
























Uvijek me zaintrigiraju novi pristupi implementacije Retrieval-Augmented Generation (RAG) preko grafova, koji se često naziva GraphRAG. No, čini se da svatko ima drugačiju implementaciju na umu kada čuje izraz GraphRAG. U ovom postu na blogu zaronit ćemo duboko u članak " Od lokalnog do globalnog GraphRAG " i implementaciju Microsoftovih istraživača. Pokrit ćemo konstrukciju grafikona znanja i dio sažimanja, a retrivere ćemo ostaviti za sljedeći post na blogu. Istraživači su bili tako ljubazni da su nam dali repozitorij kodova, a imaju i stranicu projekta .
Pristup zauzet u gore spomenutom članku vrlo je zanimljiv. Koliko ja razumijem, to uključuje korištenje grafikona znanja kao koraka u cjevovodu za sažimanje i kombiniranje informacija iz više izvora. Izdvajanje entiteta i odnosa iz teksta nije ništa novo. Međutim, autori uvode novu (barem meni) ideju sažimanja kondenzirane strukture grafa i informacija natrag kao teksta prirodnog jezika. Cjevovod počinje s unosom teksta iz dokumenata, koji se obrađuju za generiranje grafikona. Grafikon se zatim pretvara natrag u tekst prirodnog jezika, gdje generirani tekst sadrži sažete informacije o određenim entitetima ili zajednicama grafova prethodno raspoređenih u više dokumenata.


Na vrlo visokoj razini, ulaz u GraphRAG cjevovod su izvorni dokumenti koji sadrže različite informacije. Dokumenti se obrađuju pomoću LLM-a za izdvajanje strukturiranih informacija o entitetima koji se pojavljuju u dokumentima zajedno s njihovim odnosima. Ove izdvojene strukturirane informacije zatim se koriste za izradu grafikona znanja.
Prednost upotrebe prikaza podataka grafikona znanja je u tome što može brzo i izravno kombinirati informacije iz više dokumenata ili izvora podataka o određenim entitetima. Kao što je spomenuto, grafikon znanja nije jedini prikaz podataka. Nakon što je graf znanja konstruiran, oni koriste kombinaciju algoritama grafa i LLM promptova za generiranje sažetaka na prirodnom jeziku zajednica entiteta pronađenih u grafu znanja.
Ti sažeci zatim sadrže sažete informacije koje se šire kroz više izvora podataka i dokumenata za određene entitete i zajednice.
Za detaljnije razumijevanje cjevovoda, možemo se pozvati na opis korak po korak u izvornom radu.


Koraci u pripremi — Slika s GraphRAG papira , licencirano pod CC BY 4.0
Slijedi sažetak na visokoj razini cjevovoda koji ćemo koristiti za reprodukciju njihovog pristupa korištenjem Neo4j i LangChain.
Indeksiranje — Generiranje grafikona
- Izvorni dokumenti u tekstualne dijelove : Izvorni dokumenti podijeljeni su u manje tekstualne dijelove za obradu.
- Dijelovi teksta u instance elementa : Svaki se dio teksta analizira kako bi se izdvojili entiteti i odnosi, stvarajući popis torki koje predstavljaju te elemente.
- Instance elemenata u sažetke elemenata : LLM sažima izdvojene entitete i odnose u blokove teksta za svaki element.
- Sažeci elemenata za zajednice grafikona : Ovi sažeci entiteta tvore grafikon, koji se zatim dijeli na zajednice pomoću algoritama poput Leidena za hijerarhijsku strukturu.
- Grafikirajte sažetke zajednice u zajednicu : Sažeci svake zajednice generiraju se s LLM-om kako bi se razumjela globalna tematska struktura i semantika skupa podataka.
Dohvaćanje — Odgovaranje
- Sažeci zajednice do globalnih odgovora : Sažeci zajednice koriste se za odgovaranje na upit korisnika generiranjem posrednih odgovora, koji se zatim agregiraju u konačni globalni odgovor.
Imajte na umu da je moja implementacija gotova prije nego što je njihov kod bio dostupan, tako da mogu postojati male razlike u temeljnom pristupu ili LLM upitima koji se koriste. Pokušat ću objasniti te razlike usput.
Kod je dostupan na GitHubu .
Postavljanje Neo4j okruženja
Koristit ćemo Neo4j kao temeljnu pohranu grafova. Najlakši način za početak je korištenje besplatne instance Neo4j Sandboxa , koja nudi instance Neo4j baze podataka u oblaku s instaliranim Graph Data Science dodatkom. Alternativno, možete postaviti lokalnu instancu Neo4j baze podataka preuzimanjem aplikacije Neo4j Desktop i stvaranjem lokalne instance baze podataka. Ako koristite lokalnu verziju, svakako instalirajte i APOC i GDS dodatke. Za postavke proizvodnje možete koristiti plaćenu, upravljanu instancu AuraDS (Data Science), koja pruža GDS dodatak.
Počinjemo stvaranjem instance Neo4jGraph , koja je pogodan omot koji smo dodali u LangChain:
from langchain_community.graphs import Neo4jGraph os.environ["NEO4J_URI"] = "bolt://44.202.208.177:7687" os.environ["NEO4J_USERNAME"] = "neo4j" os.environ["NEO4J_PASSWORD"] = "mast-codes-trails" graph = Neo4jGraph(refresh_schema=False)Skup podataka
Koristit ćemo skup podataka o članku s vijestima koji sam izradio prije nekog vremena koristeći Diffbotov API. Prenio sam ga na svoj GitHub za lakšu ponovnu upotrebu:
news = pd.read_csv( "https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/news_articles.csv" ) news["tokens"] = [ num_tokens_from_string(f"{row['title']} {row['text']}") for i, row in news.iterrows() ] news.head()
Ispitajmo prvih nekoliko redaka iz skupa podataka.


Dostupni su nam naslov i tekst članaka, zajedno s njihovim datumom objavljivanja i brojem tokena pomoću knjižnice tiktoken.
Usitnjavanje teksta
Korak dijeljenja teksta ključan je i značajno utječe na daljnje rezultate. Autori rada otkrili su da korištenje manjih dijelova teksta rezultira izdvajanjem više entiteta u cjelini.


Broj entiteta ekstrakta s obzirom na veličinu tekstualnih dijelova — Slika s GraphRAG papira , licencirano pod CC BY 4.0
Kao što možete vidjeti, korištenje tekstualnih dijelova od 2400 tokena rezultira s manje ekstrahiranih entiteta nego kada su koristili 600 tokena. Osim toga, utvrdili su da LLM možda neće izdvojiti sve entitete pri prvom pokretanju. U tom slučaju uvode heuristiku za izvođenje ekstrakcije više puta. O tome ćemo više govoriti u sljedećem odjeljku.
Međutim, uvijek postoje kompromisi. Korištenje manjih dijelova teksta može rezultirati gubitkom konteksta i koreferencija određenih entiteta raspoređenih po dokumentima. Na primjer, ako se u dokumentu spominju "Ivan" i "on" u zasebnim rečenicama, razbijanje teksta na manje dijelove moglo bi učiniti nejasnim da se "on" odnosi na Ivana. Neki problemi s koreferencijom mogu se riješiti strategijom preklapanja teksta na komade, ali ne svi.
Pogledajmo veličinu tekstova naših članaka:
sns.histplot(news["tokens"], kde=False) plt.title('Distribution of chunk sizes') plt.xlabel('Token count') plt.ylabel('Frequency') plt.show()


Distribucija broja tokena članaka je približno normalna, s vrhom od oko 400 tokena. Učestalost dijelova postupno raste do ovog vrha, a zatim simetrično opada, što ukazuje da je većina tekstualnih dijelova blizu oznake od 400 tokena.
Zbog ove distribucije, ovdje nećemo izvoditi nikakvo razdvajanje teksta kako bismo izbjegli probleme s koreferencijom. Prema zadanim postavkama, projekt GraphRAG koristi veličine komada od 300 tokena sa 100 tokena preklapanja.
Izdvajanje čvorova i odnosa
Sljedeći korak je konstruiranje znanja iz tekstualnih dijelova. Za ovaj slučaj upotrebe koristimo LLM za izdvajanje strukturiranih informacija u obliku čvorova i odnosa iz teksta. Možete pregledati LLM prompt koji su autori koristili u radu. Imaju upite za LLM gdje možemo unaprijed definirati oznake čvorova ako je potrebno, ali prema zadanim postavkama to nije obavezno. Osim toga, izdvojeni odnosi u izvornoj dokumentaciji zapravo nemaju vrstu, samo opis. Pretpostavljam da je razlog iza ovog izbora dopustiti LLM-u da izdvoji i zadrži bogatije i nijansiranije informacije kao odnose. Ali teško je imati čist grafikon znanja bez specifikacija vrste odnosa (opisi mogu ići u svojstvo).
U našoj implementaciji koristit ćemo LLMGraphTransformer koji je dostupan u biblioteci LangChain. Umjesto korištenja čistog brzog inženjeringa, kao što to čini implementacija u članku, LLMGraphTransformer koristi ugrađenu podršku za pozivanje funkcija za izdvajanje strukturiranih informacija (strukturirani izlazni LLM-ovi u LangChainu). Možete provjeriti upit sustava :
from langchain_experimental.graph_transformers import LLMGraphTransformer from langchain_openai import ChatOpenAI llm = ChatOpenAI(temperature=0, model_name="gpt-4o") llm_transformer = LLMGraphTransformer( llm=llm, node_properties=["description"], relationship_properties=["description"] ) def process_text(text: str) -> List[GraphDocument]: doc = Document(page_content=text) return llm_transformer.convert_to_graph_documents([doc])
U ovom primjeru koristimo GPT-4o za ekstrakciju grafa. Autori posebno upućuju doktore prava da izdvoje entitete i odnose i njihove opise . Uz implementaciju LangChain, možete koristiti atribute node_properties i relationship_properties da odredite koja svojstva čvora ili odnosa želite da LLM izdvoji.
Razlika s implementacijom LLMGraphTransformer je u tome što su sva svojstva čvorova ili odnosa izborna, tako da neće svi čvorovi imati svojstvo description . Da želimo, mogli bismo definirati prilagođeno izdvajanje da ima obavezno svojstvo description , ali to ćemo preskočiti u ovoj implementaciji.
Paralelizirat ćemo zahtjeve kako bismo ekstrakciju grafikona učinili bržim i pohranili rezultate u Neo4j:
MAX_WORKERS = 10 NUM_ARTICLES = 2000 graph_documents = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(process_text, f"{row['title']} {row['text']}") for i, row in news.head(NUM_ARTICLES).iterrows() ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): graph_document = future.result() graph_documents.extend(graph_document) graph.add_graph_documents( graph_documents, baseEntityLabel=True, include_source=True )
U ovom primjeru izvlačimo informacije grafikona iz 2000 članaka i pohranjujemo rezultate u Neo4j. Ekstrahirali smo oko 13.000 entiteta i 16.000 odnosa. Evo primjera izdvojenog dokumenta na grafikonu.


Za dovršetak ekstrakcije potrebno je oko 35 (+/- 5) minuta i košta oko 30 USD s GPT-4o.
U ovom koraku, autori uvode heuristiku kako bi odlučili hoće li izvući informacije grafikona u više od jednog prolaza. Radi jednostavnosti, napravit ćemo samo jedan prolaz. Međutim, ako želimo napraviti više prolaza, mogli bismo staviti prve rezultate ekstrakcije kao povijest razgovora i jednostavno uputiti LLM da mnogi entiteti nedostaju , i on bi trebao izdvojiti više, kao što to rade autori GraphRAG-a.
Ranije sam spomenuo koliko je bitna veličina bloka teksta i kako ona utječe na broj ekstrahiranih entiteta. Budući da nismo izvršili nikakvo dodatno dijeljenje teksta, možemo procijeniti distribuciju izdvojenih entiteta na temelju veličine dijela teksta:
entity_dist = graph.query( """ MATCH (d:Document) RETURN d.text AS text, count {(d)-[:MENTIONS]->()} AS entity_count """ ) entity_dist_df = pd.DataFrame.from_records(entity_dist) entity_dist_df["token_count"] = [ num_tokens_from_string(str(el)) for el in entity_dist_df["text"] ] # Scatter plot with regression line sns.lmplot( x="token_count", y="entity_count", data=entity_dist_df, line_kws={"color": "red"} ) plt.title("Entity Count vs Token Count Distribution") plt.xlabel("Token Count") plt.ylabel("Entity Count") plt.show()


Dijagram raspršenosti pokazuje da iako postoji pozitivan trend, označen crvenom linijom, odnos je sublinearan. Većina podatkovnih točaka grupira se pri nižim brojevima entiteta, čak i kada se brojevi tokena povećavaju. To znači da se broj ekstrahiranih entiteta ne mjeri proporcionalno veličini dijelova teksta. Iako postoje neki ekstremi, opći obrazac pokazuje da veći broj tokena ne dovodi dosljedno do većeg broja entiteta. Ovo potvrđuje nalaz autora da će manje veličine dijelova teksta izvući više informacija.
Također sam mislio da bi bilo zanimljivo pregledati distribucije stupnja čvorova konstruiranog grafa. Sljedeći kod dohvaća i vizualizira raspodjele stupnja čvorova:
degree_dist = graph.query( """ MATCH (e:__Entity__) RETURN count {(e)-[:!MENTIONS]-()} AS node_degree """ ) degree_dist_df = pd.DataFrame.from_records(degree_dist) # Calculate mean and median mean_degree = np.mean(degree_dist_df['node_degree']) percentiles = np.percentile(degree_dist_df['node_degree'], [25, 50, 75, 90]) # Create a histogram with a logarithmic scale plt.figure(figsize=(12, 6)) sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue') # Use a logarithmic scale for the x-axis plt.yscale('log') # Adding labels and title plt.xlabel('Node Degree') plt.ylabel('Count (log scale)') plt.title('Node Degree Distribution') # Add mean, median, and percentile lines plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'Mean: {mean_degree:.2f}') plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25th Percentile: {percentiles[0]:.2f}') plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50th Percentile: {percentiles[1]:.2f}') plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75th Percentile: {percentiles[2]:.2f}') plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90th Percentile: {percentiles[3]:.2f}') # Add legend plt.legend() # Show the plot plt.show()


Distribucija stupnja čvora slijedi obrazac zakona snage, što ukazuje da većina čvorova ima vrlo malo veza, dok je nekoliko čvorova visoko povezano. Srednji stupanj je 2,45, a medijan 1,00, što pokazuje da više od polovice čvorova ima samo jednu vezu. Većina čvorova (75 posto) ima dvije ili manje veza, a 90 posto pet ili manje. Ova distribucija tipična je za mnoge mreže u stvarnom svijetu, gdje mali broj čvorišta ima mnogo veza, a većina čvorova ima malo.
Budući da opisi čvorova i odnosa nisu obvezna svojstva, također ćemo ispitati koliko ih je ekstrahirano:
graph.query(""" MATCH (n:`__Entity__`) RETURN "node" AS type, count(*) AS total_count, count(n.description) AS non_null_descriptions UNION ALL MATCH (n)-[r:!MENTIONS]->() RETURN "relationship" AS type, count(*) AS total_count, count(r.description) AS non_null_descriptions """)
Rezultati pokazuju da 5926 čvorova od 12994 (45,6 posto) ima svojstvo opisa. S druge strane, samo 5.569 veza od 15.921 (35 posto) ima takvo svojstvo.
Imajte na umu da zbog vjerojatnosne prirode LLM-ova, brojevi mogu varirati u različitim izvođenjima i različitim izvornim podacima, LLM-ovima i upitima.
Rješenje entiteta
Razlučivanje entiteta (dedupliciranje) ključno je pri izradi grafikona znanja jer osigurava da je svaki entitet jedinstveno i točno predstavljen, sprječavajući duplikate i spajanje zapisa koji se odnose na isti entitet iz stvarnog svijeta. Ovaj je proces bitan za održavanje integriteta podataka i dosljednosti unutar grafikona. Bez razlučivanja entiteta, grafikoni znanja patili bi od fragmentiranih i nedosljednih podataka, što bi dovelo do pogrešaka i nepouzdanih uvida.


Ova slika pokazuje kako se jedan entitet iz stvarnog svijeta može pojaviti pod neznatno drugačijim imenima u različitim dokumentima i, posljedično, u našem grafikonu.
Štoviše, rijetki podaci postaju značajan problem bez rješavanja entiteta. Nepotpuni ili djelomični podaci iz različitih izvora mogu rezultirati raštrkanim i nepovezanim dijelovima informacija, što otežava stvaranje koherentnog i sveobuhvatnog razumijevanja entiteta. Precizno razlučivanje entiteta rješava to konsolidacijom podataka, popunjavanjem praznina i stvaranjem jedinstvenog prikaza svakog entiteta.


Prije/poslije korištenja razlučivanja entiteta Senzing za povezivanje podataka o curenju podataka Međunarodnog konzorcija istraživačkih novinara (ICIJ) u pučinu — slika Paca Nathana
Lijevi dio vizualizacije predstavlja oskudan i nepovezan graf. Međutim, kao što je prikazano na desnoj strani, takav graf može postati dobro povezan s učinkovitom rezolucijom entiteta.
Sveukupno, razlučivanje entiteta poboljšava učinkovitost dohvaćanja podataka i integracije, pružajući kohezivni prikaz informacija iz različitih izvora. U konačnici omogućuje učinkovitije odgovaranje na pitanja na temelju pouzdanog i potpunog grafikona znanja.
Nažalost, autori GraphRAG dokumenta nisu uključili nikakav kod za rješavanje entiteta u svoj repo, iako ga spominju u svom radu. Jedan od razloga za izostavljanje ovog koda mogao bi biti taj što je teško implementirati robusnu i učinkovitu rezoluciju entiteta za bilo koju domenu. Možete implementirati prilagođenu heuristiku za različite čvorove kada radite s unaprijed definiranim vrstama čvorova (ako nisu unaprijed definirani, nisu dovoljno dosljedni, poput tvrtke, organizacije, posla itd.). Međutim, ako oznake ili tipovi čvorova nisu unaprijed poznati, kao u našem slučaju, to postaje još teži problem. Bez obzira na to, implementirat ćemo verziju razlučivanja entiteta u naš projekt ovdje, kombinirajući ugradnje teksta i algoritme grafikona s udaljenosti riječi i LLM-ovima.


Naš postupak rješavanja entiteta uključuje sljedeće korake:
- Entiteti u grafikonu — Započnite sa svim entitetima unutar grafikona.
- K-najbliži graf — Konstruirajte k-najbliži susjedni graf, povezujući slične entitete na temelju ugrađivanja teksta.
- Slabo povezane komponente — Identificirajte slabo povezane komponente u k-najbližem grafu, grupirajući entitete koji su vjerojatno slični. Dodajte korak filtriranja udaljenosti riječi nakon što su te komponente identificirane.
- Procjena LLM -a — Koristite LLM za procjenu ovih komponenti i odlučite trebaju li se entiteti unutar svake komponente spojiti, što rezultira konačnom odlukom o razrješenju entiteta (na primjer, spajanje 'Silicon Valley Bank' i 'Silicon_Valley_Bank' uz odbijanje spajanja za različite datumi poput '16. rujna 2023.' i '2. rujna 2023.').
Počinjemo s izračunavanjem ugrađivanja teksta za svojstva naziva i opisa entiteta. Možemo upotrijebiti metodu from_existing_graph u Neo4jVector integraciji u LangChainu da bismo to postigli:
vector = Neo4jVector.from_existing_graph( OpenAIEmbeddings(), node_label='__Entity__', text_node_properties=['id', 'description'], embedding_node_property='embedding' )
Možemo upotrijebiti ova ugrađivanja kako bismo pronašli potencijalne kandidate koji su slični na temelju kosinusne udaljenosti tih umetanja. Koristit ćemo algoritme grafova koji su dostupni u biblioteci Graph Data Science (GDS) ; stoga možemo koristiti GDS Python klijent za jednostavnu upotrebu na Pythonic način:
from graphdatascience import GraphDataScience gds = GraphDataScience( os.environ["NEO4J_URI"], auth=(os.environ["NEO4J_USERNAME"], os.environ["NEO4J_PASSWORD"]) )
Ako niste upoznati s GDS bibliotekom, prvo moramo projektirati graf u memoriji prije nego što možemo izvršiti bilo koji algoritam grafa.


Prvo, Neo4j pohranjeni graf se projicira u graf u memoriji za bržu obradu i analizu. Zatim se algoritam grafa izvršava na grafu u memoriji. Po izboru, rezultati algoritma mogu se pohraniti natrag u Neo4j bazu podataka. Saznajte više o tome u dokumentaciji .
Da bismo stvorili graf k-najbližih susjeda, projicirat ćemo sve entitete zajedno s njihovim umetnutim tekstom:
G, result = gds.graph.project( "entities", # Graph name "__Entity__", # Node projection "*", # Relationship projection nodeProperties=["embedding"] # Configuration parameters )
Sada kada je graf projiciran pod imenom entities , možemo izvršiti algoritme za graf. Počet ćemo konstruiranjem k-najbližeg grafa . Dva najvažnija parametra koji utječu na to koliko će k-najbliži graf biti rijedak ili gust su similarityCutoff i topK . topK je broj susjeda koje treba pronaći za svaki čvor, s minimalnom vrijednošću 1. similarityCutoff filtrira odnose sa sličnošću ispod ovog praga. Ovdje ćemo koristiti zadani topK od 10 i relativno visoku graničnu vrijednost sličnosti od 0,95. Korištenje granične vrijednosti visoke sličnosti, kao što je 0,95, osigurava da se samo vrlo slični parovi smatraju podudaranjima, smanjujući lažno pozitivne rezultate i poboljšavajući točnost.


Budući da želimo pohraniti rezultate natrag u projektirani graf u memoriji umjesto u graf znanja, koristit ćemo način mutate algoritma:
similarity_threshold = 0.95 gds.knn.mutate( G, nodeProperties=['embedding'], mutateRelationshipType= 'SIMILAR', mutateProperty= 'score', similarityCutoff=similarity_threshold )
Sljedeći korak je identificirati grupe entiteta koji su povezani s novozaključenim odnosima sličnosti. Identificiranje grupa povezanih čvorova čest je proces u mrežnoj analizi, koji se često naziva otkrivanje zajednice ili klasteriranje , što uključuje pronalaženje podgrupa gusto povezanih čvorova. U ovom primjeru koristit ćemo algoritam slabo povezanih komponenti , koji nam pomaže pronaći dijelove grafa gdje su svi čvorovi povezani, čak i ako zanemarimo smjer veza.


Koristimo način write algoritma za pohranu rezultata natrag u bazu podataka (pohranjeni graf):
gds.wcc.write( G, writeProperty="wcc", relationshipTypes=["SIMILAR"] )
Usporedba ugrađivanja teksta pomaže u pronalaženju potencijalnih duplikata, ali samo je dio procesa rješavanja entiteta. Na primjer, Google i Apple su vrlo bliski u prostoru ugradnje (0,96 kosinusne sličnosti korištenjem ada-002 modela ugradnje). Isto vrijedi za BMW i Mercedes Benz (0,97 kosinus sličnosti). Visoka sličnost ugrađivanja teksta dobar je početak, ali možemo je poboljšati. Stoga ćemo dodati dodatni filtar koji dopušta samo parove riječi s razmakom teksta od tri ili manje (što znači da se mogu mijenjati samo znakovi):
word_edit_distance = 3 potential_duplicate_candidates = graph.query( """MATCH (e:`__Entity__`) WHERE size(e.id) > 3 // longer than 3 characters WITH e.wcc AS community, collect(e) AS nodes, count(*) AS count WHERE count > 1 UNWIND nodes AS node // Add text distance WITH distinct [n IN nodes WHERE apoc.text.distance(toLower(node.id), toLower(n.id)) < $distance OR node.id CONTAINS n.id | n.id] AS intermediate_results WHERE size(intermediate_results) > 1 WITH collect(intermediate_results) AS results // combine groups together if they share elements UNWIND range(0, size(results)-1, 1) as index WITH results, index, results[index] as result WITH apoc.coll.sort(reduce(acc = result, index2 IN range(0, size(results)-1, 1) | CASE WHEN index <> index2 AND size(apoc.coll.intersection(acc, results[index2])) > 0 THEN apoc.coll.union(acc, results[index2]) ELSE acc END )) as combinedResult WITH distinct(combinedResult) as combinedResult // extra filtering WITH collect(combinedResult) as allCombinedResults UNWIND range(0, size(allCombinedResults)-1, 1) as combinedResultIndex WITH allCombinedResults[combinedResultIndex] as combinedResult, combinedResultIndex, allCombinedResults WHERE NOT any(x IN range(0,size(allCombinedResults)-1,1) WHERE x <> combinedResultIndex AND apoc.coll.containsAll(allCombinedResults[x], combinedResult) ) RETURN combinedResult """, params={'distance': word_edit_distance})
Ova Cypher izjava malo je složenija, a njezino tumačenje je izvan opsega ovog posta na blogu. Uvijek možete zamoliti LLM da ga protumači.


Osim toga, granična udaljenost riječi mogla bi biti funkcija duljine riječi umjesto jednog broja, a implementacija bi mogla biti skalabilnija.
Ono što je važno jest da daje grupe potencijalnih entiteta koje bismo možda željeli spojiti. Ovdje je popis potencijalnih čvorova za spajanje:
{'combinedResult': ['Sinn Fein', 'Sinn Féin']}, {'combinedResult': ['Government', 'Governments']}, {'combinedResult': ['Unreal Engine', 'Unreal_Engine']}, {'combinedResult': ['March 2016', 'March 2020', 'March 2022', 'March_2023']}, {'combinedResult': ['Humana Inc', 'Humana Inc.']}, {'combinedResult': ['New York Jets', 'New York Mets']}, {'combinedResult': ['Asia Pacific', 'Asia-Pacific', 'Asia_Pacific']}, {'combinedResult': ['Bengaluru', 'Mangaluru']}, {'combinedResult': ['US Securities And Exchange Commission', 'Us Securities And Exchange Commission']}, {'combinedResult': ['Jp Morgan', 'Jpmorgan']}, {'combinedResult': ['Brighton', 'Brixton']},
Kao što vidite, naš pristup rješavanju radi bolje za neke vrste čvorova nego za druge. Na temelju brzog ispitivanja, čini se da bolje funkcionira za ljude i organizacije, dok je prilično loše za datume. Kad bismo koristili unaprijed definirane tipove čvorova, mogli bismo pripremiti različite heuristike za različite tipove čvorova. U ovom primjeru nemamo unaprijed definirane oznake čvorova, pa ćemo se obratiti LLM-u da donese konačnu odluku o tome trebaju li se entiteti spojiti ili ne.
Prvo, moramo formulirati upit za LLM kako bismo učinkovito vodili i informirali konačnu odluku o spajanju čvorova:
system_prompt = """You are a data processing assistant. Your task is to identify duplicate entities in a list and decide which of them should be merged. The entities might be slightly different in format or content, but essentially refer to the same thing. Use your analytical skills to determine duplicates. Here are the rules for identifying duplicates: 1. Entities with minor typographical differences should be considered duplicates. 2. Entities with different formats but the same content should be considered duplicates. 3. Entities that refer to the same real-world object or concept, even if described differently, should be considered duplicates. 4. If it refers to different numbers, dates, or products, do not merge results """ user_template = """ Here is the list of entities to process: {entities} Please identify duplicates, merge them, and provide the merged list. """
Uvijek volim koristiti with_structured_output metodu u LangChainu kada očekujem izlaz strukturiranih podataka kako bih izbjegao ručno analiziranje izlaza.
Ovdje ćemo definirati izlaz kao list of lists , gdje svaki unutarnji popis sadrži entitete koje treba spojiti. Ova se struktura koristi za rukovanje scenarijima gdje, na primjer, unos može biti [Sony, Sony Inc, Google, Google Inc] . U takvim slučajevima, trebali biste spojiti "Sony" i "Sony Inc" odvojeno od "Google" i "Google Inc."
class DuplicateEntities(BaseModel): entities: List[str] = Field( description="Entities that represent the same object or real-world entity and should be merged" ) class Disambiguate(BaseModel): merge_entities: Optional[List[DuplicateEntities]] = Field( description="Lists of entities that represent the same object or real-world entity and should be merged" ) extraction_llm = ChatOpenAI(model_name="gpt-4o").with_structured_output( Disambiguate )
Zatim integriramo LLM prompt sa strukturiranim izlazom kako bismo stvorili lanac pomoću sintakse jezika LangChain Expression Language (LCEL) i enkapsulirali ga unutar funkcije disambiguate .
extraction_chain = extraction_prompt | extraction_llm def entity_resolution(entities: List[str]) -> Optional[List[List[str]]]: return [ el.entities for el in extraction_chain.invoke({"entities": entities}).merge_entities ]
Moramo pokrenuti sve potencijalne čvorove kandidate kroz funkciju entity_resolution kako bismo odlučili treba li ih spojiti. Kako bismo ubrzali proces, ponovno ćemo paralelizirati LLM pozive:
merged_entities = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(entity_resolution, el['combinedResult']) for el in potential_duplicate_candidates ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): to_merge = future.result() if to_merge: merged_entities.extend(to_merge)
Posljednji korak razlučivanja entiteta uključuje uzimanje rezultata iz entity_resolution LLM i njihovo zapisivanje natrag u bazu podataka spajanjem navedenih čvorova:
graph.query(""" UNWIND $data AS candidates CALL { WITH candidates MATCH (e:__Entity__) WHERE e.id IN candidates RETURN collect(e) AS nodes } CALL apoc.refactor.mergeNodes(nodes, {properties: { description:'combine', `.*`: 'discard' }}) YIELD node RETURN count(*) """, params={"data": merged_entities})
Ova rezolucija entiteta nije savršena, ali daje nam početnu točku koju možemo poboljšati. Osim toga, možemo poboljšati logiku za određivanje entiteta koje treba zadržati.
Sažimanje elemenata
U sljedećem koraku autori izvode korak sažimanja elemenata. U biti, svaki čvor i odnos prolaze kroz upit za sažetak entiteta . Autori ističu novost i zanimljivost svog pristupa:
“Općenito, naša upotreba bogatog opisnog teksta za homogene čvorove u potencijalno šumnoj strukturi grafa usklađena je i s mogućnostima LLM-a i s potrebama globalnog sažimanja usmjerenog na upite. Ove kvalitete također razlikuju naš indeks grafikona od tipičnih grafikona znanja, koji se oslanjaju na koncizne i dosljedne trojke znanja (subjekt, predikat, objekt) za nizvodne zadatke zaključivanja.”
Ideja je uzbudljiva. I dalje izvlačimo ID-ove ili imena predmeta i objekata iz teksta, što nam omogućuje povezivanje odnosa s ispravnim entitetima, čak i kada se entiteti pojavljuju u višestrukim dijelovima teksta. Međutim, odnosi se ne svode na jednu vrstu. Umjesto toga, vrsta odnosa zapravo je tekst slobodnog oblika koji nam omogućuje da zadržimo bogatije i nijansiranije informacije.
Osim toga, informacije o entitetu sažete su pomoću LLM-a, što nam omogućuje učinkovitije ugrađivanje i indeksiranje ovih podataka i entiteta za točnije dohvaćanje.
Moglo bi se tvrditi da se te bogatije i nijansiranije informacije mogu zadržati dodavanjem dodatnih, po mogućnosti proizvoljnih, svojstava čvorova i odnosa. Jedan problem s proizvoljnim svojstvima čvora i odnosa jest da bi moglo biti teško dosljedno izvući informacije jer LLM može koristiti različite nazive svojstava ili se usredotočiti na različite pojedinosti pri svakom izvršenju.
Neki od ovih problema mogu se riješiti korištenjem unaprijed definiranih naziva svojstava s dodatnim informacijama o vrsti i opisu. U tom slučaju, trebat će vam stručnjak za određeno područje koji će vam pomoći definirati ta svojstva, ostavljajući malo prostora LLM-u da izvuče bilo kakve vitalne informacije izvan unaprijed definiranih opisa.
To je uzbudljiv pristup predstavljanju bogatijih informacija u grafikonu znanja.
Jedan potencijalni problem s korakom sažimanja elementa je da se ne skalira dobro jer zahtijeva LLM poziv za svaki entitet i odnos u grafikonu. Naš je grafikon relativno malen s 13 000 čvorova i 16 000 odnosa. Čak i za tako mali graf, bilo bi nam potrebno 29 000 LLM poziva, a svaki bi poziv koristio nekoliko stotina tokena, što ga čini prilično skupim i vremenski intenzivnim. Stoga ćemo ovdje izbjegavati ovaj korak. I dalje možemo koristiti svojstva opisa izdvojena tijekom početne obrade teksta.
Konstruiranje i sažimanje zajednica
Posljednji korak u procesu konstrukcije grafikona i indeksiranja uključuje identificiranje zajednica unutar grafikona. U ovom kontekstu, zajednica je skupina čvorova koji su međusobno gušće povezani nego s ostatkom grafa, što ukazuje na višu razinu interakcije ili sličnosti. Sljedeća vizualizacija prikazuje primjer rezultata otkrivanja zajednice.


Nakon što se te zajednice entiteta identificiraju algoritmom klasteriranja, LLM generira sažetak za svaku zajednicu, pružajući uvid u njihove pojedinačne karakteristike i odnose.
Ponovno koristimo biblioteku Graph Data Science. Počinjemo projiciranjem grafa u memoriji. Kako bismo točno pratili izvorni članak, projicirat ćemo graf entiteta kao neusmjerenu težinsku mrežu, gdje mreža predstavlja broj veza između dva entiteta:
G, result = gds.graph.project( "communities", # Graph name "__Entity__", # Node projection { "_ALL_": { "type": "*", "orientation": "UNDIRECTED", "properties": {"weight": {"property": "*", "aggregation": "COUNT"}}, } }, )
Autori su upotrijebili Leidenov algoritam , metodu hijerarhijskog klasteriranja, kako bi identificirali zajednice unutar grafa. Jedna prednost korištenja hijerarhijskog algoritma za otkrivanje zajednice je mogućnost ispitivanja zajednica na više razina granularnosti. Autori predlažu sažimanje svih zajednica na svakoj razini, pružajući sveobuhvatno razumijevanje strukture grafikona.
Prvo ćemo koristiti algoritam slabo povezanih komponenti (WCC) za procjenu povezanosti našeg grafikona. Ovaj algoritam identificira izolirane dijelove unutar grafa, što znači da otkriva podskupove čvorova ili komponenti koje su povezane jedna s drugom, ali ne i s ostatkom grafa. Ove komponente nam pomažu razumjeti fragmentaciju unutar mreže i identificirati grupe čvorova koji su neovisni o drugima. WCC je vitalan za analizu cjelokupne strukture i povezanosti grafa.
wcc = gds.wcc.stats(G) print(f"Component count: {wcc['componentCount']}") print(f"Component distribution: {wcc['componentDistribution']}") # Component count: 1119 # Component distribution: { # "min":1, # "p5":1, # "max":9109, # "p999":43, # "p99":19, # "p1":1, # "p10":1, # "p90":7, # "p50":2, # "p25":1, # "p75":4, # "p95":10, # "mean":11.3 }
Rezultati WCC algoritma identificirali su 1119 različitih komponenti. Naime, najveća komponenta se sastoji od 9109 čvorova, uobičajenih u mrežama stvarnog svijeta gdje jedna superkomponenta koegzistira s brojnim manjim izoliranim komponentama. Najmanja komponenta ima jedan čvor, a prosječna veličina komponente je oko 11,3 čvora.
Zatim ćemo pokrenuti Leidenov algoritam, koji je također dostupan u GDS biblioteci, i omogućiti parametar includeIntermediateCommunities za vraćanje i pohranjivanje zajednica na svim razinama. Također smo uključili parametar relationshipWeightProperty za pokretanje ponderirane varijante Leidenovog algoritma. Korištenje načina write algoritma pohranjuje rezultate kao svojstvo čvora.
gds.leiden.write( G, writeProperty="communities", includeIntermediateCommunities=True, relationshipWeightProperty="weight", )
Algoritam je identificirao pet razina zajednica, s najvišom (najmanje granularnom razinom gdje su zajednice najveće) koja ima 1188 zajednica (za razliku od 1119 komponenti). Ovdje je vizualizacija zajednica na posljednjoj razini pomoću Gephija.


Vizualizacija više od 1000 zajednica je teška; čak je i odabrati boje za svaku praktički nemoguće. Međutim, oni čine lijepe umjetničke izvedbe.
Nadovezujući se na to, stvorit ćemo poseban čvor za svaku zajednicu i predstaviti njihovu hijerarhijsku strukturu kao međusobno povezani grafikon. Kasnije ćemo također pohraniti sažetke zajednice i druge atribute kao svojstva čvora.
graph.query(""" MATCH (e:`__Entity__`) UNWIND range(0, size(e.communities) - 1 , 1) AS index CALL { WITH e, index WITH e, index WHERE index = 0 MERGE (c:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET c.level = index MERGE (e)-[:IN_COMMUNITY]->(c) RETURN count(*) AS count_0 } CALL { WITH e, index WITH e, index WHERE index > 0 MERGE (current:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET current.level = index MERGE (previous:`__Community__` {id: toString(index - 1) + '-' + toString(e.communities[index - 1])}) ON CREATE SET previous.level = index - 1 MERGE (previous)-[:IN_COMMUNITY]->(current) RETURN count(*) AS count_1 } RETURN count(*) """)
Autori također uvode community rank , koji označava broj različitih tekstualnih dijelova u kojima se pojavljuju entiteti unutar zajednice:
graph.query(""" MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(:__Entity__)<-[:MENTIONS]-(d:Document) WITH c, count(distinct d) AS rank SET c.community_rank = rank; """)
Ispitajmo sada primjer hijerarhijske strukture s mnogim srednjim zajednicama koje se spajaju na višim razinama. Zajednice se ne preklapaju, što znači da svaki entitet pripada točno jednoj zajednici na svakoj razini.


Slika predstavlja hijerarhijsku strukturu koja proizlazi iz algoritma detekcije zajednice Leiden. Ljubičasti čvorovi predstavljaju pojedinačne entitete, dok narančasti čvorovi predstavljaju hijerarhijske zajednice.
Hijerarhija pokazuje organizaciju tih entiteta u različite zajednice, pri čemu se manje zajednice spajaju u veće na višim razinama.
Ispitajmo sada kako se manje zajednice spajaju na višim razinama.

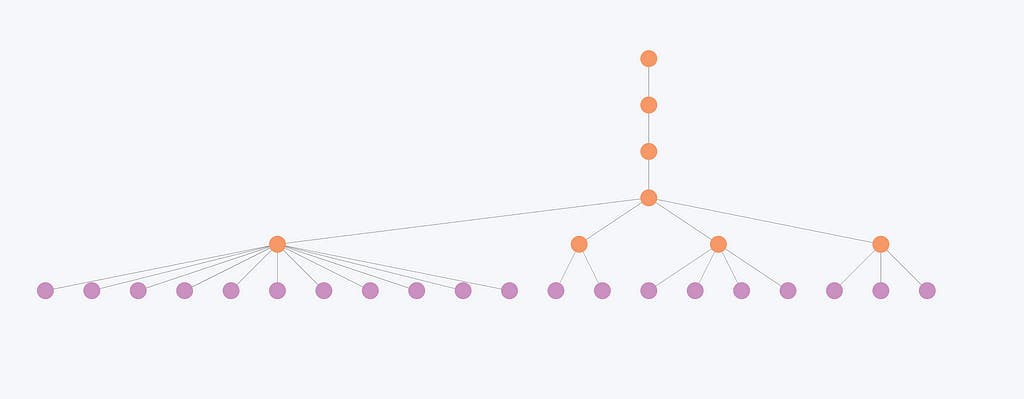
Ova slika ilustrira da manje povezani entiteti i posljedično manje zajednice doživljavaju minimalne promjene na svim razinama. Na primjer, struktura zajednice ovdje se mijenja samo na prve dvije razine, ali ostaje identična na posljednje tri razine. Posljedično, hijerarhijske razine se često čine suvišnima za ove entitete, jer se cjelokupna organizacija značajno ne mijenja na različitim razinama.
Pogledajmo detaljnije broj zajednica i njihovu veličinu i različite razine:
community_size = graph.query( """ MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(e:__Entity__) WITH c, count(distinct e) AS entities RETURN split(c.id, '-')[0] AS level, entities """ ) community_size_df = pd.DataFrame.from_records(community_size) percentiles_data = [] for level in community_size_df["level"].unique(): subset = community_size_df[community_size_df["level"] == level]["entities"] num_communities = len(subset) percentiles = np.percentile(subset, [25, 50, 75, 90, 99]) percentiles_data.append( [ level, num_communities, percentiles[0], percentiles[1], percentiles[2], percentiles[3], percentiles[4], max(subset) ] ) # Create a DataFrame with the percentiles percentiles_df = pd.DataFrame( percentiles_data, columns=[ "Level", "Number of communities", "25th Percentile", "50th Percentile", "75th Percentile", "90th Percentile", "99th Percentile", "Max" ], ) percentiles_df


U izvornoj implementaciji, zajednice na svim razinama bile su sažete. U našem slučaju to bi bilo 8.590 zajednica i, posljedično, 8.590 LLM poziva. Tvrdio bih da, ovisno o hijerarhijskoj strukturi zajednice, ne treba svaku razinu sažimati. Na primjer, razlika između zadnje i pretposljednje razine je samo četiri zajednice (1192 naspram 1188). Stoga bismo stvorili mnogo suvišnih sažetaka. Jedno rješenje je stvoriti implementaciju koja može napraviti jedan sažetak za zajednice na različitim razinama koje se ne mijenjaju; drugi bi bio urušavanje hijerarhija zajednice koje se ne mijenjaju.
Također, nisam siguran želimo li sažeti zajednice sa samo jednim članom, jer možda ne pružaju mnogo vrijednosti ili informacija. Ovdje ćemo sažeti zajednice na razinama 0, 1 i 4. Prvo moramo dohvatiti njihove informacije iz baze podataka:
community_info = graph.query(""" MATCH (c:`__Community__`)<-[:IN_COMMUNITY*]-(e:__Entity__) WHERE c.level IN [0,1,4] WITH c, collect(e ) AS nodes WHERE size(nodes) > 1 CALL apoc.path.subgraphAll(nodes[0], { whitelistNodes:nodes }) YIELD relationships RETURN c.id AS communityId, [n in nodes | {id: n.id, description: n.description, type: [el in labels(n) WHERE el <> '__Entity__'][0]}] AS nodes, [r in relationships | {start: startNode(r).id, type: type(r), end: endNode(r).id, description: r.description}] AS rels """)
Trenutno informacije o zajednici imaju sljedeću strukturu:
{'communityId': '0-6014', 'nodes': [{'id': 'Darrell Hughes', 'description': None, type:"Person"}, {'id': 'Chief Pilot', 'description': None, type: "Person"}, ... }], 'rels': [{'start': 'Ryanair Dac', 'description': 'Informed of the change in chief pilot', 'type': 'INFORMED', 'end': 'Irish Aviation Authority'}, {'start': 'Ryanair Dac', 'description': 'Dismissed after internal investigation found unacceptable behaviour', 'type': 'DISMISSED', 'end': 'Aidan Murray'}, ... ]}
Sada moramo pripremiti LLM upit koji generira sažetak prirodnog jezika na temelju informacija koje pružaju elementi naše zajednice. Možemo uzeti nešto inspiracije iz poticaja koji su istraživači koristili .
Autori ne samo da su saželi zajednice, već su i generirali nalaze za svaku od njih. Nalaz se može definirati kao sažeta informacija o određenom događaju ili informaciji. Jedan takav primjer:
"summary": "Abila City Park as the central location", "explanation": "Abila City Park is the central entity in this community, serving as the location for the POK rally. This park is the common link between all other entities, suggesting its significance in the community. The park's association with the rally could potentially lead to issues such as public disorder or conflict, depending on the nature of the rally and the reactions it provokes. [records: Entities (5), Relationships (37, 38, 39, 40)]"
Moja intuicija sugerira da izdvajanje nalaza samo jednim prolazom možda neće biti sveobuhvatno koliko nam je potrebno, slično kao izdvajanje entiteta i odnosa.
Nadalje, nisam pronašao nikakve reference ili primjere njihove upotrebe u njihovom kodu ni u lokalnim ni u globalnim pretraživačima. Kao rezultat toga, u ovom ćemo se slučaju suzdržati od izdvajanja nalaza. Ili, kako to akademici često kažu: ovu vježbu prepuštamo čitatelju. Osim toga, također smo preskočili tvrdnje ili ekstrakciju kovarijatnih informacija , što na prvi pogled izgleda slično nalazima.
Upit koji ćemo koristiti za izradu sažetaka zajednice prilično je jednostavan:
community_template = """Based on the provided nodes and relationships that belong to the same graph community, generate a natural language summary of the provided information: {community_info} Summary:""" # noqa: E501 community_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Given an input triples, generate the information summary. No pre-amble.", ), ("human", community_template), ] ) community_chain = community_prompt | llm | StrOutputParser()
Jedina stvar koja je preostala jest pretvoriti prikaze zajednice u nizove kako bi se smanjio broj tokena izbjegavanjem preopterećenja JSON tokena i zamotao lanac kao funkciju:
def prepare_string(data): nodes_str = "Nodes are:\n" for node in data['nodes']: node_id = node['id'] node_type = node['type'] if 'description' in node and node['description']: node_description = f", description: {node['description']}" else: node_description = "" nodes_str += f"id: {node_id}, type: {node_type}{node_description}\n" rels_str = "Relationships are:\n" for rel in data['rels']: start = rel['start'] end = rel['end'] rel_type = rel['type'] if 'description' in rel and rel['description']: description = f", description: {rel['description']}" else: description = "" rels_str += f"({start})-[:{rel_type}]->({end}){description}\n" return nodes_str + "\n" + rels_str def process_community(community): stringify_info = prepare_string(community) summary = community_chain.invoke({'community_info': stringify_info}) return {"community": community['communityId'], "summary": summary}
Sada možemo generirati sažetke zajednice za odabrane razine. Opet, paraleliziramo pozive radi bržeg izvršenja:
summaries = [] with ThreadPoolExecutor() as executor: futures = {executor.submit(process_community, community): community for community in community_info} for future in tqdm(as_completed(futures), total=len(futures), desc="Processing communities"): summaries.append(future.result())
Jedan aspekt koji nisam spomenuo jest da se autori također bave potencijalnim problemom prekoračenja veličine konteksta prilikom unosa informacija o zajednici. Kako se grafikoni šire, zajednice također mogu značajno rasti. U našem slučaju najveća zajednica broji 545 članova. S obzirom da GPT-4o ima veličinu konteksta veću od 100.000 tokena, odlučili smo preskočiti ovaj korak.
Kao posljednji korak, pohranit ćemo sažetke zajednice natrag u bazu podataka:
graph.query(""" UNWIND $data AS row MERGE (c:__Community__ {id:row.community}) SET c.summary = row.summary """, params={"data": summaries})
Konačna struktura grafa:


Grafikon sada sadrži izvorne dokumente, izdvojene entitete i odnose, kao i hijerarhijsku strukturu zajednice i sažetke.
Sažetak
Autori rada “Od lokalnog do globalnog” napravili su sjajan posao u demonstraciji novog pristupa GraphRAG-u. Oni pokazuju kako možemo kombinirati i sažeti informacije iz različitih dokumenata u hijerarhijsku strukturu grafikona znanja.
Jedna stvar koja nije eksplicitno spomenuta je da također možemo integrirati strukturirane izvore podataka u grafikon; unos ne mora biti ograničen samo na nestrukturirani tekst.
Ono što posebno cijenim kod njihovog pristupa izdvajanju je to što hvataju opise i za čvorove i za odnose. Opisi omogućuju LLM-u da zadrži više informacija od smanjenja svega na samo ID-ove čvorova i vrste odnosa.
Osim toga, oni pokazuju da jedan prolaz ekstrakcije preko teksta možda neće uhvatiti sve relevantne informacije i uvode logiku za izvođenje više prolaza ako je potrebno. Autori također predstavljaju zanimljivu ideju za izvođenje sažimanja nad zajednicama grafova, što nam omogućuje ugrađivanje i indeksiranje sažetih tematskih informacija u višestrukim izvorima podataka.
U sljedećem postu na blogu proći ćemo kroz lokalne i globalne implementacije retrivera pretraživanja i govoriti o drugim pristupima koje bismo mogli implementirati na temelju dane strukture grafa.
Kao i uvijek, kod je dostupan na GitHubu .
Ovaj put sam također prenio ispis baze podataka tako da možete istražiti rezultate i eksperimentirati s različitim opcijama preuzimanja.
Također možete uvesti ovaj dump u zauvijek besplatnu instancu Neo4j AuraDB , koju možemo koristiti za istraživanja dohvaćanja budući da nam za to nisu potrebni algoritmi Graph Data Science — samo podudaranje uzorka grafikona, vektorski indeksi i indeksi punog teksta.
Saznajte više o Neo4j integracijama sa svim GenAI okvirima i praktičnim algoritmima grafova u mojoj knjizi "Algoritmi grafova za podatkovnu znanost."
Da biste saznali više o ovoj temi, pridružite nam se na NODES 2024 7. studenog, našoj besplatnoj virtualnoj konferenciji za razvojne programere o inteligentnim aplikacijama, grafikonima znanja i umjetnoj inteligenciji. Registrirajte se sada !




