
























Saya sentiasa tertarik dengan pendekatan baharu untuk melaksanakan Retrieval-Augmented Generation (RAG) melalui graf, sering dipanggil GraphRAG. Walau bagaimanapun, nampaknya setiap orang mempunyai pelaksanaan yang berbeza dalam fikiran apabila mereka mendengar istilah GraphRAG. Dalam catatan blog ini, kami akan mendalami artikel dan pelaksanaan " Dari Setempat ke Global GraphRAG " oleh penyelidik Microsoft. Kami akan merangkumi bahagian pembinaan dan ringkasan graf pengetahuan dan meninggalkan retriever untuk catatan blog seterusnya. Para penyelidik sangat baik untuk memberikan kami repositori kod, dan mereka juga mempunyai halaman projek .
Pendekatan yang diambil dalam artikel yang dinyatakan di atas agak menarik. Setakat yang saya faham, ia melibatkan penggunaan graf pengetahuan sebagai langkah dalam perancangan untuk memadatkan dan menggabungkan maklumat daripada pelbagai sumber. Mengekstrak entiti dan perhubungan daripada teks bukanlah perkara baharu. Walau bagaimanapun, pengarang memperkenalkan idea novel (sekurang-kurangnya kepada saya) untuk meringkaskan struktur graf pekat dan maklumat kembali sebagai teks bahasa semula jadi. Saluran paip bermula dengan teks input daripada dokumen, yang diproses untuk menghasilkan graf. Graf kemudiannya ditukarkan semula kepada teks bahasa semula jadi, di mana teks yang dijana mengandungi maklumat ringkas tentang entiti atau komuniti graf tertentu yang sebelum ini tersebar merentasi berbilang dokumen.


Pada tahap yang sangat tinggi, input kepada saluran paip GraphRAG ialah dokumen sumber yang mengandungi pelbagai maklumat. Dokumen diproses menggunakan LLM untuk mengekstrak maklumat berstruktur tentang entiti yang muncul dalam kertas kerja bersama-sama dengan hubungan mereka. Maklumat berstruktur yang diekstrak ini kemudiannya digunakan untuk membina graf pengetahuan.
Kelebihan menggunakan perwakilan data graf pengetahuan ialah ia boleh menggabungkan maklumat dengan cepat dan mudah daripada berbilang dokumen atau sumber data tentang entiti tertentu. Seperti yang dinyatakan, graf pengetahuan bukanlah satu-satunya perwakilan data, walaupun. Selepas graf pengetahuan telah dibina, mereka menggunakan gabungan algoritma graf dan dorongan LLM untuk menjana ringkasan bahasa semula jadi komuniti entiti yang terdapat dalam graf pengetahuan.
Ringkasan ini kemudiannya mengandungi maklumat padat yang tersebar merentasi pelbagai sumber data dan dokumen untuk entiti dan komuniti tertentu.
Untuk pemahaman yang lebih terperinci tentang saluran paip, kita boleh merujuk kepada penerangan langkah demi langkah yang disediakan dalam kertas asal.


Langkah dalam perancangan — Imej daripada kertas GraphRAG , dilesenkan di bawah CC BY 4.0
Berikut ialah ringkasan peringkat tinggi saluran paip yang akan kami gunakan untuk menghasilkan semula pendekatan mereka menggunakan Neo4j dan LangChain.
Pengindeksan — Penjanaan Graf
- Dokumen Sumber kepada Potongan Teks : Dokumen sumber dibahagikan kepada ketulan teks yang lebih kecil untuk diproses.
- Potongan Teks kepada Contoh Unsur : Setiap ketulan teks dianalisis untuk mengekstrak entiti dan perhubungan, menghasilkan senarai tupel yang mewakili elemen ini.
- Contoh Unsur kepada Ringkasan Unsur : Entiti dan perhubungan yang diekstrak diringkaskan oleh LLM ke dalam blok teks deskriptif untuk setiap elemen.
- Ringkasan Elemen kepada Komuniti Graf : Ringkasan entiti ini membentuk graf, yang kemudiannya dibahagikan kepada komuniti menggunakan algoritma seperti Leiden untuk struktur hierarki.
- Komuniti Graf kepada Ringkasan Komuniti : Ringkasan setiap komuniti dijana dengan LLM untuk memahami struktur topikal global dan semantik set data.
Retrieval - Menjawab
- Ringkasan Komuniti kepada Jawapan Global : Ringkasan komuniti digunakan untuk menjawab pertanyaan pengguna dengan menjana jawapan perantaraan, yang kemudiannya diagregatkan menjadi jawapan global akhir.
Ambil perhatian bahawa pelaksanaan saya telah dilakukan sebelum kod mereka tersedia, jadi mungkin terdapat sedikit perbezaan dalam pendekatan asas atau gesaan LLM yang digunakan. Saya akan cuba menerangkan perbezaan tersebut semasa kita meneruskan.
Kod ini tersedia di GitHub .
Menyediakan Persekitaran Neo4j
Kami akan menggunakan Neo4j sebagai kedai graf asas. Cara paling mudah untuk bermula ialah menggunakan contoh percuma Neo4j Sandbox , yang menawarkan tika awan pangkalan data Neo4j dengan pemalam Sains Data Graf dipasang. Sebagai alternatif, anda boleh menyediakan tika tempatan pangkalan data Neo4j dengan memuat turun aplikasi Desktop Neo4j dan mencipta tika pangkalan data setempat. Jika anda menggunakan versi tempatan, pastikan anda memasang kedua-dua pemalam APOC dan GDS. Untuk persediaan pengeluaran, anda boleh menggunakan contoh AuraDS (Sains Data) berbayar dan terurus, yang menyediakan pemalam GDS.
Kami mulakan dengan mencipta contoh Neo4jGraph , iaitu pembungkus kemudahan yang kami tambahkan pada LangChain:
from langchain_community.graphs import Neo4jGraph os.environ["NEO4J_URI"] = "bolt://44.202.208.177:7687" os.environ["NEO4J_USERNAME"] = "neo4j" os.environ["NEO4J_PASSWORD"] = "mast-codes-trails" graph = Neo4jGraph(refresh_schema=False)Set data
Kami akan menggunakan set data artikel berita yang saya buat beberapa waktu lalu menggunakan API Diffbot. Saya telah memuat naiknya ke GitHub saya untuk penggunaan semula yang lebih mudah:
news = pd.read_csv( "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/news_articles.csv" ) news["tokens"] = [ num_tokens_from_string(f"{row['title']} {row['text']}") for i, row in news.iterrows() ] news.head()
Mari kita periksa beberapa baris pertama daripada set data.


Kami mempunyai tajuk dan teks artikel yang tersedia, bersama dengan tarikh penerbitan dan kiraan token menggunakan perpustakaan tiktoken.
Pecahan Teks
Langkah penyusunan teks adalah penting dan memberi kesan ketara kepada hasil hiliran. Penulis kertas mendapati bahawa menggunakan ketulan teks yang lebih kecil menghasilkan mengekstrak lebih banyak entiti secara keseluruhan.


Bilangan entiti ekstrak diberi saiz ketulan teks — Imej daripada kertas GraphRAG , dilesenkan di bawah CC BY 4.0
Seperti yang anda lihat, menggunakan ketulan teks sebanyak 2,400 token menghasilkan lebih sedikit entiti yang diekstrak berbanding apabila mereka menggunakan 600 token. Selain itu, mereka mengenal pasti bahawa LLM mungkin tidak mengekstrak semua entiti pada larian pertama. Dalam kes itu, mereka memperkenalkan heuristik untuk melaksanakan pengekstrakan beberapa kali. Kami akan membincangkannya lebih lanjut dalam bahagian seterusnya.
Walau bagaimanapun, sentiasa ada pertukaran. Menggunakan ketulan teks yang lebih kecil boleh mengakibatkan kehilangan konteks dan rujukan entiti tertentu yang tersebar di seluruh dokumen. Sebagai contoh, jika dokumen menyebut "John" dan "dia" dalam ayat yang berasingan, memecahkan teks kepada ketulan yang lebih kecil mungkin menjadikan tidak jelas bahawa "dia" merujuk kepada John. Beberapa isu rujukan boleh diselesaikan menggunakan strategi penggumpalan teks bertindih, tetapi tidak semuanya.
Mari kita periksa saiz teks artikel kami:
sns.histplot(news["tokens"], kde=False) plt.title('Distribution of chunk sizes') plt.xlabel('Token count') plt.ylabel('Frequency') plt.show()


Pengedaran kiraan token artikel adalah lebih kurang normal, dengan kemuncaknya sekitar 400 token. Kekerapan ketulan secara beransur-ansur meningkat sehingga kemuncak ini, kemudian menurun secara simetri, menunjukkan kebanyakan ketulan teks berada berhampiran tanda 400-token.
Disebabkan pengedaran ini, kami tidak akan melakukan sebarang penggumpalan teks di sini untuk mengelakkan isu rujukan. Secara lalai, projek GraphRAG menggunakan saiz ketulan 300 token dengan 100 token pertindihan.
Mengekstrak Nod dan Perhubungan
Langkah seterusnya ialah membina pengetahuan daripada ketulan teks. Untuk kes penggunaan ini, kami menggunakan LLM untuk mengekstrak maklumat berstruktur dalam bentuk nod dan perhubungan daripada teks. Anda boleh meneliti gesaan LLM yang digunakan oleh pengarang dalam kertas tersebut. Mereka mempunyai gesaan LLM di mana kita boleh mentakrifkan label nod jika perlu, tetapi secara lalai, itu adalah pilihan. Selain itu, perhubungan yang diekstrak dalam dokumentasi asal sebenarnya tidak mempunyai jenis, hanya perihalan. Saya membayangkan sebab di sebalik pilihan ini adalah untuk membenarkan LLM mengekstrak dan mengekalkan maklumat yang lebih kaya dan lebih bernuansa sebagai perhubungan. Tetapi sukar untuk mempunyai graf pengetahuan yang bersih tanpa spesifikasi jenis perhubungan (huraian boleh masuk ke dalam sifat).
Dalam pelaksanaan kami, kami akan menggunakan LLMGraphTransformer , yang tersedia dalam perpustakaan LangChain. Daripada menggunakan kejuruteraan segera tulen, seperti yang dilaksanakan dalam kertas artikel, LLMGraphTransformer menggunakan sokongan panggilan fungsi terbina dalam untuk mengekstrak maklumat berstruktur (LLM output berstruktur dalam LangChain). Anda boleh memeriksa gesaan sistem :
from langchain_experimental.graph_transformers import LLMGraphTransformer from langchain_openai import ChatOpenAI llm = ChatOpenAI(temperature=0, model_name="gpt-4o") llm_transformer = LLMGraphTransformer( llm=llm, node_properties=["description"], relationship_properties=["description"] ) def process_text(text: str) -> List[GraphDocument]: doc = Document(page_content=text) return llm_transformer.convert_to_graph_documents([doc])
Dalam contoh ini, kami menggunakan GPT-4o untuk pengekstrakan graf. Pengarang secara khusus mengarahkan LLM untuk mengekstrak entiti dan perhubungan serta penerangannya . Dengan pelaksanaan LangChain, anda boleh menggunakan atribut node_properties dan relationship_properties untuk menentukan sifat nod atau perhubungan yang anda mahu LLM ekstrak.
Perbezaan dengan pelaksanaan LLMGraphTransformer ialah semua sifat nod atau hubungan adalah pilihan, jadi tidak semua nod akan mempunyai sifat description . Jika kami mahu, kami boleh menentukan pengekstrakan tersuai untuk mempunyai sifat description mandatori, tetapi kami akan melangkaunya dalam pelaksanaan ini.
Kami akan menyelaraskan permintaan untuk membuat pengekstrakan graf lebih cepat dan menyimpan hasil ke Neo4j:
MAX_WORKERS = 10 NUM_ARTICLES = 2000 graph_documents = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(process_text, f"{row['title']} {row['text']}") for i, row in news.head(NUM_ARTICLES).iterrows() ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): graph_document = future.result() graph_documents.extend(graph_document) graph.add_graph_documents( graph_documents, baseEntityLabel=True, include_source=True )
Dalam contoh ini, kami mengekstrak maklumat graf daripada 2,000 artikel dan menyimpan hasil ke Neo4j. Kami telah mengekstrak sekitar 13,000 entiti dan 16,000 perhubungan. Berikut ialah contoh dokumen yang diekstrak dalam graf.


Ia mengambil masa kira-kira 35 (+/- 5) minit untuk menyelesaikan pengekstrakan dan kos kira-kira $30 dengan GPT-4o.
Dalam langkah ini, pengarang memperkenalkan heuristik untuk memutuskan sama ada untuk mengekstrak maklumat graf dalam lebih daripada satu laluan. Demi kesederhanaan, kami hanya akan melakukan satu hantaran. Walau bagaimanapun, jika kami ingin melakukan berbilang hantaran, kami boleh meletakkan hasil pengekstrakan pertama sebagai sejarah perbualan dan hanya mengarahkan LLM bahawa banyak entiti hilang , dan ia harus mengekstrak lebih banyak lagi, seperti yang dilakukan oleh pengarang GraphRAG.
Sebelum ini, saya menyebut betapa pentingnya saiz ketulan teks dan cara ia mempengaruhi bilangan entiti yang diekstrak. Memandangkan kami tidak melakukan sebarang pemotongan teks tambahan, kami boleh menilai pengedaran entiti yang diekstrak berdasarkan saiz bongkah teks:
entity_dist = graph.query( """ MATCH (d:Document) RETURN d.text AS text, count {(d)-[:MENTIONS]->()} AS entity_count """ ) entity_dist_df = pd.DataFrame.from_records(entity_dist) entity_dist_df["token_count"] = [ num_tokens_from_string(str(el)) for el in entity_dist_df["text"] ] # Scatter plot with regression line sns.lmplot( x="token_count", y="entity_count", data=entity_dist_df, line_kws={"color": "red"} ) plt.title("Entity Count vs Token Count Distribution") plt.xlabel("Token Count") plt.ylabel("Entity Count") plt.show()


Plot serakan menunjukkan bahawa walaupun terdapat aliran positif, ditunjukkan oleh garis merah, perhubungan adalah sublinear. Kebanyakan titik data berkelompok pada kiraan entiti yang lebih rendah, walaupun bilangan token meningkat. Ini menunjukkan bahawa bilangan entiti yang diekstrak tidak berskala secara berkadar dengan saiz ketulan teks. Walaupun beberapa outlier wujud, corak umum menunjukkan bahawa kiraan token yang lebih tinggi tidak secara konsisten membawa kepada kiraan entiti yang lebih tinggi. Ini mengesahkan penemuan pengarang bahawa saiz ketulan teks yang lebih rendah akan mengekstrak lebih banyak maklumat.
Saya juga fikir adalah menarik untuk memeriksa taburan darjah nod graf yang dibina. Kod berikut mendapatkan semula dan menggambarkan taburan darjah nod:
degree_dist = graph.query( """ MATCH (e:__Entity__) RETURN count {(e)-[:!MENTIONS]-()} AS node_degree """ ) degree_dist_df = pd.DataFrame.from_records(degree_dist) # Calculate mean and median mean_degree = np.mean(degree_dist_df['node_degree']) percentiles = np.percentile(degree_dist_df['node_degree'], [25, 50, 75, 90]) # Create a histogram with a logarithmic scale plt.figure(figsize=(12, 6)) sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue') # Use a logarithmic scale for the x-axis plt.yscale('log') # Adding labels and title plt.xlabel('Node Degree') plt.ylabel('Count (log scale)') plt.title('Node Degree Distribution') # Add mean, median, and percentile lines plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'Mean: {mean_degree:.2f}') plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25th Percentile: {percentiles[0]:.2f}') plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50th Percentile: {percentiles[1]:.2f}') plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75th Percentile: {percentiles[2]:.2f}') plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90th Percentile: {percentiles[3]:.2f}') # Add legend plt.legend() # Show the plot plt.show()


Taburan darjah nod mengikut corak undang-undang kuasa, menunjukkan kebanyakan nod mempunyai sangat sedikit sambungan manakala beberapa nod bersambung sangat. Darjah min ialah 2.45, dan median ialah 1.00, menunjukkan bahawa lebih daripada separuh nod hanya mempunyai satu sambungan. Kebanyakan nod (75 peratus) mempunyai dua atau kurang sambungan, dan 90 peratus mempunyai lima atau kurang. Pengedaran ini adalah tipikal bagi banyak rangkaian dunia sebenar, di mana sebilangan kecil hab mempunyai banyak sambungan, dan kebanyakan nod mempunyai sedikit.
Memandangkan kedua-dua nod dan perihalan perhubungan bukanlah sifat wajib, kami juga akan memeriksa bilangan yang telah diekstrak:
graph.query(""" MATCH (n:`__Entity__`) RETURN "node" AS type, count(*) AS total_count, count(n.description) AS non_null_descriptions UNION ALL MATCH (n)-[r:!MENTIONS]->() RETURN "relationship" AS type, count(*) AS total_count, count(r.description) AS non_null_descriptions """)
Keputusan menunjukkan bahawa 5,926 nod daripada 12,994 (45.6 peratus) mempunyai sifat perihalan. Sebaliknya, hanya 5,569 perhubungan daripada 15,921 (35 peratus) mempunyai harta sedemikian.
Ambil perhatian bahawa disebabkan sifat kebarangkalian LLM, nombor boleh berbeza-beza pada larian yang berbeza dan data sumber, LLM dan gesaan yang berbeza.
Resolusi Entiti
Penyelesaian entiti (nyahduplikasi) adalah penting apabila membina graf pengetahuan kerana ia memastikan setiap entiti diwakili secara unik dan tepat, menghalang pendua dan menggabungkan rekod yang merujuk kepada entiti dunia sebenar yang sama. Proses ini penting untuk mengekalkan integriti dan konsistensi data dalam graf. Tanpa resolusi entiti, graf pengetahuan akan mengalami data yang berpecah-belah dan tidak konsisten, yang membawa kepada ralat dan cerapan yang tidak boleh dipercayai.


Imej ini menunjukkan bagaimana satu entiti dunia nyata mungkin muncul di bawah nama yang sedikit berbeza dalam dokumen yang berbeza dan, akibatnya, dalam graf kami.
Selain itu, data yang jarang menjadi isu penting tanpa penyelesaian entiti. Data yang tidak lengkap atau separa daripada pelbagai sumber boleh mengakibatkan cebisan maklumat yang bertaburan dan terputus, menjadikannya sukar untuk membentuk pemahaman yang koheren dan menyeluruh tentang entiti. Resolusi entiti yang tepat menangani perkara ini dengan menyatukan data, mengisi jurang dan mencipta pandangan bersatu bagi setiap entiti.


Sebelum/selepas menggunakan resolusi entiti Senzing untuk menghubungkan data kebocoran luar pesisir Konsortium Antarabangsa Wartawan Penyiasatan (ICIJ) — Imej daripada Paco Nathan
Bahagian kiri visualisasi memaparkan graf yang jarang dan tidak bersambung. Walau bagaimanapun, seperti yang ditunjukkan di sebelah kanan, graf sedemikian boleh dihubungkan dengan baik dengan resolusi entiti yang cekap.
Secara keseluruhannya, resolusi entiti meningkatkan kecekapan pengambilan dan penyepaduan data, memberikan pandangan maklumat yang padu merentas sumber yang berbeza. Ia akhirnya membolehkan jawapan soalan yang lebih berkesan berdasarkan graf pengetahuan yang boleh dipercayai dan lengkap.
Malangnya, pengarang kertas GraphRAG tidak memasukkan sebarang kod resolusi entiti dalam repo mereka, walaupun mereka menyebutnya dalam kertas mereka. Satu sebab untuk meninggalkan kod ini mungkin kerana sukar untuk melaksanakan resolusi entiti yang mantap dan berprestasi baik untuk mana-mana domain tertentu. Anda boleh melaksanakan heuristik tersuai untuk nod yang berbeza apabila berurusan dengan jenis nod yang telah ditetapkan (apabila ia tidak dipratentukan, ia tidak cukup konsisten, seperti syarikat, organisasi, perniagaan, dsb.). Walau bagaimanapun, jika label atau jenis nod tidak diketahui lebih awal, seperti dalam kes kami, ini menjadi masalah yang lebih sukar. Walau bagaimanapun, kami akan melaksanakan versi resolusi entiti dalam projek kami di sini, menggabungkan pembenaman teks dan algoritma graf dengan jarak perkataan dan LLM.


Proses kami untuk penyelesaian entiti melibatkan langkah-langkah berikut:
- Entiti dalam graf — Mulakan dengan semua entiti dalam graf.
- Graf K-terhampir — Bina graf jiran k-terhampir, menghubungkan entiti serupa berdasarkan pembenaman teks.
- Komponen Bersambung Lemah — Kenal pasti komponen bersambung lemah dalam graf k-terhampir, mengelompokkan entiti yang berkemungkinan serupa. Tambah langkah penapisan jarak perkataan selepas komponen ini dikenal pasti.
- Penilaian LLM — Gunakan LLM untuk menilai komponen ini dan memutuskan sama ada entiti dalam setiap komponen perlu digabungkan, menghasilkan keputusan muktamad mengenai resolusi entiti (contohnya, menggabungkan 'Silicon Valley Bank' dan 'Silicon_Valley_Bank' sambil menolak gabungan untuk berbeza tarikh seperti '16 September 2023' dan '2 September 2023').
Kita mulakan dengan mengira pembenaman teks untuk nama dan sifat perihalan entiti. Kita boleh menggunakan kaedah from_existing_graph dalam integrasi Neo4jVector dalam LangChain untuk mencapai ini:
vector = Neo4jVector.from_existing_graph( OpenAIEmbeddings(), node_label='__Entity__', text_node_properties=['id', 'description'], embedding_node_property='embedding' )
Kita boleh menggunakan benam ini untuk mencari calon berpotensi yang serupa berdasarkan jarak kosinus bagi benam ini. Kami akan menggunakan algoritma graf yang tersedia dalam perpustakaan Sains Data Graf (GDS) ; oleh itu, kita boleh menggunakan klien GDS Python untuk kemudahan penggunaan dengan cara Pythonic:
from graphdatascience import GraphDataScience gds = GraphDataScience( os.environ["NEO4J_URI"], auth=(os.environ["NEO4J_USERNAME"], os.environ["NEO4J_PASSWORD"]) )
Jika anda tidak biasa dengan pustaka GDS, kami perlu menayangkan graf dalam memori terlebih dahulu sebelum kami boleh melaksanakan sebarang algoritma graf.


Pertama, graf yang disimpan Neo4j diunjurkan ke dalam graf dalam ingatan untuk pemprosesan dan analisis yang lebih pantas. Seterusnya, algoritma graf dilaksanakan pada graf dalam ingatan. Secara pilihan, keputusan algoritma boleh disimpan semula ke dalam pangkalan data Neo4j. Ketahui lebih lanjut mengenainya dalam dokumentasi .
Untuk mencipta graf jiran k-hampir, kami akan menayangkan semua entiti bersama-sama dengan pembenaman teks mereka:
G, result = gds.graph.project( "entities", # Graph name "__Entity__", # Node projection "*", # Relationship projection nodeProperties=["embedding"] # Configuration parameters )
Sekarang bahawa graf diunjurkan di bawah nama entities , kita boleh melaksanakan algoritma graf. Kita akan mulakan dengan membina graf k-hampir . Dua parameter paling penting yang mempengaruhi betapa jarang atau padat graf k-terdekat ialah similarityCutoff dan topK . topK ialah bilangan jiran yang perlu dicari untuk setiap nod, dengan nilai minimum 1. similarityCutoff menapis perhubungan dengan persamaan di bawah ambang ini. Di sini, kami akan menggunakan topK lalai sebanyak 10 dan potongan persamaan yang agak tinggi sebanyak 0.95. Menggunakan potongan persamaan yang tinggi, seperti 0.95, memastikan bahawa hanya pasangan yang sangat serupa dianggap padan, meminimumkan positif palsu dan meningkatkan ketepatan.


Memandangkan kami ingin menyimpan hasil kembali ke graf dalam memori yang diunjurkan dan bukannya graf pengetahuan, kami akan menggunakan mod mutate algoritma:
similarity_threshold = 0.95 gds.knn.mutate( G, nodeProperties=['embedding'], mutateRelationshipType= 'SIMILAR', mutateProperty= 'score', similarityCutoff=similarity_threshold )
Langkah seterusnya ialah mengenal pasti kumpulan entiti yang berkaitan dengan hubungan persamaan yang baru disimpulkan. Mengenal pasti kumpulan nod bersambung ialah proses yang kerap dalam analisis rangkaian, sering dipanggil pengesanan komuniti atau pengelompokan , yang melibatkan pencarian subkumpulan nod bersambung padat. Dalam contoh ini, kami akan menggunakan algoritma Komponen Bersambung Lemah , yang membantu kami mencari bahagian graf yang semua nod disambungkan, walaupun kami mengabaikan arah sambungan.


Kami menggunakan mod write algoritma untuk menyimpan hasil kembali ke pangkalan data (graf disimpan):
gds.wcc.write( G, writeProperty="wcc", relationshipTypes=["SIMILAR"] )
Perbandingan pembenaman teks membantu mencari kemungkinan pendua, tetapi ia hanya sebahagian daripada proses penyelesaian entiti. Sebagai contoh, Google dan Apple sangat rapat dalam ruang benam (kesamaan kosinus 0.96 menggunakan model benam ada-002 ). Begitu juga dengan BMW dan Mercedes Benz (kesamaan kosinus 0.97). Persamaan pembenaman teks tinggi adalah permulaan yang baik, tetapi kami boleh memperbaikinya. Oleh itu, kami akan menambah penapis tambahan yang membenarkan hanya pasangan perkataan dengan jarak teks tiga atau kurang (bermakna hanya aksara boleh ditukar):
word_edit_distance = 3 potential_duplicate_candidates = graph.query( """MATCH (e:`__Entity__`) WHERE size(e.id) > 3 // longer than 3 characters WITH e.wcc AS community, collect(e) AS nodes, count(*) AS count WHERE count > 1 UNWIND nodes AS node // Add text distance WITH distinct [n IN nodes WHERE apoc.text.distance(toLower(node.id), toLower(n.id)) < $distance OR node.id CONTAINS n.id | n.id] AS intermediate_results WHERE size(intermediate_results) > 1 WITH collect(intermediate_results) AS results // combine groups together if they share elements UNWIND range(0, size(results)-1, 1) as index WITH results, index, results[index] as result WITH apoc.coll.sort(reduce(acc = result, index2 IN range(0, size(results)-1, 1) | CASE WHEN index <> index2 AND size(apoc.coll.intersection(acc, results[index2])) > 0 THEN apoc.coll.union(acc, results[index2]) ELSE acc END )) as combinedResult WITH distinct(combinedResult) as combinedResult // extra filtering WITH collect(combinedResult) as allCombinedResults UNWIND range(0, size(allCombinedResults)-1, 1) as combinedResultIndex WITH allCombinedResults[combinedResultIndex] as combinedResult, combinedResultIndex, allCombinedResults WHERE NOT any(x IN range(0,size(allCombinedResults)-1,1) WHERE x <> combinedResultIndex AND apoc.coll.containsAll(allCombinedResults[x], combinedResult) ) RETURN combinedResult """, params={'distance': word_edit_distance})
Kenyataan Cypher ini lebih terlibat sedikit, dan tafsirannya berada di luar skop catatan blog ini. Anda sentiasa boleh meminta LLM untuk mentafsirnya.


Selain itu, pemotongan jarak perkataan boleh menjadi fungsi panjang perkataan dan bukannya nombor tunggal dan pelaksanaannya boleh menjadi lebih berskala.
Apa yang penting ialah ia mengeluarkan kumpulan entiti berpotensi yang mungkin kita ingin gabungkan. Berikut ialah senarai nod yang berpotensi untuk digabungkan:
{'combinedResult': ['Sinn Fein', 'Sinn Féin']}, {'combinedResult': ['Government', 'Governments']}, {'combinedResult': ['Unreal Engine', 'Unreal_Engine']}, {'combinedResult': ['March 2016', 'March 2020', 'March 2022', 'March_2023']}, {'combinedResult': ['Humana Inc', 'Humana Inc.']}, {'combinedResult': ['New York Jets', 'New York Mets']}, {'combinedResult': ['Asia Pacific', 'Asia-Pacific', 'Asia_Pacific']}, {'combinedResult': ['Bengaluru', 'Mangaluru']}, {'combinedResult': ['US Securities And Exchange Commission', 'Us Securities And Exchange Commission']}, {'combinedResult': ['Jp Morgan', 'Jpmorgan']}, {'combinedResult': ['Brighton', 'Brixton']},
Seperti yang anda lihat, pendekatan resolusi kami berfungsi lebih baik untuk beberapa jenis nod berbanding yang lain. Berdasarkan pemeriksaan pantas, ia nampaknya berfungsi lebih baik untuk orang dan organisasi, sementara ia agak buruk untuk tarikh. Jika kami menggunakan jenis nod yang dipratentukan, kami boleh menyediakan heuristik yang berbeza untuk pelbagai jenis nod. Dalam contoh ini, kami tidak mempunyai label nod yang dipratentukan, jadi kami akan beralih kepada LLM untuk membuat keputusan muktamad tentang sama ada entiti perlu digabungkan atau tidak.
Pertama, kita perlu merumuskan gesaan LLM untuk membimbing dan memaklumkan keputusan muktamad secara berkesan mengenai penggabungan nod:
system_prompt = """You are a data processing assistant. Your task is to identify duplicate entities in a list and decide which of them should be merged. The entities might be slightly different in format or content, but essentially refer to the same thing. Use your analytical skills to determine duplicates. Here are the rules for identifying duplicates: 1. Entities with minor typographical differences should be considered duplicates. 2. Entities with different formats but the same content should be considered duplicates. 3. Entities that refer to the same real-world object or concept, even if described differently, should be considered duplicates. 4. If it refers to different numbers, dates, or products, do not merge results """ user_template = """ Here is the list of entities to process: {entities} Please identify duplicates, merge them, and provide the merged list. """
Saya sentiasa suka menggunakan kaedah with_structured_output dalam LangChain apabila mengharapkan output data berstruktur untuk mengelakkan daripada menghuraikan output secara manual.
Di sini, kami akan mentakrifkan output sebagai list of lists , di mana setiap senarai dalaman mengandungi entiti yang harus digabungkan. Struktur ini digunakan untuk mengendalikan senario di mana, sebagai contoh, input mungkin [Sony, Sony Inc, Google, Google Inc] . Dalam kes sedemikian, anda ingin menggabungkan "Sony" dan "Sony Inc" secara berasingan daripada "Google" dan "Google Inc."
class DuplicateEntities(BaseModel): entities: List[str] = Field( description="Entities that represent the same object or real-world entity and should be merged" ) class Disambiguate(BaseModel): merge_entities: Optional[List[DuplicateEntities]] = Field( description="Lists of entities that represent the same object or real-world entity and should be merged" ) extraction_llm = ChatOpenAI(model_name="gpt-4o").with_structured_output( Disambiguate )
Seterusnya, kami menyepadukan gesaan LLM dengan output berstruktur untuk mencipta rantai menggunakan sintaks LangChain Expression Language (LCEL) dan merangkumnya dalam fungsi disambiguate .
extraction_chain = extraction_prompt | extraction_llm def entity_resolution(entities: List[str]) -> Optional[List[List[str]]]: return [ el.entities for el in extraction_chain.invoke({"entities": entities}).merge_entities ]
Kita perlu menjalankan semua nod calon yang berpotensi melalui fungsi entity_resolution untuk memutuskan sama ada ia perlu digabungkan. Untuk mempercepatkan proses, kami akan menyelaraskan lagi panggilan LLM:
merged_entities = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(entity_resolution, el['combinedResult']) for el in potential_duplicate_candidates ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): to_merge = future.result() if to_merge: merged_entities.extend(to_merge)
Langkah terakhir resolusi entiti melibatkan mengambil keputusan daripada entity_resolution LLM dan menulisnya kembali ke pangkalan data dengan menggabungkan nod yang ditentukan:
graph.query(""" UNWIND $data AS candidates CALL { WITH candidates MATCH (e:__Entity__) WHERE e.id IN candidates RETURN collect(e) AS nodes } CALL apoc.refactor.mergeNodes(nodes, {properties: { description:'combine', `.*`: 'discard' }}) YIELD node RETURN count(*) """, params={"data": merged_entities})
Resolusi entiti ini tidak sempurna, tetapi ia memberi kita titik permulaan yang boleh kita perbaiki. Selain itu, kita boleh menambah baik logik untuk menentukan entiti yang harus dikekalkan.
Rumusan Elemen
Dalam langkah seterusnya, pengarang melakukan langkah ringkasan elemen. Pada asasnya, setiap nod dan perhubungan akan dihantar melalui gesaan ringkasan entiti . Penulis mencatatkan kebaharuan dan minat pendekatan mereka:
“Secara keseluruhannya, penggunaan teks deskriptif yang kaya untuk nod homogen dalam struktur graf yang berpotensi bising adalah sejajar dengan kedua-dua keupayaan LLM dan keperluan ringkasan global yang berfokuskan pertanyaan. Kualiti ini juga membezakan indeks graf kami daripada graf pengetahuan biasa, yang bergantung pada tiga kali ganda pengetahuan yang ringkas dan konsisten (subjek, predikat, objek) untuk tugas penaakulan hiliran."
Idea yang menarik. Kami masih mengekstrak ID atau nama subjek dan objek daripada teks, yang membolehkan kami memautkan perhubungan kepada entiti yang betul, walaupun apabila entiti muncul merentas berbilang ketulan teks. Walau bagaimanapun, hubungan tidak dikurangkan kepada satu jenis. Sebaliknya, jenis perhubungan sebenarnya ialah teks bentuk bebas yang membolehkan kami mengekalkan maklumat yang lebih kaya dan lebih bernuansa.
Selain itu, maklumat entiti diringkaskan menggunakan LLM, membolehkan kami membenamkan dan mengindeks maklumat dan entiti ini dengan lebih cekap untuk mendapatkan semula yang lebih tepat.
Seseorang boleh berhujah bahawa maklumat yang lebih kaya dan lebih bernuansa ini juga boleh dikekalkan dengan menambahkan sifat nod dan perhubungan tambahan, mungkin sewenang-wenangnya. Satu isu dengan sifat nod dan perhubungan yang sewenang-wenangnya ialah mungkin sukar untuk mengekstrak maklumat secara konsisten kerana LLM mungkin menggunakan nama harta yang berbeza atau menumpukan pada pelbagai butiran pada setiap pelaksanaan.
Beberapa masalah ini boleh diselesaikan menggunakan nama sifat yang dipratentukan dengan maklumat jenis dan perihalan tambahan. Dalam kes itu, anda memerlukan pakar subjek untuk membantu mentakrifkan sifat tersebut, meninggalkan sedikit ruang untuk LLM mengekstrak sebarang maklumat penting di luar huraian yang telah ditetapkan.
Ia merupakan pendekatan yang menarik untuk mewakili maklumat yang lebih kaya dalam graf pengetahuan.
Satu isu yang berpotensi dengan langkah ringkasan elemen ialah ia tidak berskala dengan baik kerana ia memerlukan panggilan LLM untuk setiap entiti dan hubungan dalam graf. Graf kami agak kecil dengan 13,000 nod dan 16,000 perhubungan. Walaupun untuk graf sekecil itu, kami memerlukan 29,000 panggilan LLM, dan setiap panggilan akan menggunakan beberapa ratus token, menjadikannya agak mahal dan memakan masa. Oleh itu, kami akan mengelakkan langkah ini di sini. Kami masih boleh menggunakan sifat perihalan yang diekstrak semasa pemprosesan teks awal.
Membina dan Merumuskan Komuniti
Langkah terakhir dalam pembinaan graf dan proses pengindeksan melibatkan mengenal pasti komuniti dalam graf. Dalam konteks ini, komuniti ialah sekumpulan nod yang lebih rapat antara satu sama lain berbanding graf yang lain, menunjukkan tahap interaksi atau persamaan yang lebih tinggi. Visualisasi berikut menunjukkan contoh hasil pengesanan komuniti.


Setelah komuniti entiti ini dikenal pasti dengan algoritma pengelompokan, LLM menjana ringkasan untuk setiap komuniti, memberikan cerapan tentang ciri dan perhubungan individu mereka.
Sekali lagi, kami menggunakan perpustakaan Sains Data Graf. Kita mulakan dengan menayangkan graf dalam ingatan. Untuk mengikuti artikel asal dengan tepat, kami akan menayangkan graf entiti sebagai rangkaian berwajaran tidak terarah, di mana rangkaian mewakili bilangan sambungan antara dua entiti:
G, result = gds.graph.project( "communities", # Graph name "__Entity__", # Node projection { "_ALL_": { "type": "*", "orientation": "UNDIRECTED", "properties": {"weight": {"property": "*", "aggregation": "COUNT"}}, } }, )
Penulis menggunakan algoritma Leiden , kaedah pengelompokan hierarki, untuk mengenal pasti komuniti dalam graf. Satu kelebihan menggunakan algoritma pengesanan komuniti hierarki ialah keupayaan untuk memeriksa komuniti pada pelbagai peringkat butiran. Penulis mencadangkan meringkaskan semua komuniti pada setiap peringkat, memberikan pemahaman yang menyeluruh tentang struktur graf.
Pertama, kami akan menggunakan algoritma Komponen Bersambung Lemah (WCC) untuk menilai ketersambungan graf kami. Algoritma ini mengenal pasti bahagian terpencil dalam graf, bermakna ia mengesan subset nod atau komponen yang bersambung antara satu sama lain tetapi tidak kepada graf yang lain. Komponen ini membantu kami memahami pemecahan dalam rangkaian dan mengenal pasti kumpulan nod yang bebas daripada yang lain. WCC adalah penting untuk menganalisis keseluruhan struktur dan ketersambungan graf.
wcc = gds.wcc.stats(G) print(f"Component count: {wcc['componentCount']}") print(f"Component distribution: {wcc['componentDistribution']}") # Component count: 1119 # Component distribution: { # "min":1, # "p5":1, # "max":9109, # "p999":43, # "p99":19, # "p1":1, # "p10":1, # "p90":7, # "p50":2, # "p25":1, # "p75":4, # "p95":10, # "mean":11.3 }
Keputusan algoritma WCC mengenal pasti 1,119 komponen berbeza. Terutamanya, komponen terbesar terdiri daripada 9,109 nod, biasa dalam rangkaian dunia sebenar di mana satu komponen super wujud bersama dengan banyak komponen terpencil yang lebih kecil. Komponen terkecil mempunyai satu nod, dan saiz komponen purata adalah kira-kira 11.3 nod.
Seterusnya, kami akan menjalankan algoritma Leiden, yang juga tersedia dalam pustaka GDS, dan membolehkan parameter includeIntermediateCommunities untuk mengembalikan dan menyimpan komuniti di semua peringkat. Kami juga telah memasukkan parameter relationshipWeightProperty untuk menjalankan varian wajaran algoritma Leiden. Menggunakan mod write algoritma menyimpan hasil sebagai sifat nod.
gds.leiden.write( G, writeProperty="communities", includeIntermediateCommunities=True, relationshipWeightProperty="weight", )
Algoritma ini mengenal pasti lima peringkat komuniti, dengan tahap tertinggi (tahap butiran paling rendah di mana komuniti terbesar) mempunyai 1,188 komuniti (berbanding dengan 1,119 komponen). Berikut ialah visualisasi komuniti di peringkat terakhir menggunakan Gephi.


Menggambarkan lebih daripada 1,000 komuniti adalah sukar; malah memilih warna untuk setiap satu adalah mustahil. Walau bagaimanapun, mereka membuat persembahan artistik yang bagus.
Berdasarkan ini, kami akan mencipta nod yang berbeza untuk setiap komuniti dan mewakili struktur hierarki mereka sebagai graf yang saling berkaitan. Kemudian, kami juga akan menyimpan ringkasan komuniti dan atribut lain sebagai sifat nod.
graph.query(""" MATCH (e:`__Entity__`) UNWIND range(0, size(e.communities) - 1 , 1) AS index CALL { WITH e, index WITH e, index WHERE index = 0 MERGE (c:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET c.level = index MERGE (e)-[:IN_COMMUNITY]->(c) RETURN count(*) AS count_0 } CALL { WITH e, index WITH e, index WHERE index > 0 MERGE (current:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET current.level = index MERGE (previous:`__Community__` {id: toString(index - 1) + '-' + toString(e.communities[index - 1])}) ON CREATE SET previous.level = index - 1 MERGE (previous)-[:IN_COMMUNITY]->(current) RETURN count(*) AS count_1 } RETURN count(*) """)
Pengarang juga memperkenalkan community rank , menunjukkan bilangan ketulan teks yang berbeza di mana entiti dalam komuniti muncul:
graph.query(""" MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(:__Entity__)<-[:MENTIONS]-(d:Document) WITH c, count(distinct d) AS rank SET c.community_rank = rank; """)
Sekarang mari kita periksa sampel struktur hierarki dengan banyak komuniti perantaraan bergabung pada tahap yang lebih tinggi. Komuniti tidak bertindih, bermakna setiap entiti adalah milik satu komuniti pada setiap peringkat.


Imej mewakili struktur hierarki yang terhasil daripada algoritma pengesanan komuniti Leiden. Nod ungu mewakili entiti individu, manakala nod oren mewakili komuniti hierarki.
Hierarki menunjukkan organisasi entiti ini ke dalam pelbagai komuniti, dengan komuniti yang lebih kecil bergabung menjadi lebih besar di peringkat yang lebih tinggi.
Sekarang mari kita periksa bagaimana komuniti yang lebih kecil bergabung di peringkat yang lebih tinggi.

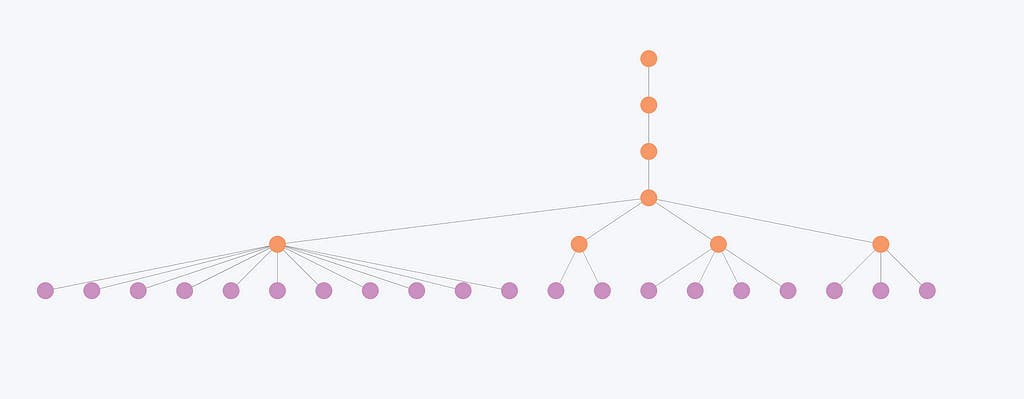
Imej ini menggambarkan bahawa entiti yang kurang berhubung dan akibatnya komuniti yang lebih kecil mengalami perubahan minimum merentas peringkat. Sebagai contoh, struktur komuniti di sini hanya berubah dalam dua peringkat pertama tetapi kekal sama untuk tiga peringkat terakhir. Akibatnya, tahap hierarki sering kelihatan berlebihan untuk entiti ini, kerana keseluruhan organisasi tidak berubah dengan ketara pada peringkat yang berbeza.
Mari kita periksa bilangan komuniti dan saiz dan tahap yang berbeza dengan lebih terperinci:
community_size = graph.query( """ MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(e:__Entity__) WITH c, count(distinct e) AS entities RETURN split(c.id, '-')[0] AS level, entities """ ) community_size_df = pd.DataFrame.from_records(community_size) percentiles_data = [] for level in community_size_df["level"].unique(): subset = community_size_df[community_size_df["level"] == level]["entities"] num_communities = len(subset) percentiles = np.percentile(subset, [25, 50, 75, 90, 99]) percentiles_data.append( [ level, num_communities, percentiles[0], percentiles[1], percentiles[2], percentiles[3], percentiles[4], max(subset) ] ) # Create a DataFrame with the percentiles percentiles_df = pd.DataFrame( percentiles_data, columns=[ "Level", "Number of communities", "25th Percentile", "50th Percentile", "75th Percentile", "90th Percentile", "99th Percentile", "Max" ], ) percentiles_df


Dalam pelaksanaan asal, komuniti di setiap peringkat diringkaskan. Dalam kes kami, itu akan menjadi 8,590 komuniti dan, akibatnya, 8,590 panggilan LLM. Saya berpendapat bahawa bergantung pada struktur komuniti hierarki, tidak setiap peringkat perlu diringkaskan. Sebagai contoh, perbezaan antara tahap terakhir dan seterusnya hingga terakhir ialah hanya empat komuniti (1,192 berbanding 1,188). Oleh itu, kami akan membuat banyak ringkasan yang berlebihan. Satu penyelesaian adalah untuk mencipta pelaksanaan yang boleh membuat ringkasan tunggal untuk komuniti pada tahap berbeza yang tidak berubah; satu lagi adalah untuk meruntuhkan hierarki komuniti yang tidak berubah.
Selain itu, saya tidak pasti sama ada kita ingin meringkaskan komuniti dengan hanya seorang ahli, kerana mereka mungkin tidak memberikan banyak nilai atau maklumat. Di sini, kami akan meringkaskan komuniti pada tahap 0, 1 dan 4. Pertama, kami perlu mendapatkan semula maklumat mereka daripada pangkalan data:
community_info = graph.query(""" MATCH (c:`__Community__`)<-[:IN_COMMUNITY*]-(e:__Entity__) WHERE c.level IN [0,1,4] WITH c, collect(e ) AS nodes WHERE size(nodes) > 1 CALL apoc.path.subgraphAll(nodes[0], { whitelistNodes:nodes }) YIELD relationships RETURN c.id AS communityId, [n in nodes | {id: n.id, description: n.description, type: [el in labels(n) WHERE el <> '__Entity__'][0]}] AS nodes, [r in relationships | {start: startNode(r).id, type: type(r), end: endNode(r).id, description: r.description}] AS rels """)
Pada masa ini, maklumat komuniti mempunyai struktur berikut:
{'communityId': '0-6014', 'nodes': [{'id': 'Darrell Hughes', 'description': None, type:"Person"}, {'id': 'Chief Pilot', 'description': None, type: "Person"}, ... }], 'rels': [{'start': 'Ryanair Dac', 'description': 'Informed of the change in chief pilot', 'type': 'INFORMED', 'end': 'Irish Aviation Authority'}, {'start': 'Ryanair Dac', 'description': 'Dismissed after internal investigation found unacceptable behaviour', 'type': 'DISMISSED', 'end': 'Aidan Murray'}, ... ]}
Kini, kita perlu menyediakan gesaan LLM yang menjana ringkasan bahasa semula jadi berdasarkan maklumat yang diberikan oleh elemen komuniti kita. Kita boleh mengambil sedikit inspirasi daripada gesaan yang digunakan oleh penyelidik .
Penulis bukan sahaja meringkaskan komuniti tetapi juga menjana penemuan untuk setiap daripada mereka. Penemuan boleh ditakrifkan sebagai maklumat ringkas mengenai peristiwa atau sekeping maklumat tertentu. Satu contoh sedemikian:
"summary": "Abila City Park as the central location", "explanation": "Abila City Park is the central entity in this community, serving as the location for the POK rally. This park is the common link between all other entities, suggesting its significance in the community. The park's association with the rally could potentially lead to issues such as public disorder or conflict, depending on the nature of the rally and the reactions it provokes. [records: Entities (5), Relationships (37, 38, 39, 40)]"
Intuisi saya mencadangkan bahawa mengekstrak penemuan dengan hanya satu laluan mungkin tidak menyeluruh seperti yang kita perlukan, sama seperti mengekstrak entiti dan perhubungan.
Tambahan pula, saya tidak menemui sebarang rujukan atau contoh penggunaannya dalam kod mereka sama ada dalam pencarian carian tempatan atau global. Akibatnya, kami akan mengelak daripada mengekstrak penemuan dalam hal ini. Atau, seperti yang sering dikatakan oleh ahli akademik: Latihan ini diserahkan kepada pembaca. Selain itu, kami juga telah melangkau tuntutan atau pengekstrakan maklumat kovariat , yang kelihatan serupa dengan penemuan pada pandangan pertama.
Gesaan yang akan kami gunakan untuk menghasilkan ringkasan komuniti adalah agak mudah:
community_template = """Based on the provided nodes and relationships that belong to the same graph community, generate a natural language summary of the provided information: {community_info} Summary:""" # noqa: E501 community_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Given an input triples, generate the information summary. No pre-amble.", ), ("human", community_template), ] ) community_chain = community_prompt | llm | StrOutputParser()
Satu-satunya perkara yang tinggal ialah mengubah perwakilan komuniti menjadi rentetan untuk mengurangkan bilangan token dengan mengelakkan overhed token JSON dan membalut rantai sebagai fungsi:
def prepare_string(data): nodes_str = "Nodes are:\n" for node in data['nodes']: node_id = node['id'] node_type = node['type'] if 'description' in node and node['description']: node_description = f", description: {node['description']}" else: node_description = "" nodes_str += f"id: {node_id}, type: {node_type}{node_description}\n" rels_str = "Relationships are:\n" for rel in data['rels']: start = rel['start'] end = rel['end'] rel_type = rel['type'] if 'description' in rel and rel['description']: description = f", description: {rel['description']}" else: description = "" rels_str += f"({start})-[:{rel_type}]->({end}){description}\n" return nodes_str + "\n" + rels_str def process_community(community): stringify_info = prepare_string(community) summary = community_chain.invoke({'community_info': stringify_info}) return {"community": community['communityId'], "summary": summary}
Kini kita boleh menjana ringkasan komuniti untuk tahap yang dipilih. Sekali lagi, kami menyelaraskan panggilan untuk pelaksanaan yang lebih pantas:
summaries = [] with ThreadPoolExecutor() as executor: futures = {executor.submit(process_community, community): community for community in community_info} for future in tqdm(as_completed(futures), total=len(futures), desc="Processing communities"): summaries.append(future.result())
Satu aspek yang saya tidak nyatakan ialah pengarang juga menangani isu potensi melebihi saiz konteks apabila memasukkan maklumat komuniti. Apabila graf berkembang, komuniti juga boleh berkembang dengan ketara. Dalam kes kami, komuniti terbesar terdiri daripada 545 ahli. Memandangkan GPT-4o mempunyai saiz konteks melebihi 100,000 token, kami memutuskan untuk melangkau langkah ini.
Sebagai langkah terakhir kami, kami akan menyimpan ringkasan komuniti kembali ke pangkalan data:
graph.query(""" UNWIND $data AS row MERGE (c:__Community__ {id:row.community}) SET c.summary = row.summary """, params={"data": summaries})
Struktur graf akhir:


Graf kini mengandungi dokumen asal, entiti dan perhubungan yang diekstrak, serta struktur dan ringkasan komuniti hierarki.
Ringkasan
Pengarang kertas kerja "Dari Tempatan ke Global" telah melakukan kerja yang hebat dalam menunjukkan pendekatan baharu kepada GraphRAG. Ia menunjukkan bagaimana kita boleh menggabungkan dan meringkaskan maklumat daripada pelbagai dokumen ke dalam struktur graf pengetahuan hierarki.
Satu perkara yang tidak dinyatakan secara eksplisit ialah kami juga boleh menyepadukan sumber data berstruktur dalam graf; input tidak perlu dihadkan kepada teks tidak berstruktur sahaja.
Apa yang saya amat menghargai pendekatan pengekstrakan mereka ialah mereka menangkap penerangan untuk kedua-dua nod dan perhubungan. Perihalan membenarkan LLM menyimpan lebih banyak maklumat daripada mengurangkan segala-galanya kepada hanya ID nod dan jenis perhubungan.
Selain itu, mereka menunjukkan bahawa satu pengekstrakan lulus ke atas teks mungkin tidak menangkap semua maklumat yang berkaitan dan memperkenalkan logik untuk melakukan berbilang hantaran jika perlu. Pengarang juga mengemukakan idea menarik untuk melaksanakan ringkasan ke atas komuniti graf, membolehkan kami membenamkan dan mengindeks maklumat topikal yang dipadatkan merentas pelbagai sumber data.
Dalam catatan blog seterusnya, kami akan meneliti pelaksanaan pencarian cari tempatan dan global dan bercakap tentang pendekatan lain yang boleh kami laksanakan berdasarkan struktur graf yang diberikan.
Seperti biasa, kod itu tersedia di GitHub .
Kali ini, saya juga telah memuat naik longgokan pangkalan data supaya anda boleh meneroka keputusan dan mencuba dengan pilihan retriever yang berbeza.
Anda juga boleh mengimport longgokan ini ke dalam contoh Neo4j AuraDB yang bebas selama-lamanya , yang boleh kami gunakan untuk penerokaan mendapatkan semula kerana kami tidak memerlukan algoritma Sains Data Graf untuk itu — hanya padanan corak graf, vektor dan indeks teks penuh.
Ketahui lebih lanjut tentang penyepaduan Neo4j dengan semua rangka kerja GenAI dan algoritma graf praktikal dalam buku saya "Algoritma Graf untuk Sains Data."
Untuk mengetahui lebih lanjut tentang topik ini, sertai kami di NODES 2024 pada 7 November, persidangan pembangun maya percuma kami tentang apl pintar, graf pengetahuan dan AI. Daftar Sekarang !




