abordarea adoptată în articolul menționat mai sus este destul de interesantă. Din câte am înțeles, implică utilizarea unui grafic de cunoștințe ca pas în conductă pentru condensarea și combinarea informațiilor din mai multe surse. Extragerea de entități și relații din text nu este nimic nou. Cu toate acestea, autorii introduc o idee nouă (cel puțin pentru mine) de a rezuma structura graficului condensat și informațiile înapoi ca text în limbaj natural. Conducta începe cu text introdus din documente, care sunt procesate pentru a genera un grafic. Graficul este apoi convertit înapoi în text în limbaj natural, unde textul generat conține informații condensate despre anumite entități sau comunități de grafice, răspândite anterior în mai multe documente.


La un nivel foarte înalt, intrarea în pipeline GraphRAG sunt documente sursă care conțin diverse informații. Documentele sunt procesate folosind un LLM pentru a extrage informații structurate despre entitățile care apar în lucrări împreună cu relațiile lor. Aceste informații structurate extrase sunt apoi utilizate pentru a construi un grafic de cunoștințe.
Avantajul utilizării unei reprezentări de date grafice de cunoștințe este că poate combina rapid și simplu informații din mai multe documente sau surse de date despre anumite entități. După cum am menționat, graficul de cunoștințe nu este însă singura reprezentare a datelor. După ce a fost construit graficul de cunoștințe, aceștia folosesc o combinație de algoritmi de grafic și solicitări LLM pentru a genera rezumate în limbaj natural ale comunităților de entități găsite în graficul de cunoștințe.
Aceste rezumate conțin apoi informații condensate răspândite în mai multe surse de date și documente pentru anumite entități și comunități.
Pentru o înțelegere mai detaliată a conductei, ne putem referi la descrierea pas cu pas furnizată în lucrarea originală.


Pași în curs — Imagine din hârtie GraphRAG , licențiată sub CC BY 4.0
Mai jos este un rezumat la nivel înalt al conductei pe care o vom folosi pentru a reproduce abordarea lor folosind Neo4j și LangChain.
Indexare — Generare de grafice
- Documente sursă în fragmente de text : documentele sursă sunt împărțite în bucăți de text mai mici pentru procesare.
- Bucăți de text la instanțele de elemente : Fiecare fragment de text este analizat pentru a extrage entități și relații, producând o listă de tupluri reprezentând aceste elemente.
- Instanțe de elemente la rezumate de elemente : entitățile și relațiile extrase sunt rezumate de LLM în blocuri de text descriptiv pentru fiecare element.
- Rezumate ale elementelor în comunități grafice : Aceste rezumate ale entităților formează un grafic, care este apoi împărțit în comunități folosind algoritmi precum Leiden pentru structura ierarhică.
- Graficul comunităților la rezumate ale comunității : rezumatele fiecărei comunități sunt generate cu LLM pentru a înțelege structura și semantica globală a setului de date.
Recuperare — Răspuns
- Rezumate ale comunității la răspunsurile globale : rezumatele comunității sunt folosite pentru a răspunde la o interogare a utilizatorului prin generarea de răspunsuri intermediare, care sunt apoi agregate într-un răspuns global final.
Rețineți că implementarea mea a fost făcută înainte ca codul lor să fie disponibil, așa că ar putea exista mici diferențe în abordarea de bază sau în solicitările LLM utilizate. Voi încerca să explic aceste diferențe pe măsură ce mergem mai departe.
Codul este disponibil pe GitHub .
Configurarea mediului Neo4j
Vom folosi Neo4j ca magazin de grafice de bază. Cel mai simplu mod de a începe este să utilizați o instanță gratuită a Neo4j Sandbox , care oferă instanțe cloud ale bazei de date Neo4j cu pluginul Graph Data Science instalat. Alternativ, puteți configura o instanță locală a bazei de date Neo4j descărcând aplicația Neo4j Desktop și creând o instanță locală a bazei de date. Dacă utilizați o versiune locală, asigurați-vă că instalați atât pluginurile APOC, cât și GDS. Pentru setările de producție, puteți utiliza instanța plătită, gestionată AuraDS (Data Science), care oferă pluginul GDS.
Începem prin a crea o instanță Neo4jGraph , care este învelișul de confort pe care l-am adăugat la LangChain:
from langchain_community.graphs import Neo4jGraph os.environ["NEO4J_URI"] = "bolt://44.202.208.177:7687" os.environ["NEO4J_USERNAME"] = "neo4j" os.environ["NEO4J_PASSWORD"] = "mast-codes-trails" graph = Neo4jGraph(refresh_schema=False)Setul de date
Vom folosi un set de date despre articole de știri pe care l-am creat cu ceva timp în urmă folosind API-ul Diffbot. L-am încărcat pe GitHub-ul meu pentru o reutilizare mai ușoară:
news = pd.read_csv( "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/news_articles.csv" ) news["tokens"] = [ num_tokens_from_string(f"{row['title']} {row['text']}") for i, row in news.iterrows() ] news.head()
Să examinăm primele două rânduri din setul de date.


Avem la dispoziție titlul și textul articolelor, împreună cu data publicării și numărul de simboluri folosind biblioteca tiktoken.
Text Chunking
Etapa de fragmentare a textului este crucială și are un impact semnificativ asupra rezultatelor din aval. Autorii lucrării au descoperit că utilizarea unor bucăți de text mai mici are ca rezultat extragerea mai multor entități în general.


Numărul de entități extrase dat de dimensiunea fragmentelor de text — Imagine din lucrarea GraphRAG , licențiată sub CC BY 4.0
După cum puteți vedea, utilizarea fragmentelor de text de 2.400 de jetoane are ca rezultat mai puține entități extrase decât atunci când foloseau 600 de jetoane. În plus, au identificat că LLM-urile ar putea să nu extragă toate entitățile la prima rulare. În acest caz, ei introduc o euristică pentru a efectua extracția de mai multe ori. Vom vorbi mai mult despre asta în secțiunea următoare.
Cu toate acestea, există întotdeauna compromisuri. Utilizarea unor bucăți de text mai mici poate duce la pierderea contextului și coreferențele unor entități specifice răspândite în documente. De exemplu, dacă un document menționează „Ioan” și „el” în propoziții separate, împărțirea textului în bucăți mai mici ar putea face neclar faptul că „el” se referă la Ioan. Unele dintre problemele coreferenței pot fi rezolvate folosind o strategie de suprapunere a fragmentelor de text, dar nu toate.
Să examinăm dimensiunea textelor articolelor noastre:
sns.histplot(news["tokens"], kde=False) plt.title('Distribution of chunk sizes') plt.xlabel('Token count') plt.ylabel('Frequency') plt.show()


Distribuția numărului de jetoane articole este aproximativ normală, cu un vârf de aproximativ 400 de jetoane. Frecvența fragmentelor crește treptat până la acest vârf, apoi scade simetric, indicând că majoritatea fragmentelor de text sunt aproape de marcajul de 400 de jetoane.
Datorită acestei distribuții, nu vom efectua nicio fragmentare a textului aici pentru a evita problemele de coreferență. În mod implicit, proiectul GraphRAG utilizează dimensiuni de 300 de jetoane cu 100 de jetoane de suprapunere.
Extragerea nodurilor și a relațiilor
Următorul pas este construirea cunoștințelor din fragmente de text. Pentru acest caz de utilizare, folosim un LLM pentru a extrage informații structurate sub formă de noduri și relații din text. Puteți examina solicitarea LLM pe care autorii au folosit-o în lucrare. Au solicitări LLM în care putem predefini etichetele nodurilor dacă este necesar, dar în mod implicit, acest lucru este opțional. În plus, relațiile extrase din documentația originală nu au un tip, ci doar o descriere. Îmi imaginez că motivul din spatele acestei alegeri este acela de a permite LLM să extragă și să rețină informații mai bogate și mai nuanțate ca relații. Dar este dificil să ai un grafic de cunoștințe curat, fără specificații de tip relație (descrierile ar putea intra într-o proprietate).
În implementarea noastră, vom folosi LLMGraphTransformer , care este disponibil în biblioteca LangChain. În loc să folosească inginerie pură promptă, așa cum o face implementarea din articolul articol, LLMGraphTransformer utilizează suportul de apelare a funcției încorporate pentru a extrage informații structurate (LLM-uri de ieșire structurată în LangChain). Puteți inspecta promptul de sistem :
from langchain_experimental.graph_transformers import LLMGraphTransformer from langchain_openai import ChatOpenAI llm = ChatOpenAI(temperature=0, model_name="gpt-4o") llm_transformer = LLMGraphTransformer( llm=llm, node_properties=["description"], relationship_properties=["description"] ) def process_text(text: str) -> List[GraphDocument]: doc = Document(page_content=text) return llm_transformer.convert_to_graph_documents([doc])
În acest exemplu, folosim GPT-4o pentru extragerea graficelor. Autorii instruiesc în mod specific LLM să extragă entități și relații și descrierile acestora . Cu implementarea LangChain, puteți utiliza atributele node_properties și relationship_properties pentru a specifica ce nod sau ce proprietăți de relație doriți să extragă LLM.
Diferența cu implementarea LLMGraphTransformer este că toate proprietățile nodurilor sau relațiilor sunt opționale, deci nu toate nodurile vor avea proprietatea description . Dacă am dori, am putea defini o extracție personalizată pentru a avea o proprietate description obligatorie, dar o vom omite în această implementare.
Vom paraleliza solicitările pentru a face extragerea graficului mai rapidă și vom stoca rezultatele în Neo4j:
MAX_WORKERS = 10 NUM_ARTICLES = 2000 graph_documents = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(process_text, f"{row['title']} {row['text']}") for i, row in news.head(NUM_ARTICLES).iterrows() ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): graph_document = future.result() graph_documents.extend(graph_document) graph.add_graph_documents( graph_documents, baseEntityLabel=True, include_source=True )
În acest exemplu, extragem informații grafice din 2.000 de articole și stocăm rezultatele în Neo4j. Am extras în jur de 13.000 de entități și 16.000 de relații. Iată un exemplu de document extras din grafic.


Este nevoie de aproximativ 35 (+/- 5) minute pentru a finaliza extracția și costă aproximativ 30 USD cu GPT-4o.
În acest pas, autorii introduc euristice pentru a decide dacă să extragă informațiile din grafic în mai multe treceri. De dragul simplității, vom face o singură trecere. Cu toate acestea, dacă am dori să facem mai multe treceri, am putea pune primele rezultate ale extragerii ca istoric conversațional și pur și simplu să instruim LLM că multe entități lipsesc și ar trebui să extragă mai multe, așa cum fac autorii GraphRAG.
Anterior, am menționat cât de vitală este dimensiunea fragmentului de text și cum afectează numărul de entități extrase. Deoarece nu am efectuat nicio fragmentare suplimentară a textului, putem evalua distribuția entităților extrase pe baza dimensiunii fragmentului de text:
entity_dist = graph.query( """ MATCH (d:Document) RETURN d.text AS text, count {(d)-[:MENTIONS]->()} AS entity_count """ ) entity_dist_df = pd.DataFrame.from_records(entity_dist) entity_dist_df["token_count"] = [ num_tokens_from_string(str(el)) for el in entity_dist_df["text"] ] # Scatter plot with regression line sns.lmplot( x="token_count", y="entity_count", data=entity_dist_df, line_kws={"color": "red"} ) plt.title("Entity Count vs Token Count Distribution") plt.xlabel("Token Count") plt.ylabel("Entity Count") plt.show()


Graficul de dispersie arată că, deși există o tendință pozitivă, indicată de linia roșie, relația este subliniară. Majoritatea punctelor de date se grupează la un număr mai mic de entități, chiar dacă numărul de simboluri crește. Acest lucru indică faptul că numărul de entități extrase nu se scalează proporțional cu dimensiunea fragmentelor de text. Deși există unele valori aberante, modelul general arată că un număr mai mare de jetoane nu duce în mod constant la un număr mai mare de entități. Acest lucru validează constatarea autorilor că dimensiunile mai mici ale fragmentelor de text vor extrage mai multe informații.
De asemenea, m-am gândit că ar fi interesant să inspectez distribuțiile gradelor de nod ale graficului construit. Următorul cod preia și vizualizează distribuțiile de grade de nod:
degree_dist = graph.query( """ MATCH (e:__Entity__) RETURN count {(e)-[:!MENTIONS]-()} AS node_degree """ ) degree_dist_df = pd.DataFrame.from_records(degree_dist) # Calculate mean and median mean_degree = np.mean(degree_dist_df['node_degree']) percentiles = np.percentile(degree_dist_df['node_degree'], [25, 50, 75, 90]) # Create a histogram with a logarithmic scale plt.figure(figsize=(12, 6)) sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue') # Use a logarithmic scale for the x-axis plt.yscale('log') # Adding labels and title plt.xlabel('Node Degree') plt.ylabel('Count (log scale)') plt.title('Node Degree Distribution') # Add mean, median, and percentile lines plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'Mean: {mean_degree:.2f}') plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25th Percentile: {percentiles[0]:.2f}') plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50th Percentile: {percentiles[1]:.2f}') plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75th Percentile: {percentiles[2]:.2f}') plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90th Percentile: {percentiles[3]:.2f}') # Add legend plt.legend() # Show the plot plt.show()


Distribuția gradului de nod urmează un model de lege de putere, indicând că majoritatea nodurilor au foarte puține conexiuni, în timp ce câteva noduri sunt foarte conectate. Gradul mediu este 2,45, iar mediana este 1,00, arătând că mai mult de jumătate dintre noduri au o singură conexiune. Majoritatea nodurilor (75 la sută) au două sau mai puține conexiuni, iar 90 la sută au cinci sau mai puține. Această distribuție este tipică pentru multe rețele din lumea reală, unde un număr mic de hub-uri au multe conexiuni, iar majoritatea nodurilor au puține.
Deoarece ambele descrieri de noduri și relații nu sunt proprietăți obligatorii, vom examina, de asemenea, câte au fost extrase:
graph.query(""" MATCH (n:`__Entity__`) RETURN "node" AS type, count(*) AS total_count, count(n.description) AS non_null_descriptions UNION ALL MATCH (n)-[r:!MENTIONS]->() RETURN "relationship" AS type, count(*) AS total_count, count(r.description) AS non_null_descriptions """)
Rezultatele arată că 5.926 de noduri din 12.994 (45,6 la sută) au proprietatea de descriere. Pe de altă parte, doar 5.569 de relații din 15.921 (35 la sută) au o astfel de proprietate.
Rețineți că, datorită naturii probabilistice a LLM-urilor, numerele pot varia în funcție de rulări și diferite date sursă, LLM-uri și solicitări.
Rezoluție de entitate
Rezolvarea entităților (deduplicarea) este crucială atunci când construiți grafice de cunoștințe, deoarece asigură că fiecare entitate este reprezentată în mod unic și precis, prevenind duplicarea și îmbinarea înregistrărilor care se referă la aceeași entitate din lumea reală. Acest proces este esențial pentru menținerea integrității și consecvenței datelor în cadrul graficului. Fără rezoluția entităților, graficele de cunoștințe ar avea de suferit din cauza datelor fragmentate și inconsecvente, ceea ce duce la erori și informații nesigure.


Această imagine demonstrează modul în care o singură entitate din lumea reală poate apărea sub nume ușor diferite în documente diferite și, în consecință, în graficul nostru.
Mai mult decât atât, datele rare devin o problemă semnificativă fără rezolvarea entității. Datele incomplete sau parțiale din diverse surse pot duce la informații dispersate și deconectate, ceea ce face dificilă formarea unei înțelegeri coerente și cuprinzătoare a entităților. Rezolvarea precisă a entității abordează acest lucru prin consolidarea datelor, completarea golurilor și crearea unei imagini unificate a fiecărei entități.


Înainte/după utilizarea rezoluției entității Senzing pentru a conecta datele privind scurgerile offshore ale Consorțiului Internațional de Jurnalişti de Investigație (ICIJ) — Imagine de la Paco Nathan
Partea din stânga a vizualizării prezintă un grafic rar și neconectat. Cu toate acestea, așa cum se arată în partea dreaptă, un astfel de grafic poate deveni bine conectat cu o rezoluție eficientă a entității.
În general, rezoluția entităților îmbunătățește eficiența regăsirii și integrării datelor, oferind o imagine coerentă a informațiilor din diferite surse. În cele din urmă, permite răspunsuri mai eficiente la întrebări, bazate pe un grafic de cunoștințe fiabil și complet.
Din păcate, autorii lucrării GraphRAG nu au inclus niciun cod de rezoluție a entității în repo-ul lor, deși îl menționează în lucrarea lor. Un motiv pentru a lăsa acest cod afară ar putea fi faptul că este dificil să implementați o rezoluție de entități robustă și performantă pentru orice domeniu dat. Puteți implementa euristici personalizate pentru diferite noduri atunci când aveți de-a face cu tipuri predefinite de noduri (când acestea nu sunt predefinite, nu sunt suficient de consistente, cum ar fi compania, organizația, afacerea etc.). Cu toate acestea, dacă etichetele sau tipurile nodurilor nu sunt cunoscute dinainte, ca în cazul nostru, aceasta devine o problemă și mai grea. Cu toate acestea, vom implementa o versiune de rezoluție a entităților în proiectul nostru aici, combinând încorporarea textului și algoritmii grafici cu distanța cuvintelor și LLM-uri.


Procesul nostru de rezolvare a entității implică următorii pași:
- Entități din grafic — Începeți cu toate entitățile din grafic.
- K-nearest graph — Construiți un k-nearest vecin graph, conectând entități similare pe baza înglobărilor de text.
- Componente slab conectate — Identificați componentele slab conectate în cel mai apropiat grafic k, grupând entitățile care sunt probabil să fie similare. Adăugați un pas de filtrare a distanței de cuvinte după ce aceste componente au fost identificate.
- Evaluare LLM — Utilizați un LLM pentru a evalua aceste componente și a decide dacă entitățile din fiecare componentă ar trebui fuzionate, rezultând o decizie finală privind rezoluția entității (de exemplu, fuzionarea „Silicon Valley Bank” și „Silicon_Valley_Bank” în timp ce respinge fuziunea pentru diferite date precum „16 septembrie 2023” și „2 septembrie 2023”).
Începem prin a calcula încorporarea textului pentru proprietățile de nume și descriere ale entităților. Putem folosi metoda from_existing_graph în integrarea Neo4jVector în LangChain pentru a realiza acest lucru:
vector = Neo4jVector.from_existing_graph( OpenAIEmbeddings(), node_label='__Entity__', text_node_properties=['id', 'description'], embedding_node_property='embedding' )
Putem folosi aceste înglobări pentru a găsi potențiali candidați care sunt similari pe baza distanței cosinus a acestor înglobări. Vom folosi algoritmi grafici disponibili în biblioteca Graph Data Science (GDS) ; prin urmare, putem folosi clientul GDS Python pentru ușurință în utilizare într-un mod Pythonic:
from graphdatascience import GraphDataScience gds = GraphDataScience( os.environ["NEO4J_URI"], auth=(os.environ["NEO4J_USERNAME"], os.environ["NEO4J_PASSWORD"]) )
Dacă nu sunteți familiarizat cu biblioteca GDS, mai întâi trebuie să proiectăm un grafic în memorie înainte de a putea executa orice algoritm de grafic.


În primul rând, graficul stocat Neo4j este proiectat într-un grafic în memorie pentru o procesare și o analiză mai rapidă. Apoi, un algoritm de grafic este executat pe graficul din memorie. Opțional, rezultatele algoritmului pot fi stocate înapoi în baza de date Neo4j. Aflați mai multe despre el în documentație .
Pentru a crea graficul k-cel mai apropiat vecin, vom proiecta toate entitățile împreună cu înglobările de text ale acestora:
G, result = gds.graph.project( "entities", # Graph name "__Entity__", # Node projection "*", # Relationship projection nodeProperties=["embedding"] # Configuration parameters )
Acum că graficul este proiectat sub numele entities , putem executa algoritmi de grafic. Vom începe prin a construi un grafic k-cel mai apropiat . Cei doi parametri cei mai importanți care influențează cât de rar sau dens va fi cel mai apropiat grafic k sunt similarityCutoff și topK . topK este numărul de vecini de găsit pentru fiecare nod, cu o valoare minimă de 1. similarityCutoff filtrează relațiile cu similaritate sub acest prag. Aici, vom folosi un topK implicit de 10 și o limită de similaritate relativ mare de 0,95. Folosirea unei limite de similaritate ridicată, cum ar fi 0,95, asigură că numai perechile foarte asemănătoare sunt considerate potriviri, minimizând falsele pozitive și îmbunătățind acuratețea.


Deoarece dorim să stocăm rezultatele înapoi în graficul proiectat în memorie în loc de graficul de cunoștințe, vom folosi modul mutate al algoritmului:
similarity_threshold = 0.95 gds.knn.mutate( G, nodeProperties=['embedding'], mutateRelationshipType= 'SIMILAR', mutateProperty= 'score', similarityCutoff=similarity_threshold )
Următorul pas este identificarea grupurilor de entități care sunt conectate cu noile relații de similitudine deduse. Identificarea grupurilor de noduri conectate este un proces frecvent în analiza rețelei, numit adesea detectarea comunității sau clustering , care implică găsirea subgrupurilor de noduri conectate dens. În acest exemplu, vom folosi algoritmul Componente slab conectate , care ne ajută să găsim părți ale unui grafic unde toate nodurile sunt conectate, chiar dacă ignorăm direcția conexiunilor.


Folosim modul write al algoritmului pentru a stoca rezultatele înapoi în baza de date (graficul stocat):
gds.wcc.write( G, writeProperty="wcc", relationshipTypes=["SIMILAR"] )
Comparația de încorporare a textului ajută la găsirea potențialelor duplicate, dar este doar o parte a procesului de rezoluție a entității. De exemplu, Google și Apple sunt foarte apropiate în spațiul de încorporare (asemănare de 0,96 cosinus folosind modelul de încorporare ada-002 ). Același lucru este valabil și pentru BMW și Mercedes Benz (asemănarea cosinusului de 0,97). Similitudinea ridicată de încorporare a textului este un început bun, dar o putem îmbunătăți. Prin urmare, vom adăuga un filtru suplimentar care să permită doar perechi de cuvinte cu o distanță de text de trei sau mai puțin (înseamnă că doar caracterele pot fi modificate):
word_edit_distance = 3 potential_duplicate_candidates = graph.query( """MATCH (e:`__Entity__`) WHERE size(e.id) > 3 // longer than 3 characters WITH e.wcc AS community, collect(e) AS nodes, count(*) AS count WHERE count > 1 UNWIND nodes AS node // Add text distance WITH distinct [n IN nodes WHERE apoc.text.distance(toLower(node.id), toLower(n.id)) < $distance OR node.id CONTAINS n.id | n.id] AS intermediate_results WHERE size(intermediate_results) > 1 WITH collect(intermediate_results) AS results // combine groups together if they share elements UNWIND range(0, size(results)-1, 1) as index WITH results, index, results[index] as result WITH apoc.coll.sort(reduce(acc = result, index2 IN range(0, size(results)-1, 1) | CASE WHEN index <> index2 AND size(apoc.coll.intersection(acc, results[index2])) > 0 THEN apoc.coll.union(acc, results[index2]) ELSE acc END )) as combinedResult WITH distinct(combinedResult) as combinedResult // extra filtering WITH collect(combinedResult) as allCombinedResults UNWIND range(0, size(allCombinedResults)-1, 1) as combinedResultIndex WITH allCombinedResults[combinedResultIndex] as combinedResult, combinedResultIndex, allCombinedResults WHERE NOT any(x IN range(0,size(allCombinedResults)-1,1) WHERE x <> combinedResultIndex AND apoc.coll.containsAll(allCombinedResults[x], combinedResult) ) RETURN combinedResult """, params={'distance': word_edit_distance})
Această declarație Cypher este puțin mai implicată, iar interpretarea ei depășește scopul acestei postări pe blog. Puteți oricând cere unui LLM să îl interpreteze.


În plus, limita de distanță a cuvântului ar putea fi o funcție de lungimea cuvântului în loc de un singur număr, iar implementarea ar putea fi mai scalabilă.
Ceea ce este important este că generează grupuri de entități potențiale pe care am putea dori să le fuzionam. Iată o listă de noduri potențiale de îmbinat:
{'combinedResult': ['Sinn Fein', 'Sinn Féin']}, {'combinedResult': ['Government', 'Governments']}, {'combinedResult': ['Unreal Engine', 'Unreal_Engine']}, {'combinedResult': ['March 2016', 'March 2020', 'March 2022', 'March_2023']}, {'combinedResult': ['Humana Inc', 'Humana Inc.']}, {'combinedResult': ['New York Jets', 'New York Mets']}, {'combinedResult': ['Asia Pacific', 'Asia-Pacific', 'Asia_Pacific']}, {'combinedResult': ['Bengaluru', 'Mangaluru']}, {'combinedResult': ['US Securities And Exchange Commission', 'Us Securities And Exchange Commission']}, {'combinedResult': ['Jp Morgan', 'Jpmorgan']}, {'combinedResult': ['Brighton', 'Brixton']},
După cum puteți vedea, abordarea noastră de rezoluție funcționează mai bine pentru unele tipuri de noduri decât pentru altele. Pe baza unei examinări rapide, pare să funcționeze mai bine pentru oameni și organizații, în timp ce este destul de rău pentru întâlniri. Dacă am folosi tipuri de noduri predefinite, am putea pregăti diferite euristici pentru diferite tipuri de noduri. În acest exemplu, nu avem etichete de noduri predefinite, așa că vom apela la un LLM pentru a lua decizia finală dacă entitățile ar trebui fuzionate sau nu.
În primul rând, trebuie să formulăm promptul LLM pentru a ghida și informa în mod eficient decizia finală cu privire la îmbinarea nodurilor:
system_prompt = """You are a data processing assistant. Your task is to identify duplicate entities in a list and decide which of them should be merged. The entities might be slightly different in format or content, but essentially refer to the same thing. Use your analytical skills to determine duplicates. Here are the rules for identifying duplicates: 1. Entities with minor typographical differences should be considered duplicates. 2. Entities with different formats but the same content should be considered duplicates. 3. Entities that refer to the same real-world object or concept, even if described differently, should be considered duplicates. 4. If it refers to different numbers, dates, or products, do not merge results """ user_template = """ Here is the list of entities to process: {entities} Please identify duplicates, merge them, and provide the merged list. """
Îmi place întotdeauna să folosesc metoda with_structured_output în LangChain când mă aștept la ieșirea de date structurate pentru a evita nevoia de a analiza manual ieșirile.
Aici, vom defini rezultatul ca o list of lists , în care fiecare listă interioară conține entitățile care ar trebui îmbinate. Această structură este utilizată pentru a gestiona scenarii în care, de exemplu, intrarea ar putea fi [Sony, Sony Inc, Google, Google Inc] . În astfel de cazuri, ați dori să fuzionați „Sony” și „Sony Inc” separat de „Google” și „Google Inc”.
class DuplicateEntities(BaseModel): entities: List[str] = Field( description="Entities that represent the same object or real-world entity and should be merged" ) class Disambiguate(BaseModel): merge_entities: Optional[List[DuplicateEntities]] = Field( description="Lists of entities that represent the same object or real-world entity and should be merged" ) extraction_llm = ChatOpenAI(model_name="gpt-4o").with_structured_output( Disambiguate )
Apoi, integrăm promptul LLM cu ieșirea structurată pentru a crea un lanț utilizând sintaxa LangChain Expression Language (LCEL) și o încapsulăm într-o funcție disambiguate .
extraction_chain = extraction_prompt | extraction_llm def entity_resolution(entities: List[str]) -> Optional[List[List[str]]]: return [ el.entities for el in extraction_chain.invoke({"entities": entities}).merge_entities ]
Trebuie să rulăm toate nodurile potențiale candidate prin funcția entity_resolution pentru a decide dacă ar trebui să fie îmbinate. Pentru a accelera procesul, vom paraleliza din nou apelurile LLM:
merged_entities = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(entity_resolution, el['combinedResult']) for el in potential_duplicate_candidates ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): to_merge = future.result() if to_merge: merged_entities.extend(to_merge)
Pasul final al rezoluției entității implică preluarea rezultatelor din LLM entity_resolution și scrierea lor înapoi în baza de date prin îmbinarea nodurilor specificate:
graph.query(""" UNWIND $data AS candidates CALL { WITH candidates MATCH (e:__Entity__) WHERE e.id IN candidates RETURN collect(e) AS nodes } CALL apoc.refactor.mergeNodes(nodes, {properties: { description:'combine', `.*`: 'discard' }}) YIELD node RETURN count(*) """, params={"data": merged_entities})
Această rezoluție a entității nu este perfectă, dar ne oferă un punct de plecare pe care ne putem îmbunătăți. În plus, putem îmbunătăți logica pentru a determina ce entități ar trebui reținute.
Rezumarea elementelor
În pasul următor, autorii efectuează un pas de rezumare a elementelor. În esență, fiecare nod și relație sunt trecute printr-un prompt de rezumare a entității . Autorii notează noutatea și interesul abordării lor:
„În general, utilizarea noastră a textului descriptiv bogat pentru noduri omogene într-o structură de grafic potențial zgomotoasă este aliniată atât cu capacitățile LLM-urilor, cât și cu nevoile de rezumare globală, axată pe interogări. Aceste calități diferențiază, de asemenea, indicele nostru grafic de graficele tipice de cunoștințe, care se bazează pe triple de cunoștințe concise și consecvente (subiect, predicat, obiect) pentru sarcinile de raționament din aval.”
Ideea este incitantă. Extragem în continuare ID-uri de subiect și obiect sau nume din text, ceea ce ne permite să legăm relații cu entitățile corecte, chiar și atunci când entitățile apar în mai multe bucăți de text. Cu toate acestea, relațiile nu sunt reduse la un singur tip. În schimb, tipul de relație este de fapt un text liber, care ne permite să reținem informații mai bogate și mai nuanțate.
În plus, informațiile despre entitate sunt rezumate folosind un LLM, permițându-ne să încorporam și să indexăm aceste informații și entități mai eficient pentru o regăsire mai precisă.
S-ar putea argumenta că această informație mai bogată și mai nuanțată ar putea fi reținută și prin adăugarea de proprietăți suplimentare, eventual arbitrare, de noduri și relații. O problemă cu proprietățile arbitrare ale nodurilor și ale relațiilor este că ar putea fi dificil să extragi informațiile în mod consecvent, deoarece LLM-ul poate folosi nume de proprietăți diferite sau se poate concentra pe diferite detalii la fiecare execuție.
Unele dintre aceste probleme ar putea fi rezolvate folosind nume de proprietate predefinite cu informații suplimentare despre tip și descriere. În acest caz, veți avea nevoie de un expert în materie pentru a ajuta la definirea acelor proprietăți, lăsând puțin loc unui LLM pentru a extrage orice informație vitală în afara descrierilor predefinite.
Este o abordare interesantă de a reprezenta informații mai bogate într-un grafic de cunoștințe.
O problemă potențială cu pasul de rezumare a elementului este că nu se scalează bine, deoarece necesită un apel LLM pentru fiecare entitate și relație din grafic. Graficul nostru este relativ mic, cu 13.000 de noduri și 16.000 de relații. Chiar și pentru un grafic atât de mic, am avea nevoie de 29.000 de apeluri LLM și fiecare apel ar folosi câteva sute de jetoane, ceea ce îl face destul de costisitor și consuma mult timp. Prin urmare, vom evita acest pas aici. Putem folosi în continuare proprietățile descrierii extrase în timpul procesării inițiale a textului.
Construirea și rezumarea comunităților
Ultimul pas în procesul de construire și indexare a graficului implică identificarea comunităților în cadrul graficului. În acest context, o comunitate este un grup de noduri care sunt mai dens conectate între ele decât cu restul graficului, indicând un nivel mai ridicat de interacțiune sau similaritate. Următoarea vizualizare arată un exemplu de rezultate ale detectării comunității.


Odată ce aceste comunități de entități sunt identificate cu un algoritm de grupare, un LLM generează un rezumat pentru fiecare comunitate, oferind informații despre caracteristicile și relațiile lor individuale.
Din nou, folosim biblioteca Graph Data Science. Începem prin proiectarea unui grafic în memorie. Pentru a urmări cu exactitate articolul original, vom proiecta graficul entităților ca o rețea ponderată nedirecționată, unde rețeaua reprezintă numărul de conexiuni între două entități:
G, result = gds.graph.project( "communities", # Graph name "__Entity__", # Node projection { "_ALL_": { "type": "*", "orientation": "UNDIRECTED", "properties": {"weight": {"property": "*", "aggregation": "COUNT"}}, } }, )
Autorii au folosit algoritmul Leiden , o metodă de grupare ierarhică, pentru a identifica comunitățile din grafic. Un avantaj al utilizării unui algoritm ierarhic de detectare a comunității este capacitatea de a examina comunitățile la mai multe niveluri de granularitate. Autorii sugerează rezumarea tuturor comunităților la fiecare nivel, oferind o înțelegere cuprinzătoare a structurii graficului.
În primul rând, vom folosi algoritmul Weakly Connected Components (WCC) pentru a evalua conectivitatea graficului nostru. Acest algoritm identifică secțiuni izolate în cadrul graficului, ceea ce înseamnă că detectează subseturi de noduri sau componente care sunt conectate între ele, dar nu și cu restul graficului. Aceste componente ne ajută să înțelegem fragmentarea în cadrul rețelei și să identificăm grupuri de noduri care sunt independente de altele. WCC este vital pentru analiza structurii generale și a conectivității graficului.
wcc = gds.wcc.stats(G) print(f"Component count: {wcc['componentCount']}") print(f"Component distribution: {wcc['componentDistribution']}") # Component count: 1119 # Component distribution: { # "min":1, # "p5":1, # "max":9109, # "p999":43, # "p99":19, # "p1":1, # "p10":1, # "p90":7, # "p50":2, # "p25":1, # "p75":4, # "p95":10, # "mean":11.3 }
Rezultatele algoritmului WCC au identificat 1.119 componente distincte. În special, cea mai mare componentă cuprinde 9.109 noduri, comune în rețelele din lumea reală, unde o singură super-componentă coexistă cu numeroase componente izolate mai mici. Cea mai mică componentă are un nod, iar dimensiunea medie a componentei este de aproximativ 11,3 noduri.
În continuare, vom rula algoritmul Leiden, care este disponibil și în biblioteca GDS și vom activa parametrul includeIntermediateCommunities pentru a returna și stoca comunitățile la toate nivelurile. De asemenea, am inclus un parametru relationshipWeightProperty pentru a rula varianta ponderată a algoritmului Leiden. Utilizarea modului write al algoritmului stochează rezultatele ca o proprietate a nodului.
gds.leiden.write( G, writeProperty="communities", includeIntermediateCommunities=True, relationshipWeightProperty="weight", )
Algoritmul a identificat cinci niveluri de comunități, cel mai înalt (nivelul cel mai puțin granular unde comunitățile sunt cele mai mari) având 1.188 de comunități (spre deosebire de 1.119 componente). Iată vizualizarea comunităților de la ultimul nivel folosind Gephi.


Vizualizarea a peste 1.000 de comunități este dificilă; chiar și alegerea culorilor pentru fiecare este practic imposibil. Cu toate acestea, fac interpretări artistice frumoase.
Bazându-ne pe aceasta, vom crea un nod distinct pentru fiecare comunitate și vom reprezenta structura lor ierarhică ca un graf interconectat. Mai târziu, vom stoca și rezumatele comunității și alte atribute ca proprietăți ale nodurilor.
graph.query(""" MATCH (e:`__Entity__`) UNWIND range(0, size(e.communities) - 1 , 1) AS index CALL { WITH e, index WITH e, index WHERE index = 0 MERGE (c:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET c.level = index MERGE (e)-[:IN_COMMUNITY]->(c) RETURN count(*) AS count_0 } CALL { WITH e, index WITH e, index WHERE index > 0 MERGE (current:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET current.level = index MERGE (previous:`__Community__` {id: toString(index - 1) + '-' + toString(e.communities[index - 1])}) ON CREATE SET previous.level = index - 1 MERGE (previous)-[:IN_COMMUNITY]->(current) RETURN count(*) AS count_1 } RETURN count(*) """)
Autorii introduc, de asemenea, un community rank , indicând numărul de bucăți de text distincte în care apar entitățile din cadrul comunității:
graph.query(""" MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(:__Entity__)<-[:MENTIONS]-(d:Document) WITH c, count(distinct d) AS rank SET c.community_rank = rank; """)
Acum să examinăm un exemplu de structură ierarhică cu multe comunități intermediare care fuzionează la niveluri superioare. Comunitățile nu se suprapun, ceea ce înseamnă că fiecare entitate aparține exact unei singure comunități la fiecare nivel.


Imaginea reprezintă o structură ierarhică rezultată din algoritmul de detectare a comunității Leiden. Nodurile violet reprezintă entități individuale, în timp ce nodurile portocalii reprezintă comunități ierarhice.
Ierarhia arată organizarea acestor entități în diferite comunități, comunitățile mai mici fuzionarea în altele mai mari la niveluri superioare.
Să examinăm acum cum comunitățile mai mici fuzionează la niveluri superioare.

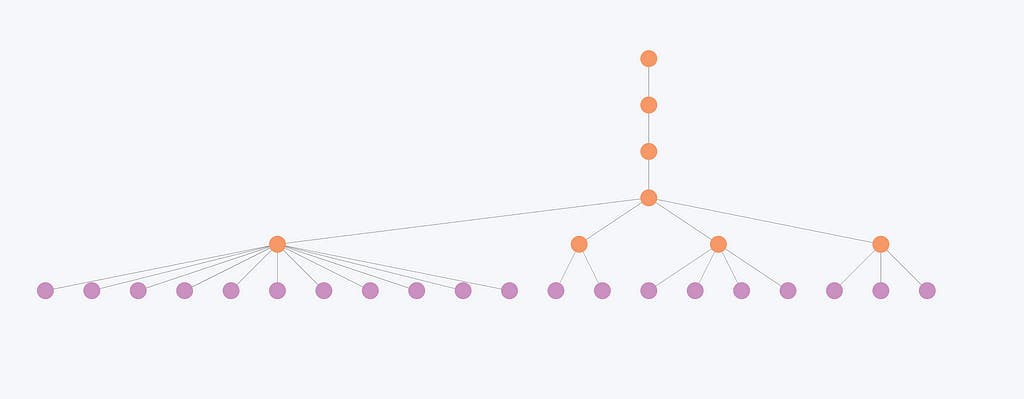
Această imagine ilustrează faptul că entitățile mai puțin conectate și, în consecință, comunitățile mai mici experimentează schimbări minime la niveluri. De exemplu, structura comunității de aici se schimbă doar în primele două niveluri, dar rămâne identică pentru ultimele trei niveluri. În consecință, nivelurile ierarhice par adesea redundante pentru aceste entități, deoarece organizația generală nu se modifică semnificativ la diferite niveluri.
Să examinăm mai detaliat numărul de comunități și dimensiunile acestora și diferitele niveluri:
community_size = graph.query( """ MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(e:__Entity__) WITH c, count(distinct e) AS entities RETURN split(c.id, '-')[0] AS level, entities """ ) community_size_df = pd.DataFrame.from_records(community_size) percentiles_data = [] for level in community_size_df["level"].unique(): subset = community_size_df[community_size_df["level"] == level]["entities"] num_communities = len(subset) percentiles = np.percentile(subset, [25, 50, 75, 90, 99]) percentiles_data.append( [ level, num_communities, percentiles[0], percentiles[1], percentiles[2], percentiles[3], percentiles[4], max(subset) ] ) # Create a DataFrame with the percentiles percentiles_df = pd.DataFrame( percentiles_data, columns=[ "Level", "Number of communities", "25th Percentile", "50th Percentile", "75th Percentile", "90th Percentile", "99th Percentile", "Max" ], ) percentiles_df


În implementarea inițială, comunitățile de la fiecare nivel au fost rezumate. În cazul nostru, ar fi 8.590 de comunități și, în consecință, 8.590 de apeluri LLM. Aș susține că, în funcție de structura ierarhică a comunității, nu trebuie rezumat fiecare nivel. De exemplu, diferența dintre ultimul și ultimul nivel este de doar patru comunități (1.192 față de 1.188). Prin urmare, am crea o mulțime de rezumate redundante. O soluție este crearea unei implementări care să poată face un singur rezumat pentru comunitățile de la diferite niveluri care nu se schimbă; alta ar fi să prăbușim ierarhiile comunității care nu se schimbă.
De asemenea, nu sunt sigur dacă vrem să rezumam comunitățile cu un singur membru, deoarece s-ar putea să nu ofere prea multă valoare sau informații. Aici, vom rezuma comunitățile de la nivelurile 0, 1 și 4. În primul rând, trebuie să le recuperăm informațiile din baza de date:
community_info = graph.query(""" MATCH (c:`__Community__`)<-[:IN_COMMUNITY*]-(e:__Entity__) WHERE c.level IN [0,1,4] WITH c, collect(e ) AS nodes WHERE size(nodes) > 1 CALL apoc.path.subgraphAll(nodes[0], { whitelistNodes:nodes }) YIELD relationships RETURN c.id AS communityId, [n in nodes | {id: n.id, description: n.description, type: [el in labels(n) WHERE el <> '__Entity__'][0]}] AS nodes, [r in relationships | {start: startNode(r).id, type: type(r), end: endNode(r).id, description: r.description}] AS rels """)
În momentul de față, informațiile comunității au următoarea structură:
{'communityId': '0-6014', 'nodes': [{'id': 'Darrell Hughes', 'description': None, type:"Person"}, {'id': 'Chief Pilot', 'description': None, type: "Person"}, ... }], 'rels': [{'start': 'Ryanair Dac', 'description': 'Informed of the change in chief pilot', 'type': 'INFORMED', 'end': 'Irish Aviation Authority'}, {'start': 'Ryanair Dac', 'description': 'Dismissed after internal investigation found unacceptable behaviour', 'type': 'DISMISSED', 'end': 'Aidan Murray'}, ... ]}
Acum, trebuie să pregătim un prompt LLM care generează un rezumat în limbaj natural bazat pe informațiile furnizate de elementele comunității noastre. Ne putem inspira din indemnul folosit de cercetători .
Autorii nu numai că au rezumat comunitățile, dar au generat și constatări pentru fiecare dintre ele. O constatare poate fi definită ca o informație concisă cu privire la un anumit eveniment sau o informație. Un astfel de exemplu:
"summary": "Abila City Park as the central location", "explanation": "Abila City Park is the central entity in this community, serving as the location for the POK rally. This park is the common link between all other entities, suggesting its significance in the community. The park's association with the rally could potentially lead to issues such as public disorder or conflict, depending on the nature of the rally and the reactions it provokes. [records: Entities (5), Relationships (37, 38, 39, 40)]"
Intuiția mea sugerează că extragerea constatărilor cu o singură trecere ar putea să nu fie atât de cuprinzătoare pe cât avem nevoie, la fel ca extragerea de entități și relații.
În plus, nu am găsit nicio referință sau exemple de utilizare a acestora în codul lor, nici în retriever-urile de căutare locale, nici globale. Ca urmare, ne vom abține de la extragerea constatărilor în acest caz. Sau, așa cum spun adesea academicienii: Acest exercițiu este lăsat la latitudinea cititorului. În plus, am omis, de asemenea, revendicările sau extragerea informațiilor covariabile , care arată similar cu constatările la prima vedere.
Solicitarea pe care o vom folosi pentru a produce rezumatele comunității este destul de simplă:
community_template = """Based on the provided nodes and relationships that belong to the same graph community, generate a natural language summary of the provided information: {community_info} Summary:""" # noqa: E501 community_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Given an input triples, generate the information summary. No pre-amble.", ), ("human", community_template), ] ) community_chain = community_prompt | llm | StrOutputParser()
Singurul lucru rămas este să transformați reprezentările comunității în șiruri de caractere pentru a reduce numărul de jetoane evitând token-ul JSON și să împachetați lanțul ca o funcție:
def prepare_string(data): nodes_str = "Nodes are:\n" for node in data['nodes']: node_id = node['id'] node_type = node['type'] if 'description' in node and node['description']: node_description = f", description: {node['description']}" else: node_description = "" nodes_str += f"id: {node_id}, type: {node_type}{node_description}\n" rels_str = "Relationships are:\n" for rel in data['rels']: start = rel['start'] end = rel['end'] rel_type = rel['type'] if 'description' in rel and rel['description']: description = f", description: {rel['description']}" else: description = "" rels_str += f"({start})-[:{rel_type}]->({end}){description}\n" return nodes_str + "\n" + rels_str def process_community(community): stringify_info = prepare_string(community) summary = community_chain.invoke({'community_info': stringify_info}) return {"community": community['communityId'], "summary": summary}
Acum putem genera rezumate ale comunității pentru nivelurile selectate. Din nou, paralelizăm apelurile pentru o execuție mai rapidă:
summaries = [] with ThreadPoolExecutor() as executor: futures = {executor.submit(process_community, community): community for community in community_info} for future in tqdm(as_completed(futures), total=len(futures), desc="Processing communities"): summaries.append(future.result())
Un aspect pe care nu l-am menționat este că autorii abordează și problema potențială a depășirii dimensiunii contextului atunci când introduc informații despre comunitate. Pe măsură ce graficele se extind, comunitățile pot crește semnificativ și ele. În cazul nostru, cea mai mare comunitate cuprindea 545 de membri. Având în vedere că GPT-4o are o dimensiune a contextului care depășește 100.000 de jetoane, am decis să omitem acest pas.
Ca pas final, vom stoca rezumatele comunității înapoi în baza de date:
graph.query(""" UNWIND $data AS row MERGE (c:__Community__ {id:row.community}) SET c.summary = row.summary """, params={"data": summaries})
Structura finală a graficului:


Graficul conține acum documentele originale, entitățile extrase și relațiile, precum și structura comunității ierarhice și rezumate.
Rezumat
Autorii lucrării „De la local la global” au făcut o treabă grozavă demonstrând o nouă abordare a GraphRAG. Ele arată cum putem combina și rezuma informațiile din diverse documente într-o structură ierarhică a graficului de cunoștințe.
Un lucru care nu este menționat în mod explicit este că putem integra și surse de date structurate într-un grafic; intrarea nu trebuie să se limiteze doar la text nestructurat.
Ceea ce apreciez în mod deosebit la abordarea lor de extracție este că captează descrieri atât pentru noduri, cât și pentru relații. Descrierile permit LLM să rețină mai multe informații decât să reducă totul la doar ID-uri de noduri și tipuri de relații.
În plus, ei demonstrează că o singură trecere de extragere peste text ar putea să nu capteze toate informațiile relevante și să introducă o logică pentru a efectua mai multe treceri, dacă este necesar. Autorii prezintă, de asemenea, o idee interesantă pentru efectuarea de rezumate asupra comunităților de grafice, permițându-ne să încorporam și să indexăm informații de actualitate condensate din mai multe surse de date.
În următoarea postare pe blog, vom trece peste implementările locale și globale ale search retriever și vom vorbi despre alte abordări pe care le-am putea implementa pe baza structurii grafice date.
Ca întotdeauna, codul este disponibil pe GitHub .
De data aceasta, am încărcat și descărcarea bazei de date, astfel încât să puteți explora rezultatele și să experimentați cu diferite opțiuni pentru retriever.
De asemenea, puteți importa această descărcare într-o instanță Neo4j AuraDB pentru totdeauna , pe care o putem folosi pentru explorările de recuperare, deoarece nu avem nevoie de algoritmi Graph Data Science pentru aceștia - doar potrivirea modelelor grafice, vector și indici full-text.
Aflați mai multe despre integrările Neo4j cu toate cadrele GenAI și algoritmii grafici practici în cartea mea „Algoritmi grafici pentru știința datelor”.
Pentru a afla mai multe despre acest subiect, alăturați-vă nouă la NODES 2024 pe 7 noiembrie, conferința noastră virtuală gratuită pentru dezvoltatori despre aplicații inteligente, grafice de cunoștințe și AI. Înregistrează-te acum !








